Zookeeper·
一、Zookeeper入门
1.)Zookeeper概述
① Zookeeper 是一个开源的分布式的,为分布式框架提供协调服务的 Apache 项目。
②Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负 责存储和管理大家都关心的数据,然 后接受观察者的注 册,一旦这些数据的状态发生变化,Zookeeper就 将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。
2.)Zookeeper的特点
①一个领导者(Leader):主要执行写操作;
多个跟随者(Follower):主要进行读操作
②集群只要有半数以上的节点存活,Zookeeper集群就能正常服务,所以Zookeeper集群适合安装奇数台服务器。
举个例子:假设总共有五台服务器,有两台宕机集群任然可以正常工作,有三台服务器宕机集群不可以正常工作。再假设总共有六台服务器的话,有三台宕机集群也不能正常工作。这样五台和六台的服务器的高可用效果是一样的。
③全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的
④更新请求顺序执行:来自同一个Client的更新请求按其发送顺序依次执行。
⑤数据更新原子性:一次数据更新要么成功,要么失败
⑥实时性:在一定时间范围内,Client能读到最新数据。
3.)数据结构
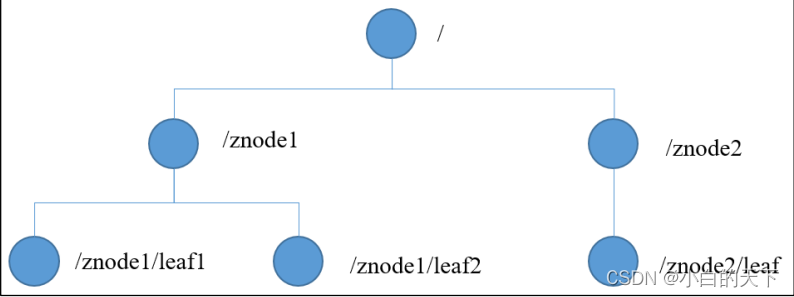
ZooKeeper 数据模型的结构与 Unix 文件系统很类似,整体上可以看作是一棵树,每个节点称做一个 ZNode。每一个 ZNode 默认能够存储 1MB 的数据,每个 ZNode 都可以通过其路径唯一标识。
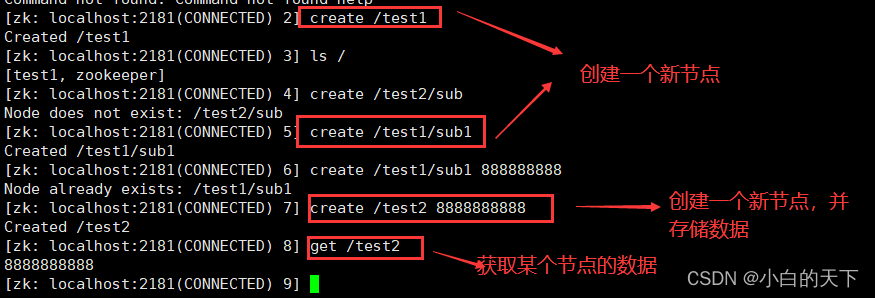
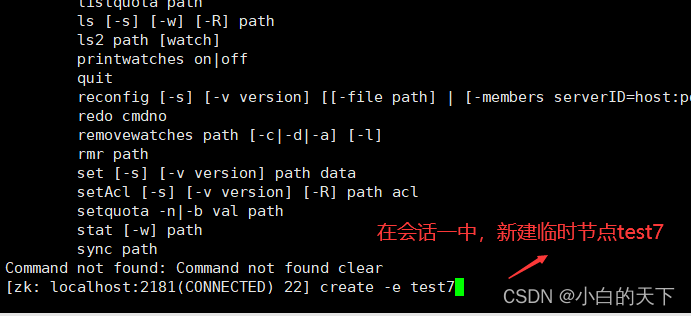
可以使用create命令新建znode节点:

1.) zk中的znode包含了四个部分:
①data:保存数据
② acl:权限:定义了什么样的用户能够操作这个节点以及对这个节点可以进行怎样的操作

③stat:描述当前节点的元数据
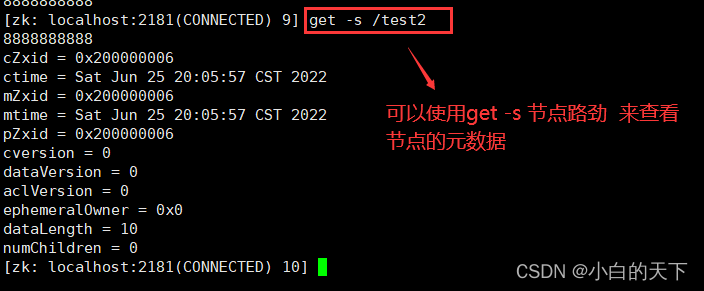
④child:当前节点的子节点
2.) Znode节点的类型:
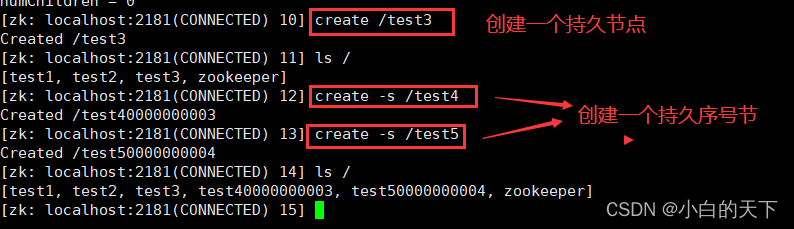
①持久节点和持久序号节点
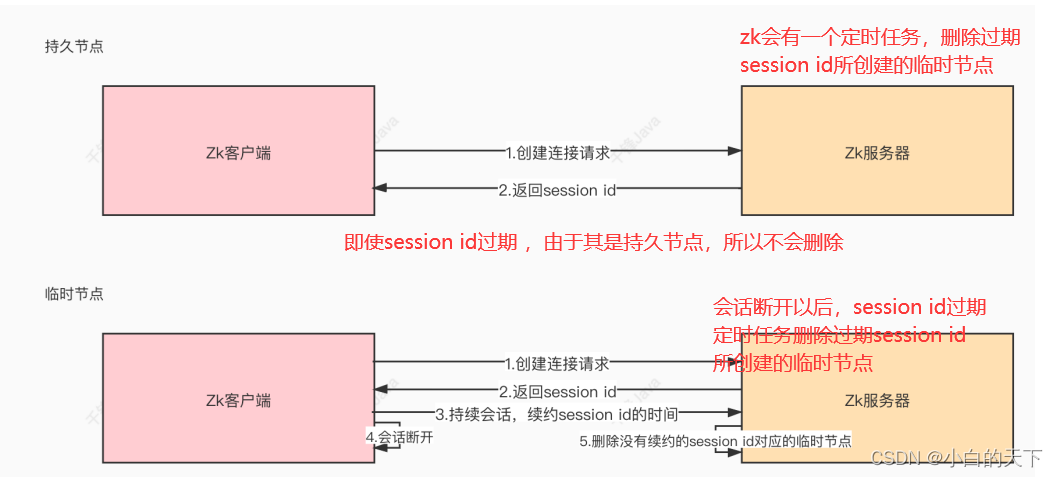
持久节点: 创建出的节点,在会话结束后依然存在。保存数据
持久序号节点:创建出的节点,根据先后顺序,会在节点之后带上⼀个数值,越后执⾏数值越⼤,适⽤于分布式锁的应⽤场景- 单调递增
②临时节点
临时节点是在会话结束后,⾃动被删除的,通过这个特性,zk可以实现服务注册与发现的效果。那么临时节点是如何维持⼼跳呢?

