Science封面研究大牛,加盟OpenAI!顶会论文奖拿到手软的那种。。。。。。
来源:量子位
OpenAI被爆最新人事动向:
前FAIR(Meta)研究科学家Noam Brown加盟!
这位大佬来头可不小,研究曾登上《Science》封面。

不仅如此,他此前的研究成果可谓相当炸裂,可以用一句话来总结:
NeurIPS、AAAI等众多顶会论文奖拿到手软!
就是这样一位传奇人物,加入OpenAI后他对自己要做的事放出狠话:
如果成功,我们或许会看到比GPT-4好1000倍的大语言模型。

所以,他之前拿下过什么成就,下一步又究竟要做什么?
德扑AI之父!拿奖拿到手软
Noam Brown与AI结缘,要从他的一篇博士论文说起。
三年前,Noam Brown从卡内基梅隆大学(CMU)以230页超硬核论文完成答辩,拿下计算机科学博士学位。

这篇论文,写的正是Noam Brown与其CMU导师Tuomas Sandholm一起创建的AI系统——称霸德州扑克赛场的赌神Libratus(冷扑大师)和Pluribus。
与围棋、国际象棋、跳棋等棋类游戏不同,这些游戏属于完美信息博弈,对战的双方,清楚每一时刻局面上的全部情况。
而相比之下,德州扑克存在大量的隐藏信息,包括:对手持有什么牌,对手是否在诈唬?
这也就决定了德扑的一个主要特征——不完美博弈。
为此,Noam Brown创建的Libratus将三个负责开发扑克策略、实时优化策略、比赛结束后审查牌局的AI系统结合了起来。
2017年年初,在宾夕法尼亚州匹兹堡的Rivers赌场上,4名顶尖人类职业玩家和Libratus在为期 20 天的赛程里面对战12万手,Libratus一路以碾压的态势豪取胜利,赢得176万美元(虚拟货币)。
和AlphaGo不同,在人机大战之前Libratus没有研究过人类如何打德州扑克,也没有和人类职业玩家有过交手。
但Libratus对战四位人类高手还是拿下了大比分优势:14.7个大盲注/百手(14.7bb/h)。
“一般领先5-10bb/h就肯定是赢了”,Noam Brown表示。
德扑AI不仅取得了这场比赛的胜利,Pluribus还在那年登顶了《Science》封面。
与此相关的研究,目前也已有近700的引用量。
当然,Libratus不是凭空而生,2015年4月它的前身Claudico正是在同一个赌场里,和四位人类顶级玩家交锋8万手后,累积输掉73.2万美元(当然也是虚拟货币),败给了人类。
Noam Brown多年来在多步骤推理、自我对战和多智能体AI方面的研究,终于以Libratus的成功交上了一份满意的答卷,并在此之后,包揽众多大奖。
比赛胜利同年,他获得了NeurIPS 2017最佳论文奖。2019年又继续与导师合作,成功拿下AAAI 2019Honorable Mention奖。
之后Noam Brown的一系列成果获得了《Science》2019年年度突破的亚军、马文·明斯基奖,还被评为《MIT科技评论》35岁以下35位创新者之一。
此前获得过这个称号的,就包括谷歌创始人Larry Page、Sergey Brin,Facebook创始人Mark Zuckerberg,Paypal及Slide创始人Max Levchin,还有著名人工智能科学家吴恩达等一众大佬。
但是不管Libratus距离扑克之神还有多远,Brown坦言他不会再对这个德扑AI进行优化了。
博士毕业后,Noam Brown加入了FAIR(Meta),成为其研究科学家。
在Meta,他曾参与共同开发出第一个在战略游戏Diplomacy中达到人类水平的AI——CICERO。

