第二阶段:JavaAPI总复习一一一之一一一01

Java API汇总复习
一、验证码功能:
1、验证码:相关知识点:
01.BufferedImage子类(继承自java.awt.Image):①是描述具有可访问的图像数据缓冲区的图像。②由: ColorModel 和 Raster 图像数据组成。③Raster 的 SampleModel 中波段的数量和类型必须与 ColorModel 表示其颜色和 alpha 分量所需的数量和类型相匹配。④BufferedImage对象的左上角坐标为 (0, 0)。因此,用于构造 BufferedImage 的任何 Raster 必须具有 minX=0 和 minY=0。⑤这个类依赖于数据获取和设置方法。package apiday.a_verification_code;
import javax.imageio.ImageIO;
import java.awt.*;
import java.awt.image.BufferedImage;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Random;
/*** 1、验证码:相关知识点:* 01.BufferedImage子类(继承自java.awt.Image):* ①是描述具有可访问的图像数据缓冲区的图像。* ②由: ColorModel 和 Raster 图像数据组成。* ③Raster 的 SampleModel 中波段的数量和类型必须与 ColorModel 表示其颜色和 alpha 分量所需的数量和类型相匹配。* ④BufferedImage对象的左上角坐标为 (0, 0)。因此,用于构造 BufferedImage 的任何 Raster 必须具有 minX=0 和 minY=0。* ⑤这个类依赖于数据获取和设置方法。*/
public class ToolVerCode {public static void main(String[] args) {/** 02.创建验证码:步骤:*///(1)创建一张空图片,并指定宽高。理解为:创建一张画纸BufferedImage image = new BufferedImage(70,30,BufferedImage.TYPE_INT_RGB);//(2)根据图片获取一张画笔,通过该画笔画的内容都会画到该图片上Graphics g = image.getGraphics();//(3)①确定验证码内容(字母与数字的组合)String line = "abcdefghijklmnopqrstuvwxyz";//②用于生成随机数(随机数line的字符下标)Random r = new Random();//(4)为图片北京填充一个随机颜色//①创建color时:需指定三个参数(分别是:红、绿、蓝 数字范围都是0-255之间)Color bgcolor = new Color(r.nextInt(256), r.nextInt(256), r.nextInt(256));//②将画笔设置为该颜色g.setColor(bgcolor);//③填充整张图片为画笔当前颜色g.fillRect(0,0,70,30);//向图片上画4个字符:for(int i=0;i<4;i++) {//随机生成一个字符:String str = line.charAt(r.nextInt(line.length())) + "";//生成随机颜色Color color = new Color(r.nextInt(256), r.nextInt(256), r.nextInt(256));//设置画笔颜色g.setColor(color);//设置字体g.setFont(new Font(null, Font.BOLD, 20));//将字符串画到图片指定位置上g.drawString(str, i*15+5, 18+r.nextInt(11)-5);}//随机生成4条干扰线:for(int i=0;i<4;i++){Color color = new Color(r.nextInt(256), r.nextInt(256), r.nextInt(256));g.setColor(color);g.drawLine(r.nextInt(71), r.nextInt(31), r.nextInt(71), r.nextInt(31));}//(5)将图片写入指定路径来生成该图片文件try {ImageIO.write(image,"jpg",new FileOutputStream("./src/apiday/a_verification_code/test/random.jpg"));} catch (IOException e) {e.printStackTrace();}}
}
一、QRCodeUtil二维码工具类:
01.简单介绍下二维码工具类测试流程:
简单介绍下二维码工具类测试流程:
二维码其实就是一种编码技术,只是这种编码技术是用在图片上了,将给定的一些文字,数字转换
为一张经过特定编码的图片;而解析二维码则相反,就是将一张经过编码的图片解析为数字或者文字。当然了,这种编码的低层实现并不是那么的简单,都是那些顶级研发人员做的事,我们只需要简单
了解并知道怎么使用就可以了。那么肯定是要导入jar包依赖的吧,那不用说,是要导包的,我用的是【lib目录中的4个(二维码工具类.jar)】。下面我们直接创建一个类来测试二维码工具类,给需要用到这个二维码工具类的包添加依赖,因为是
project项目中的类测试,所以我们只需要按照下面:【具体二维码类QRCodeUtil的测试】中的:
【1、】按顺序执行就可以: 具体二维码类QRCodeUtil的测试:
1、若在IDEA的project中生成二维码则需要进行下面【2中(1)(2)】的配置:2、若在IDEA的Maven中生成二维码则需要进行下面【①②③】的配置:二维码类QRCodeUtil的配置:(1)新建目录lib:项目名右键new——>Directory——>lib 把粘贴好的【二维码工具压缩包(4个压缩包在Git的MyWebServer项目中)】放在lib里(2)点击目录lib右键——>Add ad Library——>出现弹框——>给库起名为:QR(3)点击窗口左上角File——>project Structure——>弹出的框:——>最左侧点击Modules——>选择要加入功能的【v**】——>再点击右侧Dependencies——>再点击【+】号——>弹出一个框选择Library——>又弹出框——>选择刚才创建的【QR】——>再点击下面Add Selected——>此时有一行蓝色的【QR】,点击下面的【OK】.完成!2、1 若想要在Maven项目中:新建的Maven中继续使用该功能!因为之前版本下载导入了【二维码工具类的包】,因此只需要进行上面【2中(3)】的配置即可!遇到的问题:若【点击“+”后弹出的框没有“Library”】?解决: ——>最左侧点击Modules——>选择要加入功能的【v**】——>再点击右侧Dependencies——>再点击【+】号——>弹出一个框选择【JARs or Directories..】——>又弹出框——>选择项目——>选择【lib】点击【OK】——>此时有一行蓝色的【路径】,点击下面的【OK】.!完成!3、用二维码类QRCodeUtil的encode()方法测试二维码生成:创建包和类:src/apiday/object/QRCodeUtil包下的:ToolsController类①在main方法里存一句字符串到message中:【String message = "今天学习二维码啦~奥利给";】②用QRCodeUtil类调用encode()方法:【QRCodeUtil.encode(message,"./WebServer资料/test/Me.jpg");】③会爆红:用try-catch捕获异常,此时在指定的目标路径中会有一张二维码图片,扫一下即可得到上面的字符串信息,即:【今天学习二维码啦~奥利给】④接着可以测试QRCodeUtil类中的:生成二维码方法:重载的encode()方法解析二维码方法:decode(destPath)方法02.QRCodeUtil API 和 练习题:
QRCodeUtil:是二维码工具类。
注1:二维码存的信息越多,二维码图片也就越复杂,容错率也就越低,识别率也越低,并且二维码能存的内容大小也是有限的(大概500个汉字左右)。注2:①若想扫描生成的二维码读取出来一些语句,直接在编码的方法里,将编码内容改为字符串即可!例:String message = "今天学习二维码啦~奥利给";②若想扫描生成的二维码跳转到一个网站:则把字符串换为信息即可!例:String message = "https://www.jd.com/";1、QRCodeUtil二维码工具类 API:————>注1:存储到目标路径时,前提是路径中的目录必须存在!:编码和解码方法都有多个重载方法,根据参数列表的不同,选择不同的方法执行。01.生成二维码方法:常见参数代表意思:①content:编码到二维码中的内容,这里是:"今天学习二维码啦~奥利给"②imgPath:要嵌入二维码的图片路径,如果不写或者为null则生成一个没有嵌入图片的纯净的二维码③destPath:生成的二维码的存放路径④true:表示将嵌入二维码的图片进行压缩,如果为“false”则表示不压缩(1)String message = "https://www.jd.com/";注:若想扫描生成的二维码去一个网站:则把字符串换为信息即可!(2)String message = "今天学习二维码啦~奥利给";①encode(String content,String destPath):将message包含的信息存储到指定的图片中注:参数1:二维码上包含的信息 参数2:图片生成的位置②encode(String content,OutputStream output):将message包含的信息以流的形式写出到指定的路径中的二维码图片中注:参数1:二维码上包含的文本信息 参数2:图片生成后会通过该流(只要是字节输出流就行)写出到指定的路径③encode(String content,String imgPath,String destPath,boolean needCompress)):将message包含的信息再加一个指定路径的图片一起存储到指定的路径中的二维码图片中,并压缩图片的大小至二维码图片中心位置注意:参数1:二维码上包含的文本信息 参数2:二维码中间的logo图片所在位置参数3:图片生成的位置 参数4:是否需要压缩logo图片到生成的二维码图片之间的大小④encode(String content,String imgPath,OutputStream output,boolean needCompress)):将message包含的信息再加一个指定路径的图片一起以流的形式写出到指定的路径中的二维码图片中,并压缩图片的大小至二维码图片中心位置注意:参数1:二维码上包含的文本信息 参数2:二维码中间的logo图片参数3:图片生成后会通过该流(只要是字节输出流就行)写出到指定的路径中参数4:是否需要压缩logo图片到生成的二维码图片之间的大小02.解析二维码方法:参数代表意思:将要解析的二维码的存放路径(1)String decode(File file):该方法返回值为String类型,即返回解析出的文字或者数字等。注:参数:将要解析的二维码的存放路径练习题:
package apiday.object.QRCodeUtil;
import qrcode.QRCodeUtil;
import java.io.FileOutputStream;
/*** QRCodeUtil:是二维码工具类。* 注1:二维码存的信息越多,二维码图片也就越复杂,容错率也就越低,识别率也越低,并且二维码能存的内容大小也是有限的(大概500个汉字左右)。* 注2:①若想扫描生成的二维码读取出来一些语句,直接在编码的方法里,将编码内容改为字符串即可!* 例:String message = "今天学习二维码啦~奥利给";* ②若想扫描生成的二维码跳转到一个网站:则把字符串换为信息即可!* 例:String message = "https://www.jd.com/";** 1、QRCodeUtil二维码工具类 API:————>注1:存储到目标路径时,前提是路径中的目录必须存在!* :编码和解码方法都有多个重载方法,根据参数列表的不同,选择不同的方法执行。** 01.生成二维码方法:* 常见参数代表意思:* ①content:编码到二维码中的内容,这里是:"今天学习二维码啦~奥利给"* ②imgPath:要嵌入二维码的图片路径,如果不写或者为null则生成一个没有嵌入图片的纯净的二维码* ③destPath:生成的二维码的存放路径* ④true:表示将嵌入二维码的图片进行压缩,如果为“false”则表示不压缩* (1)String message = "https://www.jd.com/";* 注:若想扫描生成的二维码去一个网站:则把字符串换为信息即可!** (2)String message = "今天学习二维码啦~奥利给";* ①encode(String content,String destPath):将message包含的信息存储到指定的图片中* 注:参数1:二维码上包含的信息 参数2:图片生成的位置** ②encode(String content,OutputStream output):将message包含的信息以流的形式写出到指定的路径中的二维码图片中* 注:参数1:二维码上包含的文本信息 参数2:图片生成后会通过该流(只要是字节输出流就行)写出到指定的路径** ③encode(String content,String imgPath,String destPath,boolean needCompress)):* 将message包含的信息再加一个指定路径的图片一起存储到指定的路径中的二维码图片中,并压缩图片的大小至二维码图片中心位置* 注意:参数1:二维码上包含的文本信息 参数2:二维码中间的logo图片所在位置* 参数3:图片生成的位置 参数4:是否需要压缩logo图片到生成的二维码图片之间的大小** ④encode(String content,String imgPath,OutputStream output,boolean needCompress)):* 将message包含的信息再加一个指定路径的图片一起以流的形式写出到指定的路径中的二维码图片中,并压缩图片的大小至二维码图片中心位置* 注意:参数1:二维码上包含的文本信息 参数2:二维码中间的logo图片* 参数3:图片生成后会通过该流(只要是字节输出流就行)写出到指定的路径中* 参数4:是否需要压缩logo图片到生成的二维码图片之间的大小** 02.解析二维码方法:* 参数代表意思:将要解析的二维码的存放路径* (1)String decode(File file):该方法返回值为String类型,即返回解析出的文字或者数字等。* 注:参数:将要解析的二维码的存放路径*/
public class ToolsController {//ToolsController:窗口二维码public static void main(String[] args) {//注:——————————>若想扫描生成的二维码去一个网站:则把字符串换为信息即可!
// String message = "https://www.jd.com/";String message = "今天学习二维码啦~奥利给";try {/** 01.生成二维码方法: *//*(1)encode(String content,String destPath):将message包含的信息存储到指定的路径中的二维码图片中注:参数1:二维码上包含的文本信息 参数2:图片生成的位置*/QRCodeUtil.encode(message,"./src/apiday/object/QRCodeUtil/test/Me.jpg");/*(2)encode(String content,OutputStream output):将message包含的信息以流的形式写出到指定的路径中的二维码图片中注:参数1:二维码上包含的文本信息 参数2:图片生成后会通过该流(只要是字节输出流就行)写出到指定的路径*/QRCodeUtil.encode(message,new FileOutputStream("./src/apiday/object/QRCodeUtil/test/Me2.jpg"));/*(3)①encode(String content,String imgPath,String destPath,boolean needCompress)):将message包含的信息再加一个指定路径的图片一起存储到指定的路径中的二维码图片中,并压缩图片的大小至二维码图片中心位置注意:参数1:二维码上包含的文本信息 参数2:二维码中间的logo图片所在位置参数3:图片生成的位置 参数4:是否需要压缩logo图片到生成的二维码图片之间的大小②encode(String content,String imgPath,OutputStream output,boolean needCompress)):将message包含的信息再加一个指定路径的图片一起以流的形式写出到指定的路径中的二维码图片中,并压缩图片的大小至二维码图片中心位置注意:参数1:二维码上包含的文本信息 参数2:二维码中间的logo图片参数3:图片生成后会通过该流(只要是字节输出流就行)写出到指定的路径中参数4:是否需要压缩logo图片到生成的二维码图片之间的大小*/QRCodeUtil.encode(message,"./src/apiday/object/QRCodeUtil/test/tianxian.jpg","./src/apiday/object/QRCodeUtil/test/Me3.jpg",true);QRCodeUtil.encode(message,"./src/apiday/object/QRCodeUtil/test/tianxian.jpg",new FileOutputStream("./src/apiday/object/QRCodeUtil/test/Me4.jpg"),true);System.out.println("二维码生成完毕");/** 02.解析二维码方法: *//*(1)String decode(File file):该方法返回值为String类型,即返回解析出的文字或者数字等。将要解析的二维码的存放路径注:参数:将要解析的二维码的存放路径*/String a = QRCodeUtil.decode("./src/apiday/object/QRCodeUtil/test/Me3.jpg");System.out.println(a);//今天学习二维码啦~奥利给} catch (Exception e) {e.printStackTrace();}}
}
二、String类
1、String
拓展例题1:
package apiday01;
/*** String substring(int start,int end):* 截取当前字符串中指定范围内的字符串(含头不含尾--包含start,但不包含end)*/
public class SubstringDemo {public static void main(String[] args) {String name = getName("www.tedu.com.cn");System.out.println(name); //teduString str = getName("http://www.google.com");System.out.println(str);//google}/**案例:用indexOf()和substring()截取上边的网址中域名:* 获取给定网址中的域名* @param line 网址* @return 返回域名*/public static String getName(String line){//0123456789012345//www.te.du.com.cnint start = line.indexOf(".")+1;//4 +1的目的是为了找到点后的第一个字符的位置int end = line.indexOf(".",start);//8 从start往后找第一个“.”的位置return line.substring(start,end);}
}
01.String字符串类型
字符串是常量,会保存在常量池。
注意:必须使用双引号包裹的字符串才是常量,会保存到常量池。java语言中所有的字符都采用“单引号”括起来java语言中所有的字符串都采用“双引号”括起来。
特点:创建之后【长度内容是不可变的】,【每次拼接字符串,都会产生新的对象】优点:String类提供了丰富的关于操作字符串的方法,比如:拼接、获取对应下标处的字符、截取子串等等
缺点:在进行字符串拼接+=的时候,效率比较低
(1)java.lang.String使用final修饰,不能被继承
(2)java中的String在内存中采用Unicode编码方式,任何一个字符对应两个字节的编码。
(3)字符串底层封装了字符数组以及针对字符数组的操作算法
(4)字符串一旦创建,对象内容永远无法改变(因为内部是数组),但字符串引用可以重新赋值(String底层维护的是一个char[],而且String不可变,因为源码中的数组被final修饰了)
例:
String str = new String("你好hello");//不推荐这种赋值模式
String str = "你好hello";//内存中占14个字节 共7个字符,所以占14个字节
char[] chs = {'你','好','h','e','l','l','o'} //字符串底层封装了字符数组,所以对象内容永远无法改变
02.常量池(!只有字符串才有!):
(1)java对字符串有一个优化的措施--------------专门提供了一个字符串常量池(堆中)。
(2)java推荐我们使用字面量/直接量的方式来创建字符串,并且会缓存所有以字面量形式创建的字符串对象到常量池中,当使用相同字面量再次创建字符串时会重用对象以减少内存开销,避免内存中堆积大量内容相同的字符串对象。
例1:
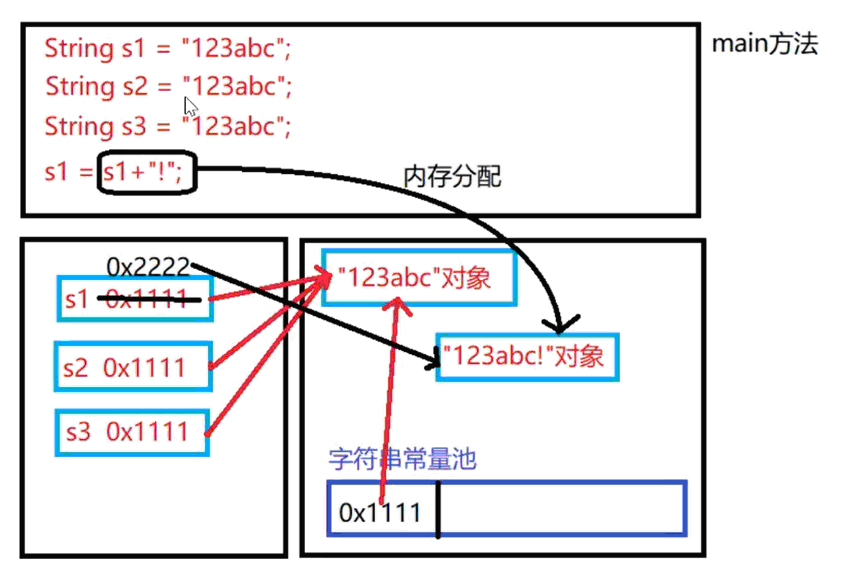
String s1 = "123abc";//字符串内容是123abc----java推荐 //在常量池中存储123abc这个对象
String s2 = "123abc"//复用常量池中的123abc,不会在创建新的对象
String s3 = "123abc"//复用常量池中的123abc,不会在创建新的对象
String s5 = new String("123abc");//内存中分配了一个123abc对象----java不推荐//在常量池中并不会缓存123abc对象
String s6 = new String("123abc");//内存中又分配了一个123abc对象
String s7 = new String("123abc");//内存中又分配了一个123abc对象例2:
String s1 = "hello";
String s2 = "hello"
//s1和s2的地址值()是不相同的,因为存储机制是不一样的
//但我们直接使用双引号(" ")写出一个字符串时,会先在常量池查找这个字符串
//如果没有相同的则会在常量池开辟空间并创建字符串,如果有则会直接使用常量池中的字符串

package apiday.day01.string;
/*** 一、String的演示:* (1)java.lang.String使用的final修饰,是final的类,不能被继承* (2)Java字符串在内存中采用Unicode编码方式,任何一个字符对应两个字节的编码。* (3)字符串底层封装了字符数组以及针对字符数组的操作算法* (4)字符串一旦创建,对象内容永远无法改变(因为内部是数组),* 但字符串引用可以重新赋值(String底层维护的是一个char[],而且String不可变,因为源码中的数组被final修饰了)** 二、常量池(!只有字符串才有!):* (1)java对字符串有一个优化的措施:专门提供了一个字符串常量池(堆中)。* (2)java推荐我们使用字面量/直接量的方式来创建字符串,并且会缓存所有* 以字面量形式创建的字符串对象到常量池中,当使用相同字面量再次创建* 字符串时会重用对象以减少内存开销,避免**内存中堆积大量内容相同的字符串对象。** 三、==和equals的区别:* (1)==:对于基本类型而言,比较的是数值是否相等* 对于引用类型而言,比较的是内存地址是否相等* (2)equals:String中重写了equals(),用于比较字符串内容是否相同,* 若不重写equals()则默认调用Object中的equals()还是比较地址,* 所以equals()常常被重写来比较对象的数据是否相同*/
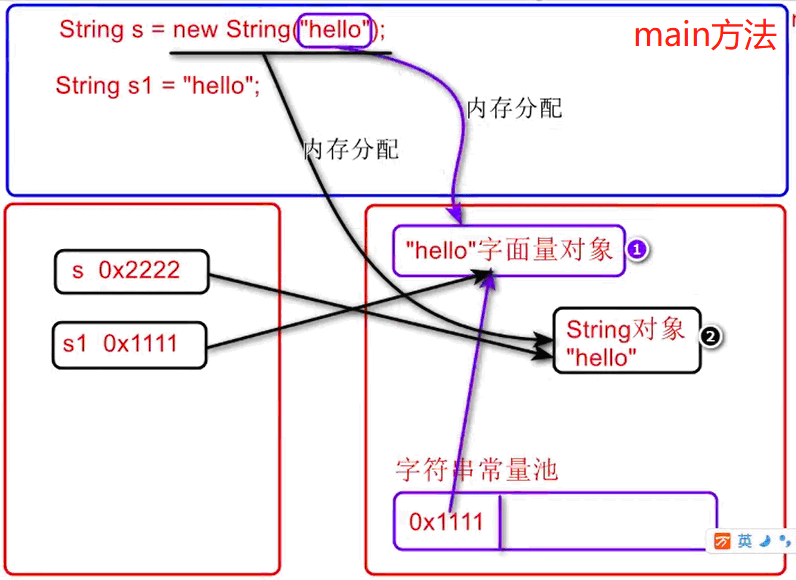
public class StringDemo {public static void main(String[] args) {//例1.使用字面量创建字符串时:JVM会检查常量池中是否有该对象://1)若没有,则创建该字符串对象并存入常量池//2)若有,则直接将该对象返回而不再创建一个新的字符串对象String s1 = "123abc";//1.JVM先检查常量池是否有该对象(123abc) 1)此时还没有,就会创建一个常量池对象(123abc)String s2 = "123abc";//2).常量池中已经有了对象,直接重用对象(123abc),不会再创建新的对象String s3 = "123abc";//2).常量池中已经有了对象,直接重用对象(123abc),不会再创建新的对象//注:引用类型的==,是比较的地址是否相同:System.out.println(s1==s2);//trueSystem.out.println(s1==s3);//trueSystem.out.println(s2==s3);//true//例2.字符串中,只要是有变量(s1)参与运算,就会开辟一个新的对象!s1 = s1+"!";//创建新的字符串对象(:123abc!)并将地址赋值给s1--------注2:字符串连接,不在常量池中!System.out.println(s1);//打印出:123abc!System.out.println(s1==s2);//false,因为s1为新对象的地址,与s2不同了!//补充://String字符串一旦定义好,对象内容不能再改变了,但是引用可以重新赋值//字符串字面量会存储在字符串常量池中,当下次内容相同的字符串被使用,将直接从常量池中获取String sss1 = "123abc";String ss2 = new String("123abc");String ss3 = "123"+"abc";String s4 = sss1;System.out.println(sss1==ss2); //falseSystem.out.println(sss1==ss3); //trueSystem.out.println(sss1==s4); //trueSystem.out.println(ss2==s4); //falseSystem.out.println(ss2.equals(s4)); //true/*例3.(1)字符串中,对象参与运算,会复用常量池中的对象(1)字符串中,只要是有变量(s1)参与运算,就会开辟一个新的对象!String s1 = "123abc";//堆中创建一个123abc对象,常量池中存储这个对象//编译器在编译时,若发现是两个字面量连接,//则直接运算好并将结果保存起来,如下代码相当于String s2 = “123abc”;String s2 = "123"+"abc";//复用常量池中的123abc对象System.out.println(s1==s2);//true,s1与s2共用常量池中的String s3 = "123";//因为s3不是字面量,所以并不会直接运算结果:String s4 = s3+"abc";//会在堆中创建新的123abc对象,而不会重用常量池中的System.out.println(s1==s4);//false*//*常见面试题:问:在【String s = new String("hello")】中创建了几个对象?答:2个;第一个:字面量“hello”-------java会创建一个String对象表示字面量“hello”,并将其存入常量池。第二个:new String()-------new String()时会再创建一个字符串,并引用hello字符串的内容。*///例4:String s = new String("hello");//s1装的是new String()对象的地址 0x1111String ss1 = "hello";//s2装的是字面量“hello”的地址 0x2222System.out.println("s:"+s);//s:helloSystem.out.println("ss1:"+ss1);//s1:helloSystem.out.println(s==ss1);//false,s和ss1内容相同但地址值不同-------注:”==“比较的是地址//字符串实际开发中 用于比较相等的需求 都是比较字符串的内容//因此我们应该使用字符串提供的equals()方法来比较两个字符串的内容System.out.println(s.equals(ss1));//true,equals()比较的是内容是否相同/*说明:java的类都重写equals()了,-----像:String、StringBuilder重写都比较内容了我们自己定义的类必须自己重写equals()*/}
}例1和例2面试题:
常见面试题和例4面试题:
03.String的8种常用方法:
package apiday.day01.stringmethod;
import java.util.Locale;
/*** 《String的8种常用方法》:* ------1.用引用去打点调用的方法都是实例方法!* (1)int length():可以获取字符串的长度(字符个数)* (2)String trim():去除当前字符串两边的空白字符* (3)String ①toUpperCase()/②toLowerCase():将当前字符串中的英文部分转为①全大写/②全小写* (4)char charAt(int index):返回当前字符串指定位置上的字符-------------根据下标找字符* (5)String substring(int start,int end):截取当前字符串中指定范围内的字符串(含头不含尾–包含start,但不包含end)* 例:substring(2,7)————>截取2~6的范围的字符串* (6)boolean ①startsWith(String str)/②endsWith(String str):判断当前字符串是否是以给定的字符串开始的/结尾的* (7)int ①indexOf(String str)/②lastIndexOf(String str):检索给定字符串在当前字符串的开始位置/最后一次出现的位置* --------根据字符串找位置** ------2.用String打点访问:* (8)static String valueOf():String类中提供的静态方法,将其它数据类型转换为String**/
public class StringMethod {public static void main(String[] args) {/* (1)length():可以获取字符串的长度(字符个数) */String s = "我爱Java!";int len = s.length();//获取str的长度System.out.println(len);//7 即数组的长度/* (2)trim():去除当前字符串两边的空白字符 */String s1 = " hello world ";System.out.println(s1);//【 hello world 】s1 = s1.trim();System.out.println(s1);//【hello world】/* (3)①toUpperCase():将当前字符串中的英文部分转为全大写 */String s6 = "我爱Java!";String upper = s6.toUpperCase();//将s2的英文部分转换为全大写System.out.println(upper);//我爱JAVA!/* (3)②toLowerCase():将当前字符串中的英文部分转为全小写 */String ss6 = "我爱java!";upper = ss6.toLowerCase();//将ss2的英文部分转换为全小写System.out.println(upper);//我爱java!/* (4)charAt():返回当前字符串指定位置上的字符 */// 0123456789012345String s2= "thinking in Java";char c = s2.charAt(9);//获取位置9所对应的字符串System.out.println(c);//i/* (5)substring(int start,int end):截取当前字符串中指定范围内的字符串(含头不含尾–包含start,但不包含end) */// 01234567890String s4 = "www.tedu.cn";String name = s4.substring(4,8);//截到下标4到7范围的字符串System.out.println(name);//tedu//例:截取该网站的【tedu.cn】:有3种方式(注意含头不含尾)
// name = s4.substring(4,s4.length());//-----①从下边4开始一直截到末尾
// name = s4.substring(4,11);//--------------②从下边4开始一直截到末尾name = s4.substring(4);//-------------------③从下边4开始一直截到末尾,可以默认没有System.out.println(name);//tedu.cn/* (6)①startsWith(String str):判断当前字符串是否是以给定的字符串开始的 */String s7 = "I love Java";boolean starts = s7.startsWith("I love");//判断s3是否以【I love】开头的System.out.println(starts);//true/* (6)②endsWith(String str):判断当前字符串是否是以给定的字符串结尾的 */String ss7 = "123.png";boolean ends = ss7.endsWith(".png");//判断ss3是否以【.png】结尾的System.out.println(ends);//true/* (7)int ①indexOf(String str):检索给定字符串在当前字符串的开始位置 */// 01234567890String s8 = "I love java";int index = s8.indexOf("l");//检索【l】在字符串s8中出现的开始位置System.out.println(index);//2index = s8.indexOf("LO");//-----若当前字符串没有该字母,会返回【-1】System.out.println(index);//-1index = s8.indexOf("v",7);//从下标为2的位置开始找【lo】第一次出现的位置-------若找得到返回下标 否则返回-1System.out.println(index);//9/* (7)②lastIndexOf(String str):检索给定字符串在当前字符串中最后一次出现的位置 */// 01234567890123456789String ss8 = "I love java and Math";int lastindex = ss8.lastIndexOf("a");//找【v】最后一次出现的位置System.out.println(lastindex);//17/* (8)valueOf():String类中提供的静态方法,将其它数据类型转换为String */int a = 123;String s9 = String.valueOf(a);//将int型变量a转换为String类型并赋值给s9System.out.println(s9);//123-----字符串类型double d = 123.456;String s10 = String.valueOf(d);//将double型变量d转换为String类型并赋值给s10System.out.println(s10);//123.456----字符串类型String s11 = a+"";//任何内容和字符串连接的结果都是字符串,效率低System.out.println(s11);//123-----字符串类型}
}案例:用indexOf()和substring()截取上边的网址中域名:
package apiday.wanke.day01;
public class LocalTest {public static void main(String[] args) {String name1 = "www.tedu.cn";String name2 = "www.tarena.com.cn";String name3 = "http://www.google.com";String str1 = getName(name1);System.out.println(str1);//teduString str2 = getName(name2);System.out.println(str2);//tarenaString str3 = getName(name3);System.out.println(str3);//tedugoogle}/*** 案例:用indexOf()和substring()截取上边的网址中域名:* 获取给定网址中的域名的名字 line:网址 返回域名*/public static String getName(String line){//01234567890123456//www.tarena.com.cn 域名:就是第一个点和第二个点之间的字符串int start = line.indexOf(".")+1;//4 +1的目的是为了找到点后的第一个字符的位置int end = line.indexOf(".",start);//10 从start往后找第一个“.”的位置return line.substring(start,end);//含start,不含end}
}
04.String的连接性能-----差!
