clickhouse跳坑指南
一、Clickhouse优缺点
优点:
1,为了高效的使用CPU,数据不仅仅按列存储,同时还按向量进行处理;
2,数据压缩空间大,减少IO;处理单查询高吞吐量每台服务器每秒最多数十亿行;
3,索引非B树结构,不需要满足最左原则;只要过滤条件在索引列中包含即可;即使在使用的数据不在索引中,由于各种并行处理机制ClickHouse全表扫描的速度也很快;
4,写入速度非常快,50-200M/s,按照每行100Byte估算,大约相当于50W-200W条/s的写入速度。
缺点:
1,不支持事务;
2,不支持高并发,官方建议qps为100,可以通过修改配置文件增加连接数,但是在服务器足够好的情况下;
3,SQL满足日常使用80%以上的语法,join写法比较特殊;最新版已支持类似SQL的join,但性能不好;
4,尽量做1000条以上批量的写入,避免逐行insert或小批量的insert,update,delete操作,因为ClickHouse底层会不断的做异步的数据合并,会影响查询性能,这个在做实时数据写入的时候要尽量避开;
5,Clickhouse快是因为采用了并行处理机制,即使一个查询,也会用服务器一半的CPU去执行,所以ClickHouse不能支持高并发的使用场景,默认单查询使用CPU核数为服务器核数的一半,安装时会自动识别服务器核数,可以通过配置文件修改该参数。
二、相关优化点
1,为每一个账户添加join_use_nulls配置,左表中的一条记录在右表中不存在,右表的相应字段会返回该字段相应数据类型的默认值,而不是标准SQL中的Null值。
2,JOIN操作时一定要把数据量小的表放在右边,ClickHouse中无论是Left Join 、Right Join还是Inner Join永远都是拿着右表中的每一条记录到左表中查找该记录是否存在,所以右表必须是小表。
3,批量写入数据时,必须控制每个批次的数据中涉及到的分区的数量,在写入之前最好对需要导入的数据进行排序。无序的数据或者涉及的分区太多,会导致ClickHouse无法及时对新导入的数据进行合并,从而影响查询性能。
4,尽量减少JOIN时的左右表的数据量,必要时可以提前对某张表进行聚合操作,减少数据条数。有些时候,先GROUP BY再JOIN比先JOIN再GROUP BY查询时间更短。
5,ClickHouse的建表分区字段值不宜过多,防止数据导入过程磁盘可能会被打满。
6,CPU一般在50%左右会出现查询波动,达到70%会出现大范围的查询超时,CPU是最关键的指标,要非常关注。
7,数据写入性能:建议每次写入不少于1000行的批量写入,或每秒不超过一个写入请求。当使用tab-separated格式将一份数据写入到MergeTree表中时,写入速度大约为50到200MB/s。如果您写入的数据每行为1Kb,那么写入的速度为50,000到200,000行每秒。如果您的行更小,那么写入速度将更高。为了提高写入性能,您可以使用多个INSERT进行并行写入,这将带来线性的性能提升。
其他补充:
1,MySQL单条SQL是单线程的,只能跑满一个core,ClickHouse相反,有多少CPU,吃多少资源,所以飞快;
2,ClickHouse不支持事务,不存在隔离级别。ClickHouse的定位是分析性数据库,而不是严格的关系型数据库。
3,IO方面,MySQL是行存储,ClickHouse是列存储,后者在count()这类操作天然有优势,同时,在IO方面,MySQL需要大量随机IO,ClickHouse基本是顺序IO。
有人可能觉得上面的数据导入的时候,数据肯定缓存在内存里了,这个的确,但是ClickHouse基本上是顺序IO。对IO基本没有太高要求,当然,磁盘越快,上层处理越快,但是99%的情况是,CPU先跑满了(数据库里太少见了,大多数都是IO不够用)。
三、跳坑指南
1、Clickhouse 高频删除数据导致 Cannot allocate memory.

