三维点云弱监督
1.论文
https://openaccess.thecvf.com/content/CVPR2021/papers/Liu_One_Thing_One_Click_A_Self-Training_Approach_for_Weakly_Supervised_CVPR_2021_paper.pdf
https://arxiv.org/abs/2202.10705 (PointMatch)
https://arxiv.org/abs/2207.09084 (DAT)
2.代码
(PointGroup)
(One Thing One Click)
按照readme安装编译:
# (1) conda创建虚拟环境
conda activate One-Thing-One-Click
# 下载代码
git clone https://github.com/liuzhengzhe/One-Thing-One-Click.git
# (2) 安装依赖库
'''
cd One-Thing-One-Click
pip install -r requirements.txt
conda install -c bioconda google-sparsehashconda install libboost
conda install -c daleydeng gcc-5 # need gcc-5.4 for sparseconv
'''
Add the $INCLUDE_PATH$ that contains boost in lib/spconv/CMakeLists.txt. (Not necessary # if it could be found.)include_directories($INCLUDE_PATH$)
# (3) Compile the spconv library.
'''
cd lib/spconv
python setup.py bdist_wheel
'''
Run cd dist and use pip to install the generated .whl file.
(4) Compile the pointgroup_ops library.'''
cd lib/pointgroup_ops
python setup.py develop
'''
# If any header files could not be found, run the following commands.
'''
python setup.py build_ext --include-dirs=$INCLUDE_PATH$
python setup.py develop
'''
$INCLUDE_PATH$ is the path to the folder containing the header files that could not be found.(5) Data Preparation
Download the ScanNet v2 dataset.
Put the data in the corresponding folders.
Put the file scannetv2-labels.combined.tsv in the data/ folder.
Change the path in prepare_data_otoc.py Line 20.
'''
cd data/
python prepare_data_otoc.py
'''
Split the generated files into the data/train_weakly and data/val_weakly folders according to the ScanNet v2 train/val split.
Pretrained Model
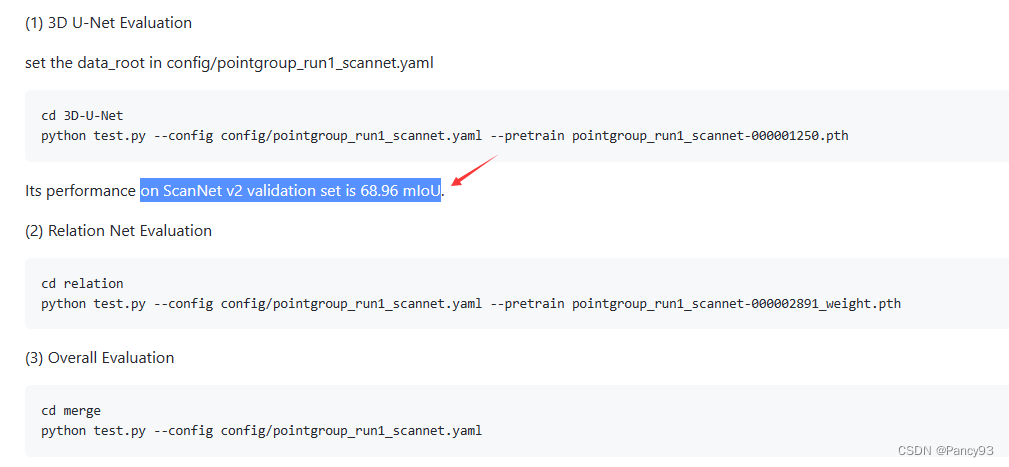
We provide a pretrained model trained on ScanNet v2 dataset. Download it here. Its performance on ScanNet v2 validation set is 71.94 mIoU.'''(6) Inference and Evaluation(1) 3D U-Net Evaluation
# set the data_root in config/pointgroup_run1_scannet.yaml
'''
cd 3D-U-Net
python test.py --config config/pointgroup_run1_scannet.yaml --pretrain pointgroup_run1_scannet-000001250.pth
'''
Its performance on ScanNet v2 validation set is 68.96 mIoU.(2) Relation Net Evaluation
'''
cd relation
python test.py --config config/pointgroup_run1_scannet.yaml --pretrain pointgroup_run1_scannet-000002891_weight.pth
'''(3) Overall Evaluation
'''
cd merge
python test.py --config config/pointgroup_run1_scannet.yaml
'''Self Training
1) Train 3D U-Netset the data_root/dataset in config/pointgroup_run1_scannet.yaml
'''
cd 3D-U-Net
CUDA_VISIBLE_DEVICES=0 python train.py --config config/pointgroup_run1_scannet.yaml
''' 2) Generate features and predictions of 3D U-Net
'''
CUDA_VISIBLE_DEVICES=0 python test_train.py --config config/pointgroup_run1_scannet.yaml --pretrain $PATH_TO_THE_MODEL$.pth
'''3) Train Relation Net
set the data_root/dataset in config/pointgroup_run1_scannet.yaml'''
cd relation
CUDA_VISIBLE_DEVICES=0 python train.py --config config/pointgroup_run1_scannet.yaml
'''4) Generate features and predictions of Relation Net
'''
CUDA_VISIBLE_DEVICES=0 python test_train.py --config config/pointgroup_run1_scannet.yaml --pretrain $PATH_TO_THE_MODEL$_weight.pth
'''5) Merge the Results via Graph Propagation
'''
cd merge
CUDA_VISIBLE_DEVICES=0 python test_train.py --config config/pointgroup_run1_scannet.yaml
'''6) Repeat from (1) to (5) for self-training for 3 to 5 times遇到问题1:python setup.py bdist_wheel报错No rule to make target '/usr/local/cuda/lib64/libnvToolsExt.so', needed by 'src/spconv/CMakeFiles/spconv.dir/cmake_device_link.o'. Stop.
