假期的学习记录
自己的一点学习(try)
pycharm 如何程序运行后,查看变量值
在菜单栏里,选择项目的下拉菜单里选择 Edit Configuration,在对应项目的设置里勾选上 Show command line afterward。就OK了。程序执行后会保持在 python shell 的状态,可以对程序中的数据进行调试。
原网址
小知识
- raw_input 与 input 的区别:
这两个函数都可以读取用户的输入,不同的是input()函数要求用户输入有效的表达式,而raw_input()函数将用户输入的任意类型数据都转换为一个字符串,如果需要输入字母必须使用raw_input. - 用三个“'”可以注释掉一段代码
- 输出一个数字跟在文字后面:
print 'my age is '+ str(21)- 输出一个数字跟在文字后面:
print 'my age is '+ str(21)- join的格式有些奇怪,它不是list的方法,而是字符串的方法。首先你需要有一个字符串作为list中所有元素的连接符,然后再调用这个连接符的join方法,join的参数是被连接的list:
s = ';'
li = ['apple', 'pear', 'orange']
fruit = s.join(li)
print fruit得到结果
'apple;pear;orange'。
从结果可以看到,分号把list中的几个字符串都连接了起来。
你也可以直接在shell中输入:
';'.join(['apple', 'pear', 'orange'])';'也可以换成空格
得到同样的结果。
6.读入文件的操作
f = file('python.txt')
data = f.read()
print data
f.close()7.写入文件的操作
data = 'i\'m xuzhian'
out = open('python.txt', 'w')
out.write(data)
out.close()w:会覆盖文件中原有的内容,当文件不存在时,会新建一个新的文件
a:append,向原文件中添加,不会覆盖。
8.OS X 中查看python的版本,在terminal中输入 python 指令,即可查看安装的版本
9.删除元素的方法:
(1)del.a[0]
(2)a.pop(),相当于弹出队尾元素,删除这个元素,但仍能访问该值。3:根据值删除元素 :a.remove('xxxxx')
10.如果想使用sort(永久排序,用soted(a)进行临时排序)进行倒序排序:
a.sort(reverse=Ture)(reverse:反转)
11.列表解析会缩短代码的行数:
eg:
squres=[]
for value in range(1,11):square=value**2squres.append(square)squares=[value**2 for value in range(1,11)]都会打印出一到十一的平方数
- 传递任意数量的实参:
def make_pizza(*toppings):for topping in toppings:print ('_'+topping)
make_pizza('zzz','xxxx','zzzz')- 在使用Python编译的时候出现如下错误:
SyntaxError: Non-ASCII character ‘\xe5‘ in file Test1.py on line 8, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details解决方法:python的默认编码文件是用的ASCII码,将文件存成了UTF-8,编译就可以通过。或者在首行加入
#coding=utf-8- csv文件格式是一种通用的电子表格和数据库导入导出格式。
15.python中matplotlib的颜色以及线条控制
16.DPI表示分辨率,指每英寸长度上的点数.