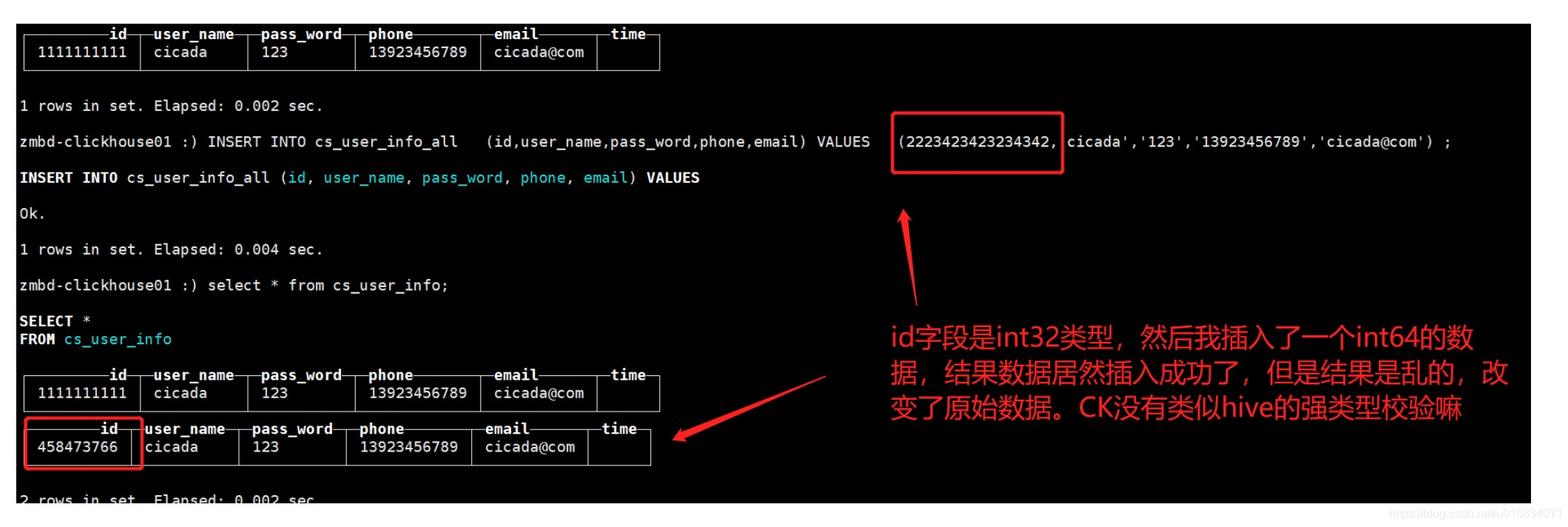
2、clickHouse中字段没有强类型校验:
注:如果我们建表的时候指定数据类型为int32,但是数据插入时不小心插入了一个超过int32范围的数据,最终存到表里的数据会被ClickHouse内部机制进行截取,造成数据不一致
3、clickHouse中对重复数据的处理:
经测试,clickHouse对重复数据插入,同一个分片上会进行去重,不同分片间不保证重复,所以clickHouse对重复数据有可能进行了去重也有可能没去重,这是不预测的!
4、Clickhouse 批量插入报错:Too many partitions for single INSERT block (more than 100)
两种解决办法:
1、配置文件修改: 在users.xml配置文件中进行配置。配置在
2、在一个会话中临时修改:SET max_partitions_per_insert_block=1000。用于临时导入大量数据的情况。
参数:Clickhouse 批量插入报错:Too many partitions for single INSERT block (more than 100) - 简书
5、Clickhouse 删除数据,然后插入相同的数据不显示
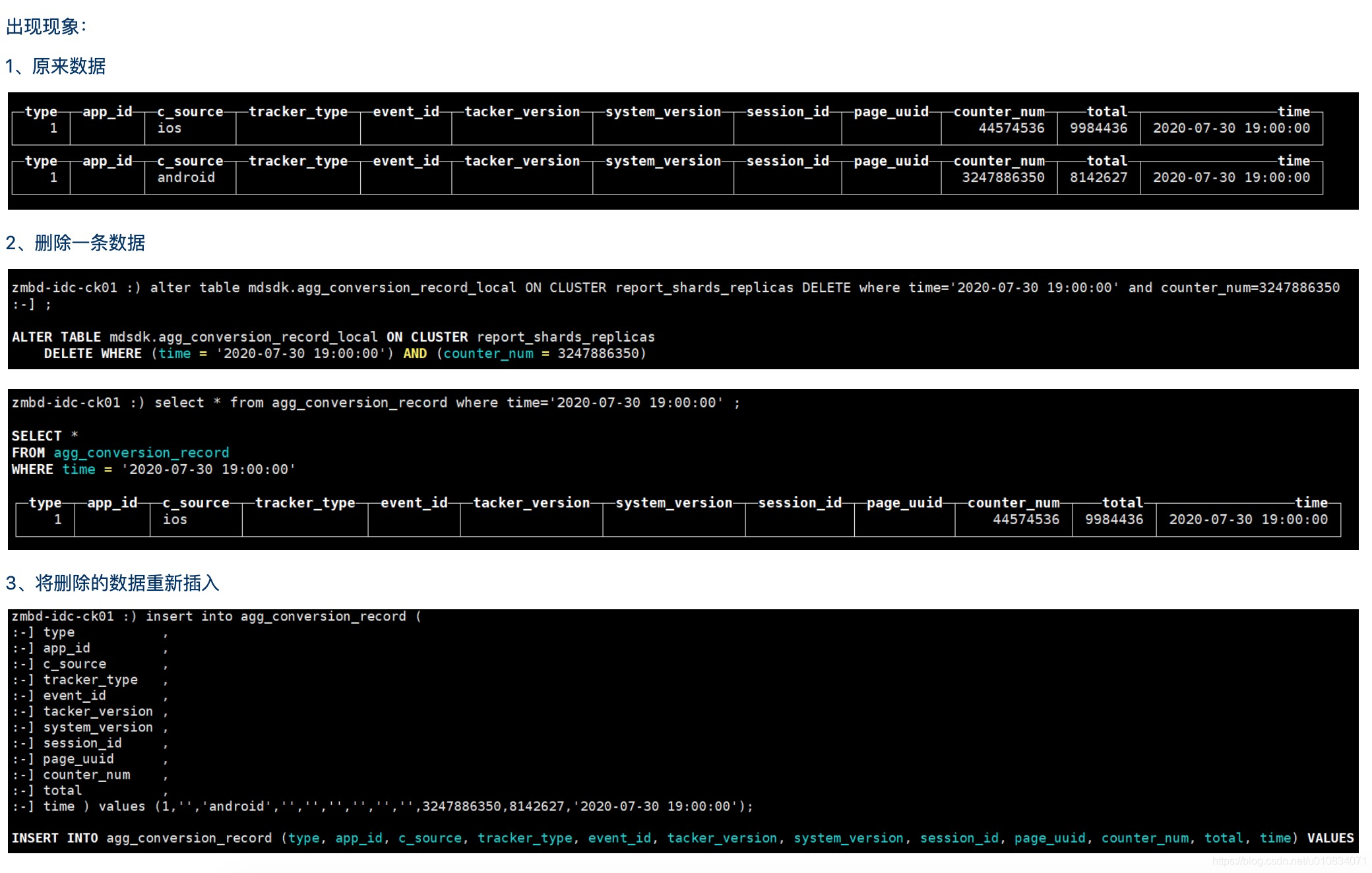

综上:发现这一问题,去查询了官方文档没找到原因,然后看了下mergeTree底层原理,了解到基于合并树原理,它后台不定期合并,移除没用的数据,时间是不可预估的!如果你插入数据的时候它后台没合并的话,你是插不进去的,因为数据已经有了,默认去重
尝试1:执行手动合并命令--→ optimize table +本地表名 ON CLUSTER report_shards_replicas;