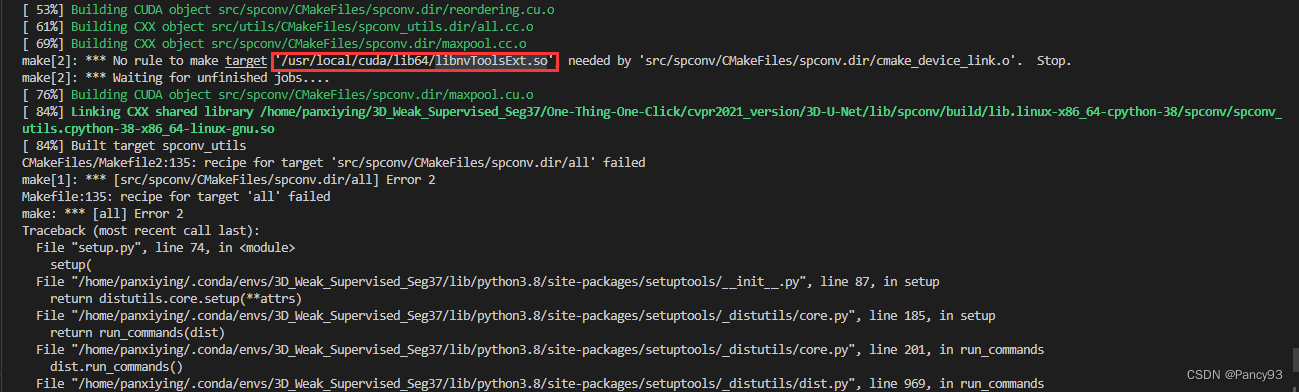
解决:cuda有多个路径,得指定版本
sudo ln -s /usr/local/cuda-10.1 /usr/local/cuda
遇到问题:note: candidate: constexpr torch::jit::RegisterOperators::RegisterOperators(torch::jit::RegisterOperators&&)
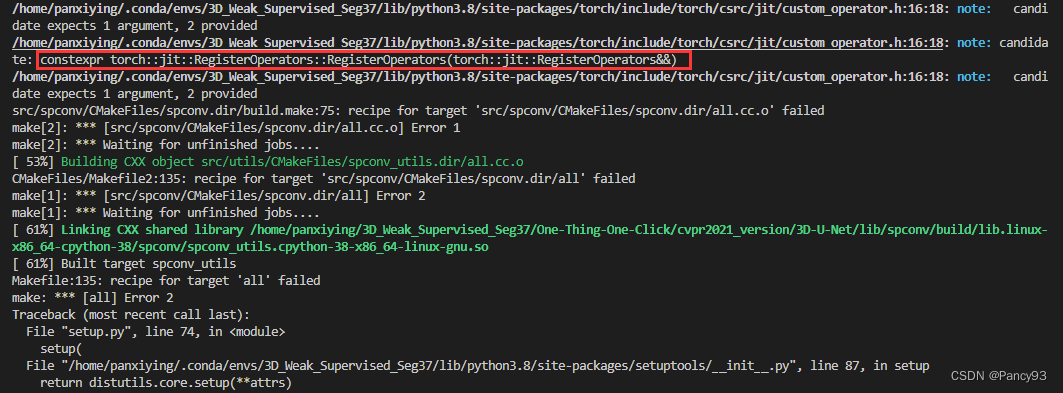
解决:
torch::jit::RegisterOperators("spconv::get_indice_pairs_2d", &spconv::getIndicePair
)去掉jit
![]()
遇到问题2:python setup.py bdist_wheel报错 /usr/bin/ld: cannot find -lCUDA_cublas_LIBRARY-NOTFOUND
解决:在One-Thing-One-Click/cvpr2021_version/3D-U-Net/lib/spconv/CMakeLists.txt添加cublas库所在路径
set(CUDA_CUDART /usr/lib/x86_64-linux-gnu/)
set(CUDA_CUBLAS /usr/lib/x86_64-linux-gnu/)
set(CUDA_cublas_LIBRARY /usr/local/cuda/lib64/)

成功结果:

利用已训练好的模型对val进行测试:
python test.py --config ./config/pointgroup_run1_scannet.yaml --pretrain ./config/pointgroup_run1_scannet-000001250.pth问题4:运行test.py报错
ImportError: cannot import name 'spconv_utils' from partially initialized module 'spconv' (most likely due to a circular import) (/home/xxx/3D_Weak_Supervised_Seg37/One-Thing-One-Click/cvpr2021_version/3D-U-Net/spconv/__init__.py)
解决:One-Thing-One-Click/cvpr2021_version/3D-U-Net/spconv/utils/__init__.py按如下修改

问题5:运行test.py报错
OSError: /home/xxx/3D_Weak_Supervised_Seg37/One-Thing-One-Click/cvpr2021_version/3D-U-Net/spconv/libspconv.so: cannot open shared object file: No such file or directory
解决:
cp -r ./lib/spconv/build/lib.linux-x86_64-cpython-38/spconv/libspconv.so /home/xxx/3D_Weak_Supervised_Seg37/One-Thing-One-Click/cvpr2021_version/3D-U-Net/spconv/
结果成功:生成对应的txt
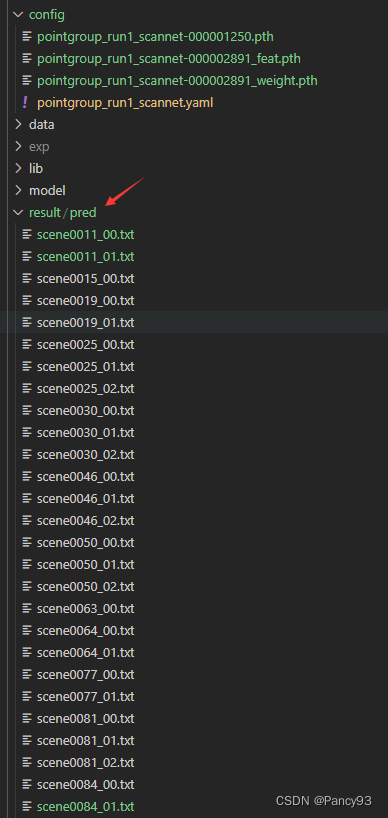
困惑:on ScanNet v2 validation set is 68.96 mIoU,这个值是怎么算到的?
(DAT)
安装编译: DAT/INSTALL.md at main · wu-zhonghua/DAT (github.com)

遇到问题1:系统库版本过低
![]()
解决:
重新设置lib库路径为/home/panxiying/.conda/envs/3D_Weak_Supervised_Seg37/lib/
# 查看当前系统中其它的同类型文件,找到一个版本比较高的
locate libstdc++.so.6*
# 版本比较多,就选了一个版本较高的,我这里是3.4.29,使用之前的指令看看其是否包含需要的版本:
strings /home/xxx/anaconda3/envs/tf2/lib/libstdc++.so.6.0.29 | grep GLIBCXX