package apiday.day01.string0_0stringbuilder;
/*** 一、String类----------------------------------方便读(String连接性能差!)* 是不可变对象,每次修改内容都要创建新的对象,* 因此String不适用做频繁修改动作(内存中在不断new对象),* 为解决上面这个问题:Java提供了StringBuilder类-----方便改(用于提升String字符串的连接性能)* ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓** 二、* 1、StringBuilder类:——————是专门用于修改String的一个API* (1)内部维护一个可变的char数组,* (2)其API可以直接修改其内部数组的内容,* (3)修改速度、性能优秀。* (4)并且提供了修改字符串的常见的方法:增、删、改、插、翻转*/
public class String0_0StringBuilderDemo {public static void main(String[] args) {//一、测试String连接性能--------------差!//String不适合频繁修改内容long t1 = System.currentTimeMillis();String s = "a";for(int i=0;i<10000;i++){s = s+i;}long t2 = System.currentTimeMillis();System.out.println(t2-t1);//执行完for循环耗时346毫秒System.out.println("执行完毕"+s);//执行完毕a0123...99989999 }
}
2、String …(变长参数)-----是JDK5推出的一个新特性
(1)概念:
- 在Java5 中提供了变长参数(varargs),允许在调用方法时传入不定长度的参数。
(2)定义及调用
在定义方法时,在最后一个形参后加上三点 …,就表示该形参可以接受多个参数值,多个参数值被当成数组传入。上述定义有几个要点需要注意:
- 可变参数只能作为函数的最后一个参数,但其前面可以有也可以没有任何其他参数
- 由于可变参数必须是最后一个参数,所以一个函数最多只能有一个可变参数
- Java的可变参数,会被编译器转型为一个数组
- 变长参数在编译为字节码后,在方法签名中就是以数组形态出现的。这两个方法的签名是一致的,不能作为方法的重载。如果同时出现,是不能编译通过的。可变参数可以兼容数组,反之则不成立
《ArgsDemo.java》:package reflect;
import java.util.Arrays;
/*** JDK5之后推出了一个特性:变长参数*/
public class ArgsDemo {public static void main(String[] args) {doing(1,23,"one");doing(1,23,"one","two");doing(1,23,"one","three");doing(1,23,"one","three","four");}public static void doing(int age,long a,String... arg){/*可以将Varargs(即变长参数“...”)理解成里面封装数组的特殊类型。所以也可以进行遍历注意:可变长参数可以传入0个参数,数组不可以。
// for (int i = 0; i < arg.length; i++) {
// System.out.println(arg[i]);
// }for (int i : arg) {System.out.println(i);}*/System.out.println(arg.length); //arg的长度为1 2 3 4System.out.println(Arrays.toString(arg)); //在数组调用toString把数字转为字符串}
}
3、StringBuilder的性能好/6个常用方法、和StringBuffer区别:
01.String和StringBuilder的连接性能:
(1)如下例中String类型的连接性能不好,所以Java提供了 StringBuilder解决字符串连接性能问题。
- 简单理解StringBuilder性能好!重点!
package apiday.day01.string0_0stringbuilder;
/*** 一、String类----------------------------------方便读(String连接性能差!)* 是不可变对象,每次修改内容都要创建新的对象,* 因此String不适用做频繁修改动作(内存中在不断new对象),* 为解决上面这个问题:Java提供了StringBuilder类-----方便改(用于提升String字符串的连接性能)* ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓** 二、* 1、StringBuilder类:——————是专门用于修改String的一个API* (1)内部维护一个可变的char数组,* (2)其API可以直接修改其内部数组的内容,* (3)修改速度、性能优秀。* (4)并且提供了修改字符串的常见的方法:增、删、改、插、翻转*/
public class String0_0StringBuilderDemo {public static void main(String[] args) {/*//一、测试String连接性能--------------差!//String不适合频繁修改内容long t1 = System.currentTimeMillis();String s = "a";for(int i=0;i<10000;i++){s = s+i;}long t2 = System.currentTimeMillis();System.out.println(t2-t1);//执行完for循环耗时346毫秒System.out.println("执行完毕"+s);//执行完毕a0123...99989999*///二、测试StringBuilder连接性能---------好!long t1 = System.currentTimeMillis();StringBuilder builder = new StringBuilder("a");for(int i=0;i<10000;i++){builder.append(i);}long t2 = System.currentTimeMillis();System.out.println(t2-t1);//执行完for循环耗时4毫秒System.out.println("执行完毕:"+builder);//执行完毕:a012345........99989999}
}
02.StringBuilder类特有的5种常用方法:
StringBuilder类常见的方法:增、删、改、插、翻转
(1)append(int i/String str...):追加内容;当容量满了会自动扩容----括号里可包含:8种基本类型不含byte/str/[]/Obj....
注:StringBuilder的API返回的大多是当前对象,可以连续使用【.】调用方法【.append(...)】。 在StringBuilder的后面添加字符,当容量满了,会自动扩容, 扩容规则 1倍+2;
(2)delete(int start,int end):删除部分内容
(3)replace(int start,int end,String str):替换部分内容
(4)insert(int offset,String str):插入操作-------------------括号里第二个参可以是:8种基本类型不含byte/str/[]/Obj....
(5)reverse():将内容全部翻转
补充:toString():【便于访问时用String】和【进行增删改插翻时用StringBuilder的来回切换】。
package apiday.day01.string0_0stringbuilder;
/*** 一、String类----------------------------------方便读(String连接性能差!)* 是不可变对象,每次修改内容都要创建新的对象,* 因此String不适用做频繁修改动作(内存中在不断new对象),* 为解决上面这个问题:Java提供StringBuilder类-----方便改(用于提升String字符串的连接性能)* ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓** 二、* 1、StringBuilder类:——————是专门用于修改String的一个API* (1)内部维护一个可变的char数组,* (2)其API可以直接修改其内部数组的内容,* (3)修改速度、性能优秀。* (4)并且提供了修改字符串的常见的方法:增、删、改、插、翻转** 2、StringBuilder类常见的方法:增、删、改、插、翻转* (1)append(int i/String str...):追加内容;当容量满了会自动扩容----括号里可包含:8种基本类型不含byte/str/[]/Obj....* 注:StringBuilder的API返回的大多是当前对象,可以连续使用【.】调用方法【.append(...)】。* (2)delete(int start,int end):删除部分内容* (3)replace(int start,int end,String str):替换部分内容* (4)insert(int offset,String str):插入操作-------------------括号里第二个参可以是:8种基本类型不含byte/str/[]/Obj....* (5)reverse():将内容全部翻转** 3、toString():【便于访问时用String】和【进行增删改插翻时用StringBuilder的来回切换】。** 三、StringBuffer和StringBuilder区别?* StringBuffer:线程安全的,同步处理的,性能稍慢------不常用了* StringBuilder:非线程安全的,并发处理的,性能稍快----经常用*/
public class String0_0StringBuilderDemo {public static void main(String[] args) {/*//一、测试String连接性能--------------差!//String不适合频繁修改内容long t1 = System.currentTimeMillis();String s = "a";for(int i=0;i<10000;i++){s = s+i;}long t2 = System.currentTimeMillis();System.out.println(t2-t1);//执行完for循环耗时346毫秒System.out.println("执行完毕"+s);//执行完毕a0123...99989999//二、测试StringBuilder连接性能---------好!long t1 = System.currentTimeMillis();StringBuilder builder = new StringBuilder("a");for(int i=0;i<10000;i++){builder.append(i);}long t2 = System.currentTimeMillis();System.out.println(t2-t1);//执行完for循环耗时4毫秒System.out.println("执行完毕:"+builder);//执行完毕:a012345........99989999*//** 2、StringBuilder类常见的方法:增、删、改、插、翻转 */String s = "好好学学java";//复制str中的内容(好好学学java)到builder中StringBuilder sb = new StringBuilder(s);//(1)append():追加内容;当容量满了,会自动扩容// 01 2 34 56 78sb.append(",为了找个好工作!");System.out.println(sb);//好好学学java,为了找个好工作!sb.append("对不对");System.out.println(sb);//好好学学java,为了找个好工作!对不对//(2)delete():删除部分内容//0 1 23 456789 0 12 3 456 78 9//好好学学java,为了找个好工作!对不对sb.delete(17,20);//删除下标18~20的System.out.println(sb);//好好学学java,为了找个好工作!//(3)replace():替换部分内容//0 1 23 456789 0 12 3 456//好好学学java,为了找个好工作!sb.replace(0,16,"就是为了改变世界");//含头不含尾System.out.println(sb);//就是为了改变世界!//(4)insert():插入操作sb.insert(0,"活着,");//从下标0的位置插入System.out.println(sb);//活着,就是为了改变世界!//(5)reverse():将内容全部翻转sb.reverse();//翻转内容System.out.println(sb);//!界世变改了为是就,着活/** 3、toString():【便于访问时用String】和【进行增删改插翻时用StringBuilder的来回切换】。 */StringBuilder builder = new StringBuilder();//空字符串StringBuilder builder1 = new StringBuilder("abc");//abc串System.out.println(builder1);String str = "abc";//--------想访问用StringStringBuilder builder2 = new StringBuilder(str);//复制abc到builder2中System.out.println(builder2);//toString():可以将StringBuilder转换为StringString line = builder2.toString();System.out.println(line);/** 三、StringBuffer和StringBuilder区别?* StringBuffer:线程安全的,同步处理的,性能稍慢------不常用了* StringBuilder:非线程安全的,并发处理的,性能稍快----经常用* 注:一样的东西,但是StringBuffer不常用了。*/StringBuffer buffer3 = new StringBuffer();StringBuilder builder4 = new StringBuilder();}
}
03.StringBuffer和StringBuilder区别?
StringBuffer:线程安全的,同步处理的,性能稍慢------不常用了
StringBuilder:非线程安全的,并发处理的,性能稍快----经常用
注:一样的东西,但是StringBuffer不常用了。StringBuffer(线程安全):
StringBuffer对象则代表一个字符序列可变的字符串,当一个StringBuffer被创建以后,通过StringBuffer提供的 增删改插 等方法可以改变这个字符串对象的字符序列。
一旦通过StringBuffer生成了最终想要的字符串,就可以调用它的toString()方法将其转换为一个String对象。
——————————————————————————————————————————————————————————————————————————————————————
StringBuilder(非线程安全的):
StringBuilder类也代表可变字符串对象。
实际上,StringBuilder和StringBuffer基本相似,两个类的构造器和方法也基本相同。
因为没有实现线程安全功能,所以性能略高。
4、正则表达式
(1)概念:
正则表达式是用来描述字符串内容格式,使用它通常用来匹配一个字符串的内容是否符合要求
补充:
正则的概念:正则就是正则对象(RegExp),核心是正则表达式(规则字符串)。正则表达式: 对字符串操作的一种逻辑公式,就是用事先定义好的
一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,
这个“规则字符串”用来表达对字符串的一种过滤逻辑。
(2)语法:
正则表达式的语法:-----------了解、不用纠结、不用深入研究
例:在网站上经常用于检测用户输入数据是否符合规范:- 检测 用户名 是否为8~10数字 英文(大小写)- 检测 电话号码是否符合规范- 检测 邮箱地址是否符合规范 - 等
01.正则表达式的特殊字符:
- 1.字符集合:
- 2.预定义字符集:
- 3.量词:约定左侧元素的个数
- 4.特殊字符转义
- 5.分组:将一组规则作为整体进行处理:
1.字符集合:限制字符
[]:表示一个字符,该字符可以是[]中指定的内容
例如:
[abc]:这个字符可以是a或b或c
[^abc]:该字符只要不是a或b或c
[a-z]:表示任意一个小写字母
[a-zA-Z]:表示任意一个字母
[a-zA-Z0-9_]:表示任意一个数字字母下划线
[a-z&&[^bc]]:a~z中除了b和c以外的任意一个字符,其中&&表示“与”的关系2.预定义字符集:
.:表示任意一个字符,没有范围限制
\d:表示任意一个数字,等同于[0-9]
\w:表示任意一个单词字符,等同于[a-zA-Z0-9_]
\s:表示任意一个空白字符
\D:表示不是数字
\W:不是单词字符
\S:不是空白字符
补充:
在其他语言中,\\ 表示:我想要在正则表达式中插入一个普通的(字面上的)反斜杠,请不要给它任何特殊的意义。
在 Java 中,\\ 表示:我要插入一个正则表达式的反斜线,所以其后的字符具有特殊的意义。
所以,在其他的语言中(如 Perl),一个反斜杠 \ 就足以具有转义的作用,而在 Java 中正则表达式中则需要有两个反斜杠才能被解析为其他语言中的转义作用。也可以简单的理解在 Java 的正则表达式中,两个 \\ 代表其他语言中的一个 \,这也就是为什么表示一位数字的正则表达式是 \\d,而表示一个普通的反斜杠是 \\。
例:
System.out.print("\\"); // 输出为 \
System.out.print("\\\\"); // 输出为 \\3.量词:约定左侧元素的个数
?:表示前面的内容出现0-1次例如: [abc]? 可以匹配:a 或 b 或 c 或什么也不写
+:表示前面的内容最少出现1次例如: [abc]+ 可以匹配:b或aaaaaaaaaa...或abcabcbabcbabcbabcbabbabab....但是不能匹配:什么都不写 或 abcfdfsbbaqbb34bbwer...
*:表示前面的内容出现任意次(0-多次)---匹配内容与+一致,只是可以一次都不写例如: [abc]* 可以匹配:b或aaaaaaaaaa...或abcabcbabcbabcbabcbabbabab....或什么也不写但是不能匹配:abcfdfsbbaqbb34bbwer...
{n}:表示前面的内容出现n次例如: [abc]{3} 可以匹配:aaa 或 bbb 或 aab 或abc 或bbc但是不能匹配: aaaa 或 aad
{n,m}:表示前面的内容出现最少n次最多m次例如: [abc]{3,5} 可以匹配:aaa 或 abcab 或者 abcc但是不能匹配:aaaaaa 或 aabbd
{n,}:表示前面的内容出现n次以上(含n次)例如: [abc]{3,} 可以匹配:aaa 或 aaaaa.... 或 abcbabbcbabcbabcba....但是不能匹配:aa 或 abbdaw...
()用于分组,是将括号内的内容看做是一个整体例如: (abc){3} 表示abc整体出现3次. 可以匹配abcabcabc但是不能匹配aaa 或abcabc(abc|def){3}表示abc或def整体出现3次.可以匹配: abcabcabc 或 defdefdef 或 abcdefabc但是不能匹配abcdef 或abcdfbdef
量词补充:
x{n} 约定左侧x出现n次
x{n,m} 规定左侧x出现最少n次,最多m次
x{0,n} 规定左侧x出现0到n次
x{n,} 规定左侧x出现最少n次
x? 和x{0,1}等价,x可以没有或者有一个
x+ 和x{1,}等价,x至少有1个,多了随意,简称:一个以上
x* 和x{0}等价,x至少有0个,多了随意,简称:0个以上4.特殊字符转义:如何匹配字符 【[ ] ? + * .】 ,使用\特殊字符,进行转义!
\. 匹配点 --------重点!
\[] 匹配[
\? 匹配?
\* 匹配*
\+ 匹配+
\\ 匹配\5.分组:将一组规则作为整体进行
(red|blue|green):匹配red或者blue或者green;
02.如下对应例题:
(1)如上1.字符集合练习题:
例:匹配一个有效字符范围
Hello[1-6]
例:
package apiday02;
/*** 测试正则*/
public class RegDemo06 {public static void main(String[] args) {String reg = "Hello[123456]";//被测试的字符串String s1 = "Hello1";String s2 = "Hello7";//测试System.out.println(s1.matches(reg));//trueSystem.out.println(s2.matches(reg));//false}
}
(2)如上2.预定义字符集练习题:
例:
正则规则:\w\w\w\w\w\w
Java String : “\\w\\w\\w\\w\\w\\w”
测试案例:网站上规则 用户名是6个单词字符
package apiday01;
public class RegDome {public static void main(String[] args) {/*** 测试 用户名规则:6个单词字符组成* - \ 在Java字符串中需要进行转义为\*///正则表达式:可不可以写成:...... 6个点 不可以,范围太大了;逻辑错误String reg = "\\w\\w\\w\\w\\w\\w";System.out.println(reg);// \w\w\w\w\w\wSystem.out.println(a);//被检查的字符串String s1 = "Jerry1";//可以通过检查String s2 = "Tom-12";//不可以通过检查String s3 = "Andy";//不可以通过检查System.out.println(s1.matches(reg));//trueSystem.out.println(s2.matches(reg));//falseSystem.out.println(s3.matches(reg));//false}
}
(3)如上3.量词练习题:
①例1:\w\w\w\w\w\w 等价于 \w{6}
package apiday01;
public class RegDemo08 {public static void main(String[] args) {/*** 测试:网站的密码是单词字符,最少8个,多了不限\w{8}*///定义 网站密码的规则String reg = "\\w{8,}";// x{n,}:规定左侧x出现最少n次//定义 被检查的字符串String s1 = "asdfghjkl";//可以通过检查的字符串String s2 = "abcde";//不可以通过检查的字符串,太短了 (网站的密码是单词字符,最少8个,多了不限)String s3 = "asdfghjkl;";//不可以通过检查的字符串,包括“;”//System.out.println(s1.matches(reg));//trueSystem.out.println(s2.matches(reg));//falseSystem.out.println(s3.matches(reg));//false}
}②例2:- 网站的用户名是8~16个单词字符:\w{8,16}- 网站的密码是单词字符,最少8个,多了不限\w{8}- 匹配Hello World,中间至少有一个空白:Hello\s+World \s+ :至少一个,多了不限---不能匹配:"HelloWorld"---不能匹配:"Hello World!"-----能匹配: "Hello World"
package apiday01;
public class RegDemo09 {public static void main(String[] args) {/*** 测试:* Hello\s+World*///定义正则表达式:String reg = "Hello\\s+World";////定义被检查的字符串:String s1 = "HelloWorld";//不能通过检查String s2 = "Hello World";//能通过检查String s3 = "Hello World";//能通过检查String s4 = "Hello World";//能通过检查String s5 = "Hello World!";//不能通过检查//检查结果:System.out.println(s1.matches(reg));//falseSystem.out.println(s2.matches(reg));//trueSystem.out.println(s3.matches(reg));//trueSystem.out.println(s4.matches(reg));//trueSystem.out.println(s5.matches(reg));//false}
}
(4)如上4.特殊字符转义练习题:
例:如下正则的意义:匹配www.tedu.cn域名
① - - www.tedu.cn 匹配:- www.tedu.cn 通过- wwwAteduAcn 通过- www-tedu-cn 通过
②- - www\\.tedu\\.cn 匹配:- www.tedu.cn 通过- wwwAteduAcn 不通过- www-tedu-cn 不通过
package apiday02;
public class RegDemo10 {public static void main(String[] args) {/*** 测试 如何匹配 域名 www.tedu.cn* 必须使用正则表达式 www\.tedu\.cn* . 表示任意字符* 如果匹配. 就需要\.*///定义正则表达式:String reg1 = "www.tedu.cn";//错误的!String reg2 = "www\\.tedu\\.cn";//正确的//定义被检查的字符串:String s1 = "www.tedu.cn";String s2 = "wwwAteduAcn";String s3 = "www-tedu-cn";//测试reg1System.out.println(s1.matches(reg1));//trueSystem.out.println(s2.matches(reg1));//trueSystem.out.println(s3.matches(reg1));//true//测试reg2System.out.println(s1.matches(reg2));//trueSystem.out.println(s2.matches(reg2));//falseSystem.out.println(s3.matches(reg2));//false}
}
补充练习题:
案例:如何检查一个字符串是否为正确的IPV4地址
正确IP: "192.168.1.25"、 "192.168.199.1"、 "10.0.0.20"、"8.8.8.8"
错误IP: "10-10-10-20" 、"192点168点5点25"
正则:\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}- \d{1,3} \. \d{1,3} \. \d{1,3} \. \d{1,3}
注意:写在idea中反斜杠要写两次
(5)如上5.分组练习题
例1:正则
①\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}
②(\d{1,3}\.)(\d{1,3}\.)(\d{1,3}\.)(\d{1,3})
③(\d{1,3}\.){3} \d{1,3}
package apiday02;
public class RegDemo11 {public static void main(String[] args) {/*** 检查IP地址是否符合规则*///定义正则规则//String reg = "\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}";//:\.是匹配点 的String reg = "(\\d{1,3}\\.){3}\\d{1,3}";//括号里的后边重复了出现三次 用{3}表示//定义被检查的字符串String ip1 = "192.168.2.70";String ip2 = "10.0.0.20";String ip3 = "8.8.8.8";//定义错误的被检查字符串String ip4 = "192点168点2点70";String ip5 = "192-168-2-70";//检查System.out.println(ip1.matches(reg));//trueSystem.out.println(ip2.matches(reg));//trueSystem.out.println(ip3.matches(reg));//trueSystem.out.println(ip4.matches(reg));//falseSystem.out.println(ip5.matches(reg));//false}
}例2:如下①②③:
①`\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}`
②`\d{1,3}(\.\d{1,3})(\.\d{1,3})(\.\d{1,3})`
③ `\d{1,3}(\.\d{1,3}){3}`
区别是?:
①(\d{1,3}\.){3} \d{1,3} (分组){3} 分组的整体出现3次
②\d{1,3}\.{3}\d{1,3} \.{3}中的. 必须出现2次,可以匹配“192.168...”
