ChatGPT实践应用和大模型技术解析
点击蓝字 关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式
计算机视觉研究院专栏
Column of Computer Vision Institute
从技术原理、实战、应用等多维角度,共同探讨ChatGPT和大模型在当今技术领域的影响和变革
深度学习是机器学习的分支,大语言模型是深度学习的分支。
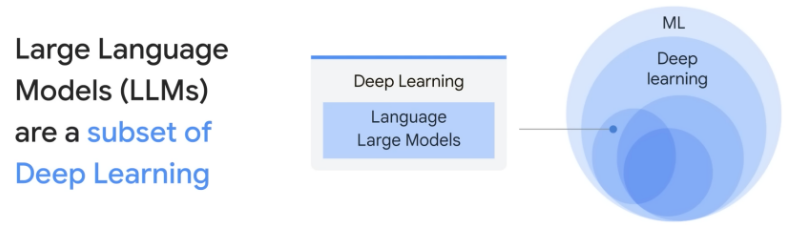
机器学习是人工智能(AI)的一个子领域,它的核心是让计算机系统能够通过对数据的学习来提高性能。在机器学习中,我们不是直接编程告诉计算机如何完成任务,而是提供大量的数据,让机器通过数据找出隐藏的模式或规律,然后用这些规律来预测新的、未知的数据。
深度学习是机器学习的一个子领域,它尝试模拟人脑的工作方式,创建所谓的人工神经网络来处理数据。这些神经网络包含多个处理层,因此被称为“深度”学习。深度学习模型能够学习和表示大量复杂的模式,这使它们在诸如图像识别、语音识别和自然语言处理等任务中非常有效。
大语言模型是深度学习的应用之一,尤其在自然语言处理(NLP)领域。这些模型的目标是理解和生成人类语言。为了实现这个目标,模型需要在大量文本数据上进行训练,以学习语言的各种模式和结构。如 ChatGPT,就是一个大语言模型的例子。被训练来理解和生成人类语言,以便进行有效的对话和解答各种问题。
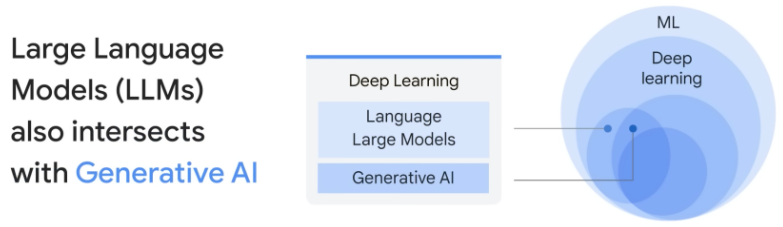
生成式AI是一种能够创造新的内容或预测未来数据的人工智能技术。

这种技术包括用于生成文本、图像、音频和视频等各种类型的内容的模型。生成式AI的一个关键特性是,它不仅可以理解和分析数据,还可以创造新的、独特的输出,这些输出是从学习的数据模式中派生出来的。
大型通用语言模型可以进行预训练,然后针对特定目标进行微调。
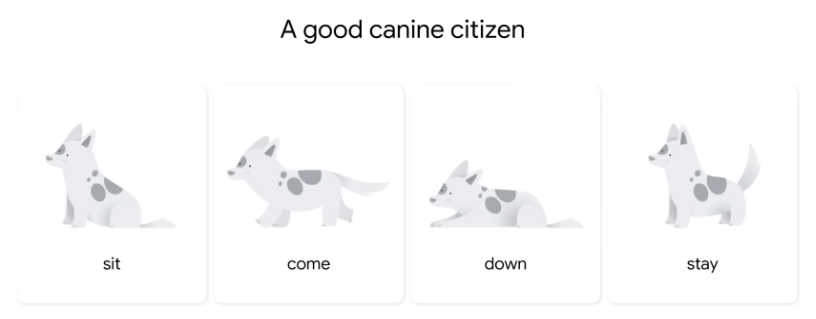
训练:训练狗狗为例,可以训练它坐、跑过来、蹲下、保持不动。
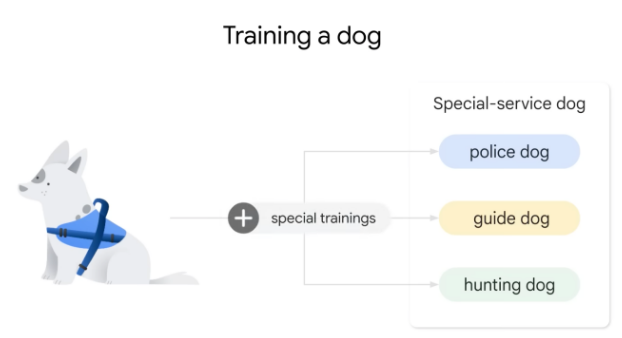
如果想训练警犬、导盲犬和猎犬,则需要特殊的训练方法。