# 可以看到有需要的版本,接下来就是建立新的链接到这个文件上
# 复制
sudo cp /home/xxx/anaconda3/envs/tf2/lib/libstdc++.so.6.0.29 /usr/lib/x86_64-linux-gnu/
# 删除之前链接
sudo rm /usr/lib/x86_64-linux-gnu/libstdc++.so.6
# 创建新的链接
sudo ln -s /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.29 /usr/lib/x86_64-linux-gnu/libstdc++.so.6
遇到问题2:scikit-learn版本过高,No module named 'sklearn.neighbors._dist_metrics'
解决:conda install scikit-learn==0.24.2 安装低版本scikit-learn
nohup防止ssh断连,进程停止,保留运行日志
# 在 train_S3DIS.py 第199行指定GPU
nohup python -u train_S3DIS.py >train_S3DIS.log 2>&1 &# 查看日志
tail -f train_S3DIS.log
3. PointTransformerV2
https://github.com/Gofinge/PointTransformerV2 (先根据github的readme安装编译好)
# 数据预处理
python pcr/datasets/preprocessing/scannet/preprocess_scannet.py --dataset_root /home/panxiying/data/scannetv2 --output_root /home/panxiying/data/scannetv2_processedpython pcr/datasets/preprocessing/s3dis/preprocess_s3dis.py --dataset_root /home/panxiying/data/s3dis --output_root /home/panxiying/data/s3dis_processed# 指定GPU,一般print(torch.cuda.device_count())=2
export CUDA_VISIBLE_DEVICES='1,2'
python
import torch
print(torch.cuda.device_count())# nohup 防止因网络出现断连,重定向不输出日志
nohup 命令 1>/dev/null 2>&1 &# 训练数据集scannet 如果想要resume继续跑,命令后面加-r true 记住要同步修改config.py里面的batch size
nohup sh scripts/train.sh -p python -d scannet -c semseg-ptv2m2-0-base -n semseg-ptv2m2-0-base >train_sh_scannet.log 2>&1 &# 训练数据集s3dis 如果想要resume继续跑,命令后面加-r true
nohup sh scripts/train.sh -p python -d s3dis -c semseg-ptv2m2-0-base -n semseg-ptv2m2-0-base >train_sh_s3dis.log 2>&1 &# 杀死进程
fuser -v /dev/nvidia* |awk '{for(i=1;i<=NF;i++)print "kill -9 " $i;}' | sh# 测试scannet
nohup sh scripts/test.sh -p python -d scannet -n semseg-ptv2m2-0-base -w model_best 1>/dev/null 2>&1 &# 测试s3dis
nohup sh scripts/test.sh -p python -d s3dis -n semseg-ptv2m2-0-base -w model_best 1>/dev/null 2>&1 &debug vscode参数
1)数据预处理
python pcr/datasets/preprocessing/scannet/preprocess_scannet.py --dataset_root /home/panxiying/data/scannetv2 --output_root /home/panxiying/data/scannetv2_processed
