Lucene Solr 811
文章目录
- solr
- lucene
- 倒排索引
- 实际举例
- lucene API 介绍
- 创建索引
- 新建 maven 项目,添加依赖
- 创建测试类,添加以下代码
- 查看索引
- 运行 luke
- 查看文档
- 指定分词器,并测试分词
- 查询测试
- 从索引查询
- solr 安装
- 把 solr-8.1.1.tgz 传到服务器
- 解压 solr
- 启动 solr
- 浏览器访问 solr 控制台
- 创建 core
- 复制默认配置
- 创建名为 pd 的 core
- 中文分词测试
- 中文分词工具 - ik-analyzer
- 使用 ik-analyzer 对中文进行分词测试
- 设置停止词
- 准备 mysql 数据库数据
- 从 mysql 导入商品数据
- 设置字段
- Copy Field 副本字段
- Data Import Handler 配置
- 导入数据
- 查询测试
- 在复制字段 `_text_` 中查找 `电脑`
- 在标题中查找 `电脑`
- 用双引号查找完整词 `"笔记本"`
- 搜索 `+lenovo +电脑`
- 搜索 `+lenovo -电脑`
- 统计 cid
- 价格范围
- 多字段统计
- 拼多商城实现商品的全文检索
- 修改 hosts 文件, 添加 www.pd.com 映射
- eclipse 导入 pd-web 项目
- 修改数据库连接配置
- 启动项目, 访问 www.pd.com
- 商品检索调用分析
- pom.xml 添加 solr 和 lombok 依赖
- application.yml 添加 solr 连接信息
- Item 实体类
- SearchService 业务接口
- SearchServiceImpl 业务实现类
- SearchController 控制器
solr
Solr是一个高性能,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
lucene
Lucene是apache jakarta项目的一个子项目,是一个开放源代码的全文检索引擎开发工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
倒排索引
我们一般情况下,先找到文档,再在文档中找出包含的词;
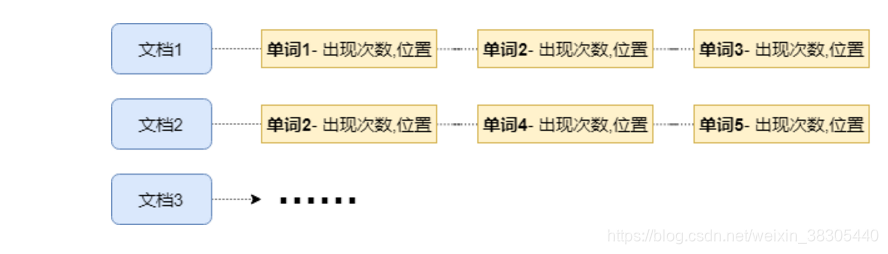
倒排索引则是这个过程反过来,用词,来找出它出现的文档.
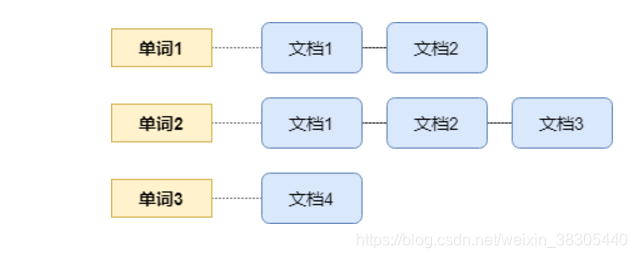
实际举例
| 文档编号 | 文档内容 |
|---|---|
| 1 | 全文检索引擎工具包 |
| 2 | 全文检索引擎的架构 |
| 3 | 查询引擎和索引引擎 |
分词结果
| 文档编号 | 分词结果集 |
|---|---|
| 1 | {全文,检索,引擎,工具,包} |
| 2 | {全文,检索,引擎,的,架构} |
| 3 | {查询,引擎,和,索引,引擎} |
倒排索引
| 编号 | 单词 | 文档编号列表 |
|---|---|---|
| 1 | 全文 | 1,2 |
| 2 | 检索 | 1,2 |
| 3 | 引擎 | 1,2,3 |
| 4 | 工具 | 1 |
| 5 | 包 | 1 |
| 6 | 架构 | 2 |
| 7 | 查询 | 3 |
