科研周报1
时间:2023-07-26至2023-08-02
研发
目前直径为50cm的球形机器人在航向控制上还存在问题。如果角速度控制器使用PID,航向角控制器使用S面,控制效果不好,现象是航向跟踪收敛速度缓慢,导致巡线时路线歪歪扭扭。在直径为80cm的球形机器人上,同样的架构,则可以控制得很好,现象是航向跟踪基本上都是一步到位,使得巡线时路径平滑笔直。可能原因:或许是PID参数没有调整好,也可能是S面参数没有调整好,也可能是都有问题。是否是PID参数的原因可以依据下发固定期望角速度然后根据跟踪情况来判断,但是之前做的实验,只能知道可以跟上,但是其调节时间和超调量由于没有80球对应的baseline,也无法知道控制效果的好坏。
从理论上讲,对于最小相位系统,PID通过反复调参一定是可以达到极好的角速度控制要求的(毕竟角速度范围也不大,最快不过200度每秒,大部分情况下都是在120度每秒以内的),只是由于对于小直径的有机玻璃材质的球壳而言,更小的摩擦力导致的更大的超调量会使得PID更为难调一些。所以如果不想在角速度控制上尝试用更高级的算法,PID(顶多加一个前馈)通过反复调参一定可以达到和80cm直径球体一样的性能。
那么使用更高级的算法(MFAC)的意义在哪里呢?有望(注意只是有望)应对未知的海流干扰有更强的自适应性,以及对于不同尺寸不同外壳材质的球也不需要做太久的参数调整,有望(也只是有望)能用于之后的仿生魔鬼鱼的运动控制。最主要的意义当然是前者。当然也可能PID面对海流干扰已经有较强的适应性了也说不准,因为之前我亲眼见到无人船在侧向海流的作用下仍然可以笔直的往前开,底层控制器就是PID,只不过可能多了高级的滤波算法。不管MFAC是否要使用,PID都是要在静水中,在球上达到理想的效果的,然后通过在海流的干扰下的运动情况判断是否有采用更高级算法的必要,如果有,PID还可以作为baseline。所以这是下面要做的一个工作。
在大海之中能够扛得住浪或水流的速度吗?我们连现在能最快开到多少速度都不知道,所以必须引入对速度的测量,这是第二个工作。从目测上看,最快速度是快不到哪里去的,否则非常容易翘起,从而产生空泡。这里我有个问题要问:如果水流速度很快,但是我只是要让球保持静止,此时螺旋桨转的很快,是否会让球体翘起?如果不会翘起,就是一件非常令人激动的事情,这意味着我可以研究靠泊控制。但是我想应该是会的。因为是否翘起,取决于与水流的相对速度,那么如果在急流中,在绝对速度为0时,相对速度应该会很大。那么相对速度的上限是多少?还是要通过速度反馈才能知道。那么靠泊是否还有必要做呢?有,所以靠泊是速度反馈完成后要做的事情,是第五个工作。
如果控制做好了,那么剩下的事情就是使命级和任务级的事情,这些事情是可以在仿真器中进行的,所以构建仿真器是第三个工作
之后引入视觉跟踪,就是第四个工作。
我还想提一个问题:强化学习对于机器人的应用意义在哪里?如果四足机器人使用PID来做运动控制和步态控制,难道不可以吗?
我还想提一个问题:在水下的机器人,没有GPS,怎么做好定位呢?如何依靠声波定位呢?
我还想问一个问题:仿生魔鬼鱼的控制是用什么来做的?
想法
我们现在在追求什么,在追求让机器人在室外环境中运动稳定、可靠,能够识别我们希望它识别的人或者物体,能够跟随之,能够避障,能够在给定的起终点之间往复巡逻,且能识别障碍物并与之保持距离。这个愿景一旦实现,它就和动物没有太大区别,且相比起动物除了无法提供情绪价值,完全可以替代。 这里面如果不涉及到学习我是不相信的。那么学习的是什么?是控制律吗?我觉得不是。从控制回路来说,任务规划级->使命级->行为级->回路级。回路级用传统控制就可以了,或者是MFAC。但是MFAC严格来说不是真正意义上的学习型算法。从行为级开始,就可以考虑引入学习算法。
强化学习
首先是对强化学习的简要介绍以明确定义和特点。下面一段文字来自chatgpt:
强化学习(Reinforcement Learning,RL)是机器学习的一个分支,主要关注如何使智能体(agent)通过与环境的交互来学习做出最优决策或行动。强化学习的核心思想可以概括为“试错学习”和“延迟奖励”。
以下是强化学习的一些主要组成部分:
- 智能体(Agent):执行行动并从环境中接收反馈的实体。
- 环境(Environment):智能体与之交互的外部系统或世界。
- 状态(State):环境在特定时刻的描述。
- 行动(Action):智能体可以采取的具体措施。
- 奖励(Reward):对智能体行动的正面或负面反馈。
- 策略(Policy):定义了智能体在给定状态下采取特定行动的规则或方法。
强化学习的过程大致如下:
- 智能体观察当前环境的状态。
- 根据某种策略或规则,智能体在当前状态下选择一个行动。
- 智能体执行该行动,环境转移到新的状态。
- 环境根据行动的结果提供相应的奖励给智能体。
- 智能体使用这个反馈来更新或改进其策略。
- 这个过程持续迭代,直到达到某种停止条件或达到满意的性能。
目标通常是寻找一种策略,使得智能体从长期来看能够获得最大的累积奖励。强化学习广泛应用于许多领域,如游戏、机器人、自动驾驶、金融优化等。
强化学习对于机器人的应用意义在哪里?如果四足机器人使用PID来做运动控制和步态控制,难道不可以吗?