"args": ["--dataset_root","/home/panxiying/data/Stanford3dDataset_v1.2_Aligned_Version","--output_root","/home/panxiying/data/s3dis_processed_otoc_random_one"]2)训练
python tools/train.py --config-file configs/s3dis/semseg-ptv2m2-0-base.py --num-gpus 4 --options save_path=exp/s3dis/semseg-ptv2m2-0-base
py文件添加
sys.path.append('/home/panxiying/3D_Weak_Supervised_Seg37/PointTransformerV2/')
os.environ["CUDA_VISIBLE_DEVICES"]="2,3,4,5"
"args": ["--config-file","/home/panxiying/3D_Weak_Supervised_Seg37/PointTransformerV2/configs/s3dis/semseg-ptv2m2-0-base.py","--num-gpus","4","--options","save_path=/home/panxiying/3D_Weak_Supervised_Seg37/PointTransformerV2/exp/s3dis/semseg-ptv2m2-0-base"]3)测试
py文件添加
sys.path.append('/home/panxiying/3D_Weak_Supervised_Seg37/PointTransformerV2/')
os.environ["CUDA_VISIBLE_DEVICES"]="2,3,4,5"
python tools/test.py --config-file configs/s3dis/semseg-ptv2m2-0-base.py --options save_path=/home/panxiying/3D_Weak_Supervised_Seg37/PointTransformerV2/exp/s3dis/semseg-ptv2m2-0-base weight=/home/panxiying/3D_Weak_Supervised_Seg37/PointTransformerV2/exp/s3dis/semseg-ptv2m2-0-base/model/model_best.pth
{// 使用 IntelliSense 了解相关属性。 // 悬停以查看现有属性的描述。// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387"version": "0.2.0","configurations": [{"name": "Python: Current File","type": "python","request": "launch","program": "${file}","console": "integratedTerminal","justMyCode": true,"args": ["--config-file","/home/panxiying/3D_Weak_Supervised_Seg37/PointTransformerV2/configs/s3dis/semseg-ptv2m2-0-base.py","--options","save_path=/home/panxiying/3D_Weak_Supervised_Seg37/PointTransformerV2/exp/s3dis/semseg-ptv2m2-0-base","weight=/home/panxiying/3D_Weak_Supervised_Seg37/PointTransformerV2/exp/s3dis/semseg-ptv2m2-0-base/model/model_best.pth"]}]
}遇到报错如下:显卡内存不够
(3D_Weak_Supervised_Seg37) panxiying@ubuntu:~/3D_Weak_Supervised_Seg37/PointTransformerV2$ tail -f train_sh_scannet.log
[2023-03-28 06:31:11,712 INFO defaults.py line 427 73464] Num params: 11323948
[2023-03-28 06:31:11,877 INFO defaults.py line 174 73464] => Building writer ...
