Python内置方法详解后续
文章目录
- 一、列表内置方法
- 1. 统计列表中数据值的个数
- 2. 尾部追加数据值
- 3.任意位置插入数据值
- 4.扩展列表
- 5.查询数据与修改数据
- 6.删除数据
- 6.1.通用删除策略
- 6.2.指名道姓删除
- 6.3.先取出数据值 然后再删
- 7.查看数据值对于的索引值
- 8.统计某个数据值出现的次数
- 9.排序
- 10.翻转
- 二、元祖内置方法
- 1.类型转换
- 2.指引相关操作
- 3.统计元组内数据值的个数
- 4.查与改
- 三、字典内置方法
- 1.字典内k:v键值对是无序的
- 2.取值操作
- 3.统计字典中键值对的个数
- 4.修改数据
- 5.新增数据
- 6.删除数据
- 7.快速获取键 值 键值对数据
- 8.修改字典数据
- 9.快速构造字典
- 10.键存在则获取键对应的值
- 四、集合内置方法
- 1.去重
- 五、可变与不可变类型
- 1.可变类型
- 2.不可变类型
- 总结
提示:以下是本篇文章正文内容,下面案例可供参考
一、列表内置方法
1. 统计列表中数据值的个数
l2 = [77, 33, 22, 44, 55, 99, 88] print(len(l2)) # 关键词 len7
2. 尾部追加数据值
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry']l1.append([1, 2, 3, 4, 5]) # 关键词 .appendprint(l1) # 括号内无论写什么数据类型 都是当成一个数据值追加['jason', 'kevin', 'oscar', 'tony', 'jerry', [1, 2, 3, 4, 5]]
3.任意位置插入数据值
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry']l1.insert(0, '插队') # 关键词.insertprint(l1) # 括号内无论写什么数据类型 都是当成一个数据值插入['插队', 'jason', 'kevin', 'oscar', 'tony', 'jerry']
4.扩展列表
new_l1 = [11, 22, 33, 44, 55]new_l2 = [1, 2, 3] # extend(new_)new_l1.extend(new_l2) # 括号里面必须是支持for循环的数据类型 for循环+append()print(new_l1)
5.查询数据与修改数据
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry']print(l1) # 打印列表L1print(l1[0]) # 打印列表l10第一位print(l1[1:4]) # 打印从第二位开始l1[0] = 'jasonNB' # 数据一更改为 jasonnbprint(l1) # 已修改['jason', 'kevin', 'oscar', 'tony', 'jerry']jason['kevin', 'oscar', 'tony']['jasonNB', 'kevin', 'oscar', 'tony', 'jerry']6.删除数据
6.1.通用删除策略
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry']del l1[0] # 通过索引即可print(l1)['kevin', 'oscar', 'tony', 'jerry']
6.2.指名道姓删除
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry']res = l1.remove('jason') # 括号内必须填写明确的数据值 就地正法print(l1, res)['kevin', 'oscar', 'tony', 'jerry'] None
6.3.先取出数据值 然后再删
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry']res = l1.pop() # 默认取出列表尾部数据值 然后再删 先蹂躏一下再删print(l1, res)res = l1.pop(0)print(res, l1)['jason', 'kevin', 'oscar', 'tony'] jerryjason ['kevin', 'oscar', 'tony']7.查看数据值对于的索引值
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry']print(l1.index('kevin')) # .index kevin在哪1
8.统计某个数据值出现的次数