| 8 | 索引 | 3 |
lucene API 介绍
创建索引
新建 maven 项目,添加依赖
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0modelVersion><groupId>cn.tedugroupId><artifactId>lucene-demoartifactId><version>0.0.1-SNAPSHOTversion><name>luceme-demoname><dependencies><dependency><groupId>org.apache.lucenegroupId><artifactId>lucene-coreartifactId><version>8.1.1version>dependency><dependency><groupId>junitgroupId><artifactId>junitartifactId><version>4.12version>dependency><dependency><groupId>org.apache.lucenegroupId><artifactId>lucene-analyzers-smartcnartifactId><version>8.1.1version>dependency>dependencies><build><plugins><plugin><groupId>org.apache.maven.pluginsgroupId><artifactId>maven-compiler-pluginartifactId><version>3.8.0version><configuration><source>1.8source><target>1.8target>configuration>plugin>plugins>build>
project>
创建测试类,添加以下代码
package test;import java.io.File;import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.LongPoint;
import org.apache.lucene.document.StoredField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test;public class Test1 {String[] a = {"3, 华为 - 华为电脑, 爆款","4, 华为手机, 旗舰","5, 联想 - Thinkpad, 商务本","6, 联想手机, 自拍神器"};@Testpublic void test1() throws Exception {//存储索引文件的路径File path = new File("d:/abc/");FSDirectory d = FSDirectory.open(path.toPath());//lucene提供的中文分词器SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer();//通过配置对象来指定分词器IndexWriterConfig cfg = new IndexWriterConfig(analyzer);//索引输出工具IndexWriter writer = new