kafka学习之一(入门)
kafka学习之一(入门)
kafka是干什么的?
出入公司除了正常接触前后端、数据库,日常提及最多的就是kafka,很多功能业务都要连接kafka,那么kafka究竟是做什么的?为什么在实际应用中这么重要?
kafka是分布式流式计算平台
官方定义 kafka 是一个分布式流式计算平台
- 关键功能(消息、持久化、流处理):
- 发布和订阅记录流,类似于消息队列或企业消息传递系统;
- 以容错持久的方式存储记录流;
- 在记录流出现时对其进行处理;
- 具体应用(实时流数据管道、实时流应用程序):
- 构建实时流数据管道,在系统或应用程序之间可靠地获取数据;
- 构建实时流应用程序,转换或响应数据流;
- 相关概念(集群、主题、记录):
- Kafka作为集群运行在一个或多个服务器上,这些服务器可以跨多个数据中心;
- 卡夫卡集群以称为主题的类别存储记录流;
- 每个记录由一个键、一个值和一个时间戳组成
从以上可以看出:收集、存储、处理
kafka提供的是强大的数据集成功能,它可以将合适的数据以合适的形式放置在合适的位置。
kafka是一个日志收集系统
随着互联网的不断发展,用户所产生的行为数据被越来越多的企业,尤其是银行业所重视。此时就需要利用kafka来实现。
- 应用场景:用户行为数据的存储
- 收集日志并保存
- 日志的快速检索定位
日志采集流程图如下所示: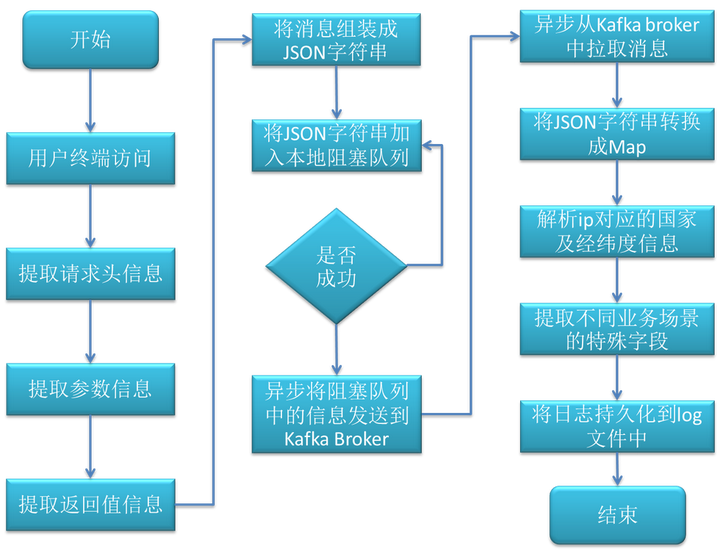 上图为消息生产者和消息消费者共同组成的流程图。
上图为消息生产者和消息消费者共同组成的流程图。
- 消息生产者的具体步骤如下:
- 通过切面拦截用户的请求。
- 从切面中提取请求头的基本信息,如设备信息,cookie信息,ip信息等。
- 提取请求的接口参数信息。
- 从接口返回值中提取相关信息,如id,pvid等。
- 将提取的信息封装成JSON字符串,放到阻塞队列中,假如阻塞队列溢出会有三次重试机制。
- 异步线程从本地阻塞队列中获取数据,并将信息组装发送到Kafka的Broker中,此时消息生产者结束。
- 消息消费者的具体步骤如下:
- 实时从Kafka Broker中批量拉取消息。
- 将拉取的消息转化成对象。解析ip对应的国家、省份、城市、经纬度信息。
- 对不同业务场景的信息进一步解析。
- 将日志信息转化成JSON字符串,持久化到log文件中。
Kafka中的日志就像数据库中的记录,或者是commit log一样的日志,是按照时间顺序写入的,但是Kafka并不是直接将message直接写到日志里的,而是把消息和timestamp,version等信息一起放到record里存储的。
- Kafka解决查询效率的手段:
- 数据文件分段:数据文件分段使得可以在一个较小的数据文件中查找对应offset的Message了,但是这依然需要顺序扫描才能找到对应offset的Message。
- 建立索引:索引文件中包含若干个索引条目,每个条目表示数据文件中一条Message的索引。索引包含两个部分(均为4个字节的数字),分别为相对offset和position。index文件中每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。
kafka是一个消息分发的总控系统
在实现复杂的系统时,不得不面对的是在多系统间的消息交互。我们可以利用系统之间的接口进行沟通,也可以利用消息分发的中间系统进行传递,这时,选择kafka是一个很好的选择。
kafka的架构: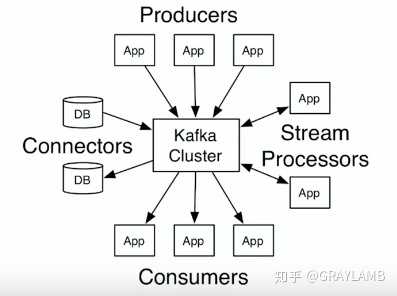
- Producers:会产生很多的消息和信息送给kafka。kafka会把这些消息存储下来。
- Consumers:会从kafka获取它所需要的数据,然后自行处理,比如Consumers可能会降消息存储到hadoop、cassandra、HBase。
- 流处理App:kafka可以很好的支持流处理(支持很多“流API”),一些流处理框架下的App可以接入kafka,并且可以实时的获取变化的数据和消息,对消息进行处理后可以立刻存回kafka,等待其它Consumers调用。
- connectors:通过它,你可以将kafka与不同的数据库或App联通,实现海量数据导入kafka或者从kafka导出。
当然,仅知道kafka的用处是远远不够的,要深入的理解kafka还要理解消息队列、zookeeper等等,期待之后的学习。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!