[2023-03-28 06:31:11,879 INFO defaults.py line 176 73464] => Building train dataset & dataloader ...
[2023-03-28 06:31:11,886 INFO scannet.py line 48 73464] Totally 1201 x 9 samples in train set.
[2023-03-28 06:31:11,886 INFO defaults.py line 178 73464] => Building val dataset & dataloader ...
[2023-03-28 06:31:11,888 INFO scannet.py line 48 73464] Totally 312 x 1 samples in val set.
[2023-03-28 06:31:11,889 INFO defaults.py line 180 73464] => Building criteria, optimize, scheduler, scaler(amp) ...
[2023-03-28 06:31:11,892 INFO defaults.py line 185 73464] => Checking load & resume ...
[2023-03-28 06:31:11,892 INFO defaults.py line 512 73464] No weight found at: None
[2023-03-28 06:31:11,893 INFO defaults.py line 191 73464] >>>>>>>>>>>>>>>> Start Training >>>>>>>>>>>>>>>>
Traceback (most recent call last):File "exp/scannet/semseg-ptv2m2-0-base/code/tools/train.py", line 34, in main()
RuntimeError: CUDA out of memory. Tried to allocate 546.00 MiB (GPU 0; 9.78 GiB total capacity; 6.78 GiB already allocated; 189.44 MiB free; 7.61 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF/home/panxiying/anaconda3/envs/3D_Weak_Supervised_Seg37/lib/python3.8/multiprocessing/resource_tracker.py:216: UserWarning: resource_tracker: There appear to be 56 leaked semaphore objects to clean up at shutdownwarnings.warn('resource_tracker: There appear to be %d ' 修改:batch size太大, 显卡至少要满足4张显卡,每张24G
PointTransformerV2/configs/scannet/semseg-ptv2m2-0-base.py
# 第5行
batch_size = 12
# 第51行
data_root = "/home/panxiying/data/scannet"结果:
4.数据集S3DIS和ScanNetv2
scannet数据集:
一共1513个采集场景数据(每个场景中点云数量都不一样,如果要用到端到端可能需要采样,使每一个场景的点都相同),共21个类别的对象,其中,1201个场景用于训练,312个场景用于测试,有四个评测任务:3D语义分割、3D实例分割、2D语义分割和2D实例分割。
如果去官网下载,要填一个TOS协议,然后发邮件过去,会得到python脚本。
类似下面这样,脚本放在github里保存。
#!/usr/bin/env python
# Downloads ScanNet public data release
# Run with ./download-scannet.py (or python download-scannet.py on Windows)
# -*- coding: utf-8 -*-
import argparse
import os
import urllib.request
import tempfileimport ssl
ssl._create_default_https_context = ssl._create_unverified_contextBASE_URL = 'http://kaldir.vc.in.tum.de/scannet/'
TOS_URL = BASE_URL + 'ScanNet_TOS.pdf'
FILETYPES = ['.aggregation.json', '.sens', '.txt', '_vh_clean.ply', '_vh_clean_2.0.010000.segs.json', '_vh_clean_2.ply', '_vh_clean.segs.json', '_vh_clean.aggregation.json', '_vh_clean_2.labels.ply', '_2d-instance.zip', '_2d-instance-filt.zip', '_2d-label.zip', '_2d-label-filt.zip']
FILETYPES_TEST = ['.sens', '.txt', '_vh_clean.ply', '_vh_clean_2.ply']
PREPROCESSED_FRAMES_FILE = ['scannet_frames_25k.zip', '5.6GB']
TEST_FRAMES_FILE = ['scannet_frames_test.zip', '610MB']
LABEL_MAP_FILES = ['scannetv2-labels.combined.tsv', 'scannet-labels.combined.tsv']
DATA_EFFICIENT_FILES = ['limited-reconstruction-scenes.zip', 'limited-annotation-points.zip', 'limited-bboxes.zip', '1.7MB']
GRIT_FILES = ['ScanNet-GRIT.zip']
RELEASES = ['v2/scans', 'v1/scans']
RELEASES_TASKS = ['v2/tasks', 'v1/tasks']
RELEASES_NAMES = ['v2', 'v1']
RELEASE = RELEASES[0]
RELEASE_TASKS = RELEASES_TASKS[0]
RELEASE_NAME = RELEASES_NAMES[0]
LABEL_MAP_FILE = LABEL_MAP_FILES[0]
RELEASE_SIZE = '1.2TB'