IndexWriter(d, cfg);for (int i = 0; i < a.length; i++) {String[] strs = a[i].split(",");//创建文档,文档中包含的是要索引的字段Document doc = new Document();doc.add(new LongPoint("id", Long.parseLong(strs[0])));doc.add(new StoredField("id", Long.parseLong(strs[0])));doc.add(new TextField("title", strs[1], Store.YES));doc.add(new TextField("sellPoint", strs[2], Store.YES));//将文档写入磁盘索引文件writer.addDocument(doc);}writer.close();}}
查看索引
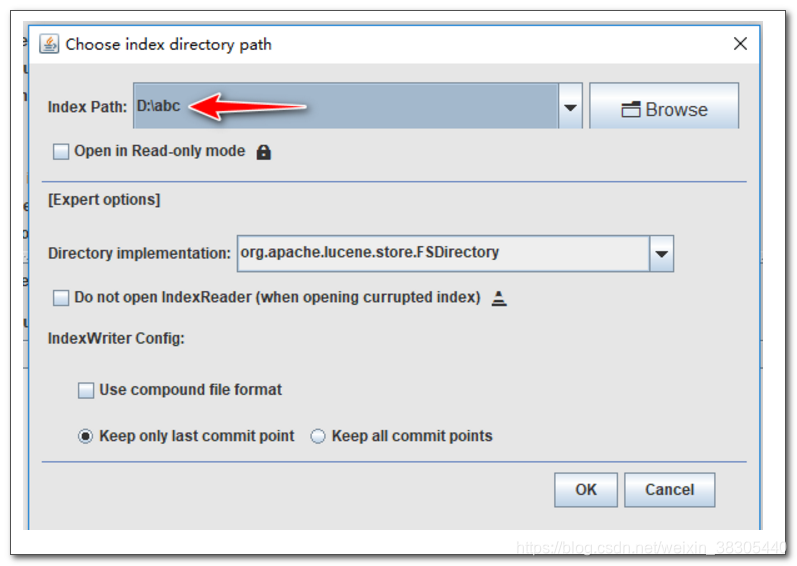
运行 luke
运行lucene 8.1.1中的luke应用程序,指定索引的存放目录
查看文档
指定分词器,并测试分词
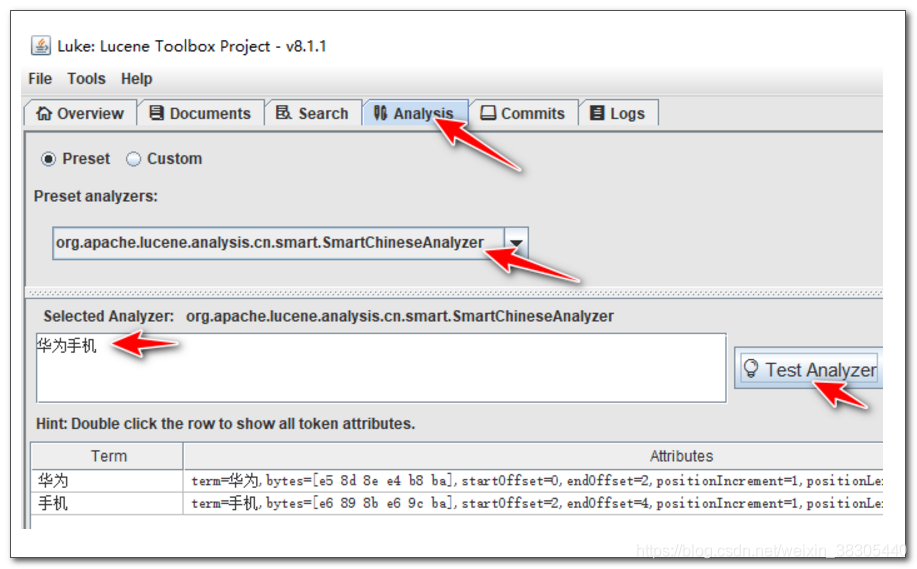
查询测试
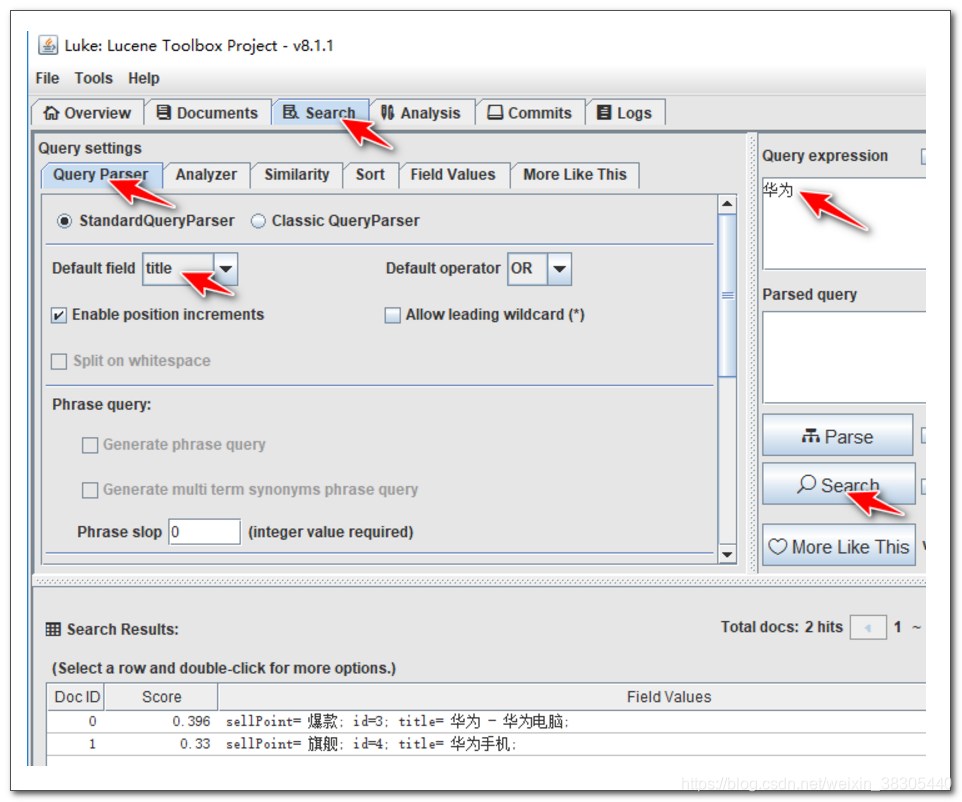
- id的查询
从索引查询
在测试类中添加 test2() 测试方法
package test;import java.io.File;import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.LongPoint;
import org.apache.lucene.document.StoredField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test;public class Test1 {String[] a = {"3, 华为 - 华为电脑, 爆款","4, 华为手机, 旗舰","5, 联想 - Thinkpad, 商务本","6, 联想手机, 自拍神器"};@Testpublic void test1() throws Exception {//存储索引文件的路径File path = new File("d:/abc/");FSDirectory d = FSDirectory.open(path.toPath());//lucene提供的中文分词器SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer();//通过配置对象来指定分词器IndexWriterConfig cfg = new IndexWriterConfig(analyzer);//索引输出工具IndexWriter writer = new IndexWriter(d, cfg);for (int i = 0; i < a.length; i++) {String[] strs = a[i].split(",");//创建文档,文档中包含的是要索引的字段Document doc = new Document();doc.add(new LongPoint("id", Long.parseLong(strs[0])));doc.add(new