17.绘图 :
import csv
from matplotlib import pyplot as plt
filename='sitka_weather_07-2014.csv'
with open(filename)as f:reader=csv.reader(f)header_row=next(reader)#print header_rowfor index,column_header in enumerate(header_row):print (index,column_header)highs=[]for row in reader:high=int(row[1])highs.append(high)print highsflg=plt.figure(dpi=128,figsize=(10,6))plt.plot(highs,c='red')plt.title("daily high temperatures,july",fontsize=23)plt.xlabel('',fontsize=16)plt.ylabel('F',fontsize=15)plt.tick_params(axis='both',which='major',labelsize=16)plt.show()
为了学习爬虫技术,我打算先学习一下网页的设计,希望能学会一点原理,而不是每次都是敲别人的代码,即使出错也不知道错在哪里。
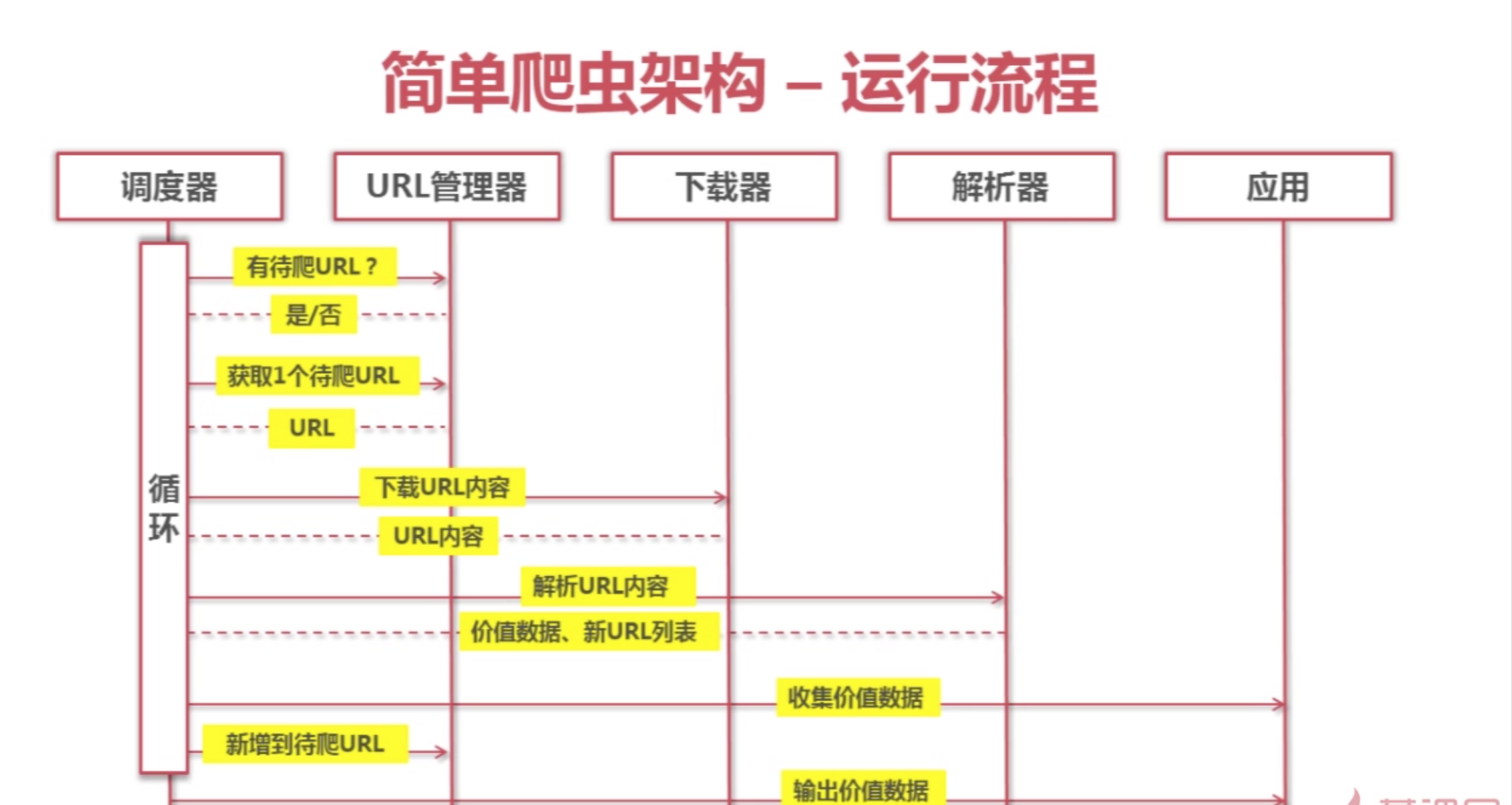
- urlib2下载网页的三种方法:
coding:utf8
import cookielib