V1_IDX = 1def get_release_scans(release_file):scan_lines = urllib.request.urlopen(release_file)scans = []for scan_line in scan_lines:scan_id = scan_line.decode('utf8').rstrip('\n')scans.append(scan_id)return scansdef download_release(release_scans, out_dir, file_types, use_v1_sens, skip_existing):if len(release_scans) == 0:returnprint('Downloading ScanNet ' + RELEASE_NAME + ' release to ' + out_dir + '...')for scan_id in release_scans:scan_out_dir = os.path.join(out_dir, scan_id)download_scan(scan_id, scan_out_dir, file_types, use_v1_sens, skip_existing)print('Downloaded ScanNet ' + RELEASE_NAME + ' release.')def download_file(url, out_file):out_dir = os.path.dirname(out_file)if not os.path.isdir(out_dir):os.makedirs(out_dir)if not os.path.isfile(out_file):print('\t' + url + ' > ' + out_file)fh, out_file_tmp = tempfile.mkstemp(dir=out_dir)f = os.fdopen(fh, 'w')f.close()urllib.request.urlretrieve(url, out_file_tmp)os.rename(out_file_tmp, out_file)else:print('WARNING: skipping download of existing file ' + out_file)def download_scan(scan_id, out_dir, file_types, use_v1_sens, skip_existing=False):print('Downloading ScanNet ' + RELEASE_NAME + ' scan ' + scan_id + ' ...')if not os.path.isdir(out_dir):os.makedirs(out_dir)for ft in file_types:v1_sens = use_v1_sens and ft == '.sens'url = BASE_URL + RELEASE + '/' + scan_id + '/' + scan_id + ft if not v1_sens else BASE_URL + RELEASES[V1_IDX] + '/' + scan_id + '/' + scan_id + ftout_file = out_dir + '/' + scan_id + ftif skip_existing and os.path.isfile(out_file):continuedownload_file(url, out_file)print('Downloaded scan ' + scan_id)def download_task_data(out_dir):print('Downloading ScanNet v1 task data...')files = [LABEL_MAP_FILES[V1_IDX], 'obj_classification/data.zip','obj_classification/trained_models.zip', 'voxel_labeling/data.zip','voxel_labeling/trained_models.zip']for file in files:url = BASE_URL + RELEASES_TASKS[V1_IDX] + '/' + filelocalpath = os.path.join(out_dir, file)localdir = os.path.dirname(localpath)if not os.path.isdir(localdir):os.makedirs(localdir)download_file(url, localpath)print('Downloaded task data.')def download_tfrecords(in_dir, out_dir):print('Downloading tf records (302 GB)...')if not os.path.exists(out_dir):os.makedirs(out_dir)split_to_num_shards = {'train': 100, 'val': 25, 'test': 10}for folder_name in ['hires_tfrecords', 'lores_tfrecords']:folder_dir = '%s/%s' % (in_dir, folder_name)save_dir = '%s/%s' % (out_dir, folder_name)if not os.path.exists(save_dir):os.makedirs(save_dir)for split, num_shards in split_to_num_shards.items():for i in range(num_shards):file_name = '%s-%05d-of-%05d.tfrecords' % (split, i, num_shards)url = '%s/%s' % (folder_dir, file_name)localpath = '%s/%s/%s' % (out_dir, folder_name, file_name)download_file(url, localpath)def download_label_map(out_dir):print('Downloading ScanNet ' + RELEASE_NAME + ' label mapping file...')files = [ LABEL_MAP_FILE ]for file in files:url = BASE_URL + RELEASE_TASKS + '/' + filelocalpath = os.path.join(out_dir, file)localdir = os.path.dirname(localpath)if not os.path.isdir(localdir):os.makedirs(localdir)download_file(url, localpath)print('Downloaded ScanNet ' + RELEASE_NAME + ' label mapping file.')def main():parser = argparse.ArgumentParser(description='Downloads ScanNet public data release.')parser.add_argument('-o', '--out_dir', required=True, help='directory in which to download')parser.add_argument('--task_data', action='store_true', help='download task data (v1)')parser.add_argument('--label_map', action='store_true', help='download label map file')parser.add_argument('--v1', action='store_true', help='download ScanNet v1 instead of v2')parser.add_argument('--id', help='specific scan id to download')parser.add_argument('--preprocessed_frames', action='store_true', help='download preprocessed subset of ScanNet frames (' + PREPROCESSED_FRAMES_FILE[1] + ')')parser.add_argument('--test_frames_2d', action='store_true', help='download 2D test frames (' + TEST_FRAMES_FILE[1] + '; also