StoredField("id", Long.parseLong(strs[0])));doc.add(new TextField("title", strs[1], Store.YES));doc.add(new TextField("sellPoint", strs[2], Store.YES));//将文档写入磁盘索引文件writer.addDocument(doc);}writer.close();}@Testpublic void test2() throws Exception {//索引数据的保存目录File path = new File("d:/abc");FSDirectory d = FSDirectory.open(path.toPath());//创建搜索工具对象DirectoryReader reader = DirectoryReader.open(d);IndexSearcher searcher = new IndexSearcher(reader);//关键词搜索器,我们搜索 "title:华为"TermQuery q = new TermQuery(new Term("title", "华为"));//执行查询,并返回前20条数据TopDocs docs = searcher.search(q, 20);//遍历查询到的结果文档并显示for (ScoreDoc scoreDoc : docs.scoreDocs) {Document doc = searcher.doc(scoreDoc.doc);System.out.println(doc.get("id"));System.out.println(doc.get("title"));System.out.println(doc.get("sellPoint"));System.out.println("--------------");}}}solr 安装
下面我们来安装 solr 服务器
把 solr-8.1.1.tgz 传到服务器
先切换到 /usr/local 目录
cd /usr/local
把文件传到 /usr/local 目录下
解压 solr
cd /usr/local# 上传 solr-8.1.1.tgz 到 /usr/local 目录
# 并解压缩
tar -xzf solr-8.1.1.tgz
启动 solr
cd /usr/local/solr-8.1.1# 不建议使用管理员启动 solr,加 -force 强制启动
bin/solr start -force# 开放 8983 端口
firewall-cmd --zone=public --add-port=8983/tcp --permanent
firewall-cmd --reload
浏览器访问 solr 控制台
http://192.168.64.170:8983
- 注意修改地址
创建 core
数据库中 pd_item 表中的商品数据, 在 solr 中保存索引数据, 一类数据, 在 solr 中创建一个 core 保存索引数据
创建一个名为 pd 的 core, 首先要准备以下目录结构:
# solr目录/server/solr/
# pd/
# conf/
# data/cd /usr/local/solr-8.1.1mkdir server/solr/pd
mkdir server/solr/pd/conf