5、String支持与正则表达式相关的3个方法(matches/split/replaceAll):
- 方法1: matches():使用给定的正则表达式验证当前字符串的格式是否符合要求
- !方法2: split():将当前字符串按照满足正则表达式的部分进行拆分
(将一个字符串劈开为几个子字符串) - 方法3: replaceAll():将当前字符串中满足正则表达式的部分替换为给定的字符串
(1)matches():使用给定的正则表达式验证当前字符串的格式是否符合要求
package apiday.day02.regularexpression;
/*** String字符串有三个比较常用的支持正则表达式的方法:* boolean matches(String regex)* 使用给定的正则表达式验证当前字符串的格式是否符合要求,符合则返回true,否则返回false*/
public class MatchesDemo1 {public static void main(String[] args) {/*邮箱的正则表达式:[a-zA-Z0-9_]+@[a-zA-Z0-9]+(\.[a-zA-Z]+)+*/String email = "wangkj@tedu.cn";String regex = "[a-zA-Z0-9_]+@[a-zA-Z0-9]+(\\.[a-zA-Z]+)+";boolean match = email.matches(regex);if(match){System.out.println("是正确的邮箱");}else{System.out.println("不是正确的邮箱");}/** 例2:测试正则表达式 *///定义正则表达式String rule = "HelloWorld";//定义被检测的字符串String s1 = "HelloKitty";String s2 = "HelloWorld";//检测 s1 是否符合规则boolean b1 = s1.matches(rule);//检测 s2 是否符合规则boolean b2 = s2.matches(rule);System.out.println(b1);System.out.println(b2);}
}
(2)split():将当前字符串按照满足正则表达式的部分进行拆分
-------------(将一个字符串劈开为几个子字符串)
package apiday.day02.regularexpression;
import java.util.Arrays;
/*** String支持正则表达式的第二个方法:拆分字符串* String[] split(String regex)* 将当前字符串按照满足正则表达式的部分进行拆分,并将拆分出的所有部分以String[]形式返回*/
public class SplitDemo2 {public static void main(String[] args) {String line = "abc123def456ghi";String[] data = line.split("[0-9]+"); //按数字拆分//将data数组按照字符串的格式输出:System.out.println(Arrays.toString(data));//[abc, def, ghi]line = "123,456,789,482";data = line.split(","); //按逗号拆分System.out.println(Arrays.toString(data));//[123, 456, 789, 482]line = "123.456.789.482";data = line.split("\\."); //按点拆分System.out.println(Arrays.toString(data));//[123, 456, 789, 482]//最开始就是可拆分项(.),那么数组中的第1个元素为一个空字符串------""//如果连续两个(两个以上)可拆分项,它们中间也会拆出一个空字符串-----""//如果末尾连续多个可拆分项,那么拆出的空字符串被忽略line = ".123.456..789.482.......";data = line.split("\\.");System.out.println(Arrays.toString(data));//[, 123, 456, , 789, 482]/*** 例题:* 根据给定正则表达式的匹配拆分此字符串。该方法的作用就像是* 使用给定的表达式和限制参数 0 来调用两参数 split 方法。* 因此,所得数组中不包括结尾空字符串。** 例如,字符串 "boo:and:foo" 使用这些表达式可生成以下结果:* Regex 结果* : { "boo", "and", "foo" }* o { "b", "", ":and:f" }*/String str = "boo:and:foo";String[] arr = str.split(":");for(int i=0;i<arr.length;i++){System.out.println(arr[i]);}//输出:// boo//and//foo//劈开时候,会自动舍弃后面的空字符串arr = str.split("o");for(int i=0;i<arr.length;i++){System.out.println(arr[i]);}// "boo:and:foo"// oo oo//输出://b////:and:f}
}
(3)replaceAll():将当前字符串中满足正则表达式的部分替换为给定的字符串
package apiday.day02.regularexpression;
import java.util.Scanner;
/*** 字符串支持正则表达式的第三个方法:替换* String replaceAll(String regex,String str)* 将当前字符串中满足正则表达式的部分替换为给定的字符串*/
public class ReplaceAllDemo3 {public static void main(String[] args) {String line = "abc123def456ghi";line = line.replaceAll("[0-9]+","#NUMBER#"); //将数字部分替换为#NUMBER#System.out.println(line);//案例:敏感词替换:Scanner scanner = new Scanner(System.in);System.out.println("请输入:");String str = scanner.nextLine();String s = str.replaceAll("我[去艹草靠]","***");System.out.println(s);}
}
三、Object(toString、equals):
Java Object 类是所有类的父类,Java 的所有类都继承了 Object,子类可以使用 Object 的所有方法。
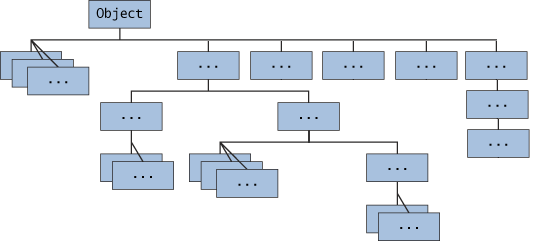
1.Object是所有类的鼻祖(顶级超类),所有类都直接或间接继承了Object,万物皆对象,为了多态
2.Object中有几个经常被派生类重写的方法:toString()和equals()还有hashCode()---这个在散列表才用(1)调用toString()时默认返回: 类的全称@地址,没有参考意义,所以常常重写toString()返回具体数据(2)调用equals()时默认比较的还是==(即比较地址),没有参考意义,所以常常重写equals()来比较具体的属性值
需要注意:java的类(String)已经重写equals()了,但我们自己定义的类中必须自己重写equals()后再去调用equals()比较的内容才会相等,否则即使调用equals()去比较的还是地址3)派生类重写equals()的基本规则:①两个对象必须是同一个类型,若类型不同则返回false②若参数对象为null,则返回false③原则上两个对象要比较对象的属性是否是相同三、==和equals的区别:(1)==:对于基本类型而言,比较的是数值是否相等对于引用类型而言,比较的是内存地址是否相等(2)equals:String中重写了equals(),用于比较字符串内容是否相同,若不重写equals()则默认调用Object中的equals()还是比较地址,所以equals()常常被重写来比较对象的数据是否相同
(1)toString():
(2)equals():注意==,作用是判定两个对象的地址是否相同!除了String类重写equals()后才是比较的内容!
补充:
1、equals()是object的方法
2、String类型的equals()重写了object的方法,所以此方法比较的是内容,不比较内存地址==比较内容和地址,因为String也属于引用数据类型注意:String是特殊的在声明对象时可以写new也可以不写(不写默认就是new)(总结:==比较内存地址和内容,equals()方法被重写只比较内容)
3、基本类型,如int,char,long,boolean。没有equals方法,只有==只比较值,因为基本数据类型存在栈里也不能new,最关键的一点是只有对象才能调方法(总结:基本数据类型只有==进行比较,只比较值)
4、引用数据类型,如Integer,Byte,Long,Character,Boolean引用数据类型是可以new的,而new出来的对象都会在堆中有开辟一个内存地址空间通常用==比较对象时,比较的就是内存地址和内容equals是用==判断两个对象是否相等,比较内存地址和内容,当两者都相等时才返回真(总结:引用数据类型除String特殊外,equals和==都比较内存地址和内容)
1.如果我有一个自定义类对象stu那么我比较两个对象是否相等,在没重写equals和hashcod方法时,是否用equals和==都可以?(是)
2.如果我比较这个对象中的某个属性是否等于某内容时,这个比较是否就要看我自定义类中的属性类型了?(如果说其中的属性是基本数据类型就只能用==比较值。如果是引用数据类型equals和==都行,比较内存地址和内容。如果是String类型equals比较内容,==比较内存地址和内容)package apiday.day02.object;
import java.util.Objects;
/** 测试常常被派生类重写的Object中的相关方法 */
public class Point {private int x;private int y;public Point(int x, int y) {this.x = x;this.y = y;}public int getX() {return x;}public void setX(int x) {this.x = x;}public int getY() {return y;}public void setY(int y) {this.y = y;}@Overridepublic String toString() {return "Point{"+"x=" + x +", y=" + y +'}';}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Point point = (Point) o;return x == point.x && y == point.y;}@Overridepublic int hashCode() {return Objects.hash(x, y);}
}package apiday.day02.object;
/*** Object:* Object是所有类的鼻祖(顶级超类),所有类都直接或间接继承了Object,万物皆对象,为了多态* Object中有几个经常被派生类重写的方法:toString()和equals()还有hashCode()---这个在散列表才用** 一、演示在什么场合下会用到Object中的什么方法?以及应当如何重写?* 1.第一个常被子类重新的Object中的方法是:toString()* (1)输出引用(即:对象p)会默认调用Object中的toString()* (2)字符串连接时会默认调用toString()* 为什么重写toString()? 答:调用toString()时默认返回:类的全称@地址,没有参考意义,所以常常重写toString()返回具体数据* 2.第二个常被子类重新的Object中的方法是:equals()* 为什么重写equals()? 答:调用equals()时默认比较的还是==(即比较地址),没有参考意义,所以常常重写equals()来比较具体的属性值* 需要注意:java的类(String)已经重写equals()了,但我们自己定义的类中必须自己重写equals()后再去调用equals()比较的内容才会相等,* 否则即使调用equals()去比较的还是地址** 二、派生类重写equals()的基本规则:* ①两个对象必须是同一个类型,若类型不同则返回false* ②若参数对象为null,则返回false* ③原则上两个对象要比较对象的属性是否相同** 三、==和equals的区别:* (1)==:对于基本类型而言,比较的是数值是否相等* 对于引用类型而言,比较的是内存地址是否相等* (2)equals:String中重写了equals(),用于比较字符串内容是否相同,* 若不重写equals()则默认调用Object中的equals()还是比较地址,* 所以equals()常常被重写来比较对象的数据是否相同**/
public class ObjectDemo {public static void main(String[] args) {Point p = new Point(1,2);//为什么重写toString()?
// 答:Point类若不重写Object类的toString()方法,则使用Object中定义了的toString(),
// 方法的返回字符串格式为:类的全称@地址(如下)
// 例:System.out.println(p);//apiday.day02.gettersetter.Point@28d93b30
// 但通常这个返回结束对我们的开发没有帮助,因此需要在Point类中重写toString()方法//一、1.第一个常被子类重新的Object中的方法是:toString()//(1)输出引用(即:对象p)会默认调用Object中的toString(),//相当于System.out.println(p.toString());System.out.println(p);//Point{x=1, y=2}//(2)字符串连接时会默认调用toString()//相当于 System.out.println(str.toString());String str = "这是一个Point:" + p;System.out.println(str);//这是一个Point:Point{x=1, y=2}/* 一、2.第二个常被子类重新的Object中的方法是equals() */Point p1 = new Point(1,2);Point p2 = new Point(1,2);System.out.println(p1==p2);//false,==比较的是地址//Object中自己定义的equals()内部还是使用==来比较//因此派生类在使用时若想比较内容,常常需要重写equals()//若派生类中重写equals(),则调用重写之后的比较/*二、派生类重写equals()的基本规则:①两个对象必须是同一个类型,若类型不同则返回false②若参数对象为null,则返回false③原则上两个对象要比较对象的属性是否相同*/System.out.println(p1.equals(p2));//true,因为重写equals()中比较的是x和y/*** 需要注意:java的类(String)已经重写equals()了,* 但我们自己定义的类中必须自己重写equals()后再去调用equals()比较的内容才会相等,* 否则即使调用equals()去比较的还是地址*///我们自己定义的类在使用时必须自行重写这个方法。//(1)只有String类的内部已经重写了equals(),重写后可以比较内容String s1 = new String("?????");String s2 = new String("?????");System.out.println(s1==s2);//falseSystem.out.println(s1.equals(s2));//true//(2)除了String类,其余类重写equals()比较的还是地址StringBuilder str1 = new StringBuilder("?????");StringBuilder str2 = new StringBuilder("?????");System.out.println(str1==str2);//falseSystem.out.println(str1.equals(str2));//false//(3)......//(4)......}
}
(1)Object中有几个经常被派生类重写的方法:toString()和equals()还有hashCode()---这个在散列表才用
(2)如果一个类没有明确指定父类,那么默认继承Object
(3)Object处于java.lang包之下,不需要导包可以直接使用
(4)toString()–我们日常使用最频繁的打印语句底层就调用了这个方法
如果没有重写这个方法,使用的是Object的默认实现,打印的是对象的地址值
如果重写以后,以重写的逻辑为准,比如String打印的是串的具体内容,比如ArrayList,打印的是[集合元素]
(5)hashCode()–用于返回对象对应的哈希码值
如果是一个对象多次调用这个方法,返回的是同一个哈希码值
如果是不同的对象调用这个方法,应该返回的是不同的哈希码值
(6)equals()–用于比较当前对象与参数对象是否相等
重写之前的默认实现比较的是两个对象的地址值
重写之后取决于重写的逻辑,比如String比较的是两个串的具体内容,比如自定义对象比较的是类型+属性值
(7)equals()与hashCode()应该保持一致【要重写都重写】
解释:equals()底层默认实现比较的是==比较,地址值,重写后我们一般比较的是对象的类型+属性值
hashCode()不同的对象生成的哈希码值不同,那么与equals()的逻辑不匹配,所以也应该重写
重写后,是根据对象的类型与属性值来生成哈希码值,这样二者就一致了
Object类的常用方法:
String toString() 返回此对象本身(它已经是一个字符串!)。
boolean equals(Object obj) 将此字符串与指定的对象比较,比较的是重写后的串的具体内容int hashCode() 返回此字符串的哈希码。
String concat(String str) 将指定字符串连接/拼接到此字符串的结尾,注意:不会改变原串
String[] split(String regex) 根据给定元素来分隔此字符串。
(8)Object 类可以显示继承,也可以隐式继承,以下两种方式时一样的:
显示继承:
public class Runoob extends Object{}隐式继承:
public class Runoob {}
四、包装类(自动拆装箱特性、两个常用功能)
- java
定义了8个包装类,目的是为了解决基本类型不能直接参与面向对象开发的问题,使得基本类型可以通过包装类的实例以对象的形式存在----其实就是给8种基本类型套了个壳 8个包装类:Integer、Character、Byte、Short、Long、Float、Double、Boolean
注:int的包装类:Integer char的包装类:Character。其余6种基本类型的包装类,首字母大写了- 其中
Character和Boolean是直接继承自Object的,而其余6个数字包装类都继承自java.lang.Number Number是一个抽象类,里边定义了一些方法,目的是让包装类可以将其表示的基本类型转换为其他数字类型.
01.JDK5之后--自动拆装箱特性:
---JDK5之后推出了一个新的特性:自动拆装箱。该特性是编译器认可以,当编译器编译时若发现有基本类型与包装类型相互赋值时,将会自动补充代码来完成他们的转换工作,这个过程称为自动拆装箱---注:装箱:把基本类型加个壳(即首字母大写)转为包装类02.包装类的常用功能:
(1)可以通过包装类来得到基本类型的取值范围:
(2)包装类提供了一个静态方法【parse(byte/int...)(引用)】,可以将字符串转换为对应的基本类型,前提是该字符串正确描述了基本类型可以保存得值,否则会抛出数字转换异常:NumberFormatExceptionpackage apiday.day02.packagingclass;
/*** 1、包装类:* (1)java定义了8个包装类,目的是为了解决基本类型不能直接参与面向对象开发的问题,* 使得基本类型可以通过包装类的实例以对象的形式存在----其实就是给8种基本类型套了个壳* (2)8个包装类:Integer、Character、Byte、Short、Long、Float、Double、Boolean* 注:int的包装类:Integer char的包装类:Character。其余6种基本类型的包装类,首字母大写了* (3)其中数字类型的包装类都继承自java.lang.Number,而char和boolean的包装类(Character和Boolean)直接继承自Object* (4)Number是一个抽象类,里边定义了一些方法,目的是让包装类可以将其表示的基本类型转换为其他数字类型.*** 01.自动拆装箱特性:* 装箱:把基本类型加个壳(即首字母大写)转为包装类* 拆箱:* (1)JDK5之后推出了一个新的特性:自动拆装箱。允许我们在基本类型与包装类型直接赋值,而无需做转换操作* (2)实际上是** 02.包装类的常用功能:* (1)可以通过包装类来得到基本类型的取值范围:* (2)包装类提供了一个静态方法【parse(byte/int...)(引用)】,可以将字符串转换为对应的基本类型,* 前提是该字符串正确描述了基本类型可以保存得值,否则会抛出数字转换异常:NumberFormatException*/
public class IntegerDemo {public static void main(String[] args) {/** 包装类: *//* -基本类型转换为包装类:------现在不用了*/int i = 123;//java推荐我们使用包装类的静态方法valueOf()将基本类型转换为包装类,而不是直接newInteger i1 = Integer.valueOf(i);//Integer会重用-128-127之间的整数对象Integer i2 = Integer.valueOf(i);System.out.println(i1==i2);//true //new则是false,valueOf在一字节之内是trueSystem.out.println(i1.equals(i2));//true/* -包装类转换为基本类型:------现在不用了*/int in = i1.intValue();//获取包装类对象中表示的基本类型值double doub = i1.doubleValue();System.out.println(in);//123System.out.println(doub);//123.0/** JDK5之后----自动拆装箱特性: *///触发编译器自动装箱特性:Integer it = 5;//会被编译为:Integer i1 = Integer.valueOf(5);//触发编译器自动拆箱特性:int ii = it;//会被编译为:int ii = i1.intValue();//————————>自动装箱时是由编译器默认调用Integer.valueOf()方法!//————————>对valueOf()方法有一个优化,若数字为-128~127之间的,则复用Integer aa = 100;//自动装箱,aa是一个对象Integer bb = 100;//自动装箱,因值在-128~127之间,所以复用了aa对象System.out.println(aa==bb);//true,因为复用了100那个对象Integer a = 200;//自动装箱,a是一个对象(因为Integer是一个引用类型)Integer b = 200;//自动装箱,b是一个对象,但数据不在应用范围内,所以b是另一个对象int c = 200;//没有装箱System.out.println(a==b); //false,因为这两个对象的地址不同System.out.println(a==c); //true,Integer和int对比时,Integer会自动拆箱为int类型/** 包装类的常用功能: *///(1)可以通过包装类来得到基本类型的取值范围:int max = Integer.MAX_VALUE;//获取int最大值int min = Integer.MIN_VALUE;//获取int最小值System.out.println(max);//2147483647System.out.println(min);//-2147483648Long max1 = Long.MAX_VALUE;Long min1 = Long.MIN_VALUE;System.out.println(max1);//9223372036854775807System.out.println(min1);//-9223372036854775808//(2)包装类提供了一个静态方法【parse(byte/int...)(引用)】,可以将字符串转换为对应的基本类型//前提是该字符串正确表达了基本类型的值//若不能正确表达,则发生NumberFormatException数字转换异常:/*String str = "123.456";//--------int不能正确表达【123.456】这个值,所以报数字转换异常int num = Integer.parseInt(str);System.out.println(num);//NumberFormatException---报异常了*/String str1 = "123";int num1 = Integer.parseInt(str1);//将字符串str转换为int类型System.out.println(num1);//123-------由字符串转为了int型的【123】str1 = "123.456";double dou = Double.parseDouble(str1);System.out.println(dou);//123.456}
}
五、二进制
1、二进制------重要:和16进制/16进制存在的原因/之间的换算
01.什么是二进制(重要)?
什么是2进制?
规则:逢二进一
数字:1 2 4 8 16 32 64
基数:2(以2为底)
权:128 64 32 16 8 4 2 1(1)如何查看整数的2进制存储情况?①java编译时候,会将10进制编译为2进制,然后按2进制来运算②【例:int a = 50;】 .java(50)——>编译后——>.class(110010)③Integer.toBinaryString()——>可以将底层的内存中2进制数显示出来System.out.println();—————>凡是在IDEA中直接输出,都是【将2进制转换为10进制输出】(2)①计算机为啥是2进制?——————————>便宜!成本优势明显!!!②如何将2进制转换为10进制?————>将1位置对应的权值累加求和注:int的二进制只能为32位:若数值开头用0b表示,显示2进制数时自动省略高位000000000 00000000 00000000 00000000 = 0
00000000 00000000 00000000 00000001 = 1
00000000 00000000 00000000 00000010 = 2
00000000 00000000 00000000 00000011 = 2+1 = 3
00000000 00000000 00000000 00000100 = 4
00000000 00000000 00000000 00000101 = 4+1 = 5
00000000 00000000 00000000 00000110 = 4+2 = 6
00000000 00000000 00000000 00000111 = 4+2+1=7
00000000 00000000 00000000 00001000 = 8
00000000 00000000 00000000 00001001 = 8+1=9
00000000 00000000 00000000 00001010 = 8+2=10
00000000 00000000 00000000 00001011 = 8+2+1=11
...
00000000 00000000 00000000 01101000 = 64+32+8=104练习题:
package apiday.day03.binary;
/*** 二进制演示 :* 1、什么是二进制? 答:逢二进一的计数规则(重要)* 规则:逢二进一* 数字:1 2 4 8 16 32 64* 基数:2(以2为底)* 权:128 64 32 16 8 4 2 1* 注:计算内部没有10进制,没有16进制,只有2进制!* (1)如何查看整数的2进制存储情况?* ①java编译时候,会将10进制编译为2进制,然后按2进制来运算* ②【例:int a = 50;】 .java(50)——>编译后——>.class(110010)* ③Integer.toBinaryString()——>可以将底层的内存中2进制数显示出来* System.out.println();—————>凡是在IDEA中直接输出,都是【将2进制转换为10进制输出】** (2)①计算机为啥是2进制?——————————>便宜!成本优势明显!!!* ②如何将2进制转换为10进制?————>将1位置对应的权值累加求和* 注:int的二进制只能为32位:若数值开头用0b表示,显示2进制数时自动省略高位0*/
public class BinaryDemo {public static void main(String[] args) {int n = 50;System.out.println(Integer.toBinaryString(n));//110010 ——>以2进制输出System.out.println(n);//50 ——>以10进制输出n++;//-----运行期间变量中存储的是2进制数System.out.println(Integer.toBinaryString(n));//110011 :——>n++编译时被编译为110011——>以2进制输出System.out.println(n);//51 ——>以10进制输出}
}
02.补充:什么是16进制(8进制)?
什么是十六进制:
1、什么是16进制?-----16进制字面量前缀:0x规则:逢16进1 10 11 12 13 14 15数字:0 1 2 3 4 5 6 7 8 9 a b c d e f基数:16(以16为底)权:128 64 32 16 8 4 2 1注:——————————————>计算内部没有10进制,没有16进制,只有2进制!