一切看起来顺风顺水,Noam Brown为什么突然要转战OpenAI,又究竟要做什么?
加入OpenAI后:用游戏中的方法提升大模型
Noam Brown给出了他的答案:
多年来,一直在研究扑克和Diplomacy等游戏中的AI自我对战和推理。现在,我将研究如何将这些方法真正通用化。
所以,下一个大模型难道将借鉴游戏中的方法?
其实,Noam Brown的灵感来自于当年Libratus成功击败了顶级人类选手时,他所观察到的一种现象。
而这种现象与2016年AlphaGo击败李世石极为相似。
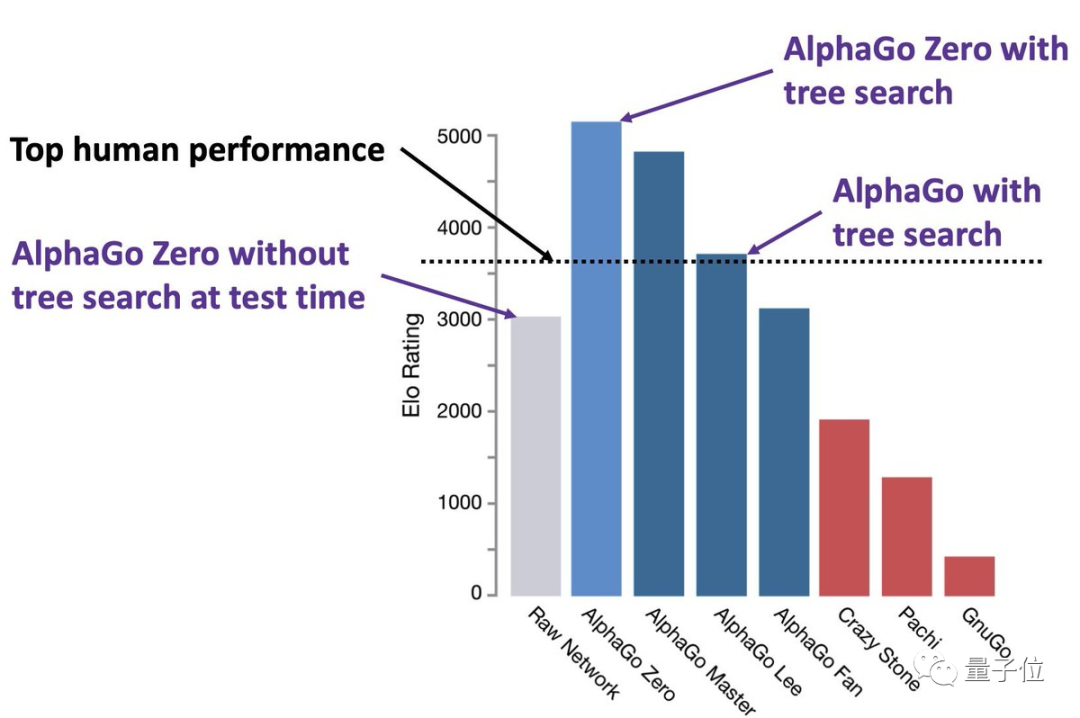
回想AlphaGo击败李世石,其中的关键在于:
AI在每一步棋之前都能够进行约1分钟的“思考”。
而就这一点对于AlphaGoZero来说,相当于将预训练的规模扩大了约10万倍(搜索后评分约为5200 Elo,不经搜索评分约为3000 Elo)。
Noam Brown在扑克中观察到了类似的现象,将其运用于Libratus,才有了后面的成功击败顶级人类选手。
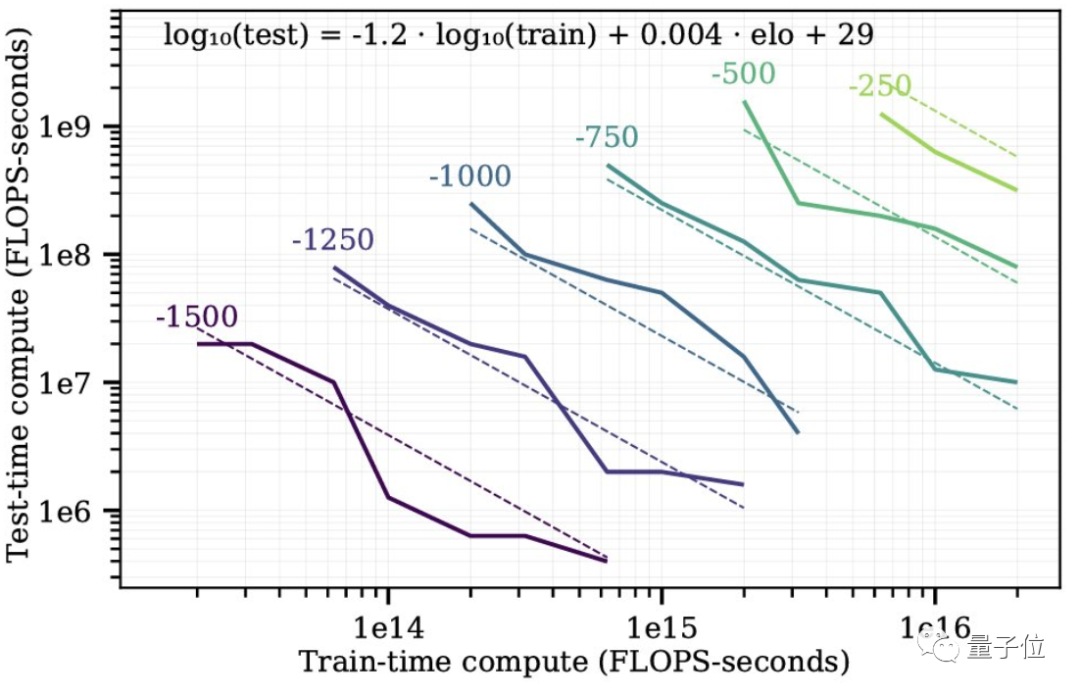
除此之外,AnthropicAI的技术工程师Andy L. Jones,在Hex棋盘游戏中详细研究了训练时间和测试时间的计算权衡,也发现了类似的模式。