optimize table agg_conversion_record_local ON CLUSTER report_shards_replicas;
结果:失败
尝试2 : SET insert_deduplicate=0
另外ck没有事务概念,但是为了保证重复插入的insert的幂等性,会检测重复,如果重复则跳过。
如果想不跳过可以SET insert_deduplicate=0
不建议关掉这个重复检查,因为这事唯一的幂等性检测,另外重复的数据块是以批次为单位的,如果同一批次和第二批次是一模一样的,通常情况下就不会产生删除了再插入的情况。
结果 :成功
6、Clickhouse 新增一个字段,并且赋默认值
语法:ALTER TABLE apm.track_apm_network ADD COLUMN timestamp DateTime DEFAULT now();
问题:历史数据新增字段之后,默认取now()当前时间,每次查询同一条数据结果不一致,每次都是当前时间
解决:测试发现,只有历史数据中的新增的字段会发生变化,新插入的数据正常没有影响。
故添加需要赋now() 时间所需的字段,若历史数据对业务影响不大,可以先truncate 将历史数据清除
7、Clickhouse 有默认时间字段,后续通过insert into插入数据问题
背景: INSERT INTO cs_user_info (id,user_name,pass_word,phone,email) VALUES (100,'cicada','123','121231231','cicada@com') 语句,要使用默认值则不必添加默认值的字段,系统会自动生成值
实际代码中调用发现,框架会自动封装所有的字段,类似 INSERT INTO cs_user_info (id,user_name,pass_word,phone,email,time,create_day) VALUES (?,?,?,?,?,?)