import urllib2
url="url="https://www.baidu.com""
print "第一种方法"
respones1=urllib2.urlopen(url)
print respones1.getcode();
print len(respones1.read( ))
print "第二种方法"
request=urllib2.Request(url)
request.add_header("user_agent","Mozilla/5.0")
respones2=urllib2.urlopen(url)
print respones2.getcode();
print len(respones2.read( ))
print "第三种方法"
cj=cookielib.CookieJar()
opener= urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
urllib2.install_opener(opener )
respones3=urllib2.urlopen(url)
print respones3.getcode();
print cj
print len(respones3.read( ))2.网页解析器: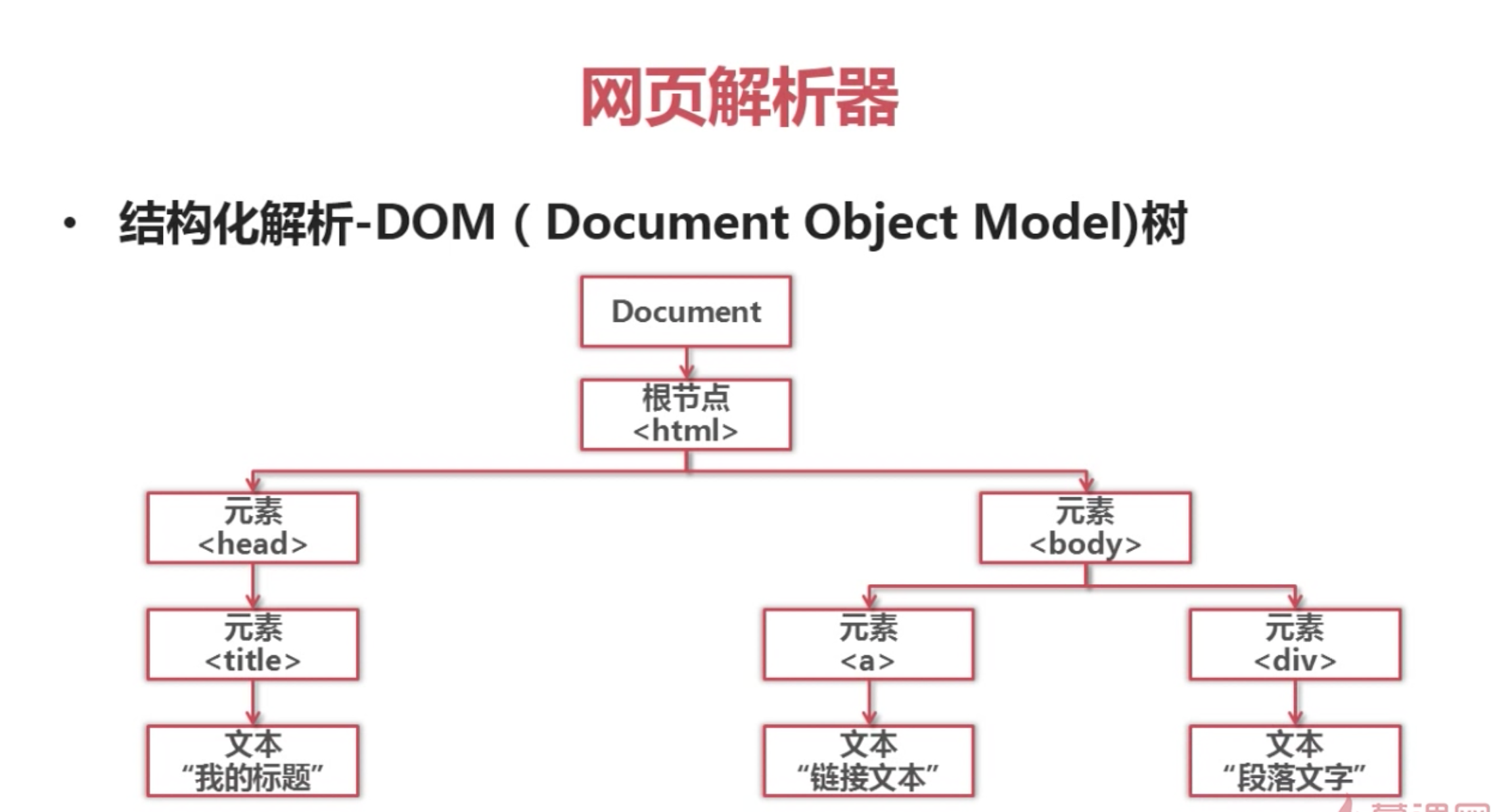
转载于:https://www.cnblogs.com/xzh1996/p/7638517.html
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!