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry']l1.append('jason')l1.append('jason') # 结尾追加 jasonl1.append('jason')print(l1.count('jason'))print(l1) 4['jason', 'kevin', 'oscar', 'tony', 'jerry', 'jason', 'jason', 'jason']
9.排序
l2 = [77, 33, 22, 44, 55, 99, 88]l2.sort() # 升序print(l2) l2.sort(reverse=True) # 降序print(l2)[22, 33, 44, 55, 77, 88, 99] # 升序结果[99, 88, 77, 55, 44, 33, 22] # 降序结果
10.翻转
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry']l1.reverse() # 前后跌倒print(l1)['jerry', 'tony', 'oscar', 'kevin', 'jason']
二、元祖内置方法
1.类型转换
print(tuple(123))print(tuple(123.11)) # 支持for循环的数据类型都可以转元组print(tuple('hello'))
2.指引相关操作
t1 = (11, 22, 33, 44, 55, 66)print(t1[0]) # 取列表中的第0位print(t1[0:2]) # 取列表中的0~211(11, 22)
3.统计元组内数据值的个数
t1 = (11, 22, 33, 44, 55, 66)print(len(t1)) # 关键词 len 统计数据值个数6
4.查与改
t1 = (11, 22, 33, 44, 55, 66)print(t1[0]) # 可以查t1[0] = 222 # 不可以改 元祖的特性就是不能改数据值!11
三、字典内置方法
1.字典内k:v键值对是无序的
info = {'username': 'jason','pwd': 123,'hobby': ['read', 'run']}K是对V的描述性性质的信息一般是字符串 K其实只要是不可变类型都可以
2.取值操作
info = {'username': 'jason','pwd': 123,'hobby': ['read', 'run']}print(info['username']) # 不推荐使用 键不存在会直接报错# print(info['xxx']) # 不推荐使用 键不存在会直接报错print(info.get('username')) # jasonprint(info.get('xxx')) # Noneprint(info.get('username', '键不存在返回的值 默认返回None')) # jasonprint(info.get('xxx', '键不存在返回的值 默认返回None')) # 键不存在返回的值 默认返回Noneprint(info.get('xxx', 123)) # 123print(info.get('xxx')) # None
3.统计字典中键值对的个数
info = {'username': 'jason','pwd': 123,'hobby': ['read', 'run']}print(len(info)) # 统计 len3
4.修改数据
info = {'username': 'jason','pwd': 123,'hobby': ['read', 'run']}info['username'] = 'jasonNB' # 键存在则是修改print(info) # 不存在是修改不了的哦!
5.新增数据
info = {'username': 'jason','pwd': 123,'hobby': ['read', 'run']}info['salary'] = 6 # 键不存在则是新增print(info){'username': 'jason', 'pwd': 123, 'hobby': ['read', 'run'], 'salary': 6}
6.删除数据
info = {'username': 'jason','pwd': 123,'hobby': ['read', 'run']}del info['username'] # 方式一print(info) # {'pwd': 123, 'hobby': ['read', 'run']}res = info.pop('username') # 方式二print(info, res) # {'pwd': 123, 'hobby': ['read', 'run']} jasoninfo.popitem() # 随机删除 方式三print(info) # {'username': 'jason', 'pwd': 123}jason7.快速获取键 值 键值对数据