③临时序号节点:
跟持久序号节点相同,适⽤于临时的分布式锁。
④Container节点(3.5.3版本新增)
Container容器节点,当容器中没有任何⼦节点,该容器节点会被zk定期删除(60s)。
⑤TTL节点(不稳定)
可以指定节点的到期时间,到期后被zk定时删除。只能通过系统配置zookeeper.extendedTypesEnabled=true 开启
3.)Znode节点的操作:
查询节点: get -R 节点 (递归查询)
修改节点的值:set 节点 值
删除节点:
①普通删除:delete(不可以删除有内容的节点) deleteall(可以删除有内容的节点)
②乐观锁删除:delete -v 版本 节点名
监听节点(可用于服务的注册和发现):
①监听节点值(只能监听一次)

②监听节点的子节点变化(只能监听一次)

4.)权限设置

4.)应用场景
①分布式协调组件
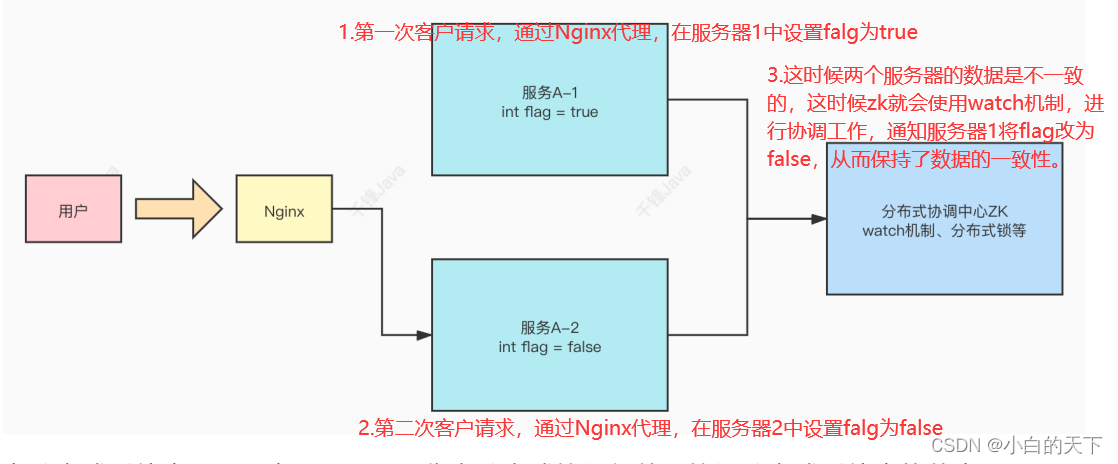
②分布式锁
zk在实现分布式锁上,可以做到强一致性。
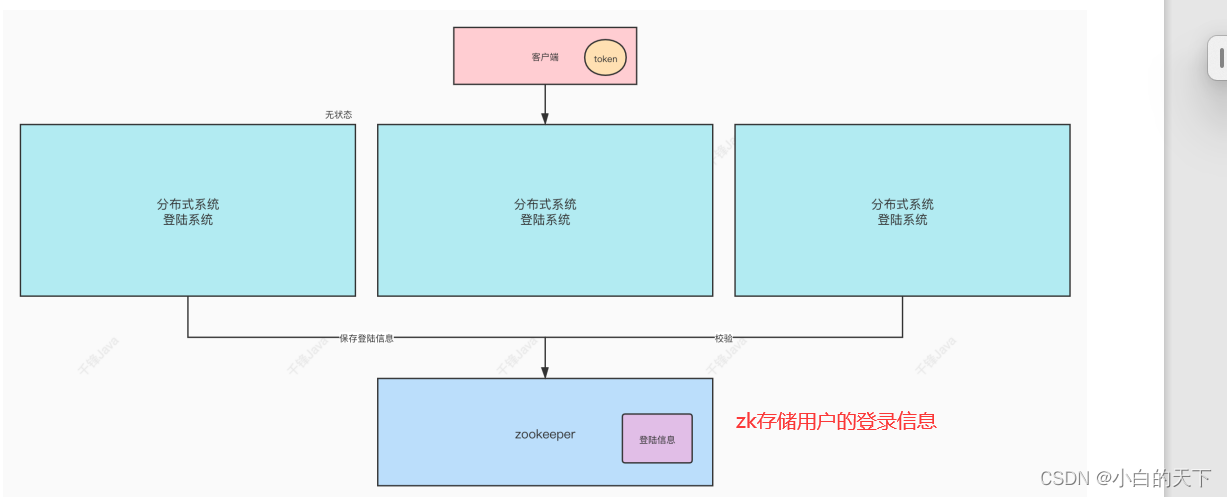
③无状态化
5.)zk数据的持久化
zk的数据是运⾏在内存中,zk提供了两种持久化机制:


zk通过两种形式的持久化,在恢复时先恢复快照⽂件中的数据到内存中,再⽤⽇志⽂件中的数据做增量恢复,这样的恢复速度更快。
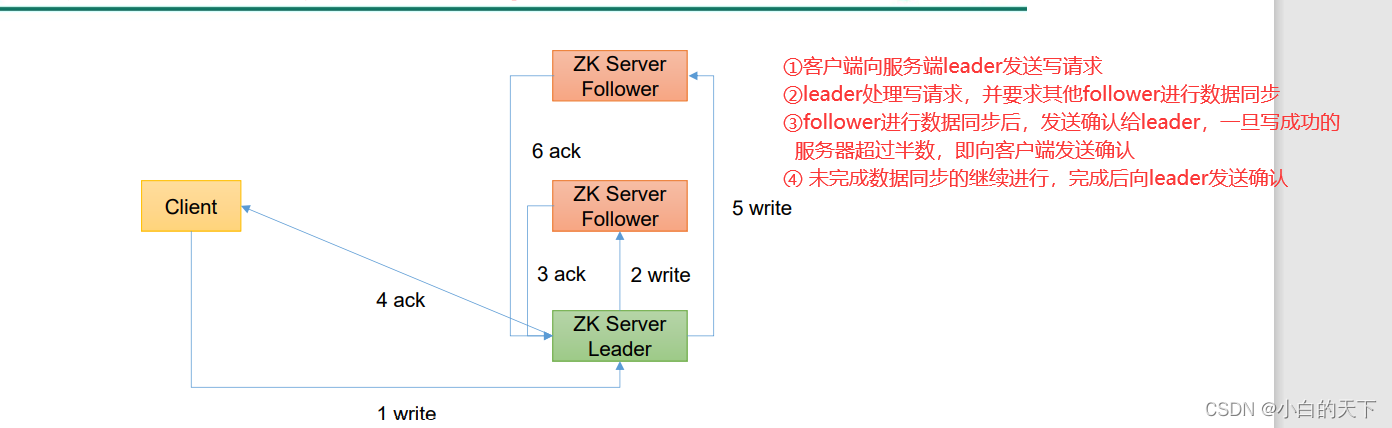
6.)zookeeper客户端向服务端写数据流程
①写请求直接发到leader节点
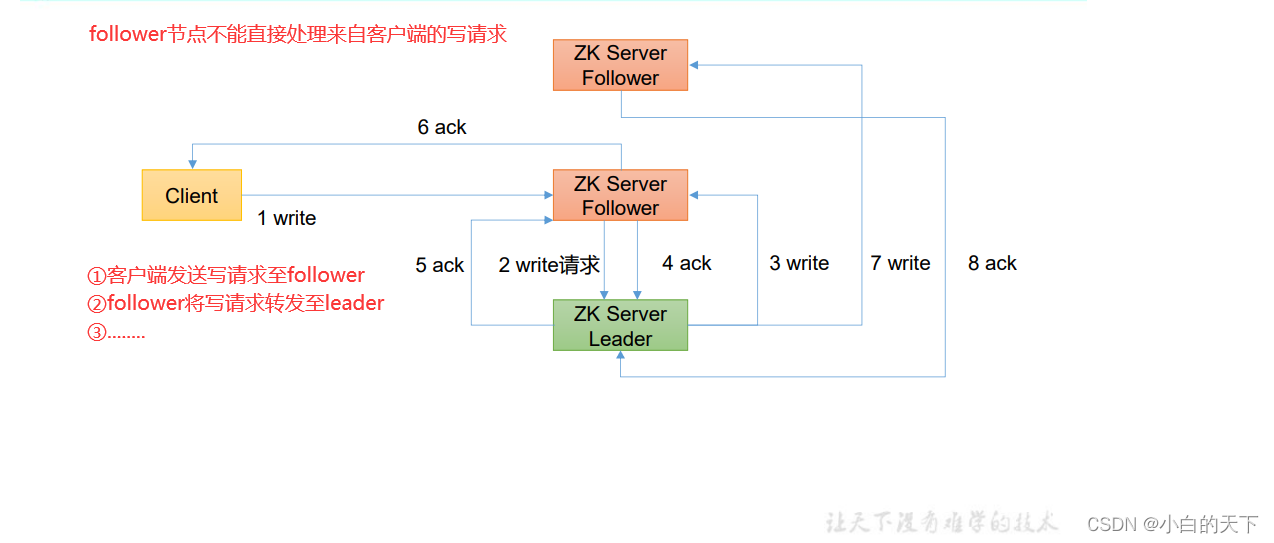
②写请求发到follower节点
二、 Zookeeper本地安装和配置参数解读
1.)安装前准备
①安装jdk
②官网下载安装包
https://zookeeper.apache.org/
2.)使用tar命令安装完成后修改配置

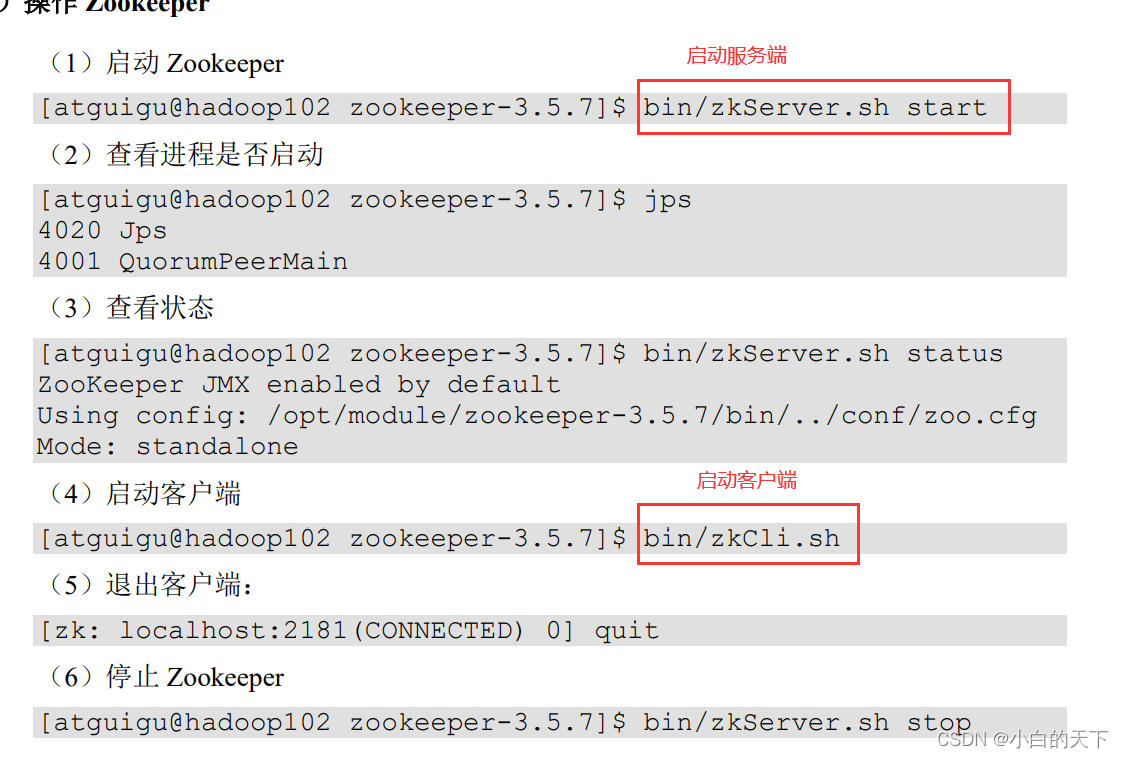
3.)启动Zookeeper
4.)配置参数解读
①tickTime
Zookeeper服务器与客户端心跳时间,单位毫秒
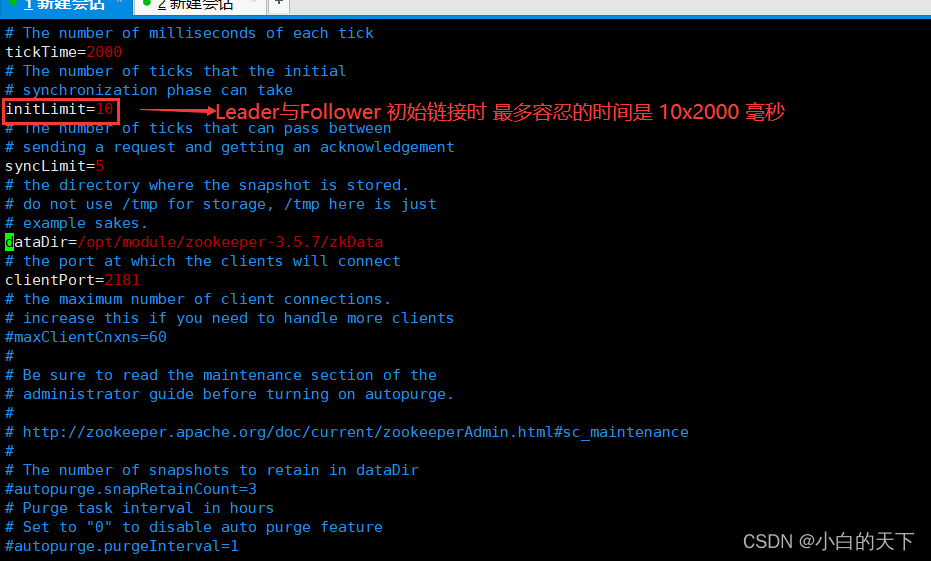
②initLimit
Leader与Follower 初始连接时能容忍的最多心跳数
③syncLimit
Leader和Follower之间通信时间如果超过syncLimit * tickTime,Leader认为Follwer死掉,从服务器列表中删除Follwer。
④dataDir
保存Zookeeper中的数据
注意:默认的tmp目录,容易被Linux系统定期删除,所以一般不用默认的tmp目录