mkdir server/solr/pd/data
conf 目录是 core 的配置目录, 存储一组配置文件, 我们以默认配置为基础, 后续逐步修改
复制默认配置
cd /usr/local/solr-8.1.1cp -r server/solr/configsets/_default/conf server/solr/pd
创建名为 pd 的 core
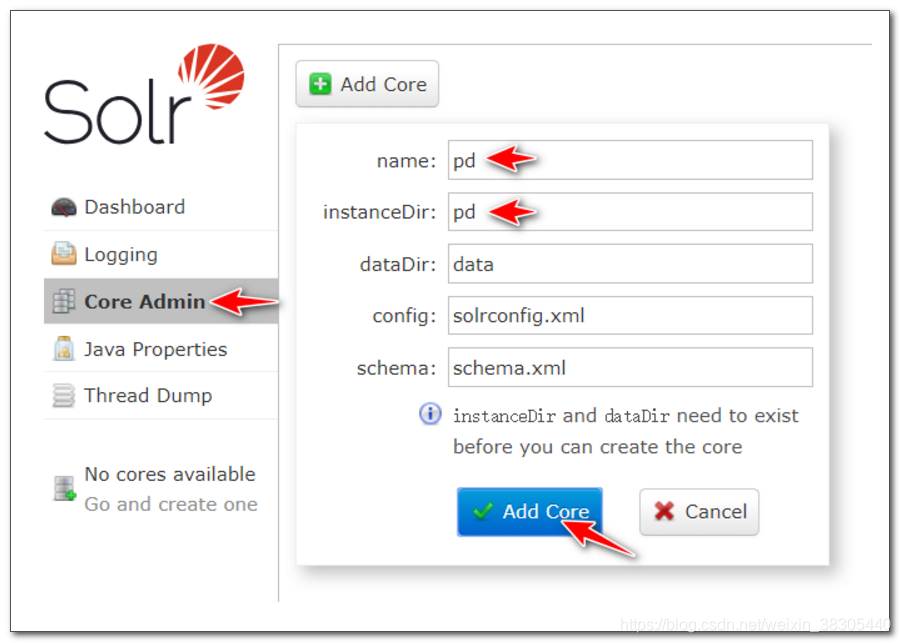
中文分词测试
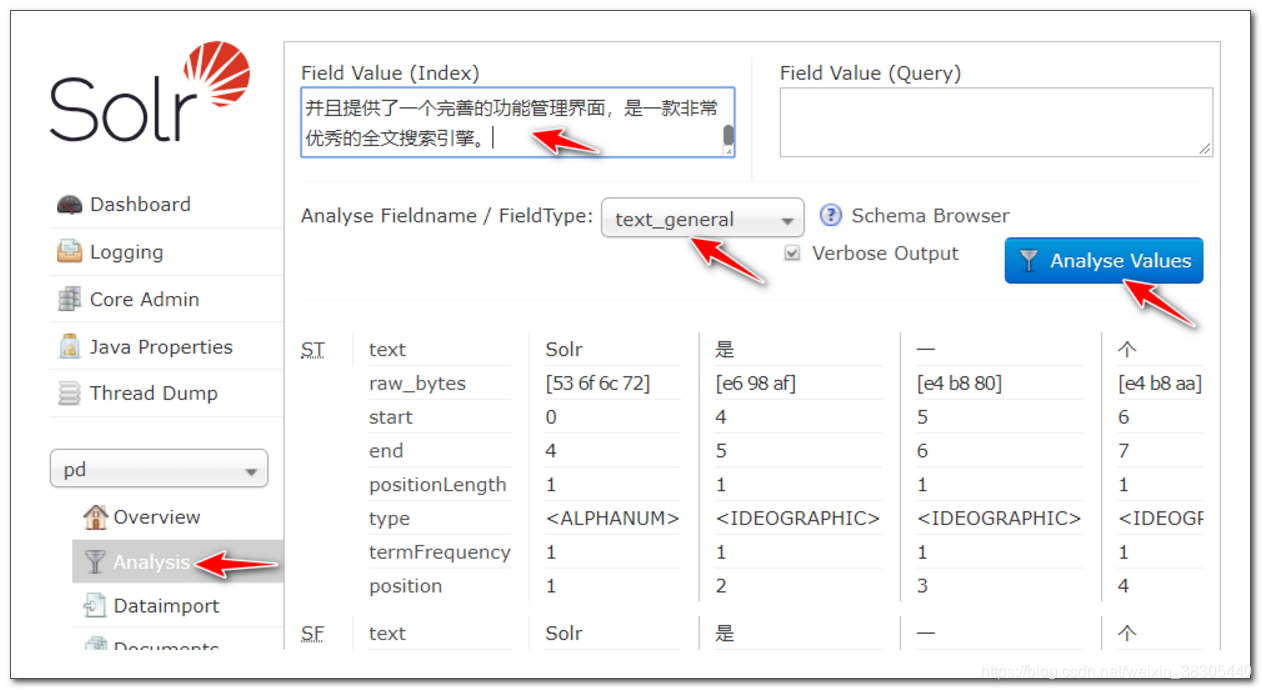
填入以下文本, 观察分词结果:
Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
中文分词工具 - ik-analyzer
https://github.com/magese/ik-analyzer-solr
-
下载 ik-analyzer 分词 jar 文件,传到
solr目录/server/solr-webapp/webapp/WEB-INF/lib- 为了后续操作方便,我们把后面用到的jar文件一同传到服务器,包括四个文件:
- ik-analyzer-8.1.0.jar
- mysql-connector-java-5.1.46.jar
- solr-dataimporthandler-8.1.1.jar
- solr-dataimporthandler-extras-8.1.1.jar
- 为了后续操作方便,我们把后面用到的jar文件一同传到服务器,包括四个文件:
-
复制6个文件到
solr目录/server/solr-webapp/webapp/WEB-INF/classes
# classes目录如果不存在,需要创建该目录
mkdir /usr/local/solr-8.1.1/server/solr-webapp/webapp/WEB-INF/classes
这6个文件复制到 classes 目录下
resources/IKAnalyzer.cfg.xmlext.dicstopword.dicstopwords.txtik.confdynamicdic.txt
- 配置 managed-schema
修改 solr目录/server/solr/pd/conf/managed-schema,添加 ik-analyzer 分词器
- 重启 solr 服务
cd /usr/local/solr-8.1.1bin/solr restart -force
使用 ik-analyzer 对中文进行分词测试
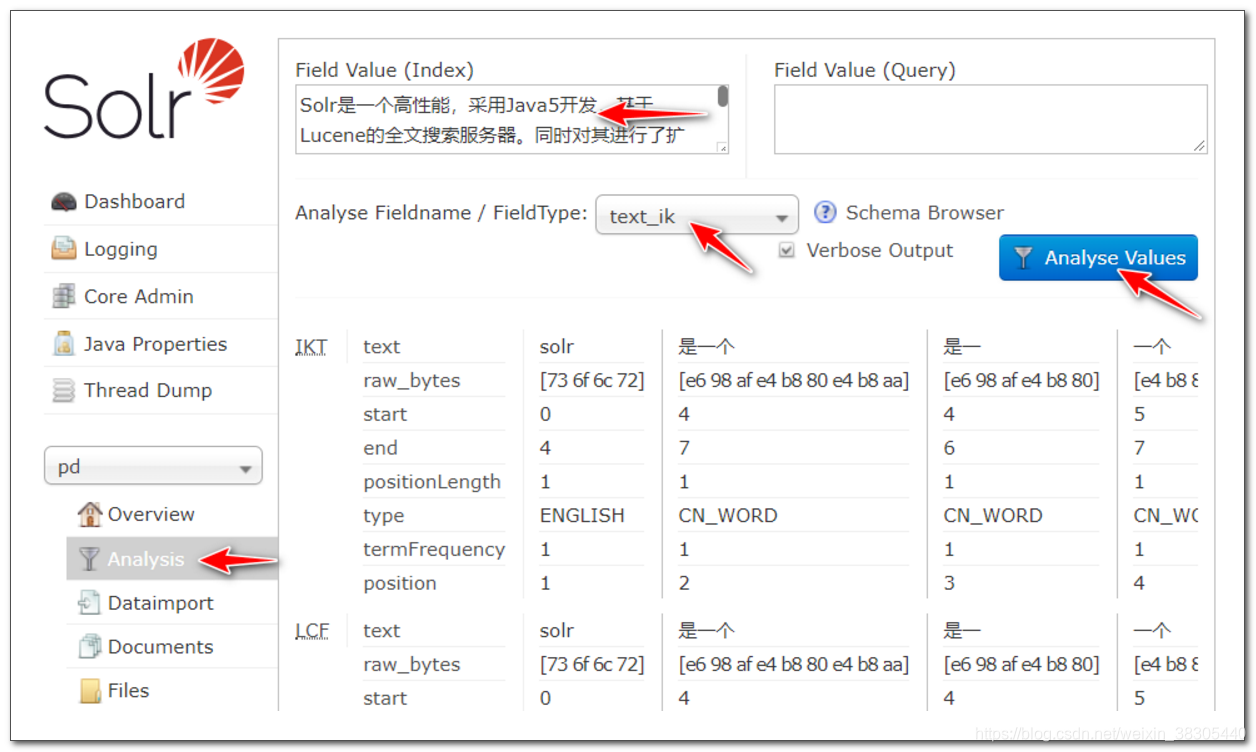
填入以下文本, 选择使用 text_ik 分词器, 观察分词结果:
Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
设置停止词
上传停止词配置文件到 solr目录/server/solr-webapp/webapp/WEB-INF/classes
stopword.dic
stopwords.txt
- 重启服务,观察分词结果中,停止词被忽略
bin/solr restart -force
准备 mysql 数据库数据
- 用 sqlyog 执行 pd.sql
- 授予 root 用户 跨网络访问权限
注意: 此处设置的是远程登录的 root 用户,本机登录的 root 用户密码不变