(1)用途:缩写2进制————>因为2进制书写非常繁琐,所以常用16进制缩写2进制如何缩写————>将2进制从最低位开始,每4位(8421)的2进制缩写为1位的16进制2进制: 00000000 00000000 00000000 0000000016进制:0000 0000 0000 0000 0000 0000 0000 0000———————————————————————————————————————————————例1:2进制: 0100 1111 0000 0101 0111 1010 1111 1110转为16进制:0x 4 f 0 5 7 a f e———————————————————————————————————————————————例2:2进制: 0110 0001 0100 1111 0111 1011 1011 1011转为16进制:0x 6 1 4 f 7 b b b练习题:
package apiday.day03.hex;
/*** 十六进制演示 :* 1、什么是16进制?-----16进制字面量前缀:0x* 规则:逢16进1 10 11 12 13 14 15* 数字:0 1 2 3 4 5 6 7 8 9 a b c d e f* 基数:16(以16为底)* 权:4096 256 16 1* 注:——————————————>计算内部没有10进制,没有16进制,只有2进制!* (1)用途:缩写2进制————>因为2进制书写非常繁琐,所以常用16进制缩写2进制* 如何缩写:———>将2进制从最低位开始,每4位(8421)的2进制缩写为1位的16进制** 2进制: 00000000 00000000 00000000 00000000* 16进制:0000 0000 0000 0000 0000 0000 0000 0000* ———————————————————————————————————————————————* 例:* 2进制: 0100 1111 0000 0101 0111 1010 1111 1110* 转为16进制:0x 4 f 0 5 7 a f e* (2)如何将16进制转为10进制? * 答:将本身数值的数[相对应]本身数值的权的[位数][相乘]的[和]相加即为10进制* 例1:因为16进制的权:256 16 1———>16进制【0x12】转为10进制:(1*16)+(2*1)———>即为18* 例2:因为 8进制的权:64 8 1———>8进制【067】转为10进制:(6*8)+(7*1)——————>即为55**/
public class HexDemo {public static void main(String[] args) {//2进制直接书写非常繁琐,16进制缩写2进制就非常方便,计算内部没有10进制,没有16进制,只有2进制!int n = 0x4f057afe;//0x表示16进制int m = 0b100_1111_0000_0101_0111_1010_1111_1110;//0b表示2进制---注:可以在数字中添加下划线,不影响数值System.out.println(Integer.toBinaryString(n));//1001111000001010111101011111110System.out.println(Integer.toBinaryString(m));//1001111000001010111101011111110System.out.println(n);//1325759230System.out.println(m);//1325759230/*** 问:将【0x12】和【0x4213】转为10进制是多少?* 答:因为16进制的权:4096 256 16 1* 16进制:0x12——————>转为10进制:(1*16)+(2*1)—————————————————————>即为18* 16进制:0x4213————>转为10进制:(4*4096)+(2*256)+(1*16)+(3*1)————>即为16915*/int o = 0x12;System.out.println(o);//18System.out.println(Integer.toBinaryString(o));//10010int p = 0x4213;System.out.println(p);//16915System.out.println(Integer.toBinaryString(p));//100001000010011/*** 补充:* 八进制:* 规则:逢8进1* 数字:0 1 2 3 4 5 6 7* 基数:8(以8为底)* 权:8^7 8^6 8^5 8^4 472 64 8 1** 问:【067】转为10进制是多少?* 答:因为8进制的权:64 8 1* 8进制:067—————>转为10进制:(6*8)+(7*1)—————>即为55*///------小面试题:(8进制平时不用)
// int y = 068;//068编译错误,因为8进制不能出现8int x = 067;//以数字0开始表明该数字是八进制System.out.println(x);//55-----以10进制输出(6个8加上7个1)System.out.println(Integer.toBinaryString(x));//110111}
}
03.补码
计算机最底层既表示正的又表示负的,怎么表示,就画条线为补码,两边为正数和负数:
以4位2进制为例画出补码图:


补码(complement):计算机中处理有符号数(正负数)的一种编码方式,Java中的补码最小类型是int,32位数1、以4位2进制为例讲解补码的编码规则:-------见补码图!(1)计算的时候如果超出4位数就自动溢出舍弃,保持4位数不变(2)将4位2进制数分一半作为负数使用(3)最高位称为符号位,高位为1时是负数;高位为0时是正数2、规律数:(1)0111为4位补码的最大值,规律:1个0和3个1,可以推导出:--32位补码的最大值是:1个0和31个1——————>(01111111111111111111111111111111)----【一般0会省略】(2)1000为4位补码的最小值,规律:1个1和3个0,可以推导出:--32位补码的最小值是:1个1和31个0——————>(10000000000000000000000000000000)(3)1111为4位补码的-1, 规律:4个1,可以推导出:--32位补码的-1是:32个1———————————————>(11111111111111111111111111111111)3、深入理解负值:—————> -1的编码是32个1如何求负值:——————> 用【-1减去0对应的权值】11111111111111111111111111111111 = -111111111111111111111111111111101 = -1-2 = -311111111111111111111111111111001 = -1-2-4 = -711111111111111111111111110010111 = -1-8-32-64 = -1054、互补对称仅限于二进制补码:————————>(正数到负数对称 负数到正数对称)验证补码的互补对称现象:一个数的补码=这个数取反+1——>公式:【-n = ~n+1】注:~:取反(2进制表示的两个数0和1互变之后用10进制表示的数)取反规则:0变1 1变0例:求-3的补码? 答:-3的补码=-3取反+1————>从地球图看-3取反为2,2加1=3-3用二进制表示:1101 -3取反用二进制表示:0010——>0010转为10进制为2——>所以2+1=3练习题:
package apiday.day03.binary;
/*** 补码(complement):* 计算机中处理有符号数(正负数)的一种编码方式,Java中的补码最小类型是int,32位数** 1、以4位2进制为例讲解补码的编码规则:-------见补码图!* (1)计算的时候如果超出4位数就自动溢出舍弃,保持4位数不变* (2)将4位2进制数分一半作为负数使用* (3)最高位称为符号位,高位为1时是负数;高位为0时是正数** 2、规律数:* (1)0111为4位补码的最大值,规律:1个0和3个1,可以推导出:* --32位补码的最大值是:1个0和31个1——————>(01111111111111111111111111111111)----【一般0会省略】* (2)1000为4位补码的最小值,规律:1个1和3个0,可以推导出:* --32位补码的最小值是:1个1和31个0——————>(10000000000000000000000000000000)* (3)1111为4位补码的-1, 规律:4个1,可以推导出:* --32位补码的-1是:32个1———————————————>(11111111111111111111111111111111)** 3、深入理解负值:—————> -1的编码是32个1* 如何求负值:——————> 用【-1减去0对应的权值】* 例:* 11111111111111111111111111111111 = -1* 11111111111111111111111111111101 = -1-2 = -3* 11111111111111111111111111111001 = -1-2-4 = -7* 11111111111111111111111110010111 = -1-8-32-64 = -105** 4、互补对称仅限于二进制补码:————————>(正数到负数对称 负数到正数对称)------位运算层面上的* 验证补码的互补对称现象:一个数的补码=这个数取反+1——>公式:【-n = ~n+1】* 注:~:取反(2进制表示的两个数0和1互变之后用10进制表示的数)* 取反规则:0变1 1变0* 例:求-3的补码? 答:-3的补码=-3取反+1————>从地球图看-3取反为2,2加1=3* -3用二进制表示:1101 -3取反用二进制表示:0010——>0010转为10进制为2——>所以2+1=3* (1)面试题*/
public class Complement {public static void main(String[] args) {/** 2、规律数: */int max = Integer.MAX_VALUE;System.out.println(Integer.toBinaryString(max));//1111..(控制台共打印31个1)---打印时第一个1前面的0会省略int min = Integer.MIN_VALUE;System.out.println(Integer.toBinaryString(min));//10000000000000000000000000000000System.out.println(Integer.toBinaryString(-1));//11111111111111111111111111111111/** 3、深入理解负值:-1的编码是32个1 ; 如何求负值:——————> 用【-1减去0对应的权值】*/int n = -1;System.out.println(Integer.toBinaryString(n));//11111111111111111111111111111111int n1 = -2;System.out.println(Integer.toBinaryString(n1));//11111111111111111111111111111110int n5 = -8;System.out.println(Integer.toBinaryString(n5));//11111111111111111111111111111000int n6 = -9;System.out.println(Integer.toBinaryString(n6));//11111111111111111111111111110111int n10 = -10;System.out.println(Integer.toBinaryString(n10));//11111111111111111111111111110110//例:将-20转为二进制如何表示?——————>-1-1-2-16————————得到下面打印的数int n20 = -20; //32 16 8 4 2 1System.out.println(Integer.toBinaryString(n20));//111111111111111111111111111 0 1 1 0 0/*** 4、面试题:* 前面代码的运算结果是(c) 注:求100的补码* A.-98 B.-99 C.-100 D.-101* System.out.println(~-100+1); 注:求-100的补码* A.98 B.99 C.100 D.101*/System.out.println(~100+1);//-100System.out.println(~-100+1);//100//例2:int k = 6;int l = ~n+1;System.out.println(l);//1int i = -3;int j = ~i+1;System.out.println(j);//3}
}
2、二进制运算
01.运算符号:
~ 取反
& 与
| 或
>>> 右移位运算
>> 数学右移位运算
<< 左移位运算
02.位运算(~、&、|、>>>(>>>和>>区别)、<<)
位运算:
0、~:取反(2进制表示的两个数0和1互变之后用10进制表示的数)(1)取反规则:0变1 1变01、&(与)运算(operation)-----逻辑乘法,见0则0(1)运算规则:运算时候将两个2进制数对其位,对应位置进行与运算例1:0 & 0 = 0 ; 0 & 1 = 01 & 0 = 0 ; 1 & 1 = 1例2: 1 7 9 d 5 d 9 ea = 00010111 10011101 01011101 10011110f fb = 00000000 00000000 00000000 11111111 8位掩码c =a&b 00000000 00000000 00000000 10011110上述代码的用途:将a的最后8位拆分出来,存储到c中b数称为掩码,8个1称为8位掩码上述运算称为:掩码运算2、|(或)运算----------------逻辑加法,见1则1(1)运算规则:运算的时候将两个数位对齐,对应的位进行 或 运算(2)计算的意义:上下两个数错位合并例: ( 6 d )a1 = 00000000 00000000 00000000 01011101( 9 d 0 0)b1 = 00000000 00000000 10011101 00000000c1=a1|b1 00000000 00000000 10011101 11011101如上案例的意义:错位合并3、>>>(右移位)运算(1)运算规则;将2进制数整体向右移动,低位自动溢出舍弃,高位补0例: ( 6 7 d 7 8 6 d )a2 = 110 01111101 01111000 01101101b2=a2>>>1 11 00111110 10111100 00110110c2=a2>>>2 1 10011111 01011110 00011011(2)>>>和>>的区别:①>>>逻辑右移位:数字向右移动,低位自动溢出,高位补0,结果没有数学意义。如果仅仅将数位向右移动,不考虑数学意义,则使用`>>>`②>> 数学右移位:数字向右移动,低位自动溢出,正数高位补0,负数高位补1,移动一次数学除以,小方向取整数。如果是替代数学 /2, 使用数学右移位。例:使用负数运算比较运算结果n = 11111111 11111111 11111111 11001100=-1-1-2-16-32=-52m=n>>1 11111111 11111111 11111111 11100110=-1-1-8-16=-26k=n>>2 11111111 11111111 11111111 11110011=-1-4-8=-13g=n>>3 11111111 11111111 11111111 11111100=-1-2-4=-7n>>>1 01111111 11111111 11111111 11100110= max-25没有数学意义4、<<(左移位)运算:(1)运算规则:将2进制数整体向左移动,高位自动溢出舍弃,低位补05、移位在数学中的意义:(1)>>>右移位数会变小 【/2】(2)<<左移位数会变大 【*2】 例:向左移动权 64 32 16 8 4 2 10 1 0 1 = 50 1 0 1 = 100 1 0 1 = 200 1 0 1 = 40练习题:
package apiday.day03.operation;
/*** 位运算:* 0、~:取反(2进制表示的两个数0和1互变之后用10进制表示的数)* (1)取反规则:0变1 1变0** 1、&(与)运算(operation)-----逻辑乘法,见0则0* (1)运算规则:运算时候将两个2进制数对其位,对应位置进行与运算* 例1:0 & 0 = 0 ; 0 & 1 = 0* 1 & 0 = 0 ; 1 & 1 = 1* 例2: 1 7 9 d 5 d 9 e* a = 00010111 10011101 01011101 10011110* f f* b = 00000000 00000000 00000000 11111111 8位掩码* c =a&b 00000000 00000000 00000000 10011110* 上述代码的用途:* 将a的最后8位拆分出来,存储到c中* b数称为掩码,8个1称为8位掩码* 上述运算称为:掩码运算** 2、|(或)运算----------------逻辑加法,见1则1* (1)运算规则:运算的时候将两个数位对齐,对应的位进行 或 运算* (2)计算的意义:上下两个数错位合并* 例: ( 6 d )* a1 = 00000000 00000000 00000000 01011101* ( 9 d 0 0)* b1 = 00000000 00000000 10011101 00000000* c1=a1|b1 00000000 00000000 10011101 11011101* 如上案例的意义:错位合并** 3、>>>(右移位)运算* (1)运算规则;将2进制数整体向右移动,低位自动溢出舍弃,高位补0* 例: ( 6 7 d 7 8 6 d )* a2 = 110 01111101 01111000 01101101* b2=a2>>>1 11 00111110 10111100 00110110* c2=a2>>>2 1 10011111 01011110 00011011* (2)>>>和>>的区别:* ①>>>逻辑右移位:数字向右移动,低位自动溢出,高位补0,结果没有数学意义。* 如果仅仅将数位向右移动,不考虑数学意义,则使用`>>>`* ②>> 数学右移位:数字向右移动,低位自动溢出,正数高位补0,负数高位补1,* 移动一次数学除以,小方向取整数。如果是替代数学 /2, 使用数学右移位。* 例:使用负数运算比较运算结果* n = 11111111 11111111 11111111 11001100=-1-1-2-16-32=-52* m=n>>1 11111111 11111111 11111111 11100110=-1-1-8-16=-26* k=n>>2 11111111 11111111 11111111 11110011=-1-4-8=-13* g=n>>3 11111111 11111111 11111111 11111100=-1-2-4=-7* n>>>1 01111111 11111111 11111111 11100110= max-25没有数学意义** 4、<<(左移位)运算:* (1)运算规则:将2进制数整体向左移动,高位自动溢出舍弃,低位补0** 5、移位在数学中的意义:* (1)>>>右移位数会变小 【/2】* (2)<<左移位数会变大 【*2】* 例:向左移动* 权 64 32 16 8 4 2 1* 0 1 0 1 = 5* 0 1 0 1 = 10* 0 1 0 1 = 20* 0 1 0 1 = 40***/
public class operation {public static void main(String[] args) {/** 1、&的运算-----逻辑乘法,见0则0 */int a = 0x179d5d9e;System.out.println(Integer.toBinaryString(a));//10111100111010101110110011110int b = 0xff;System.out.println(Integer.toBinaryString(b));// 11111111int c = a & b;System.out.println(Integer.toBinaryString(c));// 10011110/** 2、|的运算-----逻辑加法,见1则1 */int a1 = 0x6d;System.out.println(Integer.toBinaryString(a1));// 01101101int b1 = 0x9d00;System.out.println(Integer.toBinaryString(b1));//1001110100000000int c1 = a1 | b1;System.out.println(Integer.toBinaryString(c1));//1001110101101101/** 3、>>>(右移位) */int a2 = 0x67d786d;int b2 = a2>>>1;int c2 = a2>>>2;System.out.println(Integer.toBinaryString(a2));// 0110011111010111100001101101System.out.println(Integer.toBinaryString(b2));// 11001111101011110000110110System.out.println(Integer.toBinaryString(c2));// 1100111110101111000011011//(2)>>>和>>的区别:int n = -52;//0xffffffcc;int m = n>>1;int k = n>>2;int x = n>>>1;System.out.println(Integer.toBinaryString(n));//11111111111111111111111111001100System.out.println(Integer.toBinaryString(m));//11111111111111111111111111100110System.out.println(Integer.toBinaryString(k));//11111111111111111111111111110011System.out.println(Integer.toBinaryString(x));//1111111111111111111111111100110/** 4、<<(左移位)运算 */int a3 = 0x5e8e0dee;int b3 = a3<<1;int c3 = a3<<2;System.out.println(Integer.toBinaryString(a3));// 001011110100011100000110111101110System.out.println(Integer.toBinaryString(b3));// 010111101000111000001101111011100System.out.println(Integer.toBinaryString(c3));//1111010001110000011011110111000/** 5、移位在数学中的意义 *///(1)>>>右移位数会变小int a4 = 5;System.out.println(a4>>>1);//2System.out.println(a4>>>2);//1System.out.println(a4>>>3);//0//(2)<<左移位数会变大int a5 = 5;System.out.println(a5<<1);//10System.out.println(a5<<2);//20System.out.println(a5<<3);//40}
}
03.将一个整数拆分为4个字节
例:
b1 b2 b3 b4
n = 00010111 10011101 01011101 10011110
b1 = 00000000 00000000 00000000 00010111
b2 = 00000000 00000000 00000000 10011101
b3 = 00000000 00000000 00000000 01011101
b4 = 00000000 00000000 00000000 10011110代码:当n=-1;n=-3;n=max;n=min
int n = 0x179d5d9e;
int b1 = (n >>> 24) & 0xff
int b2 = (n >>> 16)& 0xff
int b3 = (n >>> 8) & 0xff;
int b4 = n & 0xff; //验证:按照二进制输出 n b1 b2 b3 b4
//当n=-1时,按照10进制输出是啥结果?
b1 = 00000000 00000000 00000000 0001011104.将4个字节合并为一个整数:
例:
b1 = 00000000 00000000 00000000 00010111
b2 = 00000000 00000000 00000000 10011101
b3 = 00000000 00000000 00000000 01011101
b4 = 00000000 00000000 00000000 10011110b1<<24 00010111 00000000 00000000 00000000
b2<<16 00000000 10011101 00000000 00000000
b3<<8 00000000 00000000 01011101 00000000
b4 00000000 00000000 00000000 10011110n = (b1<<24) | (b2<<16) | (b3<<8) | b4;代码:
int b1 = 0x17;
int b2 = 0x9d;
int b3 = 0x5d;
int b4 = 0x9e;
int n = (b1<<24) | (b2<<16) | (b3<<8) | b4;//按照2进制输出 b1 b2 b3 b3 n :
package apiday03;
public class Demo10 {public static void main(String[] args) {int b1 = 0x17;int b2 = 0x9d;int b3 = 0x5d;int b4 = 0x9e;int n = (b1<<24) | (b2<<16) | (b3<<8) | b4;System.out.println(Integer.toBinaryString(b1));//10111System.out.println(Integer.toBinaryString(b2));//10011101System.out.println(Integer.toBinaryString(b3));//1011101System.out.println(Integer.toBinaryString(b4));//10011110System.out.println(Integer.toBinaryString(n));//10111100111010101110110011110}
}
六、File类—>java.io.(File):(io:input输入 output:输出)
File类:——————>java.io.(File):(io:input输入 output:输出)
(1)File表示的是硬盘上的:文件/目录/抽象路径_.
(2)File类的每一个实例可以表示硬盘(文件系统)中的一个文件或目录(实际上表示的是一个抽象路径)
(3)用于表示文件系统中的一个抽象路径1、使用File可以做到:
01.访问其表示的文件或目录的属性信息,例如:名字,大小,修改时间等等(1)获取文件名:getName()(2)获取长度(单位是字节):long length()注:Java中(1个字母2个字节);写在文件中(1个字母1个字节;1个文字3个字节:1个原始字节信息+2个长度信息)(3)是否可读/写:boolean canRead/canWrite() 注:返回boolean型(4)是否隐藏:boolean isHidden()02.创建和删除文件(1)创建一个新文件:createNewFile()———>先判断是否存在:boolean exists(),若不存在则创建(2)删除一个文件:delete()————————————>先判断是否存在:boolean exists(),若存在则删除03.创建和删除目录———————————>注:mkdir是Linux中的一条命令(1)①创建一个目录:mkdir() 注:前提是创建目录的上一级必须存在;否则只会显示创建成功实际却没有创建-----所以不常用②创建一个目录:mkdirs() 注:创建目录时会将路径上所有不存在的目录一同创建(2)①删除一个目录:delete() 注:删除目录时为空目录才可以被删除;但可以逐级删除04.访问一个目录中的子项:———————>注:要想访问首先要获取当前目录(".")(1)列出当前目录的所有子项:File[] listFiles() 注:返回的数组中每个File元素表示其中的一个子项注:首先要判断该File是一个文件【boolean isFile()】还是目录【boolean isDirectory()】再用遍历来返回每一个子项05.获取目录中符合特定条件的子项:File[] listFiles(FileFilter filter)———>匿名内部类的方式————回调模式说明:该方法是用于抽象路径名的文件过滤器;会将该目录中每一个子项都作为参数先传给filter的accept()方法,只有accept()返回为true的子项最终才会被包含在返回的File[]数组中进行返回。注:File重载的方法 listFiles方法,允许我们传入一个文件过滤器从而可以有条件的获取一个目录中的子项。06.注:!!!File的API——————>不能访问文件中的具体内容
如上练习题:
package apiday.day03_chuanqi.file;
import java.io.File;
import java.io.FileFilter;
import java.io.IOException;
/*** File类:——————>java.io.(File):(io:input输入 output:输出)* (1)File表示的是硬盘上的:文件/目录/抽象路径_.* (2)File类的每一个实例可以表示硬盘(文件系统)中的一个文件或目录(实际上表示的是一个抽象路径)** 1、使用File可以做到:* 01.访问其表示的文件或目录的属性信息,例如:名字,大小,修改时间等等* (1)获取文件名:getName()* (2)获取长度(单位是字节):long length()* 注:Java中(1个字母2个字节);写在文件中(1个字母1个字节;1个文字3个字节:1个原始字节信息+2个长度信息)* (3)是否可读/写:boolean canRead/canWrite() 注:返回boolean型* (4)是否隐藏:boolean isHidden()** 02.创建和删除文件* (1)创建一个新文件:createNewFile()—————>先判断是否存在:boolean exists(),若不存在则创建* (2)删除一个文件:delete()————————————>先判断是否存在:boolean exists(),若存在则删除** 03.创建和删除目录————————————>注:mkdir是Linux中的一条命令* (1)①创建一个目录:mkdir() 注:前提是创建目录的上一级必须存在;否则只会显示创建成功实际却没有创建-----所以不常用* ②创建一个目录:mkdirs() 注:创建目录时会将路径上所有不存在的目录一同创建* (2)①删除一个目录:delete() 注:删除目录时为空目录才可以被删除;但可以逐级删除** 04.访问一个目录中的子项:——————>注:要想访问首先要获取当前目录(".")* (1)列出当前目录的所有子项:File[] listFiles() 注:返回的数组中每个File元素表示其中的一个子项* 注:首先要判断该File是一个文件【boolean isFile()】还是目录【boolean isDirectory()】* 再用遍历来返回每一个子项** 05.获取目录中符合特定条件的子项:File[] listFiles(FileFilter filter)———————>匿名内部类的方式————回调模式* 说明:该方法是用于抽象路径名的文件过滤器;会将该目录中每一个子项都作为参数先传给* filter的accept()方法,只有accept()返回为true的子项最终才会被包含在返回的File[]数组中进行返回。* 注:File重载的方法 listFiles方法,允许我们传入一个文件过滤器从而可以有条件的获取一个目录中的子项。** 06.注:!!!File的API——————>不能访问文件中的具体内容**/
public class FileDemo {public static void main(String[] args) throws IOException {/** 1、01.使用File访问当前项目目录下的demo.txt文件 *//*实际开发中我们不会使用绝对路径。虽然清晰明了,但是不利于跨平台。"./"是相对路径:表示当前目录;该目录就是【当前程序所在的项目目录】*///(1)获取文件名:getname()//例:在项目名下创建一个文件test包含demo.txt文件
// File file = new File("F:/danei/softone/Java/CGB2202/test/demo.txt");//绝对路径File file = new File("./test/demo.txt");//相对路径String name = file.getName();System.out.println("文件名:"+name);//文件名:demo.txt//(2)获取长度(单位是字节):long length()————————————————>注:返回的是long值,因为int最大值无法表示一个文件的最大容量long length = file.length();System.out.println("长度是:"+length+"字节");//长度是:18字节/*//注:Java中(1个字母2个字节);写在文件中(1个字母1个字节;1个文字3个字节:1个原始字节信息+2个长度信息)int s = '你';System.out.println(s);//20320 4 f 6 0System.out.println(Integer.toBinaryString(s));//100 1111 0110 0000int a = 0b100111101100000;System.out.println("转为10进制是:"+a);//转为10进制是:20320String s1 = "a";System.out.println("长度是"+s1.length()+"字节");//长度是1字节*///(3)是否可读/写:boolean canRead/canWrite()boolean cr = file.canRead();boolean cw = file.canWrite();System.out.println("可读:"+cr);//可读:trueSystem.out.println("可写"+cw);//可写true-----如果在demo.txt文件右键属性勾成只读,那么输出:可写:flase//(4)是否隐藏:boolean isHidden()boolean hidden = file.isHidden();//hidden:隐藏System.out.println("是否隐藏:"+hidden);//是否隐藏:false/** 02.创建和删除文件 *///①创建一个新文件:createNewFile()————>先判断是否存在:boolean exists(),若不存在则创建File f = new File("./test/demo2.txt");if(f.exists()){//exists:存在<——————判断当前File表示的文件或目录是否真实存在,存在则返回true。System.out.println("已存在");}else{f.createNewFile();//会爆红——————>因为createNewFile()底层需要抛出异常,按alt+enter再回车System.out.println("该文件已创建!");}//②删除一个文件:delete()————————————>先判断是否存在:boolean exists(),若存在则删除if(f.exists()){f.delete();System.out.println("该文件已删除!");}else{System.out.println("该文件不存在");}/** 03.创建和删除目录 *///(1)①创建一个目录:mkdir() 注:前提是创建目录的上一级必须存在;否则只会显示创建成功实际却没有创建//例:在当前目录下创建一个目录:demo
// File dir = new File("./test/demo");//———————————————>会创建成功File dir = new File("./a/test/demo");//——————>只会显示创建成功实际却没有创建if(dir.exists()){System.out.println("该目录已存在");}else{dir.mkdir();//①System.out.println("该目录已创建");//此时./(项目名下的路径)已经创建一个demo的目录(文件夹)}//(1)②创建一个目录:mkdirs() 注:创建目录时会将路径上所有不存在的目录一同创建File dir1 = new File("./test/a/demo");//——————>创建目录时会将路径上所有不存在的目录一同创建if(dir1.exists()){System.out.println("该目录已存在");}else{dir1.mkdirs();//②System.out.println("该目录已创建");//此时【./a/test/demo】下创建一个demo的目录(文件夹)}//(2)①删除一个目录:delete() 注:删除目录时为空目录才可以被删除;但可以逐级删除
// File dir2 = new File("./test");//————————————————>注:删除目录时为空目录才可以被删除File dir2 = new File("./test/a/demo");//——>注:但可以逐级删除,此时 a目录下的demo已经被删除if(dir2.exists()){//删除目录时只有空目录可以被删除dir2.delete();System.out.println("该目录已删除");}else{System.out.println("该目录不存在");}/** 04.访问一个目录的所有子项 注:要想访问首先要获取当前目录(".") *///(1)列出当前目录的所有子项:File[] listFiles() 首先要判断是一个文件【boolean isFile()】还是目录【boolean isDirectory()】File dir3 = new File(".");//列出“.”当前目录(即项目名)下的子项
// File dir3 = new File("./test");//列出“./test”目录下的子项/*判断当前File表示的是否为一个文件:boolean isFile()判断当前File表示的是否为一个目录:boolean isDirectory()*/if(dir3.isDirectory()) {File[] subs = dir3.listFiles();System.out.println("该“.”目录有"+subs.length+"个子项");//该“.”目录有6个子项for (int i = 0; i < subs.length; i++) {File sub = subs[i];System.out.println("这个目录的子项有:"+sub.getName());//这个目录的子项有:.git .idea......}}/** 05.获取目录中符合特定条件的子项:File[] listFiles(FileFilter filter)————————>回调模式 *//* 注:File重载的方法 listFiles方法,允许我们传入一个文件过滤器从而可以有条件的获取一个目录中的子项。*//*方法说明:该方法会将该目录中每一个子项都作为参数先传给filter的accept()方法,只有accept()返回为true的子项最终才会被包含在返回的File[]数组中进行返回。*///例1:获取当前目录中含有字母“o”的所有子项:File dir4 = new File(".");if(dir4.isDirectory()) {FileFilter filter = new FileFilter() { //FileFilter(文件过滤器)-------只用一次就写成匿名内部类!!!@Overridepublic boolean accept(File file) {System.out.println("正在过滤:"+file.getName());//正则过滤:.git .idea out ......return file.getName().contains("o");//含有o就返回true contains:包含}};File[] s = dir4.listFiles(filter);System.out.println("共有子项:" + s.length + "个");//共有子项:1个for (int i = 0; i < s.length; i++) {System.out.println("当前目录中含有字母“o”的子项为:"+s[i].getName());//当前目录中含有字母“o”的子项为:out}}//例2:获取【./src/apiday】目录下所有名字“d”开头的子项File dir5 = new File("./src/apiday");if(dir5.isDirectory()){FileFilter filter = new FileFilter() {//第一步:定义一个文件过滤器@Overridepublic boolean accept(File file1) {//第三步:定义一个过滤器的规则System.out.println("正在过滤元素:"+file1.getName());//第四步return file1.getName().contains("d");}};File[] s1 = dir5.listFiles(filter);//第二步:把这个过滤器传入File数组System.out.println("共有子项:" + s1.length + "个");//第五步:共有子项:4个for(int i=0;i<s1.length;i++){//第六步:当前目录中含有字母“d”的子项为:day01 day02 ...System.out.println("当前目录中含有字母“d”的子项为:"+s1[i].getName());}}}
}
01.使用递归操作删除一个目录
- 循环是重复执行某个步骤,而递归是重复整个过程。
package IVdayfile;
import java.io.File;
/*** 编写一个程序,要求实现1+2+3+4+....100并输出结果。* 代码中不能出现for,while关键字** 编写程序计算:* 一个人买汽水,1块钱1瓶汽水。3个瓶盖可以换一瓶汽水,2个空瓶可以换一瓶汽水。不考虑赊账问题* 问20块钱可以最终得到多少瓶汽水。** 删除一个多级目录*/
public class VdayTest {public static void main(String[] args) {File dir = new File("./a");delete(dir);}/*** 将给定的File对象表示的文件或目录删除:* @param file*/public static void delete(File file){if(file.isDirectory()){//清空目录:File[] subs = file.listFiles();//列出该文件for(int i=0;i< subs.length;i++){File sub = subs[i];//从目录中获取一个子项//将该子项删除:delete(sub);//递归调用:在一个方法的内部,调用自己的方法(循环整个过程) 而循环是重复步骤}}file.delete();}
}
七、lambda表达式:———>JDK8之后,java支持了lambda表达式这个特性
lambda表达式:————————————>JDK8之后,java支持了lambda表达式这个特性。
lambda可以使得程序员面向函数式编程
(1)lambda表达式就是一个代码块,以及必须传入代码的变量规范。
(2)lambda可以用更精简的代码创建匿名内部类.但是该匿名内部类实现的接口只能有一个抽象方法,否则无法使用!