如果让强化学习解决传统控制的问题,强化学习是没有优势的[参考:]。
以下来自handbook of Robotics:
Consider, for example, the seemingly simple task of picking up an object from a table. To do so, the robot has to decide where to go in order to pick up the object, which hand(s) to use, how to reach for the object, which type of grasp to apply, where to place the gripper, how much grasp force to apply, how much lift force, how to lift the object, where to hold it, and so on.
If programmers have to specify the decisions for every conceivable combination of object and task, the control program for picking up an object becomes very complex. But even this program would in most cases not suffice to generate competent robot behavior, because how the pickup action should be performed depends on the context, too – the state of the object, the task to be performed, the scene that the object is located in. If the object is a glass filled with juice, it has to be held upright and if it is a bottle the robot intends to fill a glass with, it should not grasp the top of the bottle.
If the bottle is to be picked up in the middle of a cluttered scene, then grasping the top of the bottle might be the best choice. If the scene is cluttered and the purpose is filling a glass, then the robot might even have to re-grasp after picking up the object.
看得出来,强化学习在回路“任务规划级->使命级->行为级->回路级”中,更多的侧重于使命级或者使命级到回路级贯通。当然强化学习也可以学习机器人的模型。
Overleaf (LaTex)
生成并排子图
查看以下这段与chatgpt的对话:
https://chat.openai.com/share/e7fbdccd-2847-4dbb-b816-db2b7455c628
如果要生成上下排列的子图,将\hfill更换为\即可
其他
肺是如何吸收空气中的氧气的?
依靠肺泡。肺泡是肺部进行气体交换的场所,吸入的氧气通过肺泡进入到毛细血管的血液中,二氧化碳从毛细血管进入到肺泡。下图可以看到对肺泡的气体交换过程做了描绘。