⑤clientPort
客户端连接端口,通常不做修改。
三、Zookeeper集群
①配置服务器编号
在zkData目录下新建myid文件,在myid文件中指明服务器编号
②添加如下配置到配置文件

③挨个启动即可,但是要注意要超过半数的服务器启动后,查看状态时才显示正常。
1.)批量启动、停止Zookeeper服务端
这里注意集群的话,各个服务器安装的路劲要一致,否则写shell脚本,循环的时候会遇到问题
①编写shell脚本
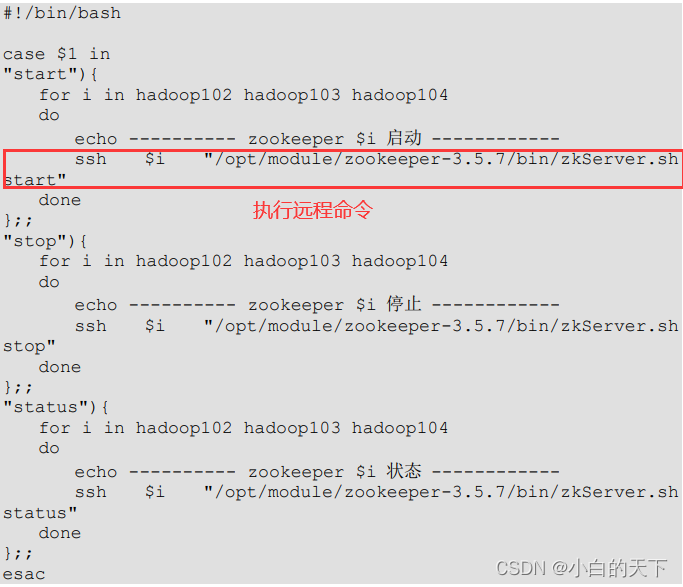
②赋予执行权限
chmod 744 文件名
2.)客户端命令行操作
四、选举机制
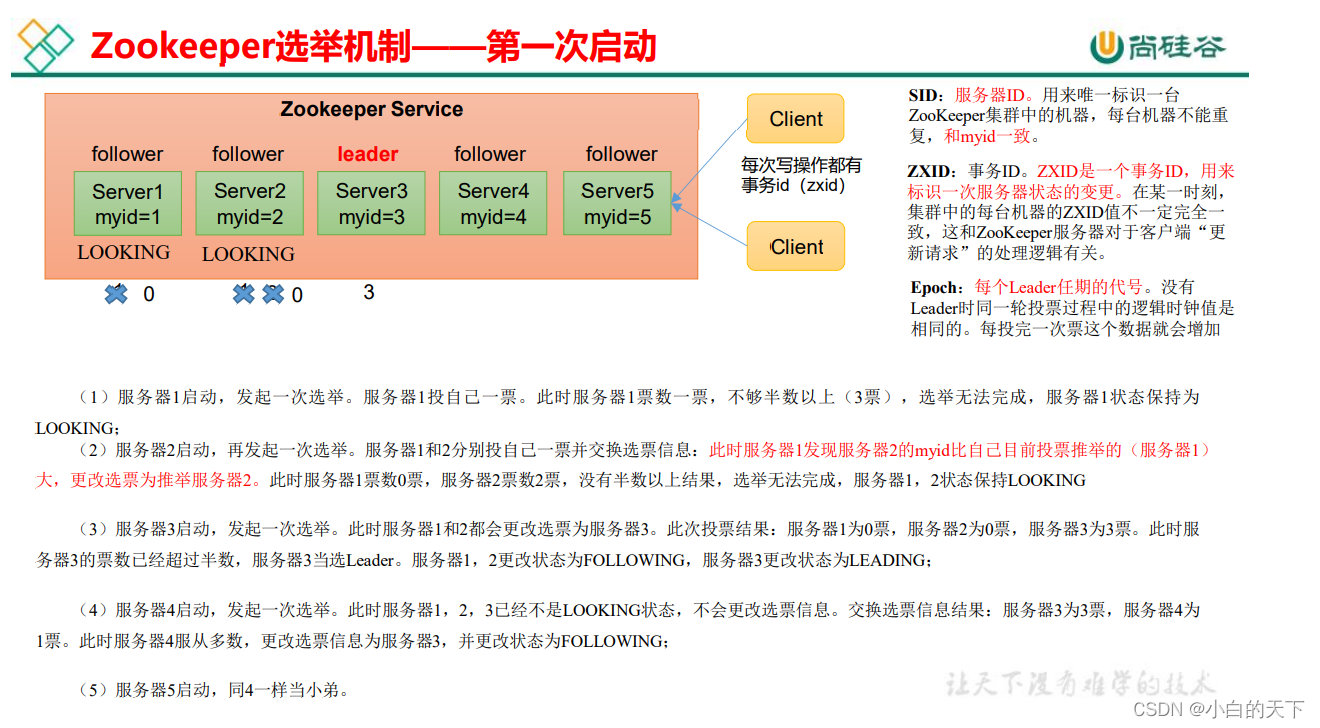
1.)第一次启动
在没有选出leader前,每启动一个服务器,就会举行一次选举,此时首先都会先投自己一票,然后进行对比,将选票投给myid最大的那一位,直到某个机器的选票超过集群服务器半数,就确定这个选票超过集群服务器半数的机器为leader,其他为follower。
2.)非第一次启动
当Zookeeper集群出现一下两种情况,就会重新开始leader选举:
①服务器初始化启动
②服务器运行期间无法和leader保持连接
重新选举leader时,会有两种情况:
①集群中已经有leader了
这种情况,会将集群中的leader信息告知没有和leader连接的那台服务器,然后进行数据同步即可
②集群中确实没有leader

五、Curator客户端的使用
Curator是Netflix公司开源的⼀套zookeeper客户端框架,Curator是对Zookeeper⽀持最好的客户端框架。Curator封装了⼤部分Zookeeper功能,⽐如Leader选举、分布式锁等,减少了技术⼈员在使⽤Zookeeper时的底层细节开发⼯作。
1.)简单使用
1.)引入依赖
<dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.4.14</version><exclusions><exclusion><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId></exclusion><exclusion><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId></exclusion><exclusion><groupId>log4j</groupId><artifactId>log4j</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