小白学python(豆瓣爬虫)
小白学python(豆瓣爬虫)
这是我之前跟着教程做的一个小爬虫,爬取豆瓣top250影片资料。其实爬虫更多的是对库函数,html,正则等等知识的应用,像我这样只知皮毛是远远不够的。我暂且将代码贴出,以后更新爬虫有关知识。
from bs4 import BeautifulSoup
import re
import urllib.request,urllib.error
import xlwtdef main():#初始网址baseurl = "https://movie.douban.com/top250?start="datalist =getData(baseurl)#保存路径savepath = "douban250.xls"#保存saveData(datalist,savepath)#影片链接规则
findLink = re.compile(r'')#创建正则表达式规则
#影片图片链接规则
findImgSic = re.compile(r',re.S) #re.S 让换行符包含在字符串中
#影片片名
findTitle = re.compile(r'(.*)')
#影片评分
findRating = re.compile(r'')
#评价人数
findJudge = re.compile(r'(\d*)')
#找到概况
findIng = re.compile(r'"inq">(.*)')
#找到相关内容
findBd = re.compile(r'(.*?)
',re.S)#爬取网址
def getData(baseurl):datalist = []for i in range(0,10): #调用获取网页的函数10次url = baseurl + str(i*25)html = askURL(url) #保存获取的网页信息#逐一解析soup = BeautifulSoup(html,"html.parser")for item in soup.find_all('div',class_="item"): #查找字符串data = [] #保存一部电影的所有信息item = str(item)#print(item)Link = re.findall(findLink,item)[0] #查找影片链接data.append(Link)imgSrc = re.findall(findImgSic,item)[0] data.append(imgSrc) #匹配添加图片titles = re.findall(findTitle,item) if(len(titles)==2):ctitle = titles[0]data.append(ctitle)otitle = titles[1].replace("/","") data.append(otitle)else :data.append(titles[0])data.append(' ') #外国名留空rating =re.findall(findRating,item)data.append(rating)judgeNum = re.findall(findJudge,item)data.append(judgeNum)inq = re.findall(findIng,item)if len(inq) !=0:inq = inq[0].replace(",","")data.append(inq)else :data.append(" ")bd = re.findall(findBd,item)[0]bd = re.sub('br(\s+)?/>(\s+)?'," ",bd)bd = re.sub('/'," ",bd)data.append(bd.strip())datalist.append(data) #把处理好的一部电影信息存储#print(datalist)return datalistdef saveData(datalist,savepath):book = xlwt.Workbook(encoding="utf-8")sheet =book.add_sheet('douban250',cell_overwrite_ok=True)col = ('Link to film details','Image links','Chinese Name of Movie','Foreign Name of Movie','score','Judgingnum','General situation ','The relevant information')for i in range(0,8):sheet.write(0,i,col[i])for i in range(0,250):print("%d条"%i)data = datalist[i]for j in range(0,8):sheet.write(i+1,j,data[j])book.save('student.xls')
def askURL(url):head = {"User-Agent":" Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400"}request = urllib.request.Request(url,headers = head)html = ""try:response = urllib.request.urlopen(request)html = response.read().decode("utf-8")#print(html)except urllib.error.URLError as e:if hasattr(e,"code"):print(e.code)if hasattr(e,"reason"):print(e.reason)return htmlif __name__ == "__main__":main() 运行截图:
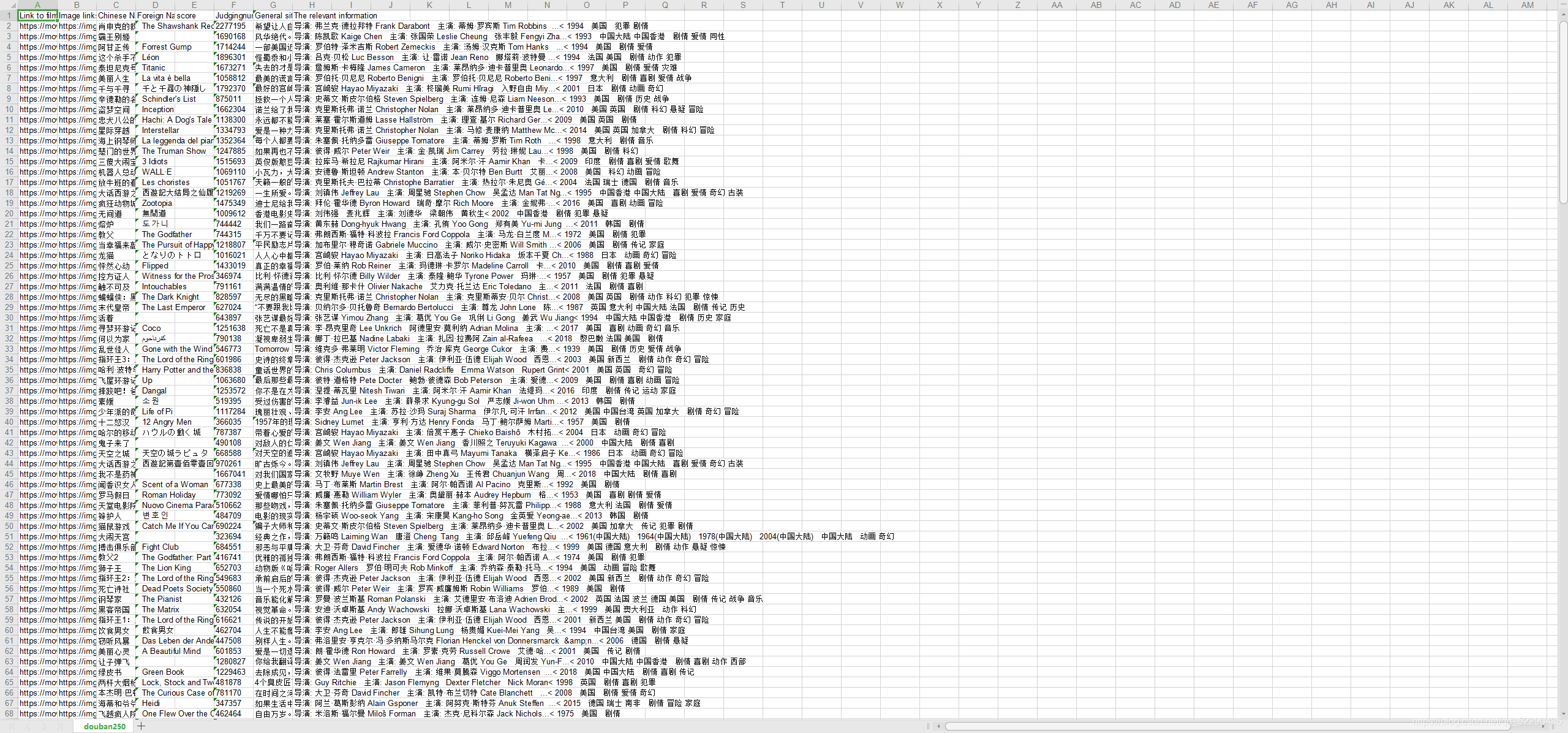
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!