CREATE USER 'root'@'%' IDENTIFIED BY 'root';GRANT ALL ON *.* TO 'root'@'%';
随机修改30%的商品,让商品下架,以便后面做查询测试
UPDATE pd_item SET STATUS=0 WHERE RAND()<0.3
从 mysql 导入商品数据
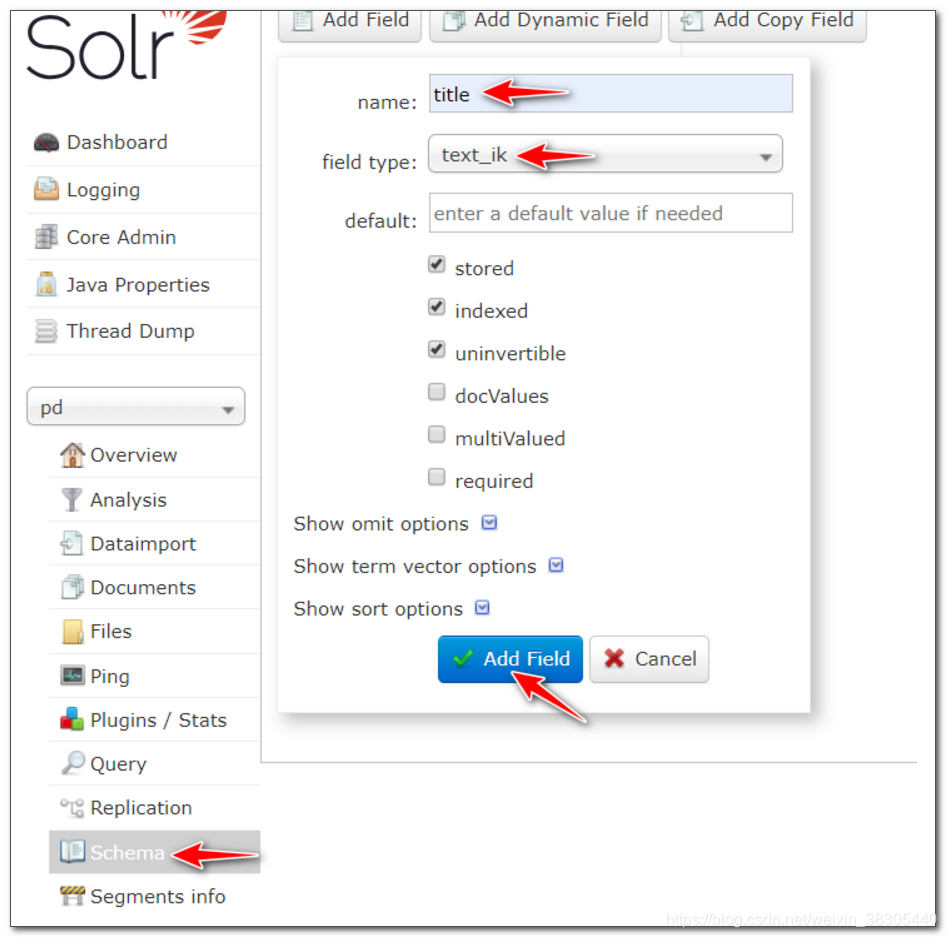
设置字段
- title
text_ik - sellPoint
text_ik - price
plong - barcode
string - image
string - cid
plong - status
pint - created
pdate - updated
pdate
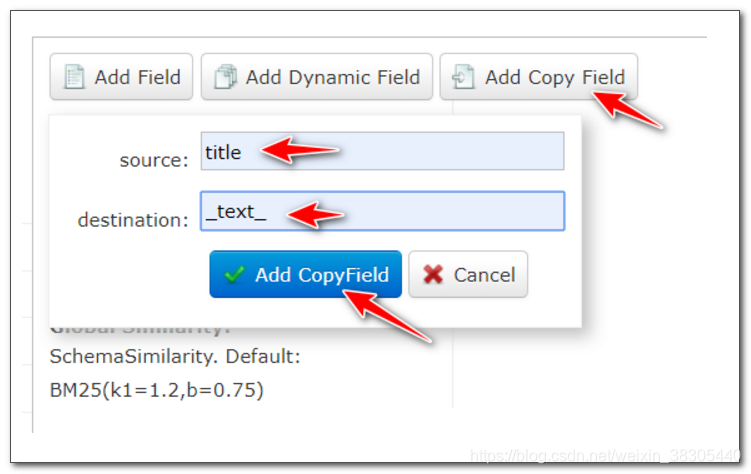
Copy Field 副本字段
查询时需要按字段查询,例如 title:电脑, 可以将多个字段的值合并到一个字段进行查询,默认查询字段 _text_
将 title 和 sellPoint 复制到 _text_ 字段
Data Import Handler 配置
- 添加 jar 文件
Data Import Handler 的 jar 文件存放在 solr目录/dist 目录下
solr-dataimporthandler-8.1.1.jar
solr-dataimporthandler-extras-8.1.1.jar
复制这两个文件和 mysql 的 jar 文件到 solr目录/server/solr-webapp/webapp/WEB-INF/lib
-
dih-config.xml
修改 mysql 的 ip 地址,传到
solr目录/server/solr/pd/conf -
solrconfig.xml 中添加 DIH 配置
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"><lst name="defaults"> <str name="config">dih-config.xmlstr> lst>
requestHandler>
- 重启 solr
cd /usr/local/solr-8.1.1bin/solr restart -force
导入数据
重启 solr 后导入数据,确认导入的文档数量为 3160

查询测试
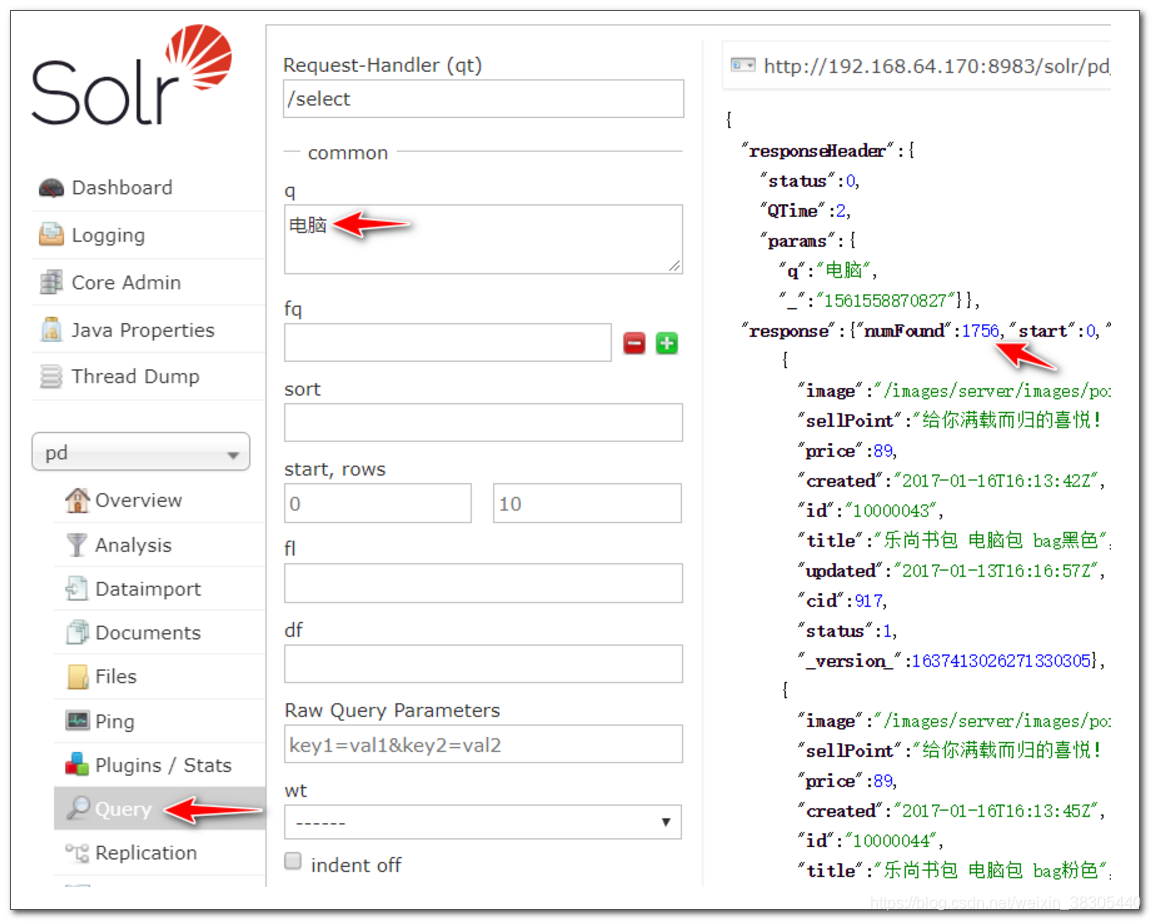
在复制字段 _text_ 中查找 电脑
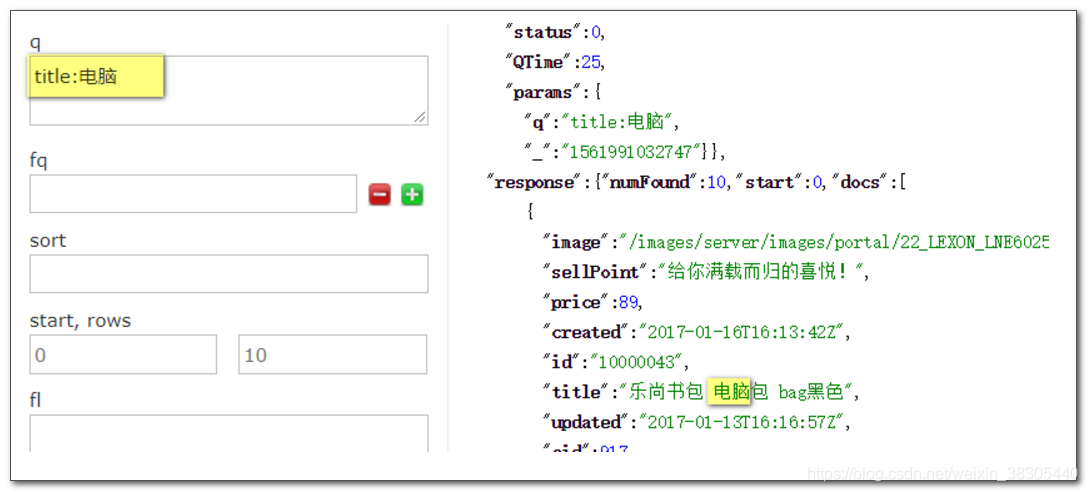
在标题中查找 电脑
用双引号查找完整词 "笔记本"

搜索 +lenovo +电脑
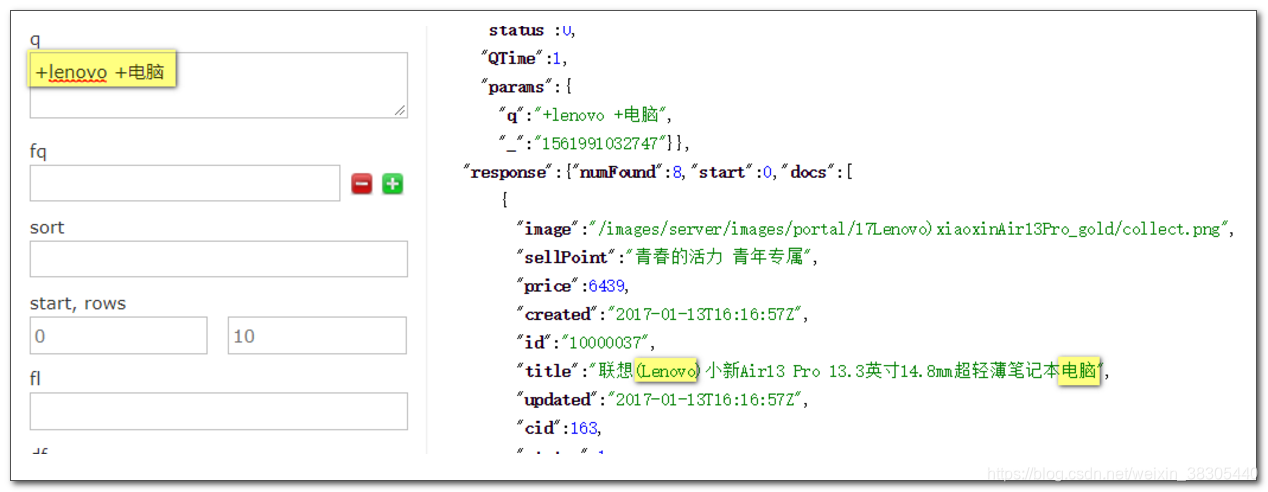
搜索 +lenovo -电脑
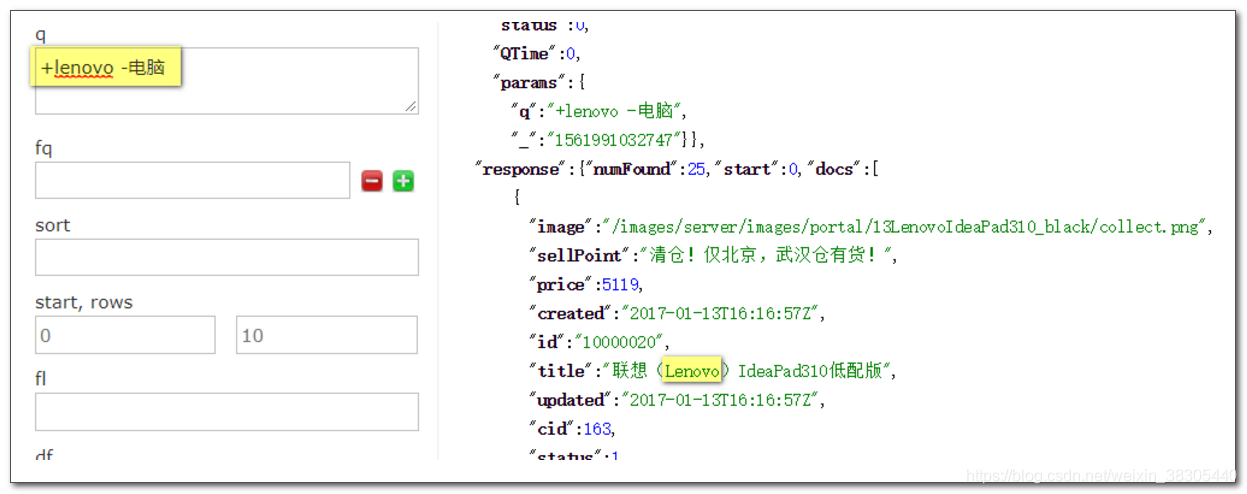
统计 cid
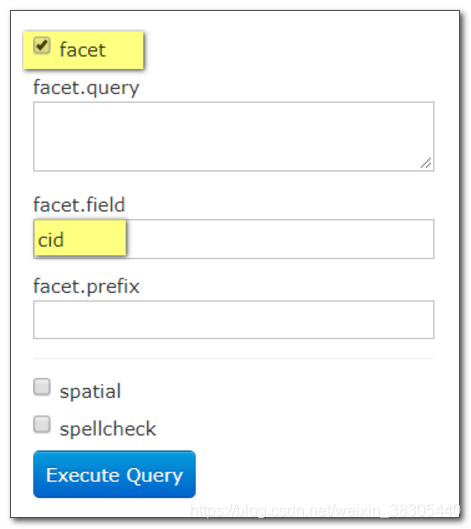
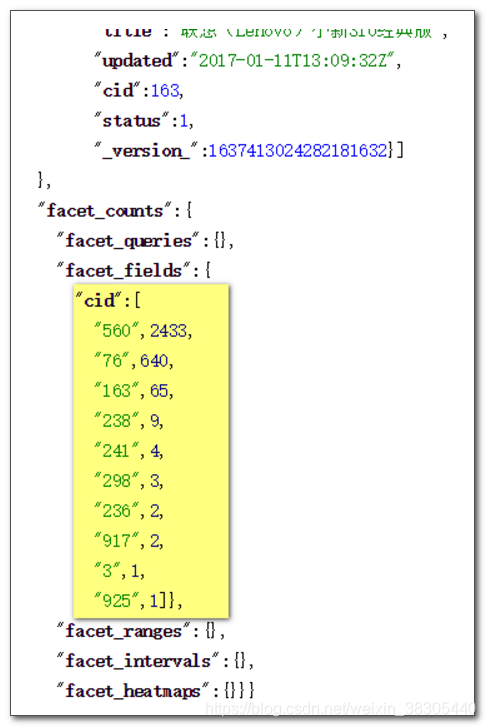
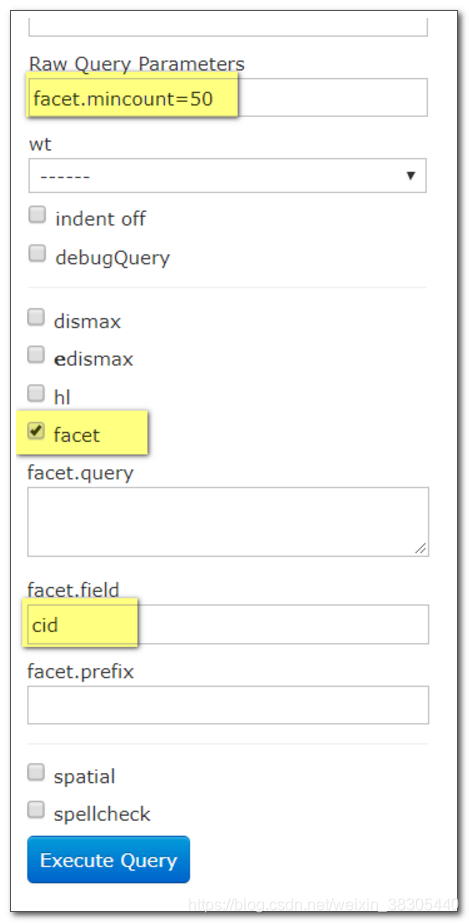
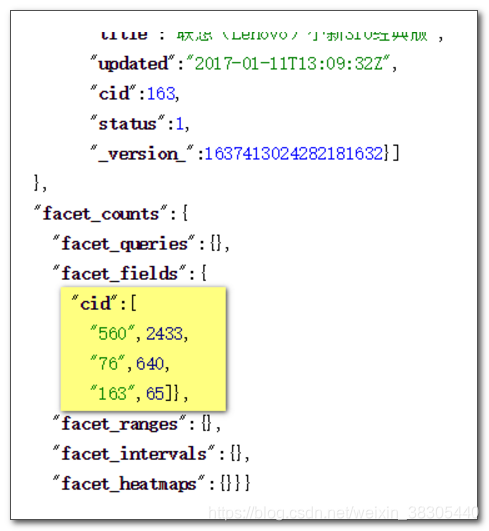
