基于kfaka和zookeeper的nginx日志收集平台,项目详细步骤
目录
一、项目环境:
二、项目介绍:
三、项目步骤
3.1 环境准备
3.1.1 准备好虚拟机
3.1.2 配置好静态ip
3.1.3 修改主机名以及写好域名映射关系
3.1.4 安装基本软件
3.1.5 关闭防火墙
3.2 nginx的部署
3.2.1 安装相关软件
3.2.2 修改相关配置文件
3.3 kafka的部署
3.3.1 相关软件安装
3.3.2 配置kafka
3.3.3 zookeeper的部署
3.4 测试
3.4.1 创建一个topic
3.4.2 创建生产者和消费者
3.5 filebeat的部署
3.5.1 安装
3.5.2 编辑文件 vim /etc/yum.repos.d/fb.repo
3.5.3 安装
3.5.4 设置开机自启
3.5.5 修改配 vim /etc/filebeat/filebeat.yml
3.5.6 创建主题
3.5.7 启动服务
3.6 数据库
3.7 编写python消费程序
四、项目详解
4.1 项目总流程
4.2 keepalived
4.2.1 keepalived的作用
4.2.2 keepalived的工作原理
4.3 kafak
4.3.1 什么是kafka
4.3.2 kafka的专业术语
4.3.3 kafka里的数据可靠性和数据一致性问题
4.3.4 kafka内leader的选举
4.4 zookeeper
4.1.1 什么是zookeeper
4.4.2 zookeeper内leader的选举
4.4.3 zookeeper在kafka内的作用
4.5 filebeat
4.5.1 什么是filebeat
4.5.2.filebeat的构成
一、项目环境:
CentOS Linux release 7.9.2009 (Core)、mariadb 5.5.68、Python 3.6、nginx 1.20.1、 filebeat 7.17.5、zookeeper 3.6.3、kafka 2.12
二、项目介绍:
本项目使用filebeat收集前端 nginx 集群访问日志,统一荐入 kafka 平台,对 nginx 日志做清洗,获取流量信息存 入数据库。
三、项目步骤
3.1 环境准备
3.1.1 准备好虚拟机
准备好8台虚拟机,三台用来搭建kafak+zookeeper集群,三台台用来搭建nginx集群,两台用来搭建MySQL数据库。
3.1.2 配置好静态ip
每台虚拟机最好都配置好静态的ip地址,便于后续的使用,如何配置请参考:(1条消息) Linux如何固定ip地址,及ifcfg-ens33文件参数_忙碌且充实的博客-CSDN博客_linux固定ip
3.1.3 修改主机名以及写好域名映射关系
1.修改主机名
[root@localhost network-scripts]# hostnamectl set-hostname nginx-kafka032.域名映射关系
[root@nginx-kafka03 nginx]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.178.263.150 nginx-kafka01
192.178.263.137 nginx-kafka02
192.178.263.134 nginx-kafka03每台机器上都要在/etc/hosts文件内设置好域名映射, 主机与ip一一对应,方便的操作。
3.1.4 安装基本软件
yum install wget lsof vim -y
yum -y install chrony
systemctl enable chronyd 设置开机自启 disable 关闭开机自启,systemctl start chronyd 启动chronnyd。
设置时区
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
3.1.5 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
并且关闭 selinux,编辑文件 /etc/selinux/config,修改成SELINUX=disabled。想要查看是否关闭成功使用 getenforce。selinux关闭 需要重启机器,selinux是一个linux系统内核里的一个跟安全相关的子系统,规则非常繁琐,一般日常工作里都是关闭的。
3.2 nginx的部署
3.2.1 安装相关软件
yum install epel-release -y
yum install nginx -y
启动:systemctl start nginx,设置开机自启:systemctl enable nginx 。
3.2.2 修改相关配置文件
[root@nginx-kafka01 ~]# vim /etc/nginx/nginx.conf
文件内大概是这样的结构
#根据核数自动生成进程数
worker_processes auto;
... #全局块events { #events块、事件块#最大支持多少连接worker_connections 1024;
}http #http块
{
#日志格式
log_format main '$remote_addr(远程ip) - $remote_user(远程用户) [$time_local] "$request" ''$status(状态) $body_bytes_sent "$http_referer" ''"$http_user_agent" "$http_x_forwarded_for"';... #http全局块server #server块{ ... #server全局块location [PATTERN] #location块{...}location [PATTERN] {...}}
#虚拟主机块,一个网站一个server,需要写在http块内server{...}#这下面的文件也会加载进来include /etc/nginx/default.d/*.conf;... #http全局块
}修改:将 listen 80 default_server;修改成:listen 80;。
相关模块:
1、全局块:配置影响nginx全局的指令。一般有运行nginx服务器的用户组,nginx进程pid存放路径,日志存放路径,配置文件引入,允许生成worker process数等。
2、events块:配置影响nginx服务器或与用户的网络连接。有每个进程的最大连接数,选取哪种事件驱动模型处理连接请求,是否允许同时接受多个网路连接,开启多个网络连接序列化等。
3、http块:可以嵌套多个server,配置代理,缓存,日志定义等绝大多数功能和第三方模块的配置。如文件引入,mime-type定义,日志自定义,是否使用sendfile传输文件,连接超时时间,单连接请求数等。
4、server块:配置虚拟主机的相关参数,一个http中可以有多个server。
5、location块:配置请求的路由,以及各种页面的处理情况。
##注: nginx 的 default_server 指令可以定义默认的 server 出处理一些没有成功匹配 server_name 的请求,如果没有显式定义,则会选取第一个定义的 server 作为 default_server。
在了解到如上规则后,我们可以捕获未做绑定的域名访问或直接IP访问,做重定向到403页面等处理
新建一个sc.conf文件
vim /etc/nginx/conf.d/sc.conf
并写入以下内容:
server {listen 80 default_server;server_name www.sc.com;# html文本存放的位置,访问根目录直接访问index.htmlroot /usr/share/nginx/html;access_log /var/log/nginx/sc/access.log main;location / {}
}检查nginx是否搭建成功,语法检测。
[root@nginx-kafka01 html]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: [emerg] open() "/var/log/nginx/sc/access.log" failed (2: No such file or directory)
