chatgpt赋能python:**Python爬虫去除特定的标签以及内容的SEO**
Python爬虫去除特定的标签以及内容的SEO
在进行网站优化时,通常需要去除一些特定的HTML标签或内容。这些HTML标签或内容通常是与SEO不利相关的,例如JavaScript代码、广告代码、一些特定的HTML标签等。Python爬虫可以帮助我们自动地去除这些HTML标签或内容。
介绍
在进行Python爬虫去除特定的标签或内容之前,首先需要了解些HTML标签的基础知识。HTML标签通常分为两类:行内标签和块级标签。行内标签是指只影响其标签内的文本的标签,而块级标签则是具有一定内容含义的一段HTML标记,例如div、ul、li、p等。
在网站优化中,广告、JavaScript代码等内容通常是一个整体块级标签,我们可以使用Python爬虫解析HTML文档,然后使用正则表达式或其他特定的方式去除这些块级HTML标签。
Python爬虫去除特定的标签或内容的方法
- 使用正则表达式
使用正则表达式可以帮助我们快速地匹配特定的HTML标签或内容,进行去除。例如,我们想去除网页上的所有JavaScript代码,可以使用如下代码:
import re# 假设html是已经获取的HTML代码
new_html = re.sub(r'', '', html, flags=re.DOTALL)
在上述代码中,我们使用re.sub函数进行匹配和替换,匹配所有的
- 使用BeautifulSoup库
BeautifulSoup库是Python中比较常用的HTML解析库,它可以帮我们轻松地解析HTML文档,并且可以提取HTML文档中的各种信息。例如,我们想去除网页中所有div标签及其内容,可以使用如下代码:
from bs4 import BeautifulSoup# 假设html是已经获取的HTML代码
soup = BeautifulSoup(html, 'html.parser')
for div in soup.find_all('div'):div.decompose()
new_html = str(soup)
在上述代码中,我们使用BeautifulSoup库的find_all函数查找所有的div标签,然后使用decompose()函数将其标记删除。最后我们将修改后的文档转换成字符串。
结论
在进行网站优化时,去除特定的HTML标签或内容是必不可少的一环。Python爬虫可以帮助我们自动地进行标记清理工作,提高我们的工作效率。在去除特定HTML标签或内容时,我们可以使用正则表达式或BeautifulSoup库,根据不同的需求选择不同的方法。
最后的最后
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。
对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。
🧡AI职场汇报智能办公文案写作效率提升教程 🧡 专注于AI+职场+办公方向。
下图是课程的整体大纲
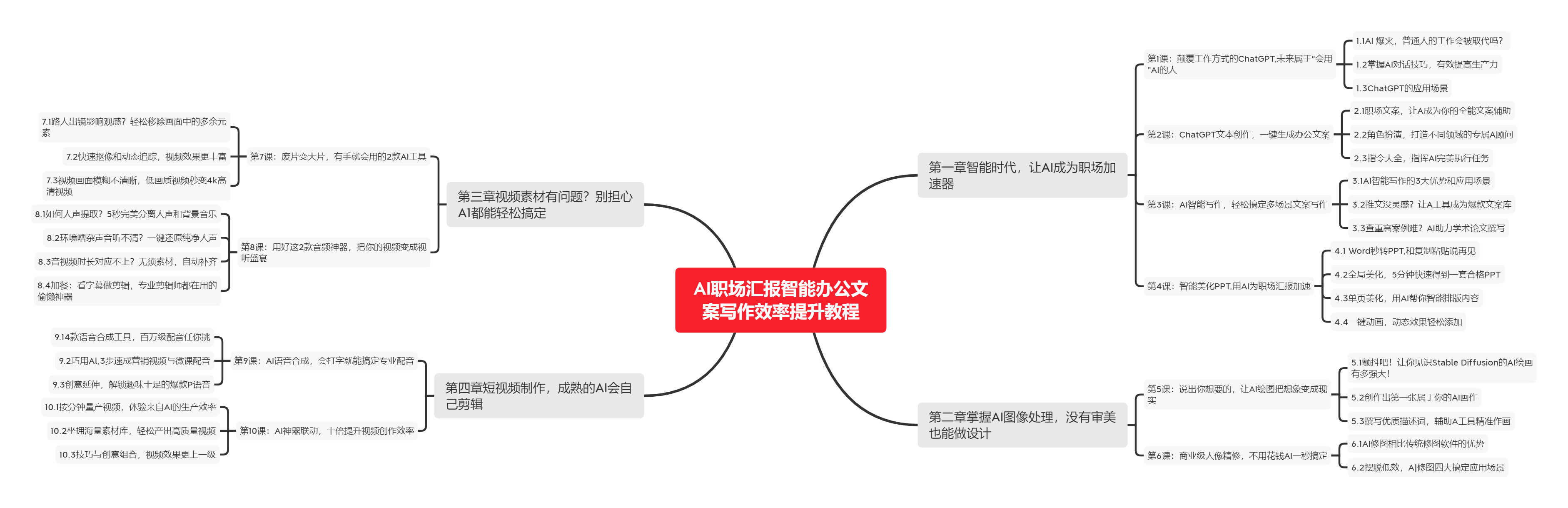

下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具

🚀 优质教程分享 🚀
- 🎄可以学习更多的关于人工只能/Python的相关内容哦!直接点击下面颜色字体就可以跳转啦!
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 AI职场汇报智能办公文案写作效率提升教程 🧡 | 进阶级 | 本课程是AI+职场+办公的完美结合,通过ChatGPT文本创作,一键生成办公文案,结合AI智能写作,轻松搞定多场景文案写作。智能美化PPT,用AI为职场汇报加速。AI神器联动,十倍提升视频创作效率 |
| 💛Python量化交易实战 💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!