![肺泡和毛细血管的气体交换图[2]](https://img-blog.csdnimg.cn/f5454eb631b64378a03353fe80a90462.png)
肺泡是由单层细胞构成的,它的外周被同样是单层细胞构成的毛细血管包裹着[3],这样的配合为快速气体交换提供了结构保障。肺泡内的氧气分子和毛细血管内的二氧化碳分子均通过扩散作用[4]分别进入到毛细血管和肺泡当中。扩散作用,即分子从高浓度向低浓度方向(由于受到浓度梯度形成的驱动力)流动的运动现象,这种运动是自发的,不需要人体提供能量。注意是扩散作用而不是渗透作用[5][6],两者有一定区别。
参考:
[1] 图文视频结合,下呼吸系统, visiblebody.com
[2] 默沙东诊疗手册
[3] 肺泡能够进行气体交换的原因,新华网,2018
[4] 扩散作用,wiki
[5] 扩散作用和渗透作用的区别,百度知道,2016
[6] 扩散作用和渗透作用的区别,chatgpt4,2023
鱼鳃是如何吸收氧气的?
鱼鳃和肺的功能一样,都是呼吸器官,鱼鳃中的鳃丝就是肺中的肺泡。当鱼吞入食物时,也将水喝到嘴里,然后食物被咽下,而水就从两侧的鳃流出体外。水中的氧在这一过程中,被鱼鳃内的血管吸收[1]。鱼鳃内部气体交换的原理同样是基于扩散作用[2]。
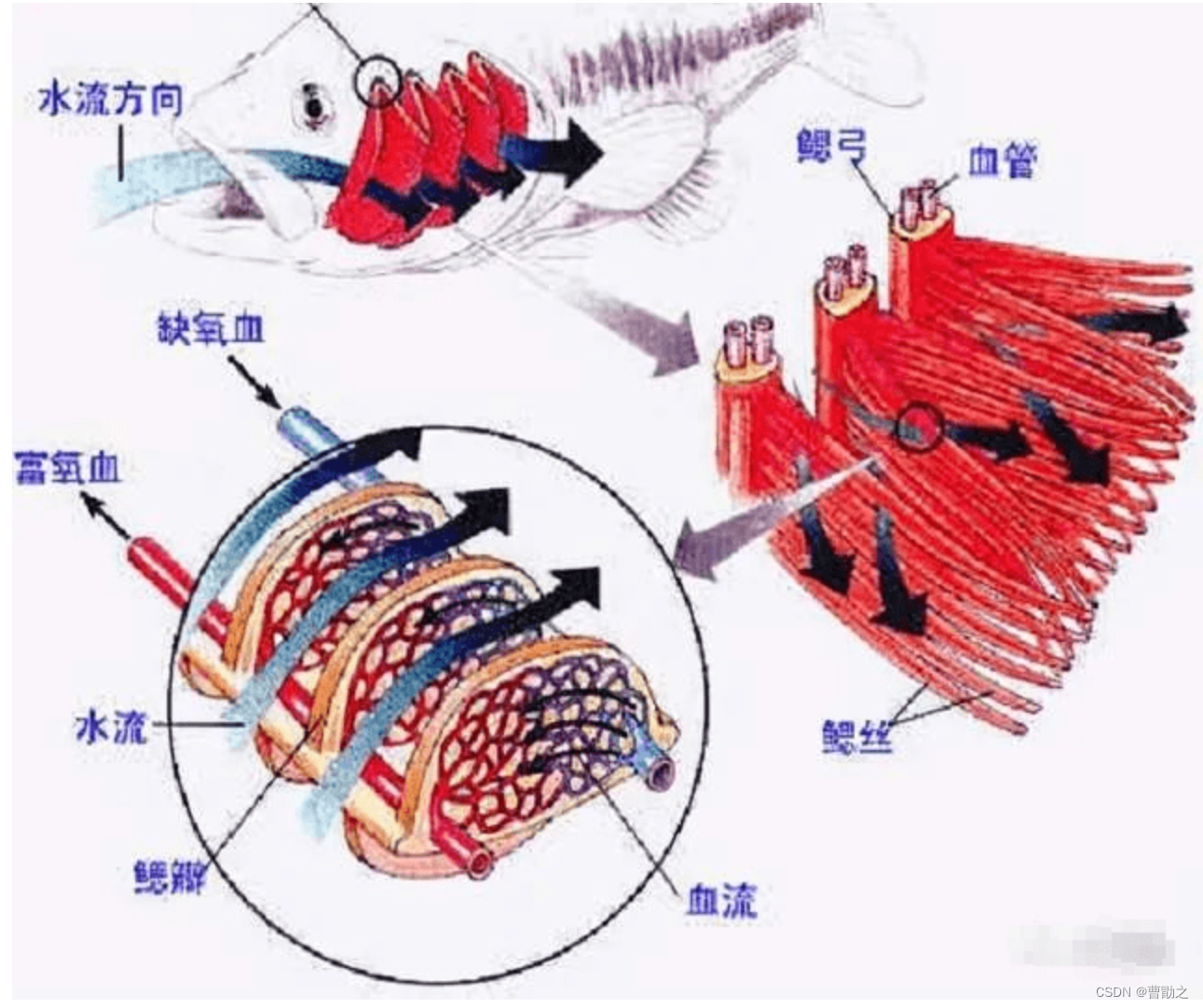
参考:
[1] 鱼鳃结构图及气体交换机理,搜狐,202012
[2] 鱼鳃气体交换原理,chatgpt4, 202308
卵生、胎生和卵胎生
生命的历程:受精卵->胚胎->多细胞生物。
也就是说,胚胎是多细胞生物发育的早期阶段,而受精卵是胚胎的起始阶段。
卵生(对于鸟类或一些爬行类动物可以通俗理解为蛋生),就是体外产卵(产蛋),在卵内的受精卵通过卵黄提供的营养逐渐发育为胚胎[1],对于大多数鱼类,则是雌鱼在体外排卵后(通常会在植物底下或者挖洞作为产卵地点,有些会在开放水域产卵),雄鱼紧随雌鱼,释放精子,与卵细胞结合。这个过程通常非常迅速,形成受精卵以后,有些鱼类会保护受精卵直到孵化,也有很多鱼类在完成受精后就会离开。
参考:
[1] 什么是卵生、胎生和卵胎生, chatgpt4,202308
蝠鲼鱼
蝠鲼鱼(Manta),又叫魔鬼鱼,是卵胎生动物,性情温和,非常聪明,寿命最长可达50年。最大的翼展长达9米,最小的不到1米,最小的蝠鲼鱼可以飞向天空高达4米。大型蝠鲼鱼(如阿氏前口蝠鲼和双吻前口蝠鱝)由于有长达13个的妊娠期,且一次只产一胎,三年怀孕一次,现如今蝠鲼鱼成为了濒危物种。有组织机构专门研究和保护蝠鲼鱼[2][3]。
参考:
[1] 我养了一条蝠鲼鱼叫巨人乔治,youtube,2021
[2] Manta Trust
[3] Mantapacific.org
前馈控制
参考文献:
csdn:前馈控制与反馈控制对比,20220203
bilibili 华南虎小分队
参数辨识的方法
"8"字曲线的参数方程
"8"字曲线其实有很多种,每一种都有自己的名字,每一种的参数方程都不相同。目前亲测过其中一种,也是相对简单的一种:
{ x = 10 ⋅ c o s ( t ) y = 10 ⋅ s i n ( t ) ⋅ c o s ( t ) \left\{ \begin{aligned} &x = 10\cdot cos(t)\\ &y = 10\cdot sin(t)\cdot cos(t) \end{aligned} \right. {x=10⋅cos(t)y=10⋅sin(t)⋅cos(t)

参考文献:
“8字曲线”有没有一个具体的专业名称? 知乎, 20160224
ADRC
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!