(3)lambda表达式是编译器认可的,最终会将其改为内部类编译到.class文件中1、语法:
(参数列表)->{//方法体}2、lambda表达式精简在哪?(1)省去了接口名和方法名(2)参数类型也可以省略,如果方法只有一个参数时,那么参数的"()"也可以忽略(3)!如果方法体只有一句代码,那么可以将方法体"{}"忽略,如果含有return关键字则要一同忽略
package apiday.day03_chuanqi.lambda;
import java.io.File;
import java.io.FileFilter;
/*** lambda表达式:————————————>JDK8之后,java支持了lambda表达式这个特性。* lambda可以使得程序员面向函数式编程* (1)lambda表达式就是一个代码块,以及必须传入代码的变量规范。* (1)lambda可以用更精简的代码创建匿名内部类.但是该匿名内部类实现的接口只能有一个抽象方法,否则无法使用!* (2)lambda表达式是编译器认可的,最终会将其改为内部类编译到.class文件中** 1、语法:* (参数列表)->{* //方法体* }** 2、lambda表达式精简在哪?* (1)省去了接口名和方法名* (2)参数类型也可以省略,如果方法只有一个参数时,那么参数的"()"也可以忽略* (3)!如果方法体只有一句代码,那么可以将方法体"{}"忽略,如果含有return关键字则要一同忽略**/
public class LambdaDemo {public static void main(String[] args) {//例1:匿名内部类形式创建FileFilter文件过滤器:FileFilter filter = new FileFilter() { //FileFilter():为接口名public boolean accept(File file) {return file.getName().contains("o");}};/** 如上:用lambda精简上边的代码: *///(1)省去了接口名和方法名FileFilter filter1 = (File file) ->{return file.getName().contains("o");};//(2)参数类型也可以省略,如果方法只有一个参数时,那么参数的"()"也可以忽略FileFilter filter2 = file ->{return file.getName().contains("o");};//(3)!如果方法体只有一句代码,那么可以将方法体"{}"忽略,如果含有return关键字则要一同忽略FileFilter filter3 = file -> file.getName().contains("o");//例2:File dir = new File(".");FileFilter fileFilter = new FileFilter() {public boolean accept(File file) {return file.getName().contains("o");}};File[] sub = dir.listFiles(fileFilter);//(1)如上进一步精简成:File dir1 = new File(".");FileFilter fileFilter1 = file -> file.getName().contains("o");File[] sub1 = dir1.listFiles(fileFilter);//(2)如上再进一步精简成://lambda表达式也是编译器认可的,最终会被编译器改回成内部类创建的形式:File dir2 = new File(".");File[] subs = dir2.listFiles(file->file.getName().contains("o"));}
}
八、Java NIO(非阻塞)
00.简介 和 前言
01.简介:NIO(非阻塞) 和 传统BIO(阻塞):
(1)NIO(非阻塞) :面向Channel("通道")的;Channel是双向的,既可用来进行读操作,又可用来进行写操作。
(2)传统BIO(阻塞):面向Stream(流)的; Stream是单向的,流的特点:方向单一,顺序读写。流要么是InputStream(输入流)用于顺序读取数据的,要么OutputStream(输出流)用于顺序写出数据。传统IO(也叫BIO):
在Java1.4之前的I/O系统中,提供的都是面向流的I/O系统,系统一次一个字节地处理数据,
一个输入流产生一个字节的数据,一个输出流消费一个字节的数据,面向流的I/O速度非常慢。NIO(非阻塞):
在Java 1.4中推出了NIO,这是一个面向块的I/O系统,系统以块的方式处理处理,每一个操作在
一步中产生或者消费一个数据库,按块处理要比按字节处理数据快的多。
——————————————————————————————————————————————————————————————————
NIO与传统IO的区别?
:传统IO基于字节流和字符流进行操作。
:而NIO基于Channel和Buffer(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。Selector(选择区)用于监听多个通道的事件(比如:连接打开,数据到达)。 因此,单个线程可以监听多个数据通道。
——————————————————————————————————————————————————————————————————
NIO主要有三大核心部分:Channel(通道),Buffer(缓冲区), Selector(选择器)。
——————————————————————————————————————————————————————————————————
Channel
首先说一下Channel,国内大多翻译成“通道”。Channel和IO中的Stream(流)是差不多一个等级的。只不过Stream是单向的,譬如:InputStream, OutputStream.而Channel是双向的,既可以用来进行读操作,又可以用来进行写操作。
NIO中的Channel的主要实现有:
FileChannel
DatagramChannel
SocketChannel
ServerSocketChannel
这里看名字就可以猜出个所以然来:分别可以对应文件IO、UDP和TCP(Server和Client)。——————————————————————————————————————————————————————————————————
——————————————————————————————————————————————————————————————————
02.前言:
(1)阻塞(Block)和非租塞(NonBlock):
阻塞和非阻塞是进程在访问数据的时候,数据是否准备就绪的一种处理方式,当数据没有准备的时
候会阻塞:往往需要等待缞冲区中的数据准备好过后才处理其他的事情,否則一直等待在那里。非阻塞:当我们的进程访问我们的数据缓冲区的时候,如果数据没有准备好则直接返回,不会等待。如果数据已经准备好,也直接返回
01.NIO三大核心之1:Channel(通道)
Channel(通道)是一个对象,通过它可以读取和写入数据,当然了所有数据都通过Buffer对象
来处理。我们永远不会将字节直接写入通道中,相反是将数据写入包含一个或者多个字节的缓冲区。
同样不会直接从通道中读取字节,而是将数据从通道读入缓冲区,再从缓冲区获取这个字节。
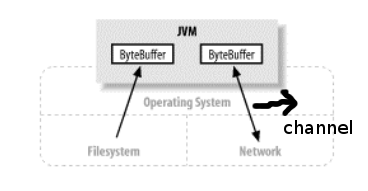
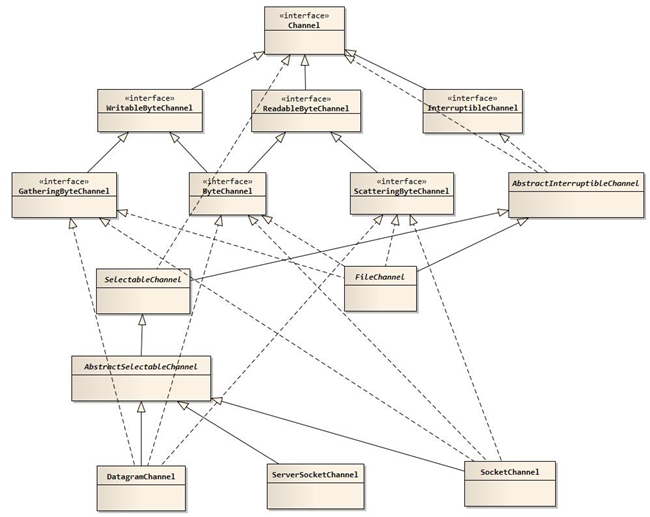
在NIO中,提供了多种通道对象,而所有的通道对象都实现了Channel接口。它们之间的继承关系如下图所示:
(1)使用NIO读取数据
在前面我们说过,任何时候读取数据,都不是直接从通道读取,而是从通道读取到缓冲区。
所以使用NIO读取数据可以分为下面三个步骤:从FileInputStream获取Channel创建Buffer将数据从Channel读取到Buffer中
例:
package com.charjay.nio.channel;
import java.io.FileInputStream;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
public class FileInputProgram { static public void main( String args[] ) throws Exception { FileInputStream fin = new FileInputStream("c:\\test.txt"); // 获取通道: FileChannel fc = fin.getChannel(); // 创建缓冲区: ByteBuffer buffer = ByteBuffer.allocate(1024); // 读取数据到缓冲区:fc.read(buffer); buffer.flip(); while (buffer.remaining() > 0) { byte b = buffer.get(); System.out.print(((char)b)); } fin.close();}
}
——————————————————————————————————————————————————————————————————
(2)使用NIO写入数据
使用NIO写入数据与读取数据的过程类似,同样数据不是直接写入通道,而是写入缓冲区,可以分为下面三个步骤:从FileInputStream获取Channel创建Buffer将数据从Channel写入到Buffer中
例:
package com.charjay.nio.channel;
import java.io.FileOutputStream;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
public class FileOutputProgram { static private final byte message[] = { 83, 111, 109, 101, 32, 98, 121, 116, 101, 115, 46 }; static public void main( String args[] ) throws Exception { FileOutputStream fout = new FileOutputStream( "e:\\test.txt" ); FileChannel fc = fout.getChannel(); ByteBuffer buffer = ByteBuffer.allocate( 1024 ); for (int i=0; i<message.length; ++i) { buffer.put( message[i] ); } buffer.flip(); fc.write( buffer ); fout.close(); }
}
02.NIO三大核心之2:Buffer(缓冲区)
缓冲区实际上是一个容器对象,更直接的说,其实就是一个数组,在NIO库中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中的; 在写入数据时,它也是写入到缓冲区中的;任何时候访问 NIO 中的数据,都是将它放到缓冲区中。而在面向流I/O系统中,所有数据都是直接写入或者直接将数据读取到Stream对象中。
在NIO中,所有的缓冲区类型都继承于抽象类Buffer,最常用的就是ByteBuffer,对于Java中的基本类型,基本都有一个具体Buffer类型与之相对应,它们之间的继承关系如下图所示:
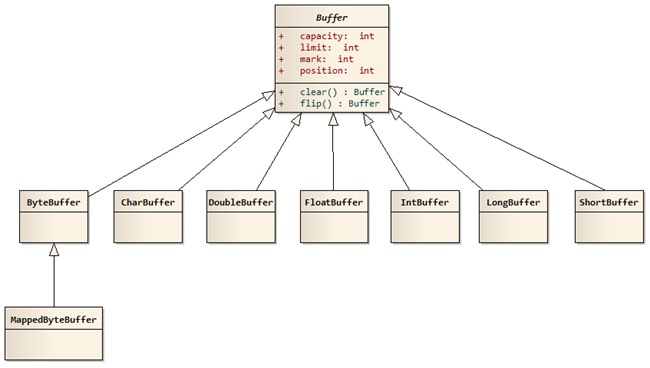
(1)其中的四个属性的含义分别如下:
容量(Capacity):缓冲区能够容纳的数据元素的最大数量。这一个容量在缓冲区创建时被设定,并且永远不能改变。上界(Limit):缓冲区的第一个不能被读或写的元素。或者说,缓冲区中现存元素的计数。位置(Position):下一个要被读或写的元素的索引。位置会自动由相应的get( )和put( )函数更新。标记(Mark):下一个要被读或写的元素的索引。位置会自动由相应的get( )和put( )函数更新。
——————————————————————————————————————————————————————————————————
(2)Buffer的常见方法如下所示:
flip(): 写模式转换成读模式
rewind():将 position 重置为 0 ,一般用于重复读。
clear():清除此缓冲区。位置设置为零,限制设置为容量,标记被丢弃。
compact():将未读取的数据拷贝到 buffer 的头部位。
mark():mark 可以标记一个位置
reset():reset 可以重置到该位置。
Buffer 常见类型: ByteBuffer 、 MappedByteBuffer 、 CharBuffer 、 DoubleBuffer 、 FloatBuffer 、 IntBuffer 、 LongBuffer 、 ShortBuffer 。
——————————————————————————————————————————————————————————————————
(3)基本操作
Buffer基础操作:
package com.charjay.nio.buffer;
import java.nio.IntBuffer;
public class TestIntBuffer {public static void main(String[] args) { // 分配新的int缓冲区,参数为缓冲区容量 // 新缓冲区的当前位置将为零,其界限(限制位置)将为其容量。它将具有一个底层实现数组,其数组偏移量将为零。 //分配了8个长度的int数组IntBuffer buffer = IntBuffer.allocate(8);
// capacity //数组的长度,容量for (int i = 0; i < buffer.capacity(); ++i) {int j = (i + 1); // 将给定整数写入此缓冲区的当前位置,当前位置递增 buffer.put(j); } // 重设此缓冲区,将限制设置为当前位置,然后将当前位置设置为0//固定缓冲区中的某些值,告诉缓冲区,我要开始操作了,如果你再往缓冲区写数据的话,不要再覆盖我固定状态以前的数据了buffer.flip();// 查看在当前位置和限制位置之间是否有元素while (buffer.hasRemaining()) { // 读取此缓冲区当前位置的整数,然后当前位置递增 int j = buffer.get(); System.out.print(j + " "); }}
}
缓冲区分片,缓冲区分配,直接缓存区,缓存区映射,缓存区只读:链接
——————————————————————————————————————————————————————————————————
(4)缓冲区存取数据流程
存数据时:position会++,
当停止数据读取的时候:调用flip(),此时limit=position,position=0
读取数据时:position++,一直读取到limit
clear():清空 buffer ,准备再次被写入 (position 变成 0 , limit 变成 capacity) 。
03.NIO三大核心之3:Selector(选择器)
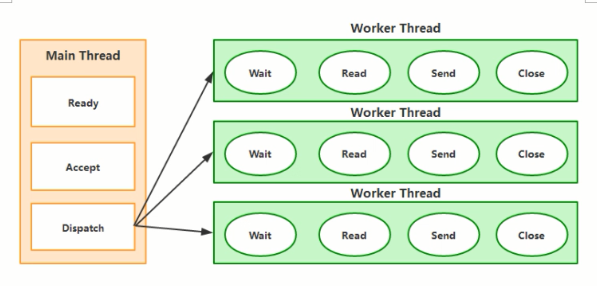
传统的 server / client 模式会基于 TPR ( Thread per Request ) .服务器会为每个客户端请求建立一个线程.由该线程单独负贵处理一个客户请求。
这种模式带未的一个问题就是线程数是的剧增:大量的线程会增大服务器的开销,大多数的实现为了避免这个问题,都采用了线程池模型,并设置线程池线程的最大数量。
这又带来了新的问题,如果线程池中有 200 个线程,而有 200 个用户都在进行大文件下载,会导致第 201 个用户的请求无法及时处理,即便第 201 个用户只想请求一个几 KB 大小的页面。传统的 Sorvor / Client 模式如下围所示:
NIO 中非阻塞IO采用了基于Reactor模式的工作方式,IO调用不会被阻塞,相反是注册感兴趣的特点IO事件,如可读数据到达,新的套接字等等。
在发生持定率件时,系统再通知我们。 NlO中实现非阻塞IO的核心设计Selector,Selector就是注册各种IO事件的地方,而且当那些事件发生时,就是这个对象告诉我们所发生的事件。
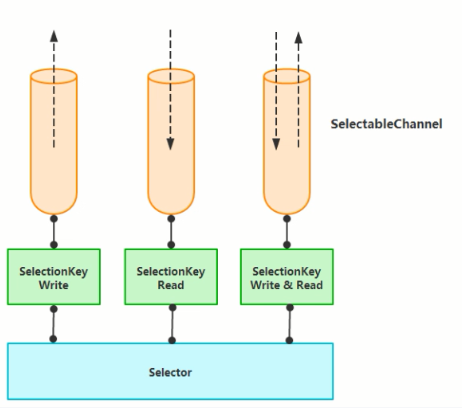
当有读或者写等任何注册的事件发生时,可以从Selector中获得相应的SelectionKey,同时从SelectionKey中可以找到发生的事件和该事件所发生的具体的SelectableChannel,以获得客户端发送过来的数据。
使用NIO中非阻塞IO编写服务器处理程序,有三个步骤
1.向Selector对象注册感兴趣的事件
2.从Selector中获取感兴趣的事件
3.根据不同事件进行相应的处理
04.NIO(非阻塞) 和 传统IO(也叫BIO:阻塞)对比
(1)区别:
IO模型 IO NIO
方式 从硬盘到内存 从内存到硬盘
通信 面向流(乡村公路) 面向缓存(高速公路,多路复用技术)
处理 阻塞IO(多线程) 非阻塞IO(反应堆Reactor)
触发 无 选择器(轮询机制)
——————————————————————————————————————————————————————————————————
(2)面向流与面向缓冲
Java NIO和IO之间第一个最大的区别是:IO是面向流的;NIO是面向缓冲区的
IO是面向流的:Java IO面向流意味着毎次从流中读一个成多个字节,直至读取所有字节,它们没有被缓存在任何地方,此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的教据,需要先将它缓存到一个缓冲区。NIO是面向缓冲区的:Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,霱要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数裾。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
——————————————————————————————————————————————————————————————————
(3)阻塞与非阻塞
IO的各种流是阻塞的:这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。 NIO的非阻塞模式:使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果 目前没有数据可用时,就什么都不会获取。而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
——————————————————————————————————————————————————————————————————
(4)NIO和BIO读取文件
BIO读取文件:从一个阻塞的流中一行一行的读取数据。
NIO读取文件:块读。通道是数据的载体,buffer是存储数据的地方,线程每次从buffer检查数据通知给通道
——————————————————————————————————————————————————————————————————
(5)处理数据的线程数
BIO:一个线程管理一个连接
NIO:一个线程管理多个连接
05.NIO练习题:重要!!!
