paddleOCR SystemError: (Fatal) Blocking queue is killed because the data reader raises an exception.
百度了很久,看了很多博主的都没有解决问题/(ㄒoㄒ)/~~
最后请教大佬,帮我解决了
第一可能是文件编码问题
问题1:UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘\ufeff’ in position 52: illegal multibyte sequence
原因:由于本地系统是Win10中的cmd,默认GBK的编码,所以需要先将上述的Unicode的文本串先编码为GBK,然后再在cmd中显示出来,然后由于文本串中包含一些GBK中无法显示的字符,导致此时提示“’gbk’ codec can’t encode”的错误的。
解决方法:使用Nopad++转换为utf-8
第二 大多数label文件是以“,”分割的
问题2:使用IDC15数据时,出现list of range,经分析,它是使用’,’逗号来作分割符,但是paddleocr是要\t作为分割符
解决方法:我们需要找到simple_dataset.py 把’,’换成\t,label文件里面最好也手动替换一下
总的来说就是要做到一致,并不一定要求\t
最后就运行成功啦!!!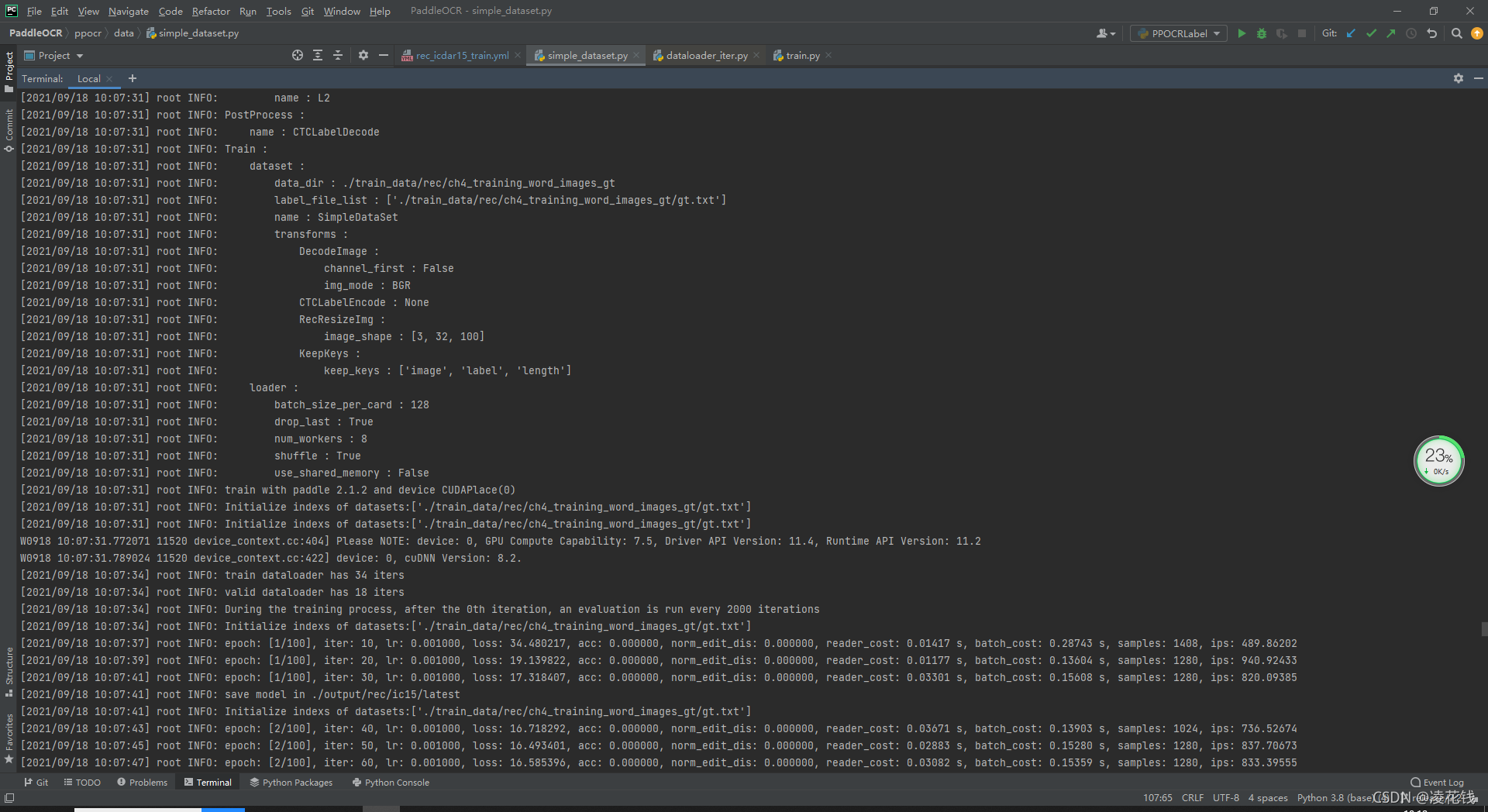
这里如果还是没有解决的话,推荐这位博主的
传送门
笔记
原配置文件中的参数
学习率0.0005
epoch 72
训练的效果并不是特别好 acc 0.412
这里选择增大学习率至0.001 epoch 100 acc 0.912
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!