info = {'username': 'jason','pwd': 123,'hobby': ['read', 'run']}print(info.keys()) # 获取字典所有的k值print(info.values()) # 获取字典所有的v值print(info.items()) # 获取字典kv键值对数据 组织成列表套元组dict_keys(['username', 'pwd', 'hobby'])dict_values(['jason', 123, ['read', 'run']])dict_items([('username', 'jason'), ('pwd', 123), ('hobby', ['read', 'run'])])
8.修改字典数据
info = {'username': 'jason','pwd': 123,'hobby': ['read', 'run']}info.update({'username':'jason123'}) # update 更新jason123print(info)info.update({'xxx':'jason123'}) # 找不到k就新建一个print(info){'username': 'jason123', 'pwd': 123, 'hobby': ['read', 'run']}{'username': 'jason123', 'pwd': 123, 'hobby': ['read', 'run'], 'xxx': 'jason123'}9.快速构造字典
new_dict = dict.fromkeys(['name', 'pwd', 'hobby'], []) # {'name': [], 'pwd': [], 'hobby': []}new_dict['name'] = []new_dict['name'].append(123) # name赋值 123new_dict['pwd'].append(123) # pwd 赋值 123new_dict['hobby'].append('read') # hobby 赋值 readprint(new_dict) # 新建一个 字典{'name': [123], 'pwd': [123, 'read'], 'hobby': [123, 'read']}
10.键存在则获取键对应的值
info = {'username': 'jason','pwd': 123,'hobby': ['read', 'run']}res = info.setdefault('username', 'jasonNB') print(res, info) # 如果键中有则取值 没有新建 jason 有值!res1 = info.setdefault('xxx', 'jasonNB')print(res1, info) # 没有值则新建 jason {'username': 'jason', 'pwd': 123, 'hobby': ['read', 'run']}jasonNB {'username': 'jason', 'pwd': 123, 'hobby': ['read', 'run'], 'xxx': 'jasonNB'}
四、集合内置方法
1.去重
s1 = {1, 2, 12, 3, 2, 3, 2, 3, 2, 3, 4, 3, 4, 5, 4, 5, 4, 5, 4, 5, 4}print(s1) # 自动去除相同的数字 升序{1, 2, 3, 4, 5, 12} # 这一行是结果 l1 = ['jason', 'jason', 'tony', 'oscar', 'tony', 'oscar', 'jason']s2 = set(l1) # l1变成集合命名给s2 去除重复l1 = list(s2) # s2变成列表命名给l1print(l1) ['oscar', 'jason', 'tony'] # 这是结果
五、可变与不可变类型
1.可变类型
可变类型 list值改变(内置方法) 内存地址可以不变 l1 = [11, 22, 33]print(id(l1)) # 140492407076608l1.append(44) # [11, 22, 33, 44]print(id(l1)) # 140492407076608

2.不可变类型
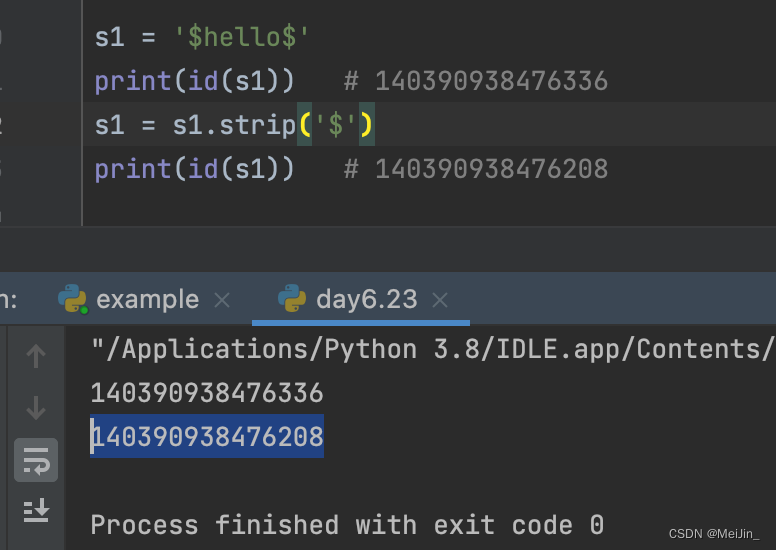
不可变类型 str int float值改变(内置方法) 内存地址肯定变s1 = '$hello$'print(id(s1)) # 140390938476336s1 = s1.strip('$')print(id(s1)) # 140390938476208ccc = 666 print(id(ccc)) # 140528780083856ccc = 990print(id(ccc)) # 140528780084080
总结
这里对文章进行总结:
以上就是今天要讲的内容,本文仅仅简单介绍了python内置方法的使用,而python提供了大量能使我们快速便捷地处理数据的内置方法和类型转换。有错误或不解的地方请指出,如果这篇文章对你有所帮助请点赞收藏+关注谢谢支持!
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!