Java NIO:称为非阻塞IO
java.nio:
(1)概述:①全称java non-blocking IO,是指jdk1.4 及以上版本里提供的新api(New IO).为所有的原始类型(boolean类型除外)提供缓存支持的数据容器,使用它可以提供非阻塞式的高伸缩性网络。——————>!!!《我们之前所学习的流(Stream),称为BIO ; 阻塞是IO,就是在读写的过程中可能会发生阻塞现象。》②非阻塞IO面向Channel("通道")的,不是面向Stream(流)的。注:流的特点:方向单一,顺序读写。流要么是输入流用于顺序读取数据的,要么是输出流用于顺序写出数据。(2)NIO 编程:Unblocking IO(New IO): 同步非阻塞的编程方式。NIO本身是基于事件驱动思想来完成的,其主要想解决的是BIO的大并发问题.NIO基于Reactor,当socket有流可读或可写入socket时,操作系统会相应的通知引用程序进行处理,应用再将流读取到缓冲区或写入操作系统。也就是说,这个时候,已经不是一个连接就要对应一个处理线程了,而是有效的请求,对应一个线程,当连接没有数据时,是没有工作线程来处理的。NIO的最重要的地方是当一个连接创建后,不需要对应一个线程,这个连接会被注册到多路复用器上面,所以所有的连接只需要一个线程就可以搞定,当这个线程中的多路复用器进行轮询的时候,发现连接上有请求的话,才开启一个线程进行处理,也就是一个请求一个线程模式。在NIO的处理方式中,当一个请求来的话,开启线程进行处理,可能会等待后端应用的资源(JDBC连接等),其实这个线程就被阻塞了,当并发上来的话,还是会有BIO一样的问题01.NIO API:————>面向Channel("通道"),不是面向Stream(流)的。channel:通道,特点:(双向的,即可以读又可以写)。常见的实现:(1)Buffer缓冲区:通道是对缓冲区(Buffer缓冲区)中的数据进行读写操作。常见的缓冲区实现:ByteBuffer:字节缓冲区,缓冲区内部内容都是字节Buffer API:①flip():翻转此缓冲区。限制设置为当前位置,然后位置设置为零。②clear():清除此缓冲区。位置设置为零,限制设置为容量,标记被丢弃。(2)FileChannel:文件通道,可对文件进行读写操作。①int read(ByteBuffer dst):从此通道中读取一个字节序列到给定的缓冲区中。(从该通道的当前文件位置开始读取字节,然后使用实际读取的字节数更新文件位置)②int write(ByteBuffer src):从给定的缓冲区将字节序列写入此通道。字节从该通道的当前文件位置开始写入,除非通道处于附加模式,在这种情况下,该位置首先前进到文件的末尾。如有必要,文件会增长以容纳写入的字节,然后使用实际写入的字节数更新文件位置。注:write在写出一个缓冲区数据时,写出的也是缓冲区中position与limit之间的数据总结:Channel(通道)在进行或读写操作时,具体可以读取多少字节或写出多少字节是取决于我们传入的Buffer 中 position到limit之间的空间(3)SocketChannel:套接字通道,可以与远端计算机进行TCP读写操作。(4)ServerSocketChannel:服务端的套接字通道,用于接听客户端的连接。package apiday.io.NIO;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
/*** Java NIO:称为非阻塞IO* java.nio:* (1)概述:①全称java non-blocking IO,是指jdk1.4 及以上版本里提供的新api(New IO).* 为所有的原始类型(boolean类型除外)提供缓存支持的数据容器,使用它可以提供非阻塞式的高伸缩性网络。* ——————>!!!《我们之前所学习的流(Stream),称为BIO ; 阻塞是IO,就是在读写的过程中可能会发生阻塞现象。》* ②非阻塞IO面向Channel("通道")的,不是面向Stream(流)的。* 注:流的特点:方向单一,顺序读写。流要么是输入流用于顺序读取数据的,要么是输出流用于顺序写出数据。* (2)NIO 编程:Unblocking IO(New IO): 同步非阻塞的编程方式。* NIO本身是基于事件驱动思想来完成的,其主要想解决的是BIO的大并发问题.* NIO基于Reactor,当socket有流可读或可写入socket时,操作系统会相应的通知引用程序进行处理,* 应用再将流读取到缓冲区或写入操作系统。也就是说,这个时候,已经不是一个连接就要对应一个处理线程了,而是有效的请求,* 对应一个线程,当连接没有数据时,是没有工作线程来处理的。NIO的最重要的地方是当一个连接创建后,不需要对应一个线程,* 这个连接会被注册到多路复用器上面,所以所有的连接只需要一个线程就可以搞定,当这个线程中的多路复用器进行轮询的时候,* 发现连接上有请求的话,才开启一个线程进行处理,也就是一个请求一个线程模式。* 在NIO的处理方式中,当一个请求来的话,开启线程进行处理,可能会等待后端应用的资源(JDBC连接等),* 其实这个线程就被阻塞了,当并发上来的话,还是会有BIO一样的问题** 01.NIO API:————>面向Channel("通道"),不是面向Stream(流)的。* channel:通道,特点:(双向的,即可以读又可以写)。常见的实现:* (1)Buffer缓冲区:通道是对缓冲区(Buffer缓冲区)中的数据进行读写操作。* 常见的缓冲区实现:ByteBuffer:字节缓冲区,缓冲区内部内容都是字节* Buffer API:* ①flip():翻转此缓冲区。限制设置为当前位置,然后位置设置为零。* ②clear():清除此缓冲区。位置设置为零,限制设置为容量,标记被丢弃。** (2)FileChannel:文件通道,可对文件进行读写操作。* ①int read(ByteBuffer dst):从此通道中读取一个字节序列到给定的缓冲区中。* (从该通道的当前文件位置开始读取字节,然后使用实际读取的字节数更新文件位置)* ②int write(ByteBuffer src):从给定的缓冲区将字节序列写入此通道。* 字节从该通道的当前文件位置开始写入,除非通道处于附加模式,在这种情况下,* 该位置首先前进到文件的末尾。如有必要,文件会增长以容纳写入的字节,然后使用实际写入的字节数更新文件位置。* 注:write在写出一个缓冲区数据时,写出的也是缓冲区中position与limit之间的数据* 总结:Channel(通道)在进行或读写操作时,具体可以读取多少字节或写出多少字节* 是取决于我们传入的Buffer 中 position到limit之间的空间** (3)SocketChannel:套接字通道,可以与远端计算机进行TCP读写操作。* (4)ServerSocketChannel:服务端的套接字通道,用于接听客户端的连接。**/
public class NIO {public static void main(String[] args) throws IOException {/** (1)BIO 和 NIO对文件复制的两种方式:*//** (1)BIO(传统IO流)的文件复制工作,使用流(Stream)的方式进行复制:*/
// FileInputStream fis = new FileInputStream("./test/halou.mp4");
// FileOutputStream fos = new FileOutputStream("./test/halou_01.mp4");
// byte[] buffer = new byte[1024*10];
// int len;//记录每次读取到的字节数
// while((len=fis.read(buffer))!=-1){
// fos.write(buffer,0,len);
// }
// System.out.println("复制完毕");
// fis.close();
// fos.close();/** (2)NIO的文件复制工作,使用通道(Channel)的方式进行复制: */FileInputStream fis = new FileInputStream("./test/halou.mp4");//基于文件输入流获取一个用于读取该文件的文件通道:FileChannel inChannel = fis.getChannel();FileOutputStream fos = new FileOutputStream("./test/halou_02.mp4");FileChannel outChannel = fos.getChannel();//创建一个字节缓冲区:ByteBuffer buffer = ByteBuffer.allocate(1024*10);//创建一个10k大小缓冲区int len;//记录每次实际读取的数据量/*(1)缓冲区重要的几个属性:position:当前位置,用来表示当前缓冲区已经有多少数据被操作了limit:缓冲区最大可以操作的位置capacity:容量,指缓冲区的大小默认创建一个缓冲区时:position = 0limit = capacitycapacity = 创建缓冲区时指定的大小position = 0limit = 10240一次最多读取数据为:position到limt之间的数据量limit-position = 10240由于position的位置与limit一致,因此表示目前缓冲区已经没有空余可操作的空间了*/
// //进行第一次读操作 前和后的变化:
// //进行第一次读操作读取前buffer状态——>position=0 limit=10240
// System.out.println("进行第一次读操作 读取前buffer状态——>"+"position="+buffer.position()+" "+"limit="+buffer.limit());
// len = inChannel.read(buffer);//从通道中读取数据到缓冲区中
// //进行第一次读操作读取后buffer状态——>position=10240 limit=10240
// System.out.println("进行第一次读操作 读取后buffer状态——>"+"position="+buffer.position()+" "+"limit="+buffer.limit());
//
// //进行第二次读操作 前和后的变化:
// //进行第二次读操作读取前buffer状态——>position=10240 limit=10240
// System.out.println("进行第二次读操作 读取前buffer状态——>"+"position="+buffer.position()+" "+"limit="+buffer.limit());
// len = inChannel.read(buffer);//从通道中读取数据到缓冲区中
// //进行第二次读操作读取后buffer状态——>position=10240 limit=10240
// System.out.println("进行第二次读操作 读取后buffer状态——>"+"position="+buffer.position()+" "+"limit="+buffer.limit());/** 完成一轮复制:*//*读取前:position = 0limit = 10240int read(ByteBuffer dst):从此通道中读取一个字节序列到给定的缓冲区中。(从该通道的当前文件位置开始读取字节,然后使用实际读取的字节数更新文件位置)*/
// len = inChannel.read(buffer);//一次读取了10k数据/*读取后:position = 10240limit = 10240*//*int write(ByteBuffer src):从给定的缓冲区将字节序列写入此通道。字节从该通道的当前文件位置开始写入,除非通道处于附加模式,在这种情况下,该位置首先前进到文件的末尾。如有必要,文件会增长以容纳写入的字节,然后使用实际写入的字节数更新文件位置。注:write在写出一个缓冲区数据时,写出的也是缓冲区中position与limit之间的数据总结:Channel(通道)在进行或读写操作时,具体可以读取多少字节或写出多少字节是取决于我们传入的Buffer 中 position到limit之间的空间flip():翻转此缓冲区。限制设置为当前位置,然后位置设置为零。*/
// buffer.flip();/*flip后:position = 0limit = 10240*/
// outChannel.write(buffer);//向文件halou_02.mp4文件中写出10k,但此时发现该文件实际大小为0k,证明没有写到文件里数据/*position = 10240limit = 10240*//** 完整的复制动作:*//*clear():清除此缓冲区。位置设置为零,限制设置为容量,标记被丢弃。*/while((len = inChannel.read(buffer))!=-1){buffer.flip();outChannel.write(buffer);buffer.clear();}}
}
06.注:JAVA NIO部分的01-04原文参考:
https://blog.csdn.net/CharJay_Lin/article/details/81810922?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165016700216780357247035%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=165016700216780357247035&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-1-81810922.142^v9^pc_search_result_cache,157^v4^control&utm_term=NIO&spm=1018.2226.3001.4187
九、Java IO(阻塞)
1、IO流(字节流结尾为stream----字符流结尾为read或writer)
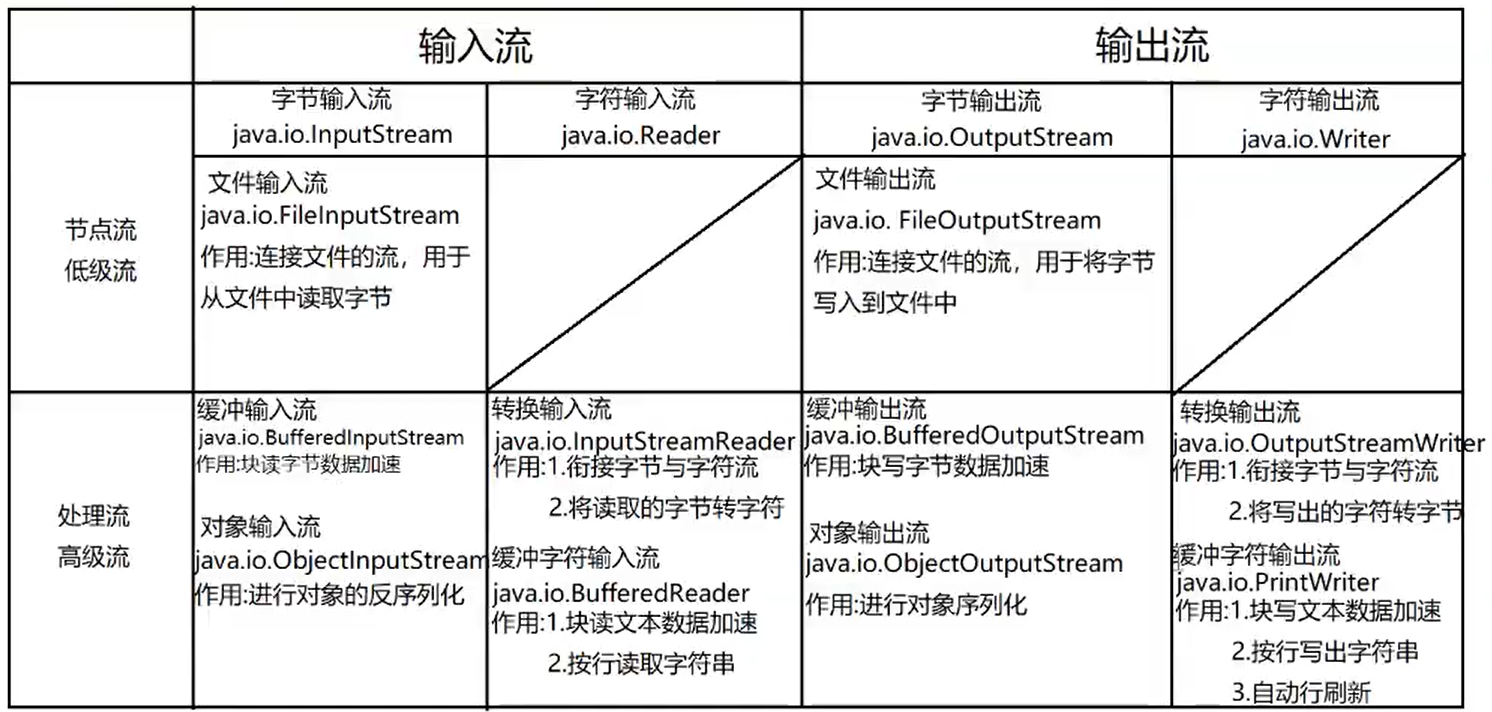 例:
例:
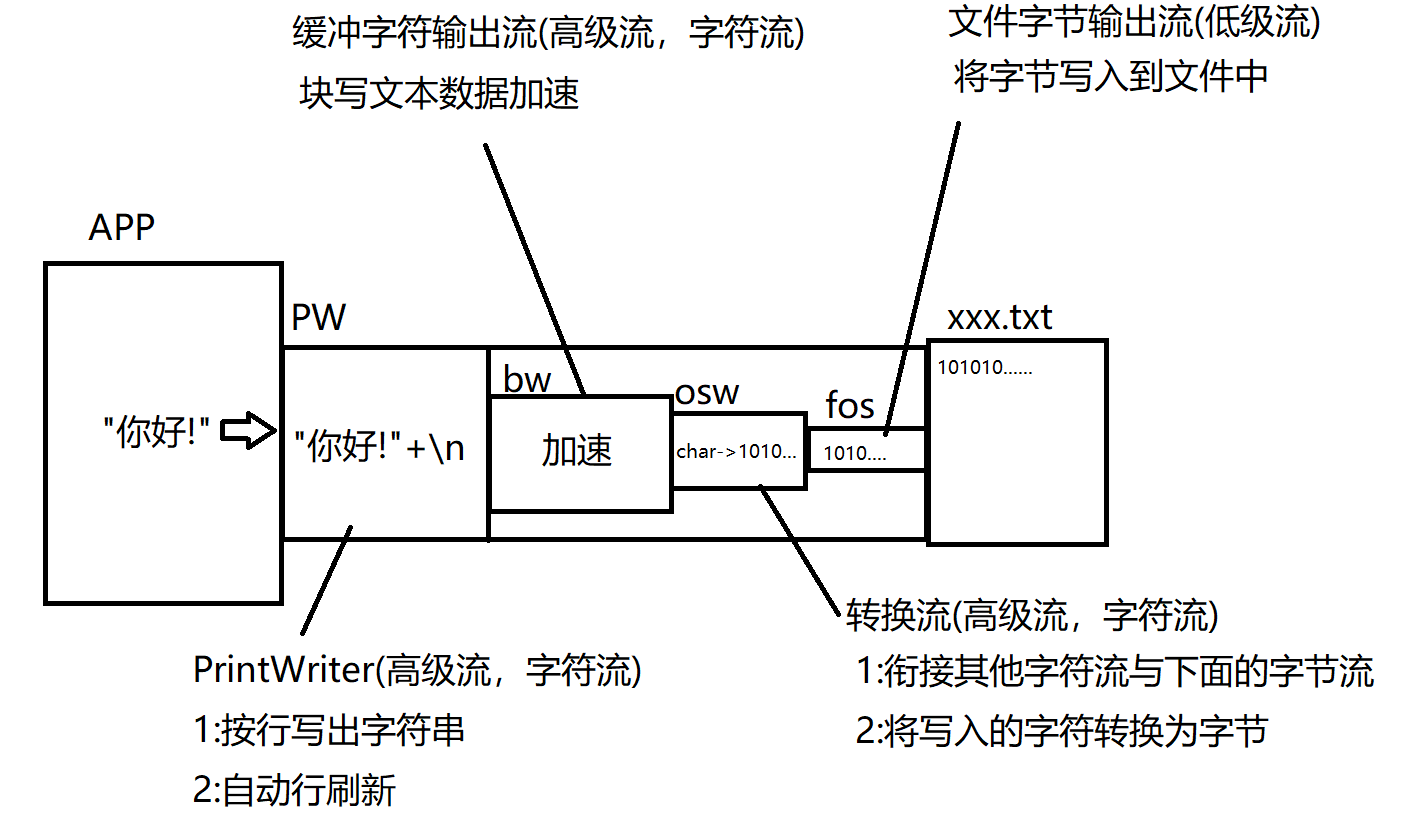

(1)学习方式:学习抽象父级的公共方法 学习子类流对象的创建方式
(2)流的连接:
串联一组高级流并最终连接到低级流上,使得读写数据以流水线式的加工处理完成,这个过程称为流的连接
(3)流的分类
根据方向:输入流 输出流
根据操作单位:字节流 字符流
输入:用来读取数据的,是从外界到程序的方向,用于获取数据.输出:用来写出数据的,是从程序到外界的方向,用于发送数据.
01.字节输入流(InputStream)和字节输出流(OutputStream)
(1)字节输入流InputStream:
—InputStream--抽象父类--不能实例化
—FileInputStream--文件字节输入流-FIS
—BufferedInputStream--高效字节输入流-BIS
FIS in = new FIS(new File(路径));
FIS in = new FIS(路径);
BIS in = new BIS( new FIS(new File(路径)));
BIS in = new BIS(new FIS(路径));Java定义了两个超类(抽象类):
/1.java.io.InputStream:所有字节输入流的超类,其中定义了读取数据的方法.- 因此将来不管读取的是什么设备(连接该设备的流)都有这些读取的方法,因此我们可以用相同的方法读取不同设备中的数据
/2.java.io.OutputStream:所有字节输出流的超类,其中定义了写出数据的方法.
(2)字节输出流OutputStream:
—OutputStream--抽象父类,不能实例化
—FileOutputStream--文件字节输出流--FOS
—BufferedOutputStream--高效字节输出流-BOS
FOS out = new FOS(new File(路径));
FOS out = new FOS(路径);
BOS out = new BOS(new FOS(new File(路径)));
BOS out = new BOS(new FOS(路径));
02.字符输入流Reader和字符输出流Writer
(1)字符输入流Reader:
—Reader--抽象父类--不能实例化
—FileReader--文件字符输入流-FR
—BufferedReader--高效字符输入流-BR
FR in = new FR(new File(路径));
FR in = new FR(路径);
BR in = new BR(new FR(new File(路径)))
BR in = new BR(new FR(路径));
(2)字符输出流Writer:
—Writer--抽象父类,不能实例化
—FileWriter--文件字符输出流--FW
—BufferedWriter--高效字符输出流--BW
FW out = new FW(File/File,append/String pathname/String pathname,append);
BW out = new BW(Writer--所以传的是子类FW(上面那4种));
注意:这里的append参数表示流向文件输出数据的时候是追加还是覆盖,如果不写,默认false是覆盖,如果改为true,表示追加
03.字节流和字符流的区别?
1)字节流-----------一个字节一个字节的去读取
1.字节流在操作的时候不会用到缓冲区(也就是内存)
2.字节流可用于任何类型的对象,包括二进制对象
3.字节流处理单元为1个字节,操作字节和字节数组。
InputStream是所有字节输入流的祖先,而OutputStream是所有字节输出流的祖先。
————————————————
2)字符流:
1.字符流在操作的时候会用到缓冲区
2.字符流只能处理字符或者字符串
3.字符流处理的单元为2个字节的Unicode字符,操作字符、字符数组或字符串。
注:Reader是所有读取字符串输入流的祖先,而writer是所有输出字符串的祖先。
在硬盘上的所有文件都是以字节形式存在的(图片,声音,视频),而字符值在内存中才会形成。
所以字符流是由Java虚拟机将字节转化为2个字节的Unicode字符为单位的字符而成的
!!!补充!!!:
- java将流按照读写单位划分为字节流与字符流.
- java.io.InputStream和OutputStream是所有字节流的超类
- 而java.io.Reader和Writer则是所有字符流的超类,它们和字节流的超类是平级关系.
- Reader和Writer是两个抽象类,里面规定了所有字符流都必须具备的读写字符的相关方法.
- 字符流最小读写单位为字符(char),但是底层实际还是读写字节,只是字符与字节的转换工作由字符流完成.
————————————————
————————————————
①简单点:
字节->解码->字符。
②复杂点:
若干字节->选择某种解码方式->解码->索引字符集->映射到一个字符。
————————————————
补充:
实际文本,又提出了字符流的概念,它是按虚拟机的编码来处理,也就是要进行字符集的转化,
这两个之间通过InputStreamReader,OutputStreamWriter(转换流)来关联,实际上是通过 byte[]和 String来关联的。
2、文件流(fos/fis):—>低级流;用来连接程序与文件之间的"管道",负责读写文件数据的流
2、文件流(fos/fis):一对低级流;用来连接程序与文件之间的"管道",负责读写文件数据的流01.文件输出流:java.io.FileOutputStream—————>继承自OutputStream(1)文件输出流常用构造:————————>①FileOutputStream(File file) 和 ②FileOutputStream(String path)(2)向文件中写入字节:——————————>void write(int d):,【内容是给定的int值对应的2进制的"低八位"】例:若第一次【fos.write(1);】写入1个字节,文件中的内容是1个字节对应的低八位:00000001若继续【fos.write(2);】 写入2个字节,文件中的内容是2个字节对应的低八位:00000010----会将之前的覆盖(3)写操作最终完毕后要关闭流: ———>fos.close()02.文件输入流:java.io.FileInputStream——————>继承自InputStream(1)文件输入流常用构造:①FileInputStream(String path)(2)读取字节:int read() 【读取字节,返回的int值对应的2进制的低八位为读取到的字节数据】。(3)流使用完后要调close关闭:———>fis.close()03.文件输入流、输出流综合练习题:
注:读写不同的设备java为我们准备了专门连接该设备的输入与输出流。他们都继承了InputStream和OutputStream,因此对我们来说读写操作是一样的,我们只需要在对不同设备进行读写时创建对应的流即可。
01.文件输出流:java.io.FileOutputStream——>继承自OutputStrea
01.文件输出流:java.io.FileOutputStream—————>继承自OutputStream(1)文件输出流常用构造:————————>①FileOutputStream(File file) 和 ②FileOutputStream(String path)(2)向文件中写入字节:——————————>void write(int d):,【内容是给定的int值对应的2进制的"低八位"】例:若第一次【fos.write(1);】写入1个字节,文件中的内容是1个字节对应的低八位:00000001若继续【fos.write(2);】 写入2个字节,文件中的内容是2个字节对应的低八位:00000010----会将之前的覆盖(3)写操作最终完毕后要关闭流: ———>fos.close()练习题:
package apiday.day04._io;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
/*** 2、文件流(fos/fis):————>一对低级流;用来连接程序与文件之间的"管道",负责读写文件数据的流* 01.文件输出流:java.io.FileOutputStream—————>继承自OutputStream* (1)文件输出流常用构造:————————>①FileOutputStream(File file) 和 ②FileOutputStream(String path)* (2)向文件中写入字节:——————————>void write(int d):,【内容是给定的int值对应的2进制的"低八位"】* 例:若第一次【fos.write(1);】写入1个字节,文件中的内容是1个字节对应的低八位:00000001* 若继续【fos.write(2);】 写入2个字节,文件中的内容是2个字节对应的低八位:00000010----会将之前的覆盖* (3)写操作最终完毕后要关闭流: ———>fos.close()*/
public class IoFos {public static void main(String[] args) throws IOException {/** 01.文件输出流:java.io.FileOutputStream *//* 2、01.(1)文件输出流常用两种构造方法:①FileOutputStream(File file) 和 ②FileOutputStream(String path) *///2、02.(1)①:FileOutputStream(File file):
// File file = new File("./test.dat");
// FileOutputStream fos1 = new FileOutputStream(file);//2、01.(1)②:向文件fos.dat中写入一个字节FileOutputStream fos = new FileOutputStream("./test/fos.dat");/*void write(int d):向文件中写入1个字节,【内容是给定的int值对应的2进制的"低八位"】fos.write(1);int型整数1的2进制: vvvvvvvv00000000 00000000 00000000 00000001fos.dat文件中的内容(低八位): 00000001fos.write(2);int型整数2的2进制: vvvvvvvv00000000 00000000 00000001 00000010fos.dat文件中的内容(低八位): 00000010*/fos.write(1);fos.write(2);System.out.println("写出完毕!");fos.close();//写操作最终完毕后要关闭流}
}
02.文件输入流:java.io.FileInputStream——>继承自InputStream
02.文件输入流:java.io.FileInputStream——————>继承自InputStream(1)文件输入流常用构造:①FileInputStream(String path)(2)读取字节:int read() 【读取字节,返回的int值对应的2进制的低八位为读取到的字节数据】。(3)流使用完后要调close关闭:———>fis.close()练习题:
package apiday.day04._io;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
/*** 02.文件输入流:java.io.FileInputStream——————>继承自InputStream* (1)文件输入流常用构造:①FileInputStream(String path)* (2)读取字节:int read() 【读取字节,返回的int值对应的2进制的低八位为读取到的字节数据】。* (3)流使用完后要调close关闭:———>fis.close()*/
public class IoFIS {public static void main(String[] args) throws IOException {//02.1(2)将fos.dat文件中的数据读取回来FileInputStream fis = new FileInputStream("./test/fos.dat");/*int read():读取一个字节,并以int型返回。【返回的int值对应的2进制的低八位为读取到的字节数据】。若返回值为int型的-1,则表示读取到了流的末尾。fos.dat:00000001 00000010int d = fis.read();变量d 2进制的表示:00000000 00000000 00000000 00000001|---------补24个0---------| 读取的字节d = fis.read();d:00000000 00000000 00000000 00000010读取的字节d = fis.read();d:11111111 11111111 11111111 11111111当读取当末尾是输出值为-1*/int d = fis.read();System.out.println(d);//1d = fis.read();System.out.println(d);//2d = fis.read();System.out.println(d);//-1,读取到末尾,值为-1fis.close();//流在使用完毕后要调用close关闭}
}
03.文件输入流、输出流综合练习题:
package apiday.day04._io;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class Fis_Fos {public static void main(String[] args) throws IOException {/** 03.文件输入流、输出流综合练习题:*///例:将a~z写入fod.dat文件中并读取成功?FileOutputStream fos1 = new FileOutputStream("./test/fos1.dat");for(int i=0;i<26;i++) {fos1.write(97+i);}fos1.close();FileInputStream fis1 = new FileInputStream("./test/fos1.dat");System.out.println(fis1.read());fis1.close();System.out.println("读取完毕");}
}
04.文件的复制两种方式:随机写/块读写
(1)文件的复制01(速度慢/毫秒级):——>随机读写(单字节读写)
01.文件的复制01(速度慢/毫秒级):——>随机读写(单字节读写)练习题:
package Vdayio;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
//文件的复制
public class CopyDemo {public static void main(String[] args) throws IOException {long t1 = System.currentTimeMillis();//1.先获取要复制的文件的路径FileInputStream fis = new FileInputStream("./test/a/太阳.jpg");//2.将获取的文件复制到一个新的路径FileOutputStream fos = new FileOutputStream("./test/太阳_cp.jpg");/*假设太阳.jpg内容:01111110 11110000 00001111 10101010 00110011^^^^^^^^int d = fis.read();d={00000000,00000000,00000000,01111110}fos.write(d);假设太阳_cp.jpg内容d={01111110}*///3.声明要复制的文件的内容:int d;//4.当文件读取到-1的时候就复制完成:while((d= fis.read())!=-1){//注意!——————>一定要在括号里初始化d=fis.read() 不然会成死循环!fos.write(d);}long t2 = System.currentTimeMillis();System.out.println("复制完毕,耗时:"+(t2-t1)+"毫秒");//复制完毕,耗时:2177毫秒//5.流在使用后要关闭:fis.close();fos.close();}
}
(2)文件的复制02(速度快):———>块读写(一组一组字节的读写)
02.文件的复制02(速度快):————————>块读写(一组一组字节的读写)块读写:通过提高每次读写的数据量,减少实际读写的次数,可以提高读写效率。注1:一次读多少个字节数取决于数组的长度注2:大多数的硬件块读写逗比随机读写性能好,尤其机械硬盘上体现最为明细。(1)块读:int read(byte[] data)一次性从文件中读取给定的字节数组总长度的字节量,并存入到该数组中。返回值为实际读取到的字节量。若返回值为-1则表示读取到了文件末尾。(2)块写:①void write(byte[] data):—————————————————————>不建议!!复制的文件会产生多余的垃圾数据一次性将给定的字节数组所有字节写入到文件中②void write(byte[] data,int offset,int len)————> 建议!!复制的文件不会产生垃圾数据一次性将给定的字节数组从下标offset处开始的连续len个字节写入文件(3)补充:8位2进制: 00000000 1byte 1字节1024byte 1kb1024kb 1mb1024mb 1gb1024gb 1tb(4)内存中详细步骤:每次读取的字节数(注:1个字节=00000000)为设置数组的长度,直到读到文件末尾时若不够数组的长度(即文件最后面的数据不够[调用.read()方法]一次性读取的字节数);把该不够长度的字节数在新的data中从前往后覆盖之前读取到的的字节数,最后读取到-1就结束了。(5)块读写步骤:(1)定义数组;(2)将数组传入:①【.write(byte[] data)】-----不建议——————>会产生多余的垃圾数据:②【byte[] data,int offset,int len】—————>不会产生垃圾数据练习题:
package Vdayio;
import java.io.*;
public class CopyDemo02 {public static void main(String[] args) throws IOException {/*假设:太阳.jpg内容:00001111 11110000 10101010 01010101 11001100 00110011byte[] data = new byte[4];//创建一个长度为4的字节数组data:[00000000,00000000,00000000,00000000]int len1;//记录每次读取到的字节数第一次调用:len1 = fis.read(data);从太阳.jpg文件中一次读取4个字节:00001111 11110000 10101010 01010101 11001100 00110011^^^^^^^^ ^^^^^^^^ ^^^^^^^^ ^^^^^^^^data:{00001111,11110000,10101010,01010101}数组存入的是本次读取的数据len1:4 表示本次实际读取到了4个字节第二次调用:len1 = fis.read(data);从太阳.jpg文件中一次读取4个字节太阳.jpg内容:00001111 11110000 10101010 01010101 11001100 00110011 文件末尾了^^^^^^^^ ^^^^^^^^ ^^^^^^^^ ^^^^^^^^实际只读取到了2个字节data:{11001100,00110011,10101010,01010101}数组存入的是本次读取的数据|---本次新读取的--| |---上次的旧数据---|len:2 表示本次实际读取到了2个字节第三次调用:len = fis.read(data);从太阳.jpg文件中一次读取4个字节太阳.jpg内容:00001111 11110000 10101010 01010101 11001100 00110011 文件末尾了^^^^^^^^ ^^^^^^^^ ^^^^^^^^ ^^^^^^^^没有数据可以读取了data:{11001100,00110011,10101010,01010101}数组没有变化|----------上次的旧数据--------------|len:-1 表示流读取到了末尾*///1.先获取要复制的文件的路径:FileInputStream fis1 = new FileInputStream("./test/a/太阳.jpg");//2.将获取的文件复制到一个新的路径:FileOutputStream fos1 = new FileOutputStream("./test/a/太阳02.jpg");//3.定义一个可以存储10240字节即10kb的数组,表示一次可以读取10kb的数据(块读):byte[] data = new byte[1024*10];long start = System.currentTimeMillis();//4.每次实际读取到的字节数:int len1;//5.当文件读取到-1的时候就复制完成:while((len1=fis1.read(data))!=-1){//fos1.write(data);//①复制的文件会产生多余的垃圾数据----------------------------不建议!!fos1.write(data,0,len1);//②不会产生垃圾数据,将文件上的字节数写入到内存data中---建议!!}long end = System.currentTimeMillis();System.out.println("复制完毕,耗时:"+(start-end)+"毫秒");//复制完毕,耗时:0毫秒//6.流在使用后要关闭:fis1.close();fos1.close();}
}
05.向文件中写入文本数据(:字符串)
1、向文件中写入文本数据(字符串)(1)String提供了将字符串转换为一组字节的方法:byte[] getBytes(String charsetName):参数指定的就是字符集。名字不区分大小写,但是拼写错误会引发异常:UnsupportedEncodingException不支持 字符集 异常补充:支持中文的常见字符集有:(1)GBK:国标编码。英文每个字符占1个字节,中文每个字符占2个字节(2)UTF-8:内部是unicode编码,在这个基础上不同了少部分2进制信息作为长度描述英文每个字符占1字节 ; 中文每个字符占3字节练习题:
package apiday.day04._io;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
/*** 1、向文件中写入文本数据(字符串)* 补充:* 支持中文的常见字符集有:* (1)GBK:国标编码。英文每个字符占1个字节,中文每个字符占2个字节* (2)UTF-8:内部是unicode编码,在这个基础上不同了少部分2进制信息作为长度描述* 英文每个字符占1字节 ; 中文每个字符占3字节* String提供了将字符串转换为一组字节的方法:* byte[] getBytes(String charsetName)* 参数指定的就是字符集。名字不区分大小写,但是拼写错误会引发异常:* UnsupportedEncodingException* 不支持 字符集 异常*/
public class WriteString {public static void main(String[] args) throws IOException {//1.向文件中写入数据FileOutputStream fos = new FileOutputStream("./test/fos.txt");//2.用UTF-8格式将字符串转换为2进制(即字节)的形式存在str数组里String str = "我是一个中国人,你是哪里的";byte[] data = str.getBytes(StandardCharsets.UTF_8);//3.流使用完毕后要关闭fos.write(data);System.out.println("写出完毕!");fos.close();}