大语言模型的训练也采用与之类似的思路。

大型语言模型被训练来解决通用(常见)的语言问题,如文本分类、问答、文档总结和文本生成等。
(1)文本分类:大型语言模型可以通过对输入文本进行分析和学习,将其归类到一个或多个预定义的类别中。例如,可以使用大型语言模型来分类电子邮件是否为垃圾邮件,或将推文归类为积极、消极或中立。
(2)问答:大型语言模型可以回答用户提出的自然语言问题。例如,可以使用大型语言模型来回答搜索引擎中的用户查询,或者回答智能助手中的用户问题。
(3)文档总结:大型语言模型可以自动提取文本中的主要信息,以生成文档摘要或摘录。例如,可以使用大型语言模型来生成新闻文章的概要,或从长篇小说中提取关键情节和事件。
(4)文本生成:大型语言模型可以使用先前学习的模式和结构来生成新的文本。例如,可以使用大型语言模型来生成诗歌、短故事、或者以特定主题的文章。
大语言模型的能力与局限,作为使用者的一些见解:
LLM是一个万能函数,而不是一个全能助手
大语言模型到可用的距离——很近,但还有点远
超长上下文
Claude 100K Context 将极大增强LLM的可用性
持久化记忆
基于向量数据库的召回检索方法精度依然无法满足多数场景的使用,分片Embedding会丢失很多局部语义信息
模型推理速度与成本
GPT-4很优秀,但费用昂贵
OpenAI最近的访谈透露,GPT-4的诸多能力受制于GPU算法短缺,正是这个原因无法开放用户微调模型权重能力
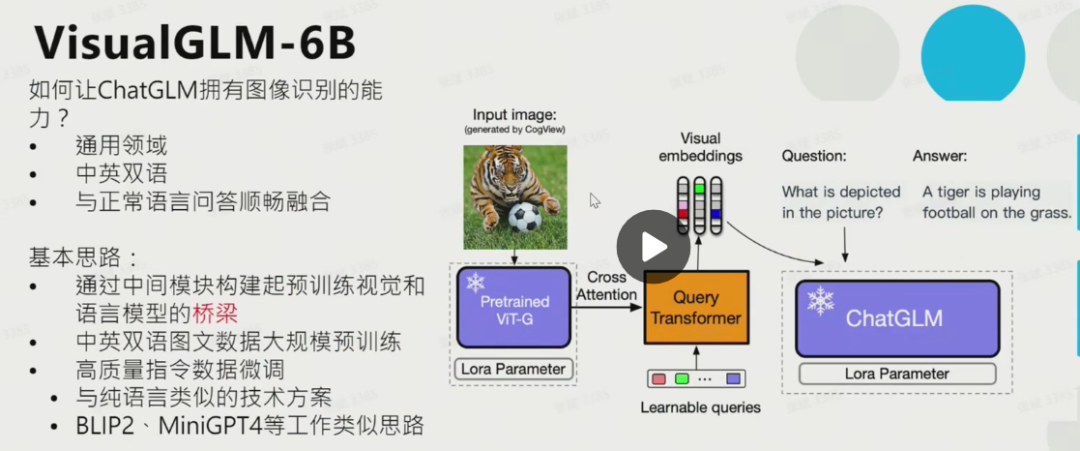
VisualCLM-6B的原理与微调


from丁铭

© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
VX:2311123606

往期推荐
🔗
中国提出的分割天花板 | 精度相当,速度提升50倍!
All Things ViTs:在视觉中理解和解释注意力
基于LangChain+GLM搭建知识本地库
OVO:在线蒸馏一次视觉Transformer搜索
最近几篇较好论文实现代码(附源代码下载)
AI大模型落地不远了!首个全量化Vision Transformer的方法FQ-ViT(附源代码)
CVPR 2023|EfficientViT:让ViT更高效部署实现实时推理(附源码)
VS Code支持配置远程同步了
基于文本驱动用于创建和编辑图像(附源代码)
基于分层自监督学习将视觉Transformer扩展到千兆像素图像
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!