价格范围
在 Raw Query Parameters 输入框中填入以下内容:
facet.range=price&facet.range.start=0&facet.range.end=10000&facet.range.gap=2000
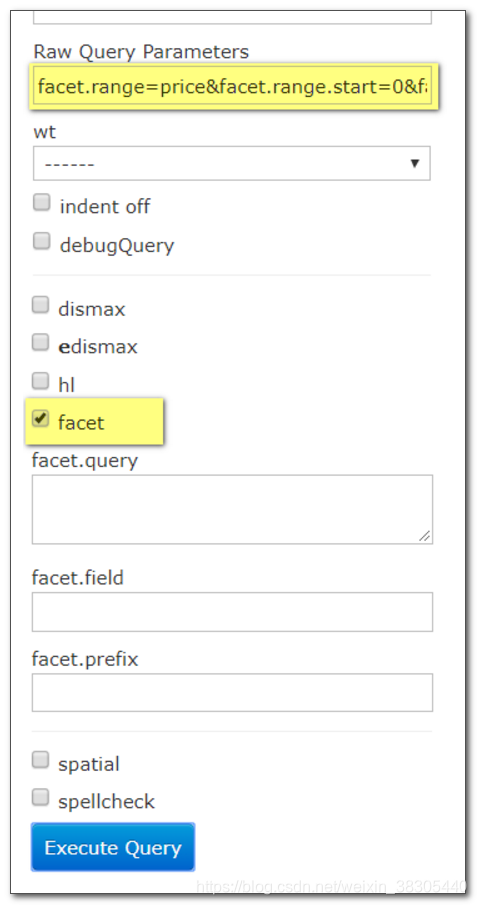
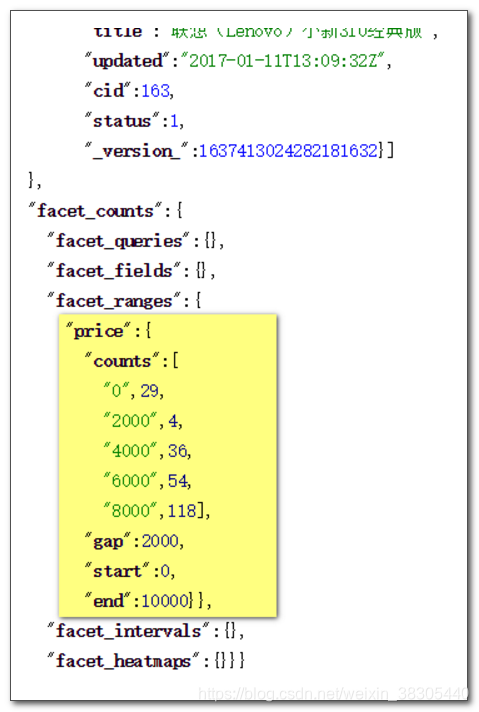
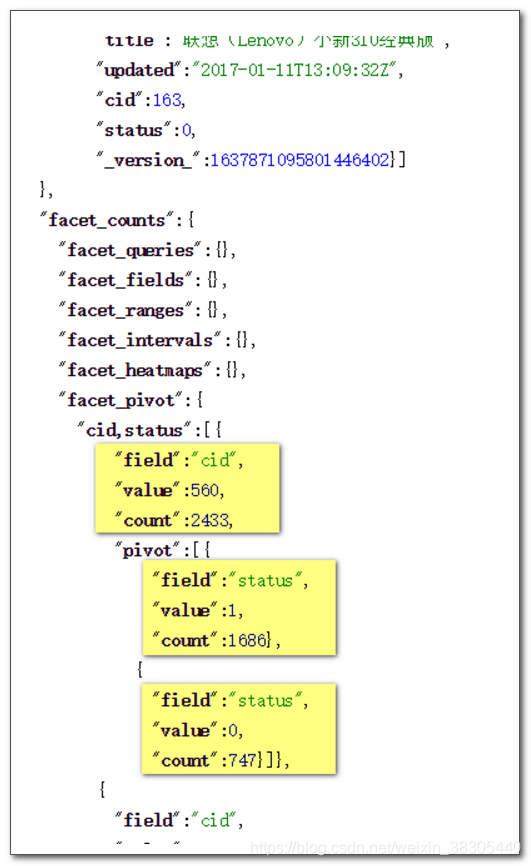
多字段统计
在 Raw Query Parameters 输入框中填入以下内容:
facet.pivot=cid,status

拼多商城实现商品的全文检索
修改 hosts 文件, 添加 www.pd.com 映射
127.0.0.1 www.pd.com
eclipse 导入 pd-web 项目

修改数据库连接配置
application.yml 配置文件中,修改连接配置
spring:datasource:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://127.0.0.1:3306/pd_store?useUnicode=true&characterEncoding=UTF-8username: rootpassword: root
启动项目, 访问 www.pd.com

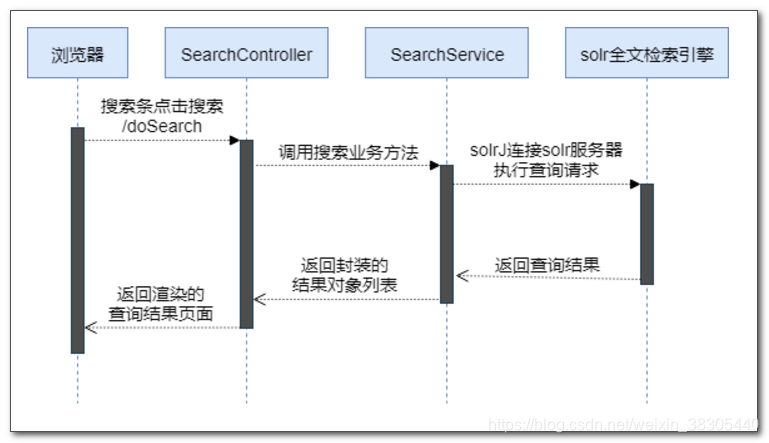
商品检索调用分析
pom.xml 添加 solr 和 lombok 依赖
<dependency><groupId>org.springframework.bootgroupId><artifactId>spring-boot-starter-data-solrartifactId>
dependency><dependency><groupId>org.projectlombokgroupId><artifactId>lombokartifactId>
dependency>
application.yml 添加 solr 连接信息
spring:data:solr: #注意修改ip地址host: http://192.168.64.170:8983/solr/pd
Item 实体类
package com.pd.pojo;import java.io.Serializable;import org.apache.solr.client.solrj.beans.Field;import lombok.Data;@Data
public class Item implements Serializable {private static final long serialVersionUID = 1L;@Field("id")private String id;@Field("title")private String title;@Field("sellPoint")private String sellPoint;@Field("price")private Long price;@Field("image")private String image;}
SearchService 业务接口