.apache.curator</groupId><artifactId>curator-framework</artifactId><version>2.12.0</version><exclusions><exclusion><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId></exclusion><exclusion><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.apache.curator</groupId><artifactId>curator-recipes</artifactId><version>2.12.0</version></dependency>
②配置文件
curator.retryCount=5
curator.elapsedTimeMs=5000
curator.connectString=ip+端口(集群中间以“,”隔开)
curator.sessionTimeoutMs=60000
curator.connectionTimeoutMs=50000
③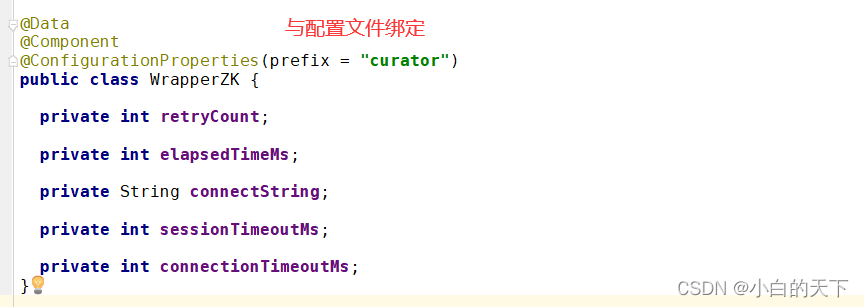
④
向ioc容器中注入CuratorFramework
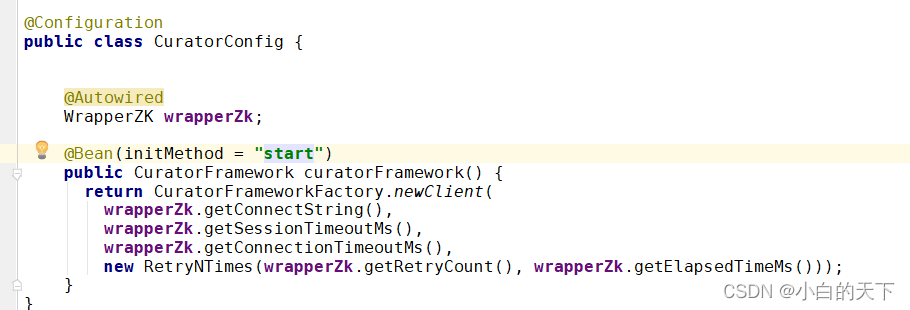
⑤操作
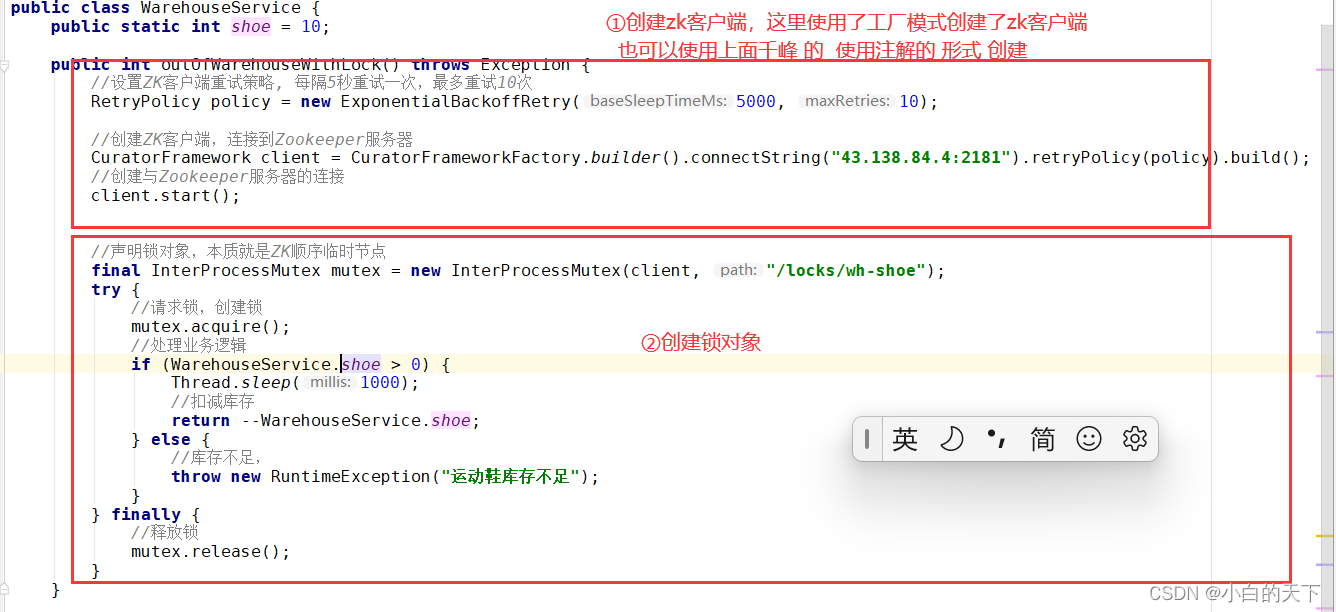
class BootZkClientApplicationTests {@AutowiredCuratorFramework curatorFramework;@Testvoid createNode() throws Exception {//添加持久节点String path = curatorFramework.create().forPath("/curator-node2");//添加临时序号节点String path1 = curatorFramework.create().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath("/curator-node2", "some-data".getBytes());System.out.println(String.format("curator create node :%s successfully.",path));System.out.println(String.format("curator create node :%s