included with whole dataset download)')parser.add_argument('--data_efficient', action='store_true', help='download data efficient task files; also included with whole dataset download)')parser.add_argument('--tf_semantic', action='store_true', help='download google tensorflow records for 3D segmentation / detection')parser.add_argument('--grit', action='store_true', help='download ScanNet files for General Robust Image Task')parser.add_argument('--type', help='specific file type to download (.aggregation.json, .sens, .txt, _vh_clean.ply, _vh_clean_2.0.010000.segs.json, _vh_clean_2.ply, _vh_clean.segs.json, _vh_clean.aggregation.json, _vh_clean_2.labels.ply, _2d-instance.zip, _2d-instance-filt.zip, _2d-label.zip, _2d-label-filt.zip)')parser.add_argument('--skip_existing', action='store_true', help='skip download of existing files when downloading full release')args = parser.parse_args()print('By pressing any key to continue you confirm that you have agreed to the ScanNet terms of use as described at:')print(TOS_URL)print('***')print('Press any key to continue, or CTRL-C to exit.')key = input('')if args.v1:global RELEASEglobal RELEASE_TASKSglobal RELEASE_NAMEglobal LABEL_MAP_FILERELEASE = RELEASES[V1_IDX]RELEASE_TASKS = RELEASES_TASKS[V1_IDX]RELEASE_NAME = RELEASES_NAMES[V1_IDX]LABEL_MAP_FILE = LABEL_MAP_FILES[V1_IDX]assert((not args.tf_semantic) and (not args.grit)), "Task files specified invalid for v1"release_file = BASE_URL + RELEASE + '.txt'release_scans = get_release_scans(release_file)file_types = FILETYPES;release_test_file = BASE_URL + RELEASE + '_test.txt'release_test_scans = get_release_scans(release_test_file)file_types_test = FILETYPES_TEST;out_dir_scans = os.path.join(args.out_dir, 'scans')out_dir_test_scans = os.path.join(args.out_dir, 'scans_test')out_dir_tasks = os.path.join(args.out_dir, 'tasks')if args.type: # download file typefile_type = args.typeif file_type not in FILETYPES:print('ERROR: Invalid file type: ' + file_type)returnfile_types = [file_type]if file_type in FILETYPES_TEST:file_types_test = [file_type]else:file_types_test = []if args.task_data: # download task datadownload_task_data(out_dir_tasks)elif args.label_map: # download label map filedownload_label_map(args.out_dir)elif args.preprocessed_frames: # download preprocessed scannet_frames_25k.zip fileif args.v1:print('ERROR: Preprocessed frames only available for ScanNet v2')print('You are downloading the preprocessed subset of frames ' + PREPROCESSED_FRAMES_FILE[0] + ' which requires ' + PREPROCESSED_FRAMES_FILE[1] + ' of space.')download_file(os.path.join(BASE_URL, RELEASE_TASKS, PREPROCESSED_FRAMES_FILE[0]), os.path.join(out_dir_tasks, PREPROCESSED_FRAMES_FILE[0]))elif args.test_frames_2d: # download test scannet_frames_test.zip fileif args.v1:print('ERROR: 2D test frames only available for ScanNet v2')print('You are downloading the 2D test set ' + TEST_FRAMES_FILE[0] + ' which requires ' + TEST_FRAMES_FILE[1] + ' of space.')download_file(os.path.join(BASE_URL, RELEASE_TASKS, TEST_FRAMES_FILE[0]), os.path.join(out_dir_tasks, TEST_FRAMES_FILE[0]))elif args.data_efficient: # download data efficient task filesprint('You are downloading the data efficient task files' + ' which requires ' + DATA_EFFICIENT_FILES[-1] + ' of space.')for k in range(len(DATA_EFFICIENT_FILES)-1):download_file(os.path.join(BASE_URL, RELEASE_TASKS, DATA_EFFICIENT_FILES[k]), os.path.join(out_dir_tasks, DATA_EFFICIENT_FILES[k]))elif args.tf_semantic: # download google tf recordsdownload_tfrecords(os.path.join(BASE_URL, RELEASE_TASKS, 