蔬菜购物网站设计【协同过滤的推荐算法】
研究目的:
本次研究的目的是开发一种基于用户行为和物品关联的推荐算法,用于提供蔬菜购物网站的个性化推荐服务。通过分析用户的购买历史、评价、收藏等信息,找到相似用户或相似物品,从而向用户推荐符合其兴趣和需求的蔬菜产品。 旨在提供用户方便快捷地购买蔬菜的在线平台,提供新鲜且优质的蔬菜产品,满足用户对健康饮食的需求
开发背景:本次研究的目的是开发一款蔬菜购物网站,旨在提供用户方便快捷地购买蔬菜的在线平台,提供新鲜且优质的蔬菜产品,满足用户对健康饮食的需求。
个性化推荐已经在电子商务领域得到广泛应用,可以提升用户的购物体验和购买满意度。在蔬菜购物网站中,通过利用用户行为和物品关联的推荐算法,可以更准确地推荐蔬菜产品,提高用户满意度和购买转化率。
国外研究现状分析:
本次研究的目的是开发一款蔬菜购物网站,旨在提供用户方便快捷地购买蔬菜的在线平台,提供新鲜且优质的蔬菜产品,满足用户对健康饮食的需求,国外已经有许多研究和应用个性化推荐算法的案例。像Amazon、Netflix等知名电商平台和影视平台,都利用用户行为数据和物品关联信息,实现了精准的个性化推荐服务。
国内研究现状分析:
国内也有一些电商平台开始运用个性化推荐算法,但在蔬菜购物领域的应用还比较有限。目前,一些农产品电商平台已经开始尝试蔬菜的个性化推荐,但仍有进一步的改进空间。
需求分析:
根据用户的需求,我们进行如下需求分析:
用户可以方便地浏览各类蔬菜产品,并查看产品的详细信息,如价格、产地、规格等。
用户可以将心仪的蔬菜添加到购物车中,并方便地管理购物车内的商品。
网站需要提供多种支付方式,并确保支付安全性。
用户可以选择适合自己的配送方式和时间,保证蔬菜的新鲜度和配送的及时性。
网站需要提供用户评价功能,供用户了解其他用户的购买评价,从而做出更好的购物决策。
网站需要有专业的客服团队,能够及时回答用户的疑问和解决用户遇到的问题。
方案分析:
基于以上需求,我们可以设计一个蔬菜购物网站的方案:
网站首页展示推荐蔬菜产品和特价促销信息,吸引用户的注意力。
提供蔬菜产品分类,方便用户按照自己的需要浏览和筛选产品。
点击进入产品详情页面,展示蔬菜的详细信息,并提供加入购物车和立即购买的选项。
购物车页面展示用户已选购的蔬菜产品,允许用户修改数量、删除产品等操作。
提供多种支付方式,如支付宝、微信支付等,并确保支付过程的安全性和便捷性。
用户可以选择适合自己的配送方式和时间,网站将保证产品的新鲜度和配送的及时性。
提供用户评价功能,让用户可以对购买的产品进行评价和分享,帮助其他用户做出购买决策。
设置在线客服系统,让用户可以随时与客服进行沟通,解决遇到的问题和疑问。
实现基于用户行为和物品关联的个性化推荐算法需要经过以下步骤:
1. 数据收集和预处理:
收集用户的购买历史、评价、收藏等行为数据。
收集蔬菜产品的信息,如蔬菜ID、名称、描述、特征等。
对收集到的数据进行预处理,如清洗、去重、填充缺失值等。
2. 建立用户行为模型:
根据用户行为数据,构建用户行为模型,描述用户的偏好和兴趣。常用的模型包括用户物品关联矩阵、用户特征向量等。
3. 建立物品关联模型:
分析蔬菜产品之间的关联关系。可以基于用户评价、购买行为等计算蔬菜产品之间的相似度或相关度。
4. 计算相似用户或相似物品:
利用用户行为模型和物品关联模型,计算用户之间的相似度或蔬菜产品之间的相似度。
常用的相似度计算方法包括余弦相似度、欧氏距离、皮尔逊相关系数等。
5. 个性化推荐:
根据用户的相似度计算结果和用户行为模型,为用户推荐与其兴趣和需求相似的蔬菜产品。
常用的推荐算法包括基于内容的推荐、协同过滤、深度学习推荐等。
6. 动态调整推荐结果:
根据用户实时行为和反馈信息,动态调整推荐结果,提高推荐准确度和用户满意度。
可以考虑结合在线学习、A/B测试等方法进行实时调优。
表名:Recommendations
字段:
recommendation_id (推荐记录ID):唯一标识每个推荐记录的ID,可以使用自增主键或其他方式生成。
user_id (用户ID):唯一标识用户的ID,用于关联用户信息。
item_id (物品ID):唯一标识推荐给用户的物品的ID,用于关联物品信息。
similarity_score (相似度分数):表示用户与推荐物品的相似度分数。
created_time (创建时间):记录推荐记录的创建时间,使用日期时间类型存储。
索引:可以根据需要创建以下索引来提高查询性能:
user_id 索引:加快根据用户ID查询推荐记录的速度。
created_time 索引:加快按创建时间进行排序或查询的速度。
建表语句(使用MySQL语法):
CREATE TABLE Recommendations (recommendation_id INT PRIMARY KEY AUTO_INCREMENT,user_id INT NOT NULL,item_id INT NOT NULL,similarity_score FLOAT NOT NULL,created_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,INDEX user_id_index (user_id),INDEX created_time_index (created_time)