}
06.文件流两种创建模式:覆盖和追加
2、文件流两种创建模式:覆盖和追加01.覆盖构造器:这种情况下文件输出流时如果连接的文件已经存在则会把文件之前的数据全部清除1)FileOutputStream(String path)2)FileOutputStream(File file)02.追加构造器:当第二个参数传入true时,文件流为追加模式,即:指定的文件若存在,则原有数据保留,新写入的数据会被顺序的追加到文件中1)FileOutputStream(String path,boolean append)2)FileOutputStream(File file,boolean append)注:——————>若想写一句追加一句,需要多次调用【.write()】练习题:
package apiday.day04._io;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
/*** 2、文件流两种创建模式:覆盖和追加* 01.覆盖构造器:这种情况下文件输出流时如果连接的文件已经存在则会把文件之前的数据全部清除* 1)FileOutputStream(String path)* 2)FileOutputStream(File file)* 02.追加构造器:当第二个参数传入true时,文件流为追加模式,即:指定的文件若存在,则原有数据保留,新写入的数据会被顺序的追加到文件中* 1)FileOutputStream(String path,boolean append)* 2)FileOutputStream(File file,boolean append)* 注:——————>若想写一句追加一句,需要多次调用【.write()】*/
public class WriteString {public static void main(String[] args) throws IOException {/** 2、文件流两种创建模式:覆盖和追加 *//*文件流两种创建模式:覆盖和追加01.覆盖构造器:这种情况下文件输出流时如果连接的文件已经存在则会把文件之前的数据全部清除1)FileOutputStream(String path)2)FileOutputStream(File file)02.追加构造器:当第二个参数传入true时,文件流为追加模式,即:指定的文件若存在,则原有数据保留,新写入的数据会被顺序的追加到文件中1)FileOutputStream(String path,boolean append)2)FileOutputStream(File file,boolean append)*///例2:以下三句字符串://加上true----会在之前字符串的基础追加下面输入的字符串:——————>若想写一句追加一句,需要多次调用【.write()】//不加true----下面的字符串则会把之前的覆盖:FileOutputStream fos1 = new FileOutputStream("./test/fos.txt",true);String str1 = "---------你好啊,我又来了";byte[] data1 = str1.getBytes(StandardCharsets.UTF_8);fos1.write(data1);str1 = "sfdewfwe";byte[] data5 = str1.getBytes(StandardCharsets.UTF_8);fos1.write(data5);str1 = "哈哈哈哈嗯嗯嗯";byte[] data6 = str1.getBytes(StandardCharsets.UTF_8);fos1.write(data6);System.out.println("写出完毕");}
}
07.将数据写入文件:实现简易记事本工具
练习题:
package apiday.day04._io;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;
/*** 3、实现简易记事本工具*/
public class WriteString {public static void main(String[] args) throws IOException {/*** 3、将数据写入文件—————————————>实现简易记事本工具* 要求:程序启动后,要求将控制台输入的每一行字符串都写入到文件note.txt中* 当在控制台单独输入exit(出口)时,程序退出*///0.创建扫描仪 并 创建可以写入的文件Scanner scan = new Scanner(System.in);System.out.println("请开始输入内容,单独输入exit退出");FileOutputStream fos2 = new FileOutputStream("./test/Test.txt");while(true){//1.先获取控制台输入的一行字符串String line = scan.nextLine();//2.判断用户输入的是否为exitif("exit".equals(line)){break;}//3.写入文件:①先将字符串转换为一组字节byte[] data2 = line.getBytes(StandardCharsets.UTF_8);//3.②将这组字节写入文件fos2.write(data2);}fos2.close();/*第(2)种方式:while(true){String line = scanner.nextLine();//扫描每一行给lineif("exit".equals(line)){//如果输入出口则break退出break;}fos.write(line.getBytes(StandardCharsets.UTF_8));//用UTF-8把字符串转化为字节存在byte[]数组里}*//*//第(2)种进阶版:String line;//定义一个字符串linewhile(!"exit".equals(line = scanner.nextLine())){fos.write(line.getBytes(StandardCharsets.UTF_8));//用UTF-8把字符串转化为字节存在byte[]数组里}fos.close();//流在使用完毕后要调用close关闭*//*第(3)种方式:如果忽略大小写来比较字符串内容方法---------equalsIgnoreCasewhile(true){String line = scanner.nextLine();//扫描每一行给line//String提供了一个忽略大小写比较字符串内容的方法:equalsIgnoreCaseif("exit".equalsIgnoreCase(line)){//如果输入出口则break退出break;}fos.write(line.getBytes(StandardCharsets.UTF_8));//反之用UTF-8把字符串转化为字节存在byte[]数组里}*/}
}
08.从文件中读取文本数据:实际上是通过byte[]和String来关联。
4、从文件中读取文本数据————————>实际上是通过byte[]和String来关联。(1)String提供了将字节数组转换为字符串的构造方法:①String(byte[]data,String charsetName):将给定的字节数组中所有字节按照指定的字符集转换为字符串②String(byte[]data,int offset,int len,String charsetName):将给定的字节数组从下标offset处开始的连续len个字节按照指定的字符集转换为字符串练习题:
package apiday.day04._io;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;
/*** 4、从文件中读取文本数据————————>实际上是通过byte[]和String来关联。* (1)String提供了将字节数组转换为字符串的构造方法:* ①String(byte[]data,String charsetName):* 将给定的字节数组中所有字节按照指定的字符集转换为字符串* ②String(byte[]data,int offset,int len,String charsetName):* 将给定的字节数组从下标offset处开始的连续len个字节按照指定的字符集转换为字符串*/
public class WriteString {public static void main(String[] args) throws IOException {/** 4、从文件中读取文本数据——————>实际上是通过byte[]和String来关联。 */FileInputStream fis = new FileInputStream("./test/fos.txt");byte[] data7 = new byte[1024*10];int len = fis.read(data7);System.out.println("实际读取到的字节:"+len);//实际读取到的字节:101/*String提供了将字节数组转换为字符串的构造方法:String(byte[]data,String charsetName)将给定的字节数组中所有字节按照指定的字符集转换为字符串String(byte[]data,int offset,int len,String charsetName)将给定的字节数组从下标offset处开始的连续len个字节按照指定的字符集转换为字符串*/String line = new String(data7,0,len, StandardCharsets.UTF_8);System.out.println(line.length());//45System.out.println(line);//我是一个中国人,你是哪里的---------你好啊,我又来了sfdewfwe哈哈哈哈嗯嗯嗯fis.close();}
}
3、缓冲流(BufferedOutputStream):
- 缓冲流:——————>高级流,作用是【加快读写效率】
①缓冲输入流:java.io.BufferedInputStream
②缓冲输出流:java.io.BufferedOutputStream。 - 注1:缓冲流内部有一个字节数组,默认长度是8K。
- 注2:缓冲流读写数据时一定是【将数据的读写方式转换为块读写】来保证读写效率.
(1)高级流 连接示意图:

(2)缓冲流:使用缓冲流完成文件复制操作:

1、java将流分为节点流和处理流:01.节点流:也称为低级流,是真实连接程序与另一端的“管道”,负责实际读写数据的流。读写一定是建立在节点流的基础上进行的。02.处理流:也称为高级流,过滤流。不能独立存在,必须连接在其他流上,目的是当数据流过它时对其数据进行某种加工处理,简化我们对数据的同等操作。注1:实际开发中经常会串联一组高级流最终连接到低级流上,在读写操作以流水线式的加工完成IO流操作。这个过程也称为“流的连接”2、缓冲流:——————>高级流,作用是【加快读写效率】①缓冲输入流:java.io.BufferedInputStream②缓冲输出流:java.io.BufferedOutputStream。注1:缓冲流内部有一个字节数组,默认长度是8K。注2:缓冲流读写数据时一定是【将数据的读写方式转换为块读写】来保证读写效率.练习题:
package apiday.day04.buffered_stream;
import java.io.*;
import java.nio.charset.StandardCharsets;
/*** 1、java将流分为节点流和处理流:* 01.节点流:也称为低级流,是真实连接程序与另一端的“管道”,负责实际读写数据的流。* 读写一定是建立在节点流的基础上进行的。* 02.处理流:也称为高级流,过滤流。不能独立存在,必须连接在其他流上,目的是当数据流过它时* 对其数据进行某种加工处理,简化我们对数据的同等操作。* 注1:实际开发中经常会串联一组高级流最终连接到低级流上,在读写操作以流水线式的加工完成IO流操作。这个过程也称为“流的连接”** 2、缓冲流:——————>高级流,作用是【加快读写效率】* ①缓冲输入流:java.io.BufferedInputStream* ②缓冲输出流:java.io.BufferedOutputStream。* 注1:缓冲流内部有一个字节数组,默认长度是8K。* 注2:缓冲流读写数据时一定是【将数据的读写方式转换为块读写】来保证读写效率.*/
public class four_Buffered_Stream_Copy {public static void main(String[] args) throws Exception {/*低级流:例:块读写方式————>文件的复制://1.先获取要复制的文件的路径:FileInputStream fis1 = new FileInputStream("./test/a/太阳.jpg");//2.将获取的文件复制到一个新的路径:FileOutputStream fos1 = new FileOutputStream("./test/a/太阳02.jpg");//3.定义一个可以存储10240字节即10kb的数组,表示一次可以读取10kb的数据(块读):byte[] data = new byte[1024*10];long start = System.currentTimeMillis();//4.每次实际读取到的字节数:int len1;//5.当文件读取到-1的时候就复制完成:while((len1=fis1.read(data))!=-1){//fos1.write(data);//①复制的文件会产生多余的垃圾数据----------------------------不建议!!fos1.write(data,0,len1);//②不会产生垃圾数据,将文件上的字节数写入到内存data中---建议!!}long end = System.currentTimeMillis();System.out.println("复制完毕,耗时:"+(start-end)+"毫秒");//复制完毕,耗时:0毫秒//6.流在使用后要关闭:fis1.close();fos1.close();*//** 2、缓冲流:——————>高级流,作用是【加快读写效率】 *//* 用缓冲流复制文件:*/long t1 = System.currentTimeMillis();FileInputStream fis = new FileInputStream("./test/a/太阳.jpg");BufferedInputStream bis = new BufferedInputStream(fis);FileOutputStream fos = new FileOutputStream("./test/a/太阳_02.jpg");BufferedOutputStream bos = new BufferedOutputStream(fos);int d;while((d=bis.read())!=-1){bos.write(d);}long t2 = System.currentTimeMillis();System.out.println("复制完毕!耗时:"+(t2-t1)+"毫秒");//复制完毕!耗时:21毫秒bis.close();//关闭流时只需要关闭高级流即可,他会自动关闭他连接的流bos.close();}
}
01.缓冲流写出数据的缓冲区问题-----flush()
缓冲流的flush方法用于强制将缓冲区中已经缓存的数据一次性写出。注:该方法实际上是在字节输出流的超类OutputStream上定义的,并非只有缓冲输出流有这个法。但是实际上只有缓冲输出流的该方法有实际意义,其他的流实现该方法的目的仅仅是为了在流连接过程中传递flush动作给缓冲输出流。练习题:
package Vdayio;
import java.io.*;
import java.nio.charset.StandardCharsets;
/*** 缓冲输出流写出数据的时效性问题(缓冲区问题)*/
public class VIdayBOS_flushDemo {public static void main(String[] args) throws IOException {/** 2、01.缓冲流写出数据的缓冲区问题-----flush() */FileOutputStream fos1 = new FileOutputStream("./test.bos.txt");BufferedOutputStream bos1 = new BufferedOutputStream(fos1);String line = "奥利给!";byte[] data = line.getBytes(StandardCharsets.UTF_8);//缓冲流内部默认有一个8k字节数组,写出的数据会先被存入数组中,直到数组装满才会写出bos.write(data);System.out.println("写出完毕");/*缓冲流的flush方法用于强制将缓冲区中已经缓存的数据一次性写出。注:该方法实际上是在字节输出流的超类OutputStream上定义的,并非只有缓冲输出流有这个方法。但是实际上只有缓冲输出流的该方法有实际意义,其他的流实现该方法的目的仅仅是为了在流连接过程中传递flush动作给缓冲输出流。*/bos.flush();//冲 flush方法的作用:让缓冲输出流将其缓冲区中已经缓存的数据立即写出bos.close();}
}
4、对象流:java.io.ObjectOutputStream和ObjectInputStream
- 对象流(高级流)--------在流连接中的作用:进行对象的序列化与反序列化。
对象流:—————————>java.io.ObjectOutputStream和ObjectInputStream(1)①对象输入流——————>java.io.ObjectInputStream(是InputStream的子类)②对象输出流——————>java.io.ObjectOutputStream(是OutputStream的子类)(2)概述:是一对高级流,在流连接中完成对象与字节的转换(即:对象序列化和反序列化操作)(3)这两个类存在的意义: ①有了它们我们可以轻松读写任何java对象.②用于序列化对象的操作。用于存储和读取对象的输入输出流类。(4)注意:当使用对象流写入或者读取对象的时候,必须保证该对象是序列化的;这样是为了保证对象能够正确的写入文件,并能够把对象正确的读回程序。例:/*将一个Person对象写入文件①先将Person对象转换为一组字节------序列化②将字节写入文件------------------对象反序列化流连接: 序列化 持久化↓ ↓对象----转换为---->对象流(字节)----转换为---->文件流---->*/
01.对象序列化(ObjectOutputStream)——>将给定的对象转换为一组字节(二进制数据流)并写出的过程
1、什么是序列化与反序列化?
①序列化:把内存中的对象通过序列化流输出到磁盘中(比如文件里),使用的流是ObjectOutputStream【把数据写出到文件】
②反序列化:通过反序列化流将磁盘中的数据恢复成对象,使用的流是ObjectInputStream【把之前写到文件里的数据读到程序中】注意1:一个类的对象如果想被序列化,那么这个类必须实现可序列化接口实现这个接口的目的是相当于给这个类做了一个标记,标记可以序列化注意2:序列化时会自动生成一个UID,表示当前序列化输出的对象的版本信息反序列化时会拿着当前的UID与之前序列化输出的UID做比较,一致,反序列化成功,不一致,报错注意3: 所以,标准操作是一次序列化对应一次反序列化如果目标对象所在的类没有做任何修改,一次序列化也可以对应多次反序列化(根本原因是UID没变)2、为什么要做序列化?
①、在分布式系统中,此时需要把对象在网络上传输,就得把对象数据转换为二进制形式,需要共享的数据的 JavaBean 对象,都得做序列化。
②、服务器钝化:如果服务器发现某些对象好久没活动了,那么服务器就会把这些内存中的对象持久化在本地磁盘文件中(Java对象转换为二进制文件);如果服务器发现某些对象需要活动时,先去内存中寻找,找不到再去磁盘文件中反序列化我们的对象数据,恢复成 Java 对象。这样能节省服务器内存。3、Java 怎么进行序列化?
①、需要做序列化的对象的类,必须实现序列化接口:Java.lang.Serializable 接口(这是一个标志接口,没有任何抽象方法),Java 中大多数类都实现了该接口,比如:String,Integer
②、底层会判断,如果当前对象是 Serializable 的实例,才允许做序列化,Java对象 instanceof Serializable 来判断。
③、在 Java 中使用对象流来完成序列化和反序列化:()
ObjectOutputStream:通过 writeObject()方法做序列化操作
ObjectInputStream:通过 readObject() 方法做反序列化操作

对象序列化的流连接操作原理图:

01.对象序列化(ObjectOutputStream)———————>将给定的对象转换为一组字节(二进制数据流)并写出的过程(1)对象输出流提供的序列化方法:void writeObject(Object obj)————>将一个对象obj写入到一个文件(2)要求:序列化时要求写出的对象所属的类必须实现可序列化接口【Serializable】,否则会抛出不可序列化异常:java.io.NotSerializableException注:Serializable:标识接口[这个接口里面什么内容都没有(来进行对象序列化和反序列化的,里面只有一个版本号,用来进行标志识别版本号的)];练习题:
(0)使用当前类测试对象流的序列化和反序列化操作:
package apiday.day05.object_serialization;
import java.io.Serializable;
import java.util.Arrays;
//01.①:序列化时要求写出的对象所属的类必须实现可序列化接口(Serializable),
// 否则会抛出异常:java.io.NotSerializableException
public class Person implements Serializable {/*Serializable手册详细介绍:原文:如果可序列化类没有显式声明 serialVersionUID,则序列化运行时将根据类的各个方面为该类计算默认的 serialVersionUID 值,如 Java(TM) 对象序列化规范中所述。【但是,强烈建议所有可序列化的类都显式声明 serialVersionUID 值,因为默认的 serialVersionUID 计算对类细节高度敏感,这些细节可能因编译器实现而异,因此可能在反序列化期间导致意外的 InvalidClassExceptions。】因此,【为了保证在不同的 java 编译器实现中具有一致的 serialVersionUID 值,可序列化的类必须声明一个显式的 serialVersionUID 值。】还强烈建议显式 serialVersionUID 声明尽可能使用 private修饰符,因为此类声明仅适用于立即声明的类——serialVersionUID 字段不能用作继承成员。数组类不能显式声明 serialVersionUID,因此它们始终具有默认计算值,但数组类无需匹配 serialVersionUID 值。自己总结:实现序列化接口最好主动定义序列化版本号这个常量,这样一来对象序列化时就不会根据类的结构生成一个版本号,而是使用该固定值。那么反序列化时,只要还原的对象和当前类的版本号一致就可以进行还原。如下:声明一个序列版本号:*/public static final long serialVersionUID = 42L;//只要定义一个版本号,反序列化(可以进行还原)时可以避免异常private String name;private int age;private String gender;//性别/*当一个属性被关键字transient修饰后,那么当进行对象序列化时,该属性的值会被忽略。忽略不必要的属性可以达到对象“瘦身”的目的,减少资源开销。未加transient运行后该Person.obj文件较大:289字节加了transient运行后该Person.obj文件较小:144字节当一个属性被关键字transient修饰后,那么当进行对象序列化时,该属性的值会被忽略。*/private transient String[] otherInfo;//其他信息/*若再重新声明一个工资变量:此时直接执行【OOS_OIS.java】会报无效的类异常:InvalidClassExceptions因为对象序列化时会根据类的结构生成另一个版本号;当反序列化时,需要还原的对象和当前类的版本号不一致了就无法进行还原。*/private int salary;//工资public Person(){ }public Person(String name, int age, String gender, String[] otherInfo) {this.name = name;this.age = age;this.gender = gender;this.otherInfo = otherInfo;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public String getGender() {return gender;}public void setGender(String gender) {this.gender = gender;}public String[] getOtherInfo() {return otherInfo;}public void setOtherInfo(String[] otherInfo) {this.otherInfo = otherInfo;}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +", gender='" + gender + '\'' +", otherInfo=" + Arrays.toString(otherInfo) +'}';}
}(2)对象序列化:
package apiday.day05.object_serialization;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
/*** 01.对象序列化(ObjectOutputStream)———————>将给定的对象转换为一组字节(二进制数据流)并写出的过程* (1)对象输出流提供的序列化方法:void writeObject(Object obj)————>将一个对象obj写入到一个文件* (2)要求:序列化时要求写出的对象所属的类必须实现可序列化接口【Serializable】,* 否则会抛出不可序列化异常:java.io.NotSerializableException* 注:Serializable:标识接口[这个接口里面什么内容都没有(来进行对象序列化和反序列化的,* 里面只有一个版本号,用来进行标志识别版本号的)];*/
public class OOS {public static void main(String[] args) throws IOException {/*将一个Person对象写入文件①先将Person对象转换为一组字节------序列化②将字节写入文件------------------对象反序列化流连接: 序列化 持久化↓ ↓对象----转换为---->对象流(字节)----转换为---->文件流---->*//** 01.对象序列化(ObjectOutputStream):将给定的对象转换为一组字节(二进制数据流)并写出的过程 *///①先将Person对象转换为一组字节------序列化String name = "苍老师";int age = 18;String gender = "女";String[] otherInfo = {"是一名演员", "来自霓虹", "爱好书法", "广大男性同胞的启蒙老师"};Person p1 = new Person(name, age, gender, otherInfo);System.out.println(p1);//输出p.toString()返回值 在Person.java中调用该构造方法//将该Person对象写入文件person.obj中:①因此程序可以实现把组件写入输出流,FileOutputStream fos = new FileOutputStream("./test/person.obj");ObjectOutputStream oos = new ObjectOutputStream(fos);/*对象输出流提供的序列化方法:void writeObject(Object obj)将给定的对象转换为一组字节并写出。但要注意:序列化时要求写出的对象所属的类必须实现可序列化接口(Serializable),否则会抛出异常:java.io.NotSerializableException*/oos.writeObject(p1);System.out.println("写出完毕");oos.close();}
}
02.对象反序列化(ObjectInputStream)——>将一组字节还原为java对象(前提是这组字节是一个对象序列化得到的字节)
02.对象反序列化(ObjectInputStream)——————>将一组字节还原为java对象(前提是这组字节是一个对象序列化得到的字节)(1)对象输入流提供的反序列化方法:readObject()——————————————————>读取一个对象。(2)①:实现序列化接口最好主动定义序列化版本号这个常量,这样一来对象序列化时就不会根据类的结构生成一个版本号,而是使用该固定值。那么反序列化时,只要还原的对象和当前类的版本号一致就可以进行还原。②:为什么进行序列化时最好主动定义序列化版本号这个常量?答:因为对象序列化时会根据类的结构生成另一个版本号;当反序列化时,需要还原的对象和当前类的版本号不一致了就无法进行还原。(3)transient————>让对象“瘦身”的目的,减少资源开销概述:当一个属性被关键字【transient】修饰后,那么当进行对象序列化时,该属性的值会被忽略。忽略不必要的属性可以达到对象“瘦身”的目的,减少资源开销。例子:【private transient String[]otherInfo;//其他信息】未加transient运行后该Person.obj文件较大:289字节加了transient运行后该Person.obj文件较小:144字节练习题:
(1)使用当前类测试对象流的序列化和反序列化操作:
package apiday.day05.object_serialization;
import java.io.Serializable;
import java.util.Arrays;
//01.①:序列化时要求写出的对象所属的类必须实现可序列化接口(Serializable),
// 否则会抛出异常:java.io.NotSerializableException
public class Person implements Serializable {/*Serializable手册详细介绍:原文:如果可序列化类没有显式声明 serialVersionUID,则序列化运行时将根据类的各个方面为该类计算默认的 serialVersionUID 值,如 Java(TM) 对象序列化规范中所述。【但是,强烈建议所有可序列化的类都显式声明 serialVersionUID 值,因为默认的 serialVersionUID 计算对类细节高度敏感,这些细节可能因编译器实现而异,因此可能在反序列化期间导致意外的 InvalidClassExceptions。】因此,【为了保证在不同的 java 编译器实现中具有一致的 serialVersionUID 值,可序列化的类必须声明一个显式的 serialVersionUID 值。】还强烈建议显式 serialVersionUID 声明尽可能使用 private修饰符,因为此类声明仅适用于立即声明的类——serialVersionUID 字段不能用作继承成员。数组类不能显式声明 serialVersionUID,因此它们始终具有默认计算值,但数组类无需匹配 serialVersionUID 值。自己总结:实现序列化接口最好主动定义序列化版本号这个常量,这样一来对象序列化时就不会根据类的结构生成一个版本号,而是使用该固定值。那么反序列化时,只要还原的对象和当前类的版本号一致就可以进行还原。如下:声明一个序列版本号:*/public static final long serialVersionUID = 42L;//只要定义一个版本号,反序列化(可以进行还原)时可以避免异常private String name;private int age;private String gender;//性别/*当一个属性被关键字transient修饰后,那么当进行对象序列化时,该属性的值会被忽略。忽略不必要的属性可以达到对象“瘦身”的目的,减少资源开销。未加transient运行后该Person.obj文件较大:289字节加了transient运行后该Person.obj文件较小:144字节当一个属性被关键字transient修饰后,那么当进行对象序列化时,该属性的值会被忽略。*/private transient String[] otherInfo;//其他信息/*若再重新声明一个工资变量:此时直接执行【OOS_OIS.java】会报无效的类异常:InvalidClassExceptions因为对象序列化时会根据类的结构生成另一个版本号;当反序列化时,需要还原的对象和当前类的版本号不一致了就无法进行还原。*/private int salary;//工资public Person(){ }public Person(String name, int age, String gender, String[] otherInfo) {this.name = name;this.age = age;this.gender = gender;this.otherInfo = otherInfo;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public String getGender() {return gender;}public void setGender(String gender) {this.gender = gender;}public String[] getOtherInfo() {return otherInfo;}public void setOtherInfo(String[] otherInfo) {this.otherInfo = otherInfo;}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +", gender='" + gender + '\'' +", otherInfo=" + Arrays.toString(otherInfo) +'}';}
}(2)对象序列化:
package apiday.day05.object_serialization;
import java.io.*;
/*** 02.对象反序列化(ObjectInputStream)——————>将一组字节还原为java对象(前提是这组字节是一个对象序列化得到的字节)* (1)对象输入流提供的反序列化方法:readObject()——————————————————>读取一个对象。* (2)①:实现序列化接口最好主动定义序列化版本号这个常量,这样一来对象序列化时就不会根据类的结构生成一个版本号,* 而是使用该固定值。那么反序列化时,只要还原的对象和当前类的版本号一致就可以进行还原。* ②:为什么进行序列化时最好主动定义序列化版本号这个常量?* 答:因为对象序列化时会根据类的结构生成另一个版本号;当反序列化时,需要还原的对象和当前类的版本号不一致了就无法进行还原。* (3)transient————>让对象“瘦身”的目的,减少资源开销* 概述:当一个属性被关键字【transient】修饰后,那么当进行对象序列化时,该属性的值会被忽略。* 忽略不必要的属性可以达到对象“瘦身”的目的,减少资源开销。* 例子:【private transient String[]otherInfo;//其他信息】* 未加transient运行后该Person.obj文件较大:289字节* 加了transient运行后该Person.obj文件较小:144字节*/
public class OIS {public static void main(String[] args) throws IOException, ClassNotFoundException {/** 02.对象反序列化(ObjectInputStream):将一组字节还原为java对象(前提是这组字节是一个对象序列化得到的字节) */FileInputStream fis = new FileInputStream("./test/Person.obj");ObjectInputStream ois = new ObjectInputStream(fis);Person p2 = (Person) ois.readObject();System.out.println(p2);ois.close();}
}
5、转换流(OSW/ISR):是一对常用的字符流实现类:
java IO将流按照读写单位划分为字节流(stream结尾的)和字符流(read和writer结尾)
一、字节流:——————>stream结尾的
java.io.InputStream和OutStream是所有字节输入/输出流的超类,读写最小单位是字节二、字符流(character stream):——————>read和writer结尾
java.io.Reader和Writer则是所有字符输入流和输出流的超类,它们是平级关系,读写单位最小为字符。
:
- java将流按照读写单位划分为字节流与字符流.