package com.pd.service;import java.util.List;import com.pd.pojo.Item;public interface SearchService {List<Item> findItemByKey(String key) throws Exception;
}
SearchServiceImpl 业务实现类
package com.pd.service.impl;import java.util.List;import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import org.springframework.stereotype.Service;import com.pd.pojo.Item;
import com.pd.service.SearchService;@Service
public class SearchServiceImpl implements SearchService {/** SolrClient实例是在 SolrAutoConfiguration 类中创建的* * SolrAutoConfiguration添加了@Configuration注解,* 是spring boot自动配置类,其中的solrClient()方法中创建了SolrClient实例*/@Autowiredprivate SolrClient solrClient;@Overridepublic List<Item> findItemByKey(String key) throws Exception {//封装查询的关键词//也可以封装其他的查询参数,比如指定字段,facet设置等SolrQuery query = new SolrQuery(key);//查询前多少条数据query.setStart(0);query.setRows(20);//执行查询并得到查询结果QueryResponse qr = solrClient.query(query);//把查询结果转成一组商品实例List<Item> beans = qr.getBeans(Item.class);return beans;}}
SearchController 控制器
package com.pd.controller;import java.util.List;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;import com.pd.pojo.Item;
import com.pd.service.SearchService;@Controller
public class SearchController {@Autowiredprivate SearchService searchService;@GetMapping("/search/toSearch.html")public String search(String key, Model model) throws Exception {List<Item> itemList = searchService.findItemByKey(key);model.addAttribute("list", itemList);return "/search.jsp";}
}
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!