全国首富排行居然有他?用Python采集全国富豪榜五百名!
前言
背景
今天刷到一则文章,就是国内某富豪花重金迎娶泰国某**皇后!

可谓是有点颠覆了我的三观啊。有钱人都玩的这么花的吗?这里内容就不一一讲了,毕竟看咱文章的都是想来学技术的!那就废话不多说,开始干活!
正文
相关模块
今天不用其他的什么模块
python3.8
pycharm
一个用来进行数据可视化的模块
jupyter notebook
这里重点
由于很多观看文章的小伙伴都是新手,可能对爬虫不是很了解,所以这里多讲一点!
爬虫知识点: requests简单使用 get方法 获取数据 re模块简单使用 .*? csv 保存数据 基础知识点: 数据类型转换 --> json字典数据 列表取值 字典创建/取值 for循环遍历 print输出函数 pprint格式化输出模块的使用 函数关键字传参
这样就对怎么去爬取数据能有个清晰的认知了吧
干货
由于爬取的内容网站非常的简单,这个应该学了两天爬虫的都会!主要还是看咱们的代码,跟着代码来应该就能搞定它了,对了,后面还有个数据可视化!思路都一样,这里也偷个小懒,嘿嘿,就不过多的讲解今天的思路了!如果实在有不会的,我也录了视频!又想看的可以到下方小卡片找我

【----帮助Python学习,以下所有学习资料文末免费领!----】
排名第一的是不是你所始料未及的!居然是咱们经常喝的农夫山泉!
完整代码
"""
# 导入数据数据请求模块
import requests
# 导入正则模块
import re
# 导入json
import json
# 导入格式化输出模块
from pprint import pprint
# 导入csv模块
import csv# 创建文件 open函数
f = open('data.csv', mode='a', encoding='utf-8', newline='')
# 配置f文件对象 fieldnames 字段名 表头
csv_writer = csv.DictWriter(f, fieldnames=['姓名','财富(亿元)','主要公司','相关行业','公司总部','性别','年龄',
])
# 写入表头
csv_writer.writeheader()
"""
1. 发送请求, 模拟浏览器对于url地址发送请求- 请求链接 找到之后直接复制- 模拟浏览器 <防止反爬>headers 请求头 --> 复制I. 字典数据类型 <构建完整键值对> - 发送请求 <请求方式方法>get --> 开发者工具显示 请求方法GET
想要本节课代码吗? 你想要本节课录播吗?课堂多发言 多互动 --> 课后给可以发给你 响应对象 表示请求成功多页数据采集:分析请求url地址变化规律根据变化规律, 构建每一页请求链接
"""
for page in range(1, 35):# 请求链接url = f'https://service.ikuyu.cn/XinCaiFu2/pcremoting/bdListAction.do?method=getPage&callback=jsonpCallback&sortBy=&order=&type=4&keyword=&pageSize=15&year=2022&pageNo={page}&from=jsonp&_=1680086650173'# 模拟浏览器headers = {# User-Agent 用户代理, 表示浏览器基本身份信息'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'}# 发送请求response = requests.get(url=url, headers=headers)"""2. 获取数据, 获取服务器返回响应数据知识点:- response.text 和 response.json() 区别- 正则表达式提取数据正则表达返回列表数据, [0] 提取列表索引位置为0的元素, 也就是提取第一个元素- 列表索引取值- json模块的使用3. 解析数据, 提取我们想要的数据内容字典取值print(index) # 打印字典数据 返回一行pprint(index) # 打印字典数据 返回多行.*? --> 通配符 可以匹配任意字符 (除了\n换行符以外)"""# 正则匹配数据html_data = re.findall('jsonpCallback\((.*?)\)', response.text)[0]# 转换数据类型json_data = json.loads(html_data)# for循环遍历, 提取列表元素for index in json_data['data']['rows']:# 创建字典 --> 字典取值dit = {'姓名': index['name'],'财富(亿元)': index['assets'],'主要公司': index['company'],'相关行业': index['industry'],'公司总部': index['addr'],'性别': index['sex'],'年龄': index['age'],}# 写入数据csv_writer.writerow(dit)print(dit)
效果展示
这就是咱们爬下来的数据了!
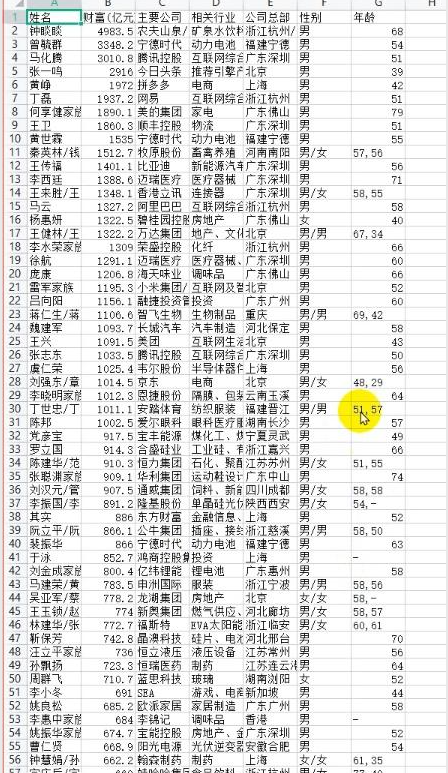
数据可视化


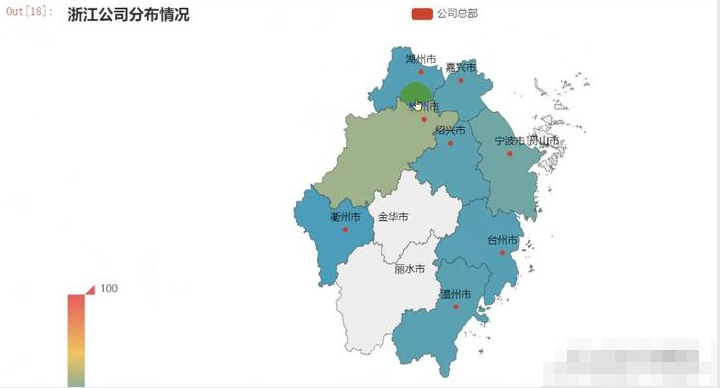
所以说学好爬虫,对于需要做统计表或者文员来讲实在是太方便了,几行代码就自动形成统计图,一目了然,老板看了直说好!
读者福利:知道你可能对Python感兴趣,便准备了这套python学习资料
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习等学习教程。带你从零基础系统性的学好Python!
零基础Python学习资源介绍
👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)
入门学习视频

👉实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉100道Python练习题👈
检查学习结果。
👉面试刷题👈


资料领取
上述这份完整版的Python全套学习资料已经上传CSDN官方,朋友们如果需要可以微信扫描下方CSDN官方认证二维码输入“领取资料” 即可领取

好文推荐
了解python的前景:https://blog.csdn.net/xiqng17111342931/article/details/127705925
了解python的副业:https://blog.csdn.net/xiqng17111342931/article/details/127872402
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!