36.Object中equals和toStirng 源码分析
文章目录
- 1.equals方法
- 2.重写equals方法为何一定要重写hashCode方法?
- 2.1 反例演示
- 3.toString方法
- 4. 整型转二进制
我们都知道Object是所有类的父类,那么它里面的一些方法你是否真的理解了呢?
下面我们就以源码为基础来学习这些看似简单的方法吧!!
1.equals方法
我们都知道String中的equals是比较两个字符串对象内容是否相同,但你知道吗,String中的equals其实是对Object中的equals方法的重写,那么equals本来的面目是什么呢?
请看下面代码,在Object类中,equals的实现如下:
public boolean equals(Object obj) {return (this == obj);
}
从源码看很明显,他其实是判断两个对象的引用是不是同一个。也就是是说,在Object中的equals比较的并不是内容,而是引用,所以,在定义我们自己的类的时候,如果有必要,可以对这个方法进行重写来实现比较内容。
2.重写equals方法为何一定要重写hashCode方法?
这个主要是有些处理逻辑需要用到hashCode方法生成的值作为判断两个对象是否相等的依据。
在通常的认知中,对hashCode的定义是:
如果两个对象的HashCode相等,则这两个对象不一定相等,如果两个对象的HashCode不相等,那么这两个对象一定不相等。
反过来说,就是如果两个对象相等,他们的HashCode一定相等,如果两个对象不相等,他们的HashCode可能相等。
为了遵循这个机制,我们需要重写**。因为如果不进行重写,内容相等的对象计算出来的hashCode也是不相等的。**
2.1 反例演示
假如我们新建一个类,对equals进行了重写,但是没有对hashCode进行重写:
public class HashCodeStudy {int i;@Overridepublic int hashCode() {return super.hashCode();}@Overridepublic boolean equals(Object obj) {if (this == obj) {return true;}try {if(this.i== obj.getClass().getField("i").getInt(obj)){return true;}} catch (IllegalAccessException | NoSuchFieldException e) {e.printStackTrace();}return false;}public static void main(String[] args) {HashCodeStudy obj1 = new HashCodeStudy();obj1.i = 1;HashCodeStudy obj2 = new HashCodeStudy();obj2.i = 1;System.out.println("obj1和obj2的内容是否相等?");System.out.println(obj1.equals(obj1));System.out.println("obj1和obj2的hashCode是否相等?");System.out.println(obj1.hashCode()==obj2.hashCode());}
}
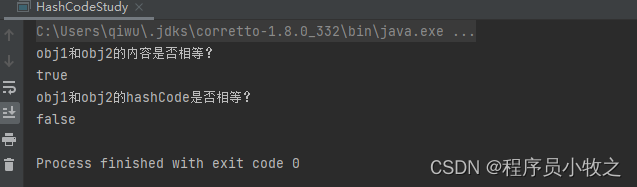
我们可以看到,当我们没有对hashCode进行重写时,就会发生两个对象内容相等,但是他们hashCode不相等的情况。这就导致我们不能用HashCode判断两个对象是否相等。
从另一个角度上看:
我们不能仅仅通过对象的hashCode去判断两个对象是否相等,还需要根据equals去比较内容。
例如HashMap的putVal中存在这样一段逻辑:
if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;
它用来判断两个对象是否相等,可以看到只有在他们hashCode相等时才会进入内容的比较,如果我们不重写hashCode方法,如果两个内容相等的对象的内存地址不同,产生的hashCode是不一样的,就无法通过这段逻辑去判断两个对象是否相等。
所以为了我们能正常使用集合对对象进行处理,在重写equlas后,想通过equals机制比较对象时,需要重写hashCode方法。
3.toString方法
先看一下源码,Object.toString():
public String toString() {return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
我们先来调用下,看到底打印出什么信息:
public static void main(String[] args) {Object obj = new Object();System.out.println(obj.toString());
}

从结果来看我们知道前面的java.lang.Object打印的是getClass().getName()的结果,就是这个类的名称,以@为一个分隔符,后面的一串数字是Integer.toHexString(hashCode())的结果,