产生问题:其中time和create_day必须赋予初始值,若赋初始值的话那么now()当前时间不生效
|
|
解决方案:发现在插入数据时可以直接用now()来进行写入,clickHouse后台会自动解析然后生成时间
example:
INSERT INTO cs_user_info (id,user_name,pass_word,phone,email) VALUES (100,'cicada','123','121231231','cicada@com',now(),now())
8、Clickhouse 的物化视图的大坑介绍
物化视图的工作原理:当将数据写入到物化视图中SELECT子句所指定的表时,插入的数据会通过SELECT子句查询进行转换并将最终结果插入到视图中,存储到磁盘。与视图的不同点是:视图只是一个Sql的链接,它并不存储实际的数据
原以为的使用背景:通过定义好一段聚合逻辑,其会不断的在后台对原始表的数据查询,并将聚合的结果存储到本地
现实测试发现:它并不会对每一条增量数据进行实时计算,而是类似触发器对每批次插入的数据进行汇总,然后增量叠加(注意:是叠加,历史数据它并不会重新计算)、
结果:导致我们取到的数据并不是一次汇总的结果,而是多次汇总的叠加增量值,后续如果要使用数据,还需要对数据再次进行聚合
测试案例链接:
ClickHouse Materialized Views Illuminated, Part 1 – Altinity | The Real Time Data Company Clickhouse 物化视图 MATERIALIZED VIEW_click 雾化视图_vkingnew的博客-CSDN博客
9、clickhouse增量写入和全量写入最佳实践
Hive数据同步到Clickhouse为例:
增量写入:注意一定要创建分区表
---- 创建本地表
CREATE TABLE bi.bi_xxx_local ON CLUSTER report_shards_replicas( \
`app_id` Nullable(Int32), \
`event_id` Nullable(String), \
`device_id` Nullable(String), \
`user_id` Nullable(Int64), \
`event_date` Date, \
`pv` Nullable(Int32), \
`role` Nullable(String), \
`page_id` Nullable(String), \
`channel_source` Nullable(String), \
`channel_code` Nullable(String), \
`channel_key` Nullable(String), \
`act_key` Nullable(String), \
`event_no` Nullable(String), \
`app_version` Nullable(String) \
) ENGINE = ReplicatedMergeTree ('/clickhouse/tables/{layer}-{shard}/bi/xxx_local', '{replica}') PARTITION BY event_date \
order by event_date \
SETTINGS index_granularity = 8192;---- 创建分布式表
CREATE TABLE bi.xxx ON CLUSTER report_shards_replicas( \
`app_id` Nullable(Int32), \
`event_id` Nullable(String), \
`device_id` Nullable(String), \
`user_id` Nullable(Int64), \
`event_date` Date, \
`pv` Nullable(Int32), \
`role` Nullable(String), \
`page_id` Nullable(String), \
`channel_source` Nullable(String), \
`channel_code` Nullable(String), \
`channel_key` Nullable(String), \
`act_key` Nullable(String), \
`event_no` Nullable(String), \
`app_version` Nullable(String) \
) ENGINE = Distributed (report_shards_replicas,bi,xxx_local,rand());---- 使用waterdrop写入
