PYTHON3.6对中文文本分词、去停用词以及词频统计
一开始设想在相似度计算中针对于《三生三世十里桃花》和《桃花债》之间的相似度计算,但是中途突然有人工智能的阅读报告需要写。
突然脑洞想做个词频统计看看《新一代人工智能规划》中的词频什么的。
用的工具是PYTHON里面的中文JIEBA分词工具。
中文文本分词中先参考了官方给出的示例,官方给出的示例主要是对一条文本进行全分词和精确分词。
import jieba
seg_list = jieba.cut("我来到北京清华大学,感到非常开心", cut_all=True)
print("Full Mode:"+"/".join(seg_list)) # 全模式seg_list = jieba.cut("我来到北京清华大学,感到非常开心", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式seg_list = jieba.cut("我来到北京清华大学,感到非常开心")
print("/ ".join(seg_list)) # 默认精确模式seg_list = jieba.cut_for_search("烟花从正面看,还是从侧面看呢?") # 搜索引擎模式
print("/ ".join(seg_list))得到的结果如下:
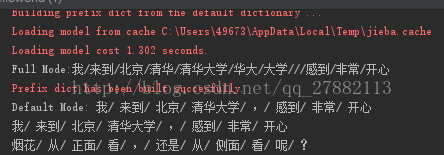
可以注意到全模式会对已经分词出来的词再进行分词,一般情况下使用精确模式(个人感觉)。
中文文本的预处理过程可以分为分词->去停用词(包含空格、回车、标点符号等都算作停用词)->词频统计 在没有仔细了解的情况下,我误以为结巴分词里面含有停用词表,然后查了一下资料发现根本就不是这个样子:( 在网上找了一下去停用词的方法,发现是把分词的结果与停用词表进行比较,后进行删除。 在相关领域哈工大的停用词表比较有名的样子。所以选择了哈工大扩展停用词表。

在完成操作后把str结果写入目标文件中,再读取删除好停用词的文件后进行wordcount操作。使用到了dict字典类型来生成结果。
from collections import Counter
import jieba# jieba.load_userdict('userdict.txt')
# 创建停用词list
def stopwordslist(filepath):stopwords = [line.strip() for line in open(filepath, 'r').readlines()]return stopwords# 对句子进行分词
def seg_sentence(sentence):sentence_seged = jieba.cut(sentence.strip())stopwords = stopwordslist('filename') # 这里加载停用词的路径outstr = ''for word in sentence_seged:if word not in stopwords:if word != '\t':outstr += wordoutstr += " "return outstrinputs = open('filename', 'r') #加载要处理的文件的路径
outputs = open('filename', 'w') #加载处理后的文件路径
for line in inputs:line_seg = seg_sentence(line) # 这里的返回值是字符串outputs.write(line_seg)
outputs.close()
inputs.close()
# WordCount
with open('filename', 'r') as fr: #读入已经去除停用词的文件data = jieba.cut(fr.read())
data = dict(Counter(data))with open('filename', 'w') as fw: #读入存储wordcount的文件路径for k,v in data.items():fw.write('%s,%d\n' % (k, v))
后来和实验室的大哥讨论了一下,使用with open比使用for可能更好一些,因为for循环完成之后还需要关闭文件:)with open就更加方便。
PYTHON果然很方便啊,下面随便贴一下得出来的结果,酷的不行。同时需要注意到的是PYTHON2.7和PYTHON3.6还是有一些区别的,这里我用到的是PYTHON3.6,使用2.7的朋友们可能需要去参考别的资料啦。
还有需要注意的是PYTHON对于空格之类的要求近乎变态,详细的还不太了解,需要继续了解一下。
这里是处理之前的文件:

经过去停用词后所得到的文件:

最后所得到的wordcount文件,格式是(词,出现的频数):

下一节大概会介绍简单粗暴的词云生成方法。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!