前面的getClass().getName()我们容易理解,就是打印出这个类的完整的类名。
那后面的Integer.toHexString(hashCode());呢?我们先看看hashCode()这个方法:
public native int hashCode();
它是个本地方法,用于生产一个hash码,然后以生产的hash码作为参数来执行Integer类中的toHexString 静态方法,
//这个方法其实就是讲十进制的数转化为16进制的数的字符串表示
public static String toHexString(int i) {return toUnsignedString0(i, 4);
}
然后以hash码和4作为参数执行toUnsignedString方法返回它执行完成后的结果,这个方法其实就是讲十进制的数转化为16进制的数。
所以后面的一串数字其实就是生产的hash码的16进制的字符串表示。
我们可以进入toUnsignedString方法看看:
这个方法的作用是将整数转换成无符号数。
/*** Convert the integer to an unsigned number.*/
private static String toUnsignedString0(int val, int shift) {// assert shift > 0 && shift <=5 : "Illegal shift value";int mag = Integer.SIZE - Integer.numberOfLeadingZeros(val);int chars = Math.max(((mag + (shift - 1)) / shift), 1);char[] buf = new char[chars];formatUnsignedInt(val, shift, buf, 0, chars);// Use special constructor which takes over "buf".return new String(buf, true);
}
下面我们来分析下这个方法的执行逻辑:
首先定义一个局部变量mag,他的值是本不变类中常量SIZE(32)和numberOfLeadingZeros(val)的和:(val就是hash码)
public static int numberOfLeadingZeros(int i) {// HD, Figure 5-6if (i == 0)return 32;int n = 1;if (i >>> 16 == 0) { n += 16; i <<= 16; }if (i >>> 24 == 0) { n += 8; i <<= 8; }if (i >>> 28 == 0) { n += 4; i <<= 4; }if (i >>> 30 == 0) { n += 2; i <<= 2; }n -= i >>> 31;return n;
}
这个方法用于返回指定int值的二补二进制表示中最高(“最左”)位之前的零位数。
然后定义一个局部变量chars,它的值是前面算出来的mag和4通过后面的式子计算出来的值。
然后定义一个char数组buf,其大小就是chars。
然后以hash码,4,buf,0,chars作为参数执行formatUnsignedInt方法:
这个方法用于将一个长字符(视为无符号)格式化到字符缓冲区中
static int formatUnsignedInt(int val, int shift, char[] buf, int offset, int len) {int charPos = len;int radix = 1 << shift;int mask = radix - 1;do {buf[offset + --charPos] = Integer.digits[val & mask];val >>>= shift;} while (val != 0 && charPos > 0);return charPos;
}
所以这个方法主要会给buf进行赋值。
最后返回以buf为内容的字符串对象打印出来也就是hash码的16进制表示。
4. 整型转二进制
说到整型转16进制,下面我们来了解下整型如何转二进制:
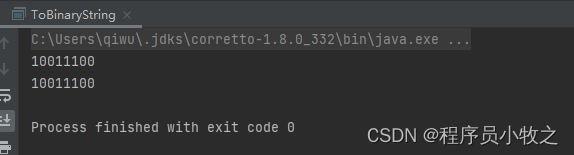
public static void main(String[] args) {byte a = -100;byte b = 100;//算法1String bri = Integer.toBinaryString((a & 0xFF) + 0x100).substring(1);//算法2,负数的二进制为正数的反码+1String bri1 = Integer.toBinaryString(~b+1);System.out.println(bri1.substring(bri1.length()-8));System.out.println(bri);
}
对于正数,我们可以直接调用Integer.toBinaryString(int n),但是对于负数,它得出的结果是错误的。
那么我们如何去得到一个负数的二进制表示呢? 实际上我们只要知道负数的二进制存储形式是:
对应正数的反码+1 , 然后根据这个规则进行计算即可。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!