---- 1.conf
spark {
spark.sql.catalogImplementation = "hive"
spark.app.name = "Waterdrop"
spark.executor.instances = 6
spark.executor.cores = 4
spark.executor.memory = "4g"
}
input {
hive {
pre_sql = "select app_id,event_id,device_id,user_id,event_date,pv,role,page_id,channel_source,channel_code,channel_key,act_key,event_no,app_version from bi.bi_behavior_event_analysis_active_di where pt ='"${pt}"'"
table_name = "bi_behavior_event_analysis_active_di_tmp"
}
}
filter {
}
output {
clickhouse {
host = "xxx:18123"
database = "bi"
table = "xxxx_local"
fields = [
"app_id","event_id","device_id","user_id","event_date","pv","role","page_id","channel_source","channel_code","channel_key","act_key","event_no","app_version"
]
username = "xxx"
password = "xxxxx"
clickhouse.socket_timeout = 50000
bulk_size = 500000
retry_codes = [209, 210]
retry = 3
}
}---- 使用waterdrop进行写入
/bin/bash /home/bigdata/program/waterdrop-1.5.0/bin/start-waterdrop.sh \
--master yarn --queue root.queue.production \--deploy-mode client \--config /xx/1.conf > 1.log 2>&1 & ---- 查看分区情况
select partition, name, active from system.parts WHERE table = 'bi.xxx'; ---- 删除分区
ALTER TABLE bi.xxx_local ON CLUSTER report_shards_replicas DROP PARTITION '2020-09-26';全量写入:可以创建分区表或者非分区表
思路:写入时复制一个源表的临时表,写完之后在rename,如果任务失败,可以对生成的临时表进行truncate之后在继续写入,当任务完成之后删除目标表即可。
10、clickhouse修改列报错
>>> ALTER table bi.xxxx on cluster report_shards_replicas MODIFY COLUMN event_date Date;
Received exception from server (version 20.5.4):
Code: 48. DB::Exception: Received from xx:9000. DB::Exception: There was an error on [xxx:9000]: Cannot execute replicated DDL query on leader.
4 rows in set. Elapsed: 12.064 sec.
原因:主键的字段类型是不能被更改的!强制更改会报错,非主键是可以改的(我这里event_date为排序列默认为主键,如建表的时候没有设置 的话)
但是如果字段类型不能相互转换的话,会报错(比如讲 int 类型强转成Date,会报错),这时可以新建表将数据insert select过去,然后在rename即可。
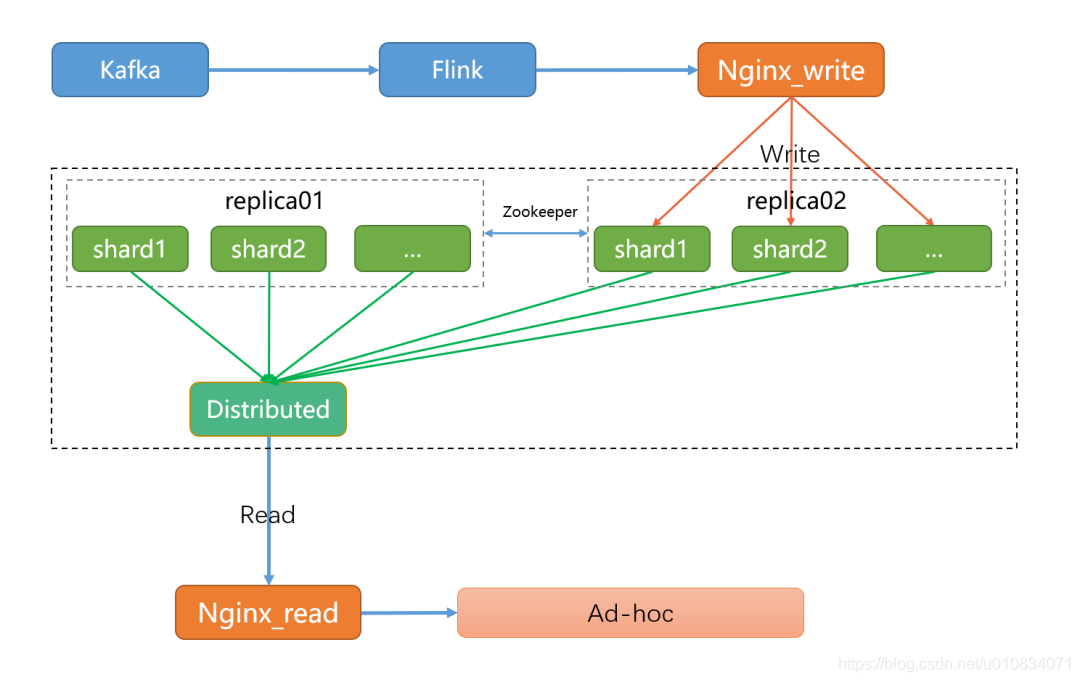
11、生产clickhouse部署模式
外面一层使用nginx负载写本地表,然后使用nginx负载均衡查分布式表即可。
>> 完 <<
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!