- java.io.InputStream和OutputStream是所有字节流的超类
- 而java.io.Reader和Writer则是所有字符流的超类,它们和字节流的超类是平级关系.
- Reader和Writer是两个抽象类,里面规定了所有字符流都必须具备的读写字符的相关方法.
- 字符流最小读写单位为字符(char),但是底层实际还是读写字节,只是字符与字节的转换工作由字符流完成.1、转换流(OSW/ISR):——————>是一对常用的字符流实现类:
01.java.io.OutputStreamWriter(OSW):高级转换流;创建转换流时,可以通过第二个参数来指定字符集【new OutputStreamWriter(fos,StandardCharsets.UTF_8);】(1).write()方法:——————>可以直接写出字符流,无需再手动转换为字节
02.java.io.InputStreamReader(ISR):高级转换流;创建转换流时,可以通过第二个参数来指定字符集【new InputStreamReader(fis,StandardCharsets.UTF_8);】(1)int read()方法:————>读取字符,返回的int值对应2进制的"低16位"为读取到的字符数据(char值);如果int的值为-1,表示读取到了末尾
注1:实际应用中我们不直接操作这一对流,但是在读写文本数据而组件流连接时他们是非常重要的一环。
注2:作用:①在流连接中衔接其他高级字符流与下面的字节流(这也是转换流名字的由来)。②负责将字符与对应的字节按照指定的字符集自动转换方便读写操作。
因此注意:字符流仅适合读写文本数据(字符或字符串)。读写文件仅读写文本文件。字符流底层本质还是读写字节,只是字符与字节的转换由字符流自行完成。转换流的意义:
实际开发中我们还有功能更好用的字符高级流.但是其他的字符高级流都有一个共通点:
不能直接连接在字节流上.而实际操作设备的流都是低级流同时也都是字节流.因此不能
直接在流连接中串联起来.转换流是一对可以连接在字节流上的字符流,其他的高级字符
流可以连接在转换流上.在流连接中起到"转换器"的作用(负责字符与字节的实际转换)
01.转换字符输出流:java.io.OutputStreamWriter(OSW)
使用转换输出流向文件中写入文本数据:
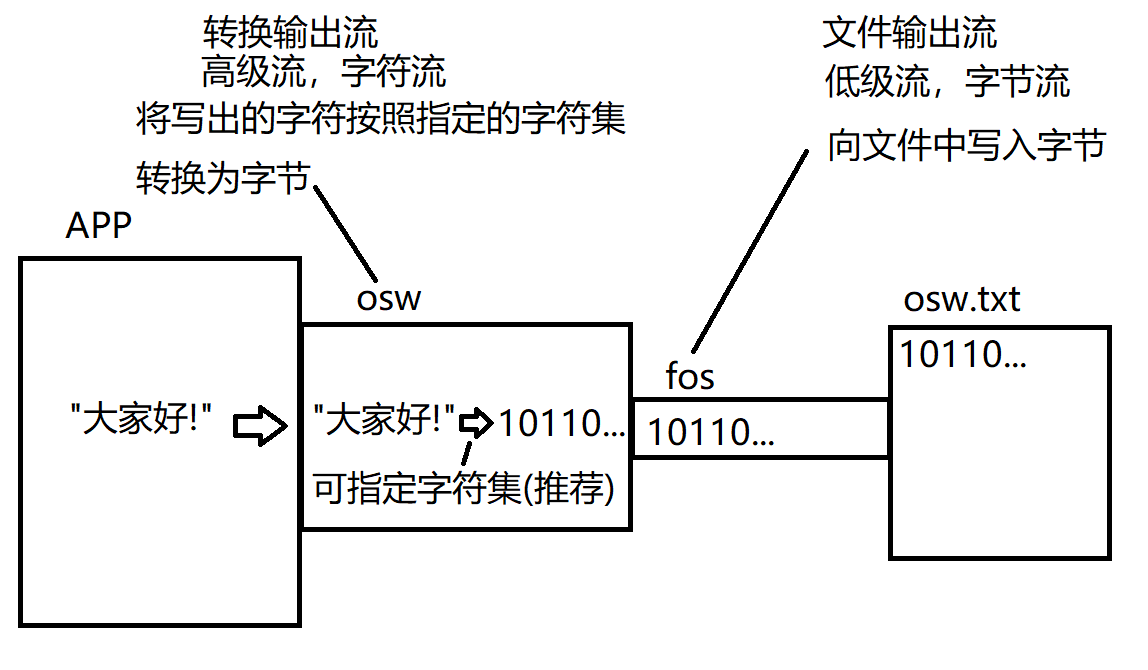
package apiday.day05.character_stream;
import java.io.*;
import java.nio.charset.StandardCharsets;
/*** 1、转换流(OSW/ISR):——————>是一对常用的字符流实现类:* 01.java.io.OutputStreamWriter(OSW):高级转换流;创建转换流时,可以通过第二个参数来指定字符集:* 【new OutputStreamWriter(fos,StandardCharsets.UTF_8);】* (1).write()方法:——————>可以直接写出字符流,无需再手动转换为字节*/
public class OSW {public static void main(String[] args) throws IOException {/** 1、01.OutStreamWriter:高级转换流 *///例:使用转换输出流向文件中写入文本数据:FileOutputStream fos = new FileOutputStream("./test/osw.txt");//创建转换流时,可以通过第二个参数来制定字符集OutputStreamWriter osw = new OutputStreamWriter(fos, StandardCharsets.UTF_8);String line = "铃铛~铃铛,响不响";
// byte[] data = line.getBytes(StandardCharsets.UTF_8);
// fos.write(data);//字符流的write方法可以直接写出字符流,无需再手动转换为字节osw.write(line);System.out.println("写出完毕");osw.close(); }
}
02.转换字符输入流:java.io.InputStreamReader(ISR)
使用转换流测试读取文本数据:
package apiday.day05.character_stream;
import java.io.*;
import java.nio.charset.StandardCharsets;
/*** 02.java.io.InputStreamReader(ISR):高级转换流;创建转换流时,可以通过第二个参数来指定字符集【new InputStreamReader(fis,StandardCharsets.UTF_8);】* (1)int read()方法:————>读取字符,返回的int值对应2进制的"低16位"为读取到的字符数据(char值);* 如果int的值为-1,表示读取到了末尾* 注1:实际应用中我们不直接操作这一对流,但是在读写文本数据而组件流连接时他们是非常重要的一环。* 注2:作用:①在流连接中衔接其他高级字符流与下面的字节流(这也是转换流名字的由来)。* ②负责将字符与对应的字节按照指定的字符集自动转换方便读写操作。*/
public class ISR {public static void main(String[] args) throws IOException {//例:使用转换流测试读取文本数据:将osw.txt中的所有内容读取出来并输出到控制台FileInputStream fis = new FileInputStream("./test/osw.txt");InputStreamReader isr = new InputStreamReader(fis,StandardCharsets.UTF_8);/*字符流:int read()读取一个字符,返回的int值对应2进制的"低16位"为读取到的字符数据(char值);00000000 00000000 10101010 10101010如果int的值为-1,表示读取到了末尾*/int d;while((d=isr.read())!=-1){System.out.println((char) d);}isr.close();}
}
6、缓冲字符流(br/bw/pw):是一对高级的字符流,作用是块写文本数据加速
2、缓冲字符流(br/bw/pw)————————>是一对高级的字符流,作用是块写文本数据加速(1)缓冲字符流内部维护一个数组,可以块读写文本数据来进行读写性能的提升。(2)缓冲字符流内部也有一个缓冲区,读写文本数据以块读写形式加快效率.并且缓冲流有一个特别的功能:可以按行读写文本数据.01.(1)java.io.BufferedReader:高级的字符流 ; 块读文本数据,并且可以按行读取字符串。①String readLine():连续读取若干字符,到换行符为止,然后将换行符之前的内容以一个字符串形式返回。注1:返回的字符串中不含有最后的换行符。如果单独读取了空行(此行内容只有一个换行符,比如当前源代码中的第二行就是空行),那么会返回一个空字符串。注2:当方法返回值为null时,表示流读取到了末尾。02.(1)java.io.BufferedWriter:高级的字符流;被PrintWriter包含在内。-------------------不是很常用!(2)java.io.PrintWriter:具有自动行刷新功能的缓冲字符输出流,【内部总是连接BufferWriter------更常用!!!】①例:自行完成流连接创建PrintWriter②例:完成简易记事本注:【equals:区分大小写<——————>equalsIgnoreCase:不区分大小写】
01.缓冲字符输入流:java.io.BufferedReader:根据读取的路径不同可以读取任意的程序源代码输出到控制台上
------高级的字符流 ; 块读文本数据,并且可以按行读取字符串。
01.(1)java.io.BufferedReader:高级的字符流 ; 块读文本数据,并且可以按行读取字符串。①String readLine():连续读取若干字符,到换行符为止,然后将换行符之前的内容以一个字符串形式返回。注1:(1)这是内存操作,因为第一次调用readLine时,缓冲流会将数据先一次性读取到内部的char数组中(8k的字符)。(2)返回的字符串中不含有最后的换行符。如果单独读取了空行(此行内容只有一个换行符,比如当前源代码中的第二行就是空行),那么会返回一个空字符串。注2:当方法返回值为null时,表示流读取到了末尾。练习题:《根据读取的路径不同可以读取任意的程序源代码输出到控制台上》:
package apiday.day05.character_stream;
import java.io.*;
/*** 2、缓冲字符流(br/bw/pw)————————>是一对高级的字符流,作用是块写文本数据加速* :缓冲字符流内部维护一个数组,可以块读写文本数据来进行读写性能的提升。* 01.(1)缓冲字符输入流:java.io.BufferedReader:——————>高级的字符流 ; 块读文本数据,并且可以按行读取字符串。* ①String readLine():连续读取若干字符,到换行符为止,然后将换行符之前的内容以一个字符串形式返回。* 注1:返回的字符串中不含有最后的换行符。如果单独读取了空行(此行内容只有一个换行符,比如当前源代码中的第二行就是空行),那么会返回一个空字符串。* 注2:当方法返回值为null时,表示流读取到了末尾。*/
public class BR {//————————>《根据读取的路径不同可以读取任意的程序源代码输出到控制台上》:public static void main(String[] args) throws IOException {/** 01.(1)缓冲字符输入流:java.io.BufferedReader:高级的字符流 ; 块读文本数据,并且可以按行读取字符串。 *///例:读取本程序(BR.java)的源代码输出到控制台上://文件字节输入流,低级流,字节流。功能:从文件中读取字节:FileInputStream fis = new FileInputStream("./src/apiday/day05/character_stream/BR.java");//转换输入流,高级流,字符流。功能:1衔接字节与其他字符流 2:将读取的字节转换为字符InputStreamReader isr = new InputStreamReader(fis);//缓冲字符输入流,高级流,字符流。功能:1块读文本数据加速 2:按行读取字符串BufferedReader br = new BufferedReader(isr);/*BufferedReader提供了一个读取一行字符串的方法:【String readLine()】:该方法会连续读取若干字符,当遇到换行符停止,然后将换行符之前的内容以一个字符串形式返回。注:这是内存操作,因为第一次调用readLine时,缓冲流会将数据先一次性读取到内部的char数组中(8k的字符)。返回的字符串中不含有最后的换行符。如果单独读取了空行(此行内容只有一个换行符,比如当前源代码中的第二行就是空行),那么会返回一个空字符串。如果流读取到了末尾,会返回null*///(1)------>只输出这两句就调用.close()会只读package包名那一行:
// String line = br.readLine();
// System.out.println(line);//(2)------>如下返回值!=null时,会在控制台读取当前程序的所有源代码。String line;//实际读取到的字符串while((line= br.readLine())!=null){System.out.println(line);//控制台输出此【BR.java】所有源代码!}br.close();}
}
02.缓冲字符输出流(BufferedWriter/PrintWriter: 带自动行刷新):
(1)缓冲字符输出流:java.io.PrintWriter:
①java.io.PrintWriter是具有自动行刷新功能的缓冲字符输出流,内部总是连接BufferedWriter;实际开发中缓冲字符输出流我们都使用它。
②缓冲字符流内部也有一个缓冲区,读写文本数据以块读写形式加快效率.并且缓冲流有一个特别的功能:可以按行读写文本数据.
(2)PrintWriter特点:
1:可以按行读写字符串
2:可以自动行刷新
3:可以提高写出字符的效率(实际由内部连接的BufferedWriter完整)


02.(1)java.io.BufferedWriter:高级的字符流;被PrintWriter包含在内。-------------------不是很常用!(2)java.io.PrintWriter:具有自动行刷新功能的缓冲字符输出流,【内部总是连接BufferWriter------更常用!!!】①例:连续调用.println()写入文本数据②例:在流连接中使用PW③例:PrintWriter的自动行刷新功能---完成简易记事本:如果实例化PW时第一个参数传入的是一个流,则此时可以再传入一个boolean型的参数,此值为true时就打开了自动行刷新功能。即:每当我们用PW的println方法写出一行字符串后会自动flush.注:【equals:区分大小写<——————>equalsIgnoreCase:不区分大小写】练习题:
package apiday.day05.character_stream;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;
/*** 02.(1)java.io.BufferedWriter:高级的字符流;被PrintWriter包含在内。-------------------不是很常用!* (2)java.io.PrintWriter:具有自动行刷新功能的缓冲字符输出流,【内部总是连接BufferWriter------更常用!!!】* ①例:连续调用.println()写入文本数据* ②例:在流连接中使用PW* ③例:PrintWriter的自动行刷新功能---完成简易记事本:* 如果实例化PW时第一个参数传入的是一个流,则此时可以再传入一个boolean型的参数,此值为true时就打开了自动行刷新功能。* 即:每当我们用PW的println方法写出一行字符串后会自动flush.* 注:【equals:区分大小写<——————>equalsIgnoreCase:不区分大小写】*/
public class PW {public static void main(String[] args) throws IOException {/** 2、02.(2)java.io.PrintWriter:具有自动行刷新功能的缓冲字符输出流,【内部总是连接BufferWriter------更常用!!!】 *//** ①例:连续调用.println()写入文本数据---向文件pw.txt中写入文本数据*//*PrintWriter提供了直接对文件做操作的构造器PrintWriter(String fileName)PrintWriter(File file)*/PrintWriter pw = new PrintWriter("./test/pw.txt","UTF-8");pw.println("你是风儿~我是沙");pw.println("你是月亮~我是沙");System.out.println("写出完毕");pw.close();/** ②例:在流连接中使用PW *///文件字节输出流(是一个低级流),向文件中写入字节数据FileOutputStream fos1 = new FileOutputStream("./test/pw2.txt",true);//转换输出流(是一个高级流,且是一个字符流)。1:衔接字符与字节流 2:将写出的字符转换为字节//创建转换流时指定字符集OutputStreamWriter osw1 = new OutputStreamWriter(fos1, StandardCharsets.UTF_8);//缓冲输出流(是一个高级流,且是一个字符流)。块写文本数据加速BufferedWriter bw1 = new BufferedWriter(osw1);/*PrintWriter提供的构造器中,当第一个参数为一个流时,就支持再传入一个boolean型的参数表示是否自动行刷新。当该值为true时则打开了自动行刷新功能。这就意味着每当我们调用println方法后会自动flush一次。*///具有自动行刷新的缓冲字符输出流:PrintWriter pw1 = new PrintWriter(bw1,true);//autoFlush:true————>[相当于pw.flush();自动行刷新功能]pw1.println("你好啊哥哥们,我是***,你是谁啊0");pw1.println("....hhh 不告诉你");System.out.println();pw1.close();/** ③:PrintWriter的自动行刷新功能---完成简易记事本。控制台输入的每行字符串都按行写入文件。单独输出exit时退出。*/PrintWriter pw2 =new PrintWriter("./test/pw.txtt");Scanner scanner = new Scanner(System.in);while(true){String line2 = scanner.nextLine();
// if("exit".equals(line2)){//————————————>equals:区分大小写if("exit".equalsIgnoreCase(line2)){//————>equalsIgnoreCase:不区分大小写break;}pw2.println(line2);//连续追加字符串
// pw.flush();//自动行刷新功能}pw2.close();}
}
7、字节数组流(BAOS/BAIS):一对低级流,内部维护一个字节数组
01.字节数组输出流:java.io.ByteArrayOutputStream
java.io.ByteArrayOutputStream和ByteArrayInputStream:他们是一对低级流,内部维护一个字节数组
01.字节数组输出流(java.io.ByteArrayOutputStream):通过该流写出的数据都会保存在内部维护的字节数组中(1)内部提供的方法:①Byte[] toByteArray():该方法返回的字节数组包含这目前通过这个流写出的所有字节②int size():返回的数字表示已经通过当前流写出来多少字节(在流自行维护的字节数组中实际保存了多少字节)02.字节数组输入流(java.io.ByteArrayOutputStream):package com.webserver.test;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
/*** java.io.ByteArrayOutputStream和ByteArrayInputStream:他们是一对低级流,内部维护一个字节数组* 01.字节数组输出流(java.io.ByteArrayOutputStream):通过该流写出的数据都会保存在内部维护的字节数组中* (1)内部提供的方法:* ①Byte[] toByteArray():该方法返回的字节数组包含这目前通过这个流写出的所有字节* ②int size():返回的数字表示已经通过当前流写出来多少字节(在流自行维护的字节数组中实际保存了多少字节)** 02.字节数组输入流(java.io.ByteArrayOutputStream):**/
public class BASO_Demo {public static void main(String[] args) throws FileNotFoundException {
// FileOutputStream fos = new FileOutputStream("./test/pw2.txt",true);//低级流,内部维护一个字节数组:ByteArrayOutputStream baos = new ByteArrayOutputStream();//转换输出流(是一个高级流,且是一个字符流)。1:衔接字符与字节流 2:将写出的字符转换为字节//创建转换流时指定字符集OutputStreamWriter osw = new OutputStreamWriter(baos, StandardCharsets.UTF_8);//缓冲输出流(是一个高级流,且是一个字符流)。块写文本数据加速BufferedWriter bw = new BufferedWriter(osw);/*PrintWriter提供的构造器中,当第一个参数为一个流时,就支持再传入一个boolean型的参数表示是否自动行刷新。当该值为true时则打开了自动行刷新功能。这就意味着每当我们调用println方法后会自动flush一次。具有自动行刷新的缓冲字符输出流:PrintWriter*/PrintWriter pw = new PrintWriter(bw,true);/*ByteArrayOutputStream内部提供的方法:①Byte[] toByteArray():该方法返回的字节数组包含着目前通过这个流写出的所有字节②int size():返回的数字表示已经通过当前流写出来多少字节(在流自行维护的字节数组中实际保存了多少字节)*/byte[] data = baos.toByteArray();System.out.println("内部数组长度:"+data.length);//内部数组长度:0System.out.println("内部数组内容:"+ Arrays.toString(data));//内部数组内容:[]System.out.println("内部已经通过当前流写出来多少字节:"+baos.size());//内部已经通过当前流写出来多少字节::0pw.println("helloword");data = baos.toByteArray();System.out.println("内部数组长度:"+data.length);//内部数组长度:11//内部数组内容:[104, 101, 108, 108, 111, 119, 111, 114, 100, 13, 10]System.out.println("内部数组内容:"+ Arrays.toString(data));System.out.println("内部已经通过当前流写出来多少字节:"+baos.size());//内部已经通过当前流写出来多少字节::11pw.println("think in java");data = baos.toByteArray();//内部数组内容:[104, 101, 108, 108, 111, 119, 111, 114, 100,// 13, 10, 116, 104, 105, 110, 107, 32, 105, 110, 32, 106, 97, 118, 97, 13, 10]System.out.println("内部数组内容:"+ Arrays.toString(data));System.out.println("内部已经通过当前流写出来多少字节:"+baos.size());//内部已经通过当前流写出来多少字节::26pw.close();}
}
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!