);用户之间的相似度计算(基于行为数据):
余弦相似度(Cosine Similarity):
公式1:
其中,u 和 v 分别是用户 u 和 v 的行为向量,|u∣ 和 |v∣ 分别表示u 和v 的模
皮尔逊相似度(Pearson Correlation):
公式2:
其中,u 和 v 分别是用户 u 和 v 的行为向量,u 和 v 分别是用户 u 和 v 的平均行为向量,∣u∣ 和 ∣v∣ 分别表示u 和v 的模
基于相似用户的个性化推荐:
给用户u推荐物品i的得分(基于相似度和用户行为数据):
公式3: 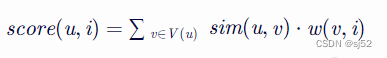
其中,V(u) 表示和用户u相似的所有用户的集合,sim(u,v) 表示用户u和用户v之间的相似度,w(v,i) 表示用户v对物品i的兴趣得分。
推荐列表中的前N个物品:
公式4: 对每个用户u,计算它对所有物品i的得分score(u,i),然后按得分从高到低排序,取前N个物品推荐给用户u。
代码:
import mysql.connector
import numpy as np
from sklearn.metrics.pairwise import cosine_similaritydef personalized_recommendation(user_id, k):# 连接数据库conn = mysql.connector.connect(host="localhost",user="root",password="root",database="database")# 创建游标cursor = conn.cursor()# 查询用户的行为矩阵query = "SELECT * FROM UserBehavior WHERE user_id = %s"cursor.execute(query, (user_id,))user_behavior = cursor.fetchone()# 查询所有用户的行为矩阵query = "SELECT * FROM UserBehavior"cursor.execute(query)all_user_behavior = cursor.fetchall()# 构建用户行为矩阵user_behavior_matrix = np.array(all_user_behavior[:, 1:])user_vector = np.array(user_behavior[1:])# 计算用户之间的相似度(余弦相似度)user_similarity_matrix = cosine_similarity(user_behavior_matrix, [user_vector])# 找出与用户相似度最高的Top K个用户top_k_users = np.argsort(user_similarity_matrix[:, 0])[::-1][:k]# 查询推荐的物品IDquery = "SELECT item_id FROM Recommendations WHERE user_id = %s"cursor.execute(query, (user_id,))recommend_items = cursor.fetchall()already_recommended_items = set(item[0] for item in recommend_items)# 构建推荐物品集合recommendations = set()for similar_user in top_k_users:# 查询相似用户推荐的物品IDquery = "SELECT item_id FROM Recommendations WHERE user_id = %s"cursor.execute(query, (similar_user,))similar_user_recommendations = cursor.fetchall()# 找出与相似用户行为差异且未曾推荐给用户的物品IDnew_items = set(item[0] for item in similar_user_recommendations) - already_recommended_itemsrecommendations.update(new_items)# 关闭游标和数据库连接cursor.close()conn.close()return recommendations# 示例调用
user_id = 1
k = 5 # Top K相似用户
recommendations = personalized_recommendation(user_id, k)print("推荐给用户", user_id, "的物品:", recommendations)
先查询用户的行为数据,并将其与数据库中所有用户的行为数据一起构建行为矩阵。然后,根据用户之间的相似度找出相似用户(Top K),并查询这些相似用户推荐过的物品。最后,根据用户未曾推荐过的物品进行个性化推荐。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!