KeyError: ‘content-length‘|学习python爬虫遇到的问题
前提:由于只学习了一些有关于python的基础,于是在需要用到有关于爬虫的内容,就想着直接用别人的代码来爬数据
出现的问题来源
首先代码是先参考这位博主的代码
https://blog.csdn.net/ChengYin1124/article/details/118578200?ops_request_misc=&request_id=&biz_id=102&utm_term=%E7%88%AC%E8%99%AB%E5%B0%8F%E5%B7%A5%E5%85%B7&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-2-118578200.142^v73^wechat_v2,201^v4^add_ask,239^v2^insert_chatgpt&spm=1018.2226.3001.4187
但是就出现了如题的代码问题
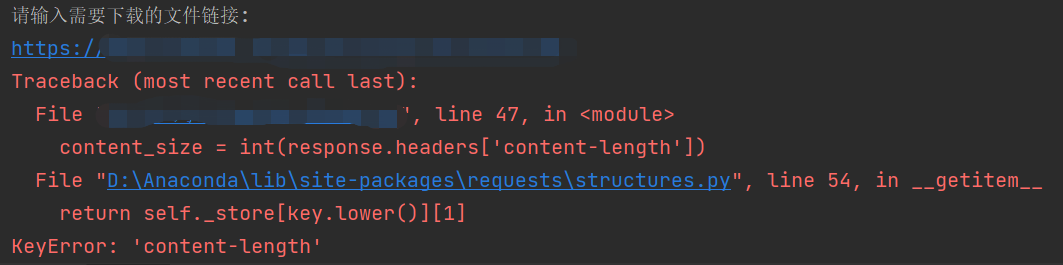
解决问题
①查找了网上很多有关于这个方面的问题都解决不了,例如我加入以下这行代码,也是同样报错了
headers = {"Accept-Encoding": "identity"}②于是我就开始在我所查找的网页中检查network,发现content-length不在响应头response.headers中,而在请求头response.request.headers中,于是我就修改代码,如下所示
content_size = int(response.request.headers['content-length'])并且我还发现我所爬取的网页为post
with closing(requests.post(url,stream=True)) as response:最后就成功啦~果然爬虫这东西基础不牢固出问题都要找半天。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!