successfully.",path1));System.in.read();}@Testpublic void testGetData() throws Exception {byte[] bytes = curatorFramework.getData().forPath("/curator-node");System.out.println(new String(bytes));}@Testpublic void testSetData() throws Exception {curatorFramework.setData().forPath("/curator-node","changed!".getBytes());byte[] bytes = curatorFramework.getData().forPath("/curator-node");System.out.println(new String(bytes));}@Testpublic void testCreateWithParent() throws Exception {String pathWithParent="/node-parent/sub-node-1";String path = curatorFramework.create().creatingParentsIfNeeded().forPath(pathWithParent);System.out.println(String.format("curator create node :%s successfully.",path));}@Testpublic void testDelete() throws Exception {String pathWithParent="/node-parent";curatorFramework.delete().guaranteed().deletingChildrenIfNeeded().forPath(pathWithParent);}@Testpublic void addNodeListener() throws Exception {NodeCache nodeCache = new NodeCache(curatorFramework, "/curator-node");nodeCache.getListenable().addListener(new NodeCacheListener() {@Overridepublic void nodeChanged() throws Exception {log.info("{} path nodeChanged: ","/curator-node");printNodeData();}});nodeCache.start();System.in.read();}public void printNodeData() throws Exception {byte[] bytes = curatorFramework.getData().forPath("/curator-node");log.info("data: {}",new String(bytes));}}2.)zk实现分布式锁(b站-IT老齐P58、59)
一般使用有序临时节点实现分布式锁
为什么会产生库存超卖问题?
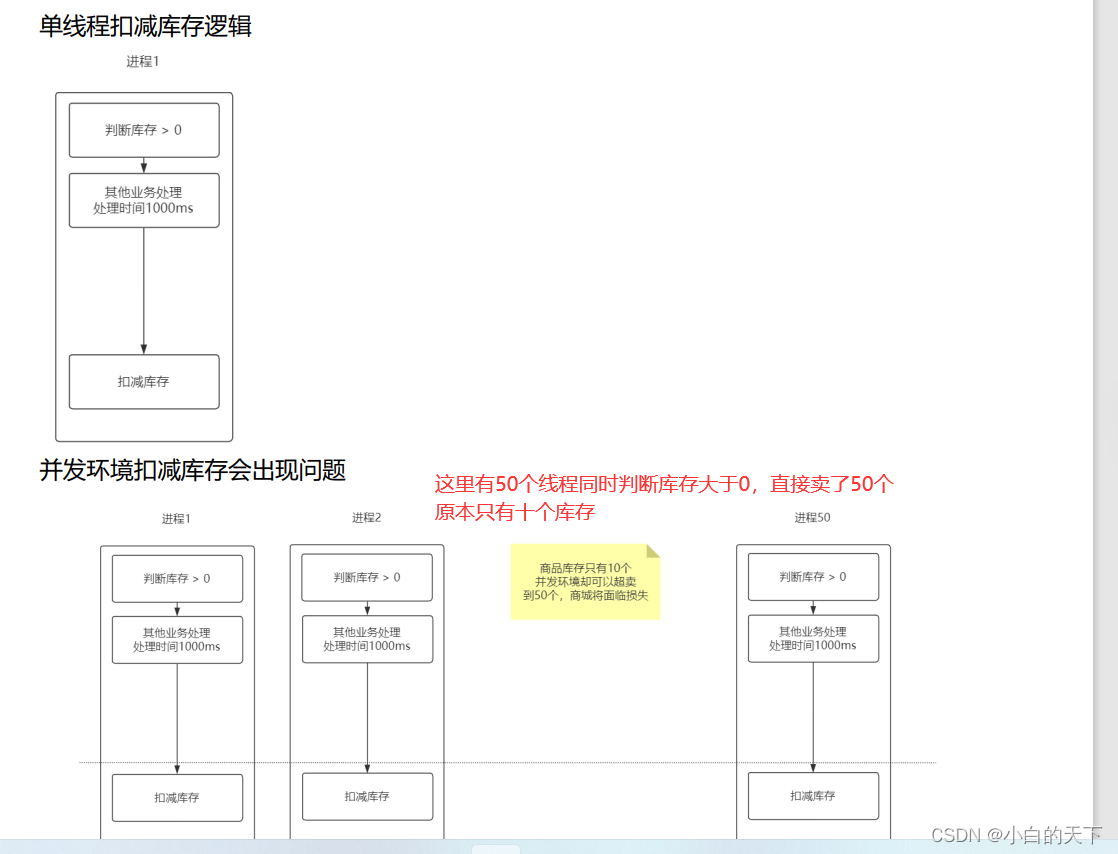
解决方案:

“锁”带来的问题:

zookeeper分布式锁的实现原理:
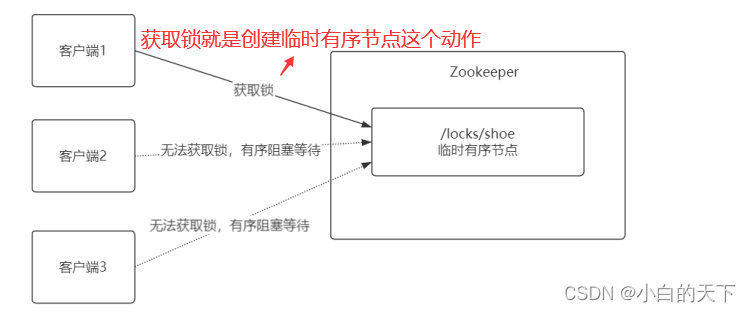
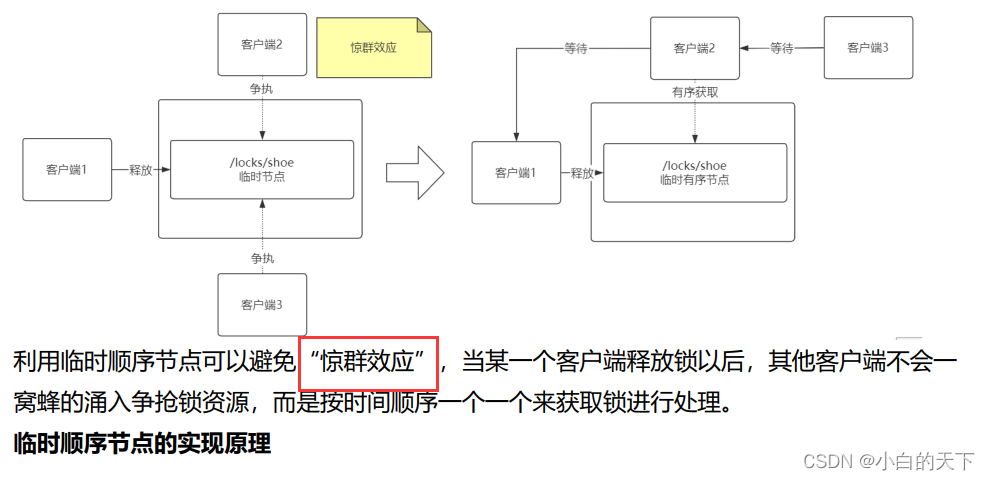
为什么使用临时有序节点实现分布式锁?
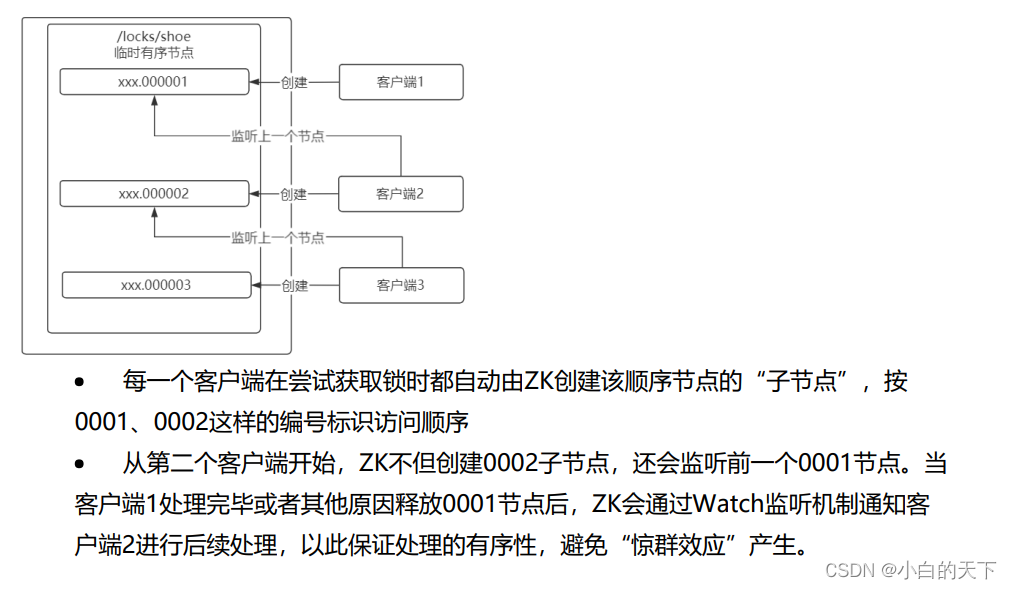
在java项目中,想要使用Zookeeper实现分布式锁,可以引入Curator客户端,Curator客户端将复杂的实现逻辑进行封装,我们只需要调包即可。
只想用分布式锁的话 ,只需要引入以下依赖:
1 <dependency>
2 <groupId>org.apache.curator</groupId>
3 <artifactId>curator‐recipes</artifactId>
4 <version>5.2.0</version>
5 </dependency>
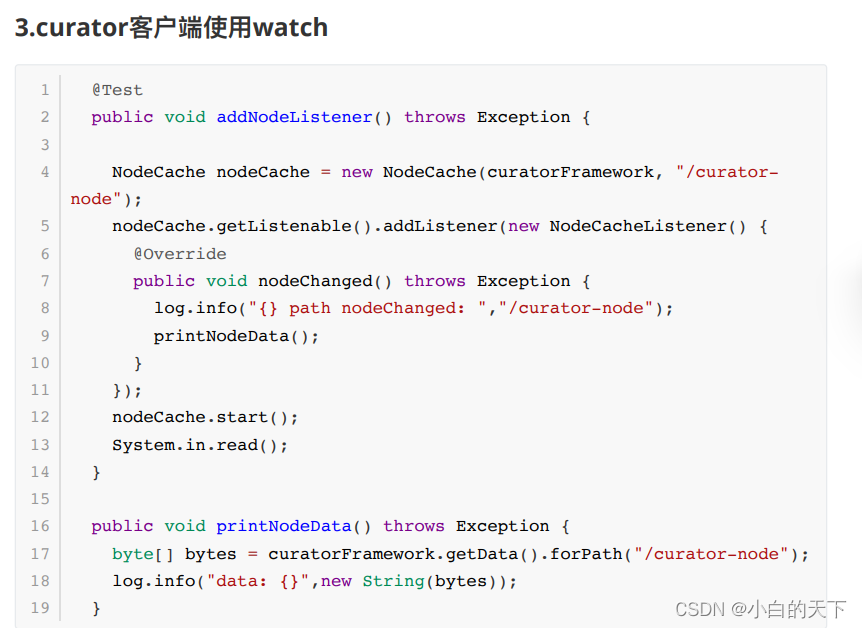
3.)Watch机制
我们可以把 Watch 理解成是注册在特定 Znode 上的触发器。当这个 Znode 发⽣改变,也就是调⽤了 create , delete , setData ⽅法的时候,将会触发 Znode 上注册的对应事件,请求 Watch 的客户端会接收到异步通知。

六、实际案例
1.)服务器动态上下线
这里只使用了原生的api来操作zookeeper,一般情况下可以使用Curator客户端来简化操作。
在idea中,可以使用zoolytic插件来管理zookeeper、查看节点结构,十分方便。
使用临时有序节点实现服务器的动态上下线
服务注册:
/*** 模拟将服务注册到zookeeper*/public class DistributeServer {private static String connectionString="xxxxxx";//以集群的形式连接zookeeper,需要将超时时间设置的长一点private static int sessionTimeout = 100000;private static ZooKeeper zk = null;public static void main(String[] args) throws IOException, KeeperException, InterruptedException {//1.连接zookeeper客户端DistributeServer distributeServer = new DistributeServer();distributeServer.createConnection();//2.创建节点以完成服务注册distributeServer.registerServer(args[0]);//3.业务逻辑System.out.println(args[0]+"is working");Thread.sleep(Long.MAX_VALUE);}//服务注册private void registerServer(String hostName) throws KeeperException, InterruptedException {String node = zk.create("/servers/" +hostName, hostName.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);System.out.println(hostName+"is online"+node);}//连接zookeeper客户端void createConnection() throws IOException {zk = new ZooKeeper(connectionString, sessionTimeout, new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {}});}
}服务监听:
/*** 模拟客户端监听服务端*/public class DistributeClient {private static String connectionString="43.138.84.4:2181,139.155.45.26:2181";//以集群的形式连接zookeeper,需要将超时时间设置的长一点private static int sessionTimeout = 100000;private static ZooKeeper zk = null;public static void main(String[] args) throws IOException, KeeperException, InterruptedException {//1.