'tf3d'), os.path.join(out_dir_tasks, 'tf3d'))elif args.grit: # download GRIT filedownload_file(os.path.join(BASE_URL, RELEASE_TASKS, GRIT_FILES[0]), os.path.join(out_dir_tasks, GRIT_FILES[0]))elif args.id: # download single scanscan_id = args.idis_test_scan = scan_id in release_test_scansif scan_id not in release_scans and (not is_test_scan or args.v1):print('ERROR: Invalid scan id: ' + scan_id)else:out_dir = os.path.join(out_dir_scans, scan_id) if not is_test_scan else os.path.join(out_dir_test_scans, scan_id)scan_file_types = file_types if not is_test_scan else file_types_testuse_v1_sens = not is_test_scanif not is_test_scan and not args.v1 and '.sens' in scan_file_types:print('Note: ScanNet v2 uses the same .sens files as ScanNet v1: Press \'n\' to exclude downloading .sens files for each scan')key = input('')if key.strip().lower() == 'n':scan_file_types.remove('.sens')download_scan(scan_id, out_dir, scan_file_types, use_v1_sens, skip_existing=args.skip_existing)else: # download entire releaseif len(file_types) == len(FILETYPES):print('WARNING: You are downloading the entire ScanNet ' + RELEASE_NAME + ' release which requires ' + RELEASE_SIZE + ' of space.')else:print('WARNING: You are downloading all ScanNet ' + RELEASE_NAME + ' scans of type ' + file_types[0])print('Note that existing scan directories will be skipped. Delete partially downloaded directories to re-download.')print('***')print('Press any key to continue, or CTRL-C to exit.')key = input('')if not args.v1 and '.sens' in file_types:print('Note: ScanNet v2 uses the same .sens files as ScanNet v1: Press \'n\' to exclude downloading .sens files for each scan')key = input('')if key.strip().lower() == 'n':file_types.remove('.sens')download_release(release_scans, out_dir_scans, file_types, use_v1_sens=True, skip_existing=args.skip_existing)if not args.v1:download_label_map(args.out_dir)download_release(release_test_scans, out_dir_test_scans, file_types_test, use_v1_sens=False, skip_existing=args.skip_existing)download_file(os.path.join(BASE_URL, RELEASE_TASKS, TEST_FRAMES_FILE[0]), os.path.join(out_dir_tasks, TEST_FRAMES_FILE[0]))for k in range(len(DATA_EFFICIENT_FILES)-1):download_file(os.path.join(BASE_URL, RELEASE_TASKS, DATA_EFFICIENT_FILES[k]), os.path.join(out_dir_tasks, DATA_EFFICIENT_FILES[k]))if __name__ == "__main__": main()整个数据集太大了,要1.2T,所以根据需要下载
python3 download-scannetv2.py -o scannet/ --type _vh_clean_2.ply
python3 download-scannetv2.py -o scannet/ --type _vh_clean_2.labels.ply
python3 download-scannetv2.py -o scannet/ --type _vh_clean_2.0.010000.segs.json
python3 download-scannetv2.py -o scannet/ --type .aggregation.json
下载好之后会是这样子的

ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes
数据集介绍
S3DIS数据集 S3DIS数据集在6个区域的271个房间,使用Matterport相机(结合3个不同间距的结构光传感器),扫描后生成重建3D纹理网格,RGB-D图像等数据,并通过对网格进行采样来制作点云。对点云中的每个点都加上了1个语义标签(例如椅子,桌子,地板,墙等共计13个对象) 网上填表很快给回复,下载# Donwload links:wget https://cvg-data.inf.ethz.ch/s3dis/ReadMe.txt
wget https://storage.googleapis.com/s3dis_data/Stanford3dDataset_v1.2.mat
wget https://cvg-data.inf.ethz.ch/s3dis/Stanford3dDataset_v1.2.zip
wget https://cvg-data.inf.ethz.ch/s3dis/Stanford3dDataset_v1.2_Aligned_Version.mat
wget https://cvg-data.inf.ethz.ch/s3dis/Stanford3dDataset_v1.2_Aligned_Version.zip问题1:Area_5/hallway_6中多了一个额外的字符,不符合编码规范,需要手动删除。
经查找具体位置为:Stanford3dDataset_v1.2_Aligned_Version\Area_5\hallway_6\Annotations\ceiling_1.txt中的第180389行数字185后。windows下建议使用EmEditor打开文件,会自动跳转到该行,数字185后面有一个类似空格的字符,实际上不是空格,删掉然后重新打一个空格就可以了
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!