这项研究展示了如何在MCTS(Monte Carlo Tree Search,蒙特卡洛树搜索)的训练计算和推理计算之间进行权衡,而增加10倍的MCTS步骤几乎等同于增加10倍的训练:
Noam Brown认为:
现在所有这些方法都是针对特定的游戏而设计的。如果我们能够发现一个通用版本,那么增益将是巨大的。
虽然推理可能会慢1000倍,并且成本更高,但是与为了一种新的抗癌药物或者为了证明黎曼猜想一样,我们会为推理付出怎样的代价呢?

接着他又补充道:
提升能力总是存在风险的,但如果这项研究取得成功,它在安全研究方面也将具有重要价值。想象一下,如果我们能够花费100万美元的推理成本来预测一个更具能力的未来模型,这将给我们一个此前所没有的警示。

对于Noam Brown加入OpenAI这事儿,评论区赶来的大多是来道喜的。
比如说PyTorch联合创始人Soumith Chintala:
前同事Meta AI研究总监、佐治亚理工学院计算机科学家Dhruv Batra也发来了“贺电”:
参考链接:
[1]https://twitter.com/polynoamial/status/1676971503261454340
[2]https://noambrown.github.io/
[3]https://www.science.org/toc/science/365/6456
推荐阅读
西电IEEE Fellow团队出品!最新《Transformer视觉表征学习全面综述》
润了!大龄码农从北京到荷兰的躺平生活(文末有福利哟!)
如何做好科研?这份《科研阅读、写作与报告》PPT,手把手教你做科研
奖金675万!3位科学家,斩获“中国诺贝尔奖”!
又一名视觉大牛从大厂离开!阿里达摩院 XR 实验室负责人谭平离职
最新 2022「深度学习视觉注意力 」研究概述,包括50种注意力机制和方法!
【重磅】斯坦福李飞飞《注意力与Transformer》总结,84页ppt开放下载!
2021李宏毅老师最新40节机器学习课程!附课件+视频资料
欢迎大家加入DLer-计算机视觉技术交流群!
大家好,群里会第一时间发布计算机视觉方向的前沿论文解读和交流分享,主要方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

👆 长按识别,邀请您进群!

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!