连接zookeeperDistributeClient client = new DistributeClient();client.createConnection();//2.监听服务器client.getServerList();//3.业务代码System.out.println("client is working");Thread.sleep(Long.MAX_VALUE);}//获取服务器列表信息,private void getServerList() throws KeeperException, InterruptedException {//1.获取服务器子节点信息,并且对父节点进行监听List<String> children = zk.getChildren("/servers", true);//2.获取节点里存储的服务器信息ArrayList<String> server = new ArrayList<>();for (String child:children){byte[] data = zk.getData("/servers/" + child, false, null);server.add(new String(data));}System.out.println(server);}//连接zookeeper客户端private void createConnection() throws IOException {zk = new ZooKeeper(connectionString, sessionTimeout, new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {//再次启动监听try {getServerList();}catch (Exception e){e.printStackTrace();}}});}}2. )分布式锁
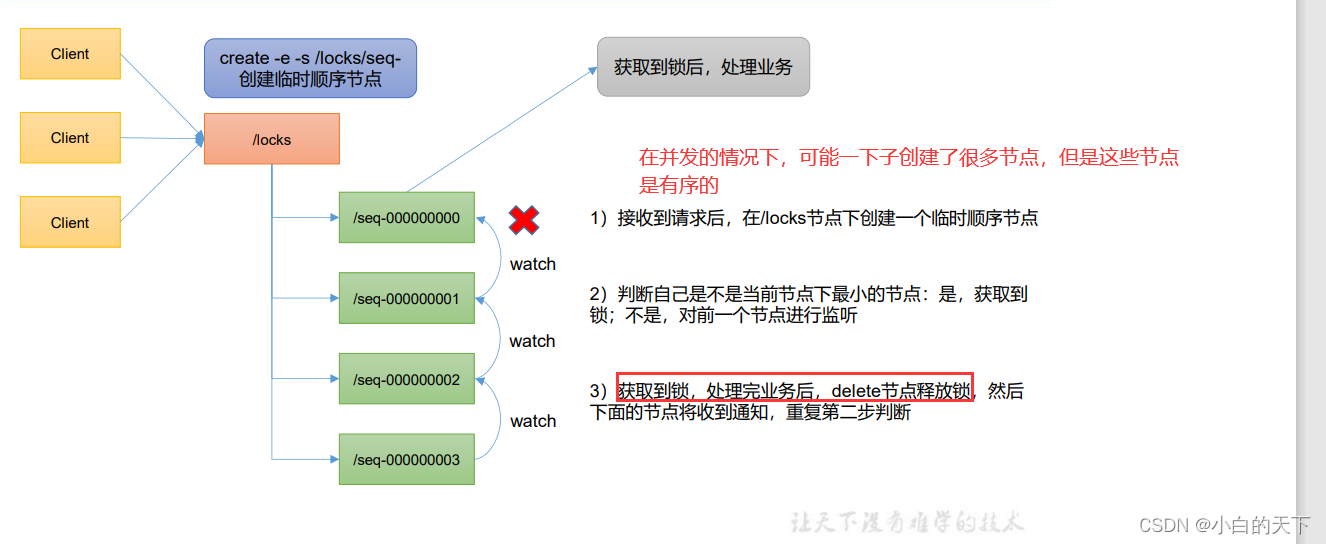
使用上面的curator框架完成分布式锁。
七、面试题
1.)选举机制
第一次选举:
投票过半数时,服务器 id 大的胜出
第二次选举:
①EPOCH 大的直接胜出
②EPOCH 相同,事务 id 大的胜出
③事务 id 相同,服务器 id 大的胜出
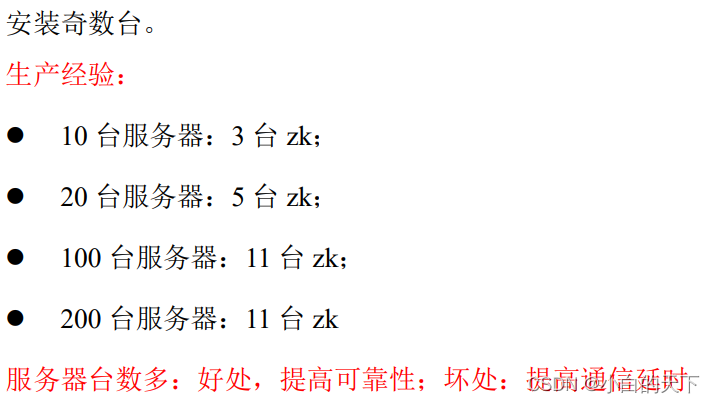
2.)生产集权安装多少zk合适?
3.)拜占庭将军问题(使用Paxos算法解决)
要面试的时候在看
4.)ZAB协议
要面试的时候在看
5.)cap理论

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!