nginx: configuration file /etc/nginx/nginx.conf test failed[root@nginx-kafka01 html]# mkdir /var/log/nginx/sc[root@nginx-kafka01 html]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful重新加载nginx。
nginx -s reload
3.3 kafka的部署
3.3.1 相关软件安装
yum install java wget -y 安装java
安装kafka:kafka_2.12-2.8.1版本需要 apache-zookeeper,最新的版本不需要脱离了apache-zookeeper。
wget https://mirrors.bfsu.edu.cn/apache/kafka/2.8.1/kafka_2.12-2.8.1.tgz
安装zookeeper
wget https://mirrors.bfsu.edu.cn/apache/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
tar xf kafka_2.12-2.8.1.tgz 解包
3.3.2 配置kafka
修改 vim /opt/kafka_2.12-2.8.1/config/server.properties 文件,配置如下:
① 修改broker.id
② 修改listeners=PLAINTEXT
③ 修改zookeeper.connec
############################# Server Basics ############################## The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
############################# Socket Server Settings ############################## The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
#listeners=PLAINTEXT://:9092
listeners=PLAINTEXT://nginx-kafka01:9092# Hostname and port the broker will advertise to producers and consumers. If not set,
# it uses the value for "listeners" if configured. Otherwise, it will use the value############################# Zookeeper ############################## Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=192.178.263.150:2181,192.178.263.137:2181,192.178.263.134:2181每台机器对应一个broker块,所以每台机器对应一个broker.id,这几个配置kafka+zookeeper集群上面都要进行配置。
listeners当前进行修改的主机,监听当前机器的9092端口,zookeeper.connect:zookeeper集群连接那几台机器,将其ip写在这里。
3.3.3 zookeeper的部署
cd /opt/apache-zookeeper-3.6.3-bin/confs
cp zoo_sample.cfg ./zoo.cfg
vim zoo.cfg
1.修改配置文件
修改 vim /opt/apache-zookeeper-3.6.3-bin/confs/cfg zoo.cfg,在最末尾添加以下几行。
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
server.1=192.178.263.150:3888:4888
server.2=192.178.263.137:3888:4888
server.3=192.178.263.134:3888:48883888和4888都是端口 一个用于数据传输,一个用于检验存活性和选举。
创建myid文件,并添加与上一步server对应的编号。
cd /tmp/zookeeper
touch myid
echo 1 > /tmp/zookeeper/myid
2.启动zookeeper:
bin/zkServer.sh start
开启zk和kafka的时候,一定是先启动zk,再启动kafka,关闭服务的时候,kafka先关闭,再关闭zk。
查看zookeeper是否启动成功:
[root@nginx-kafka03 apache-zookeeper-3.6.3-bin]# bin/zkServer.sh status
出现follower和leader即成功,三台机器有一个leader和两个follower,leader只有一个。
3.启动kafka
bin/kafka-server-start.sh -daemon config/server.properties
3.4 测试
3.4.1 创建一个topic
bin/kafka-topics.sh --create --zookeeper 192.178.263.134:2181 --replication-factor 1 --partitions 1 --topic sc
ip为任意一台zookeeper即可。
3.4.2 创建生产者和消费者
创建生产者(kafka,ctrl + D 退出,ip为任意一台kafka即可)[root@localhost kafka_2.12-2.8.0]# bin/kafka-console-producer.sh --broker-list 192.168.253.134:9092 --topic nginxlog
>hello
>sanchuang tongle
>nihao
>world !!!!!!1
>创建消费者
[root@localhost kafka_2.12-2.8.0]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.253.137:9092 --topic nginxlog --from-beginning3.5 filebeat的部署
3.5.1 安装
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
3.5.2 编辑文件 vim /etc/yum.repos.d/fb.repo
添加以下的内容:
[elastic-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
3.5.3 安装
yum install filebeat -y
3.5.4 设置开机自启
systemctl enable filebeat
3.5.5 修改配 vim /etc/filebeat/filebeat.yml
添加内容:
# 收集什么数据,字典形式,对格式要求严格
filebeat.inputs:
- type: log# Change to true to enable this input configuration.enabled: true# Paths that should be crawled and fetched. Glob based paths.paths:- /var/log/nginx/sc/access.log
#==========------------------------------kafka-----------------------------------
#吐到哪里去,只支持一个输出(output)
output.kafka:hosts: ["192.168.229.139:9092","192.168.229.140:9092"]topic: nginxlogkeep_alive: 10s3.5.6 创建主题
bin/kafka-topics.sh --create --zookeeper 192.178.263.134:2181 --replication-factor 3 --partitions 1 --topic nginxlog
3.5.7 启动服务
systemctl start filebeat
查看是否成功,看能不能消费nginxlog ,去消费一下。
3.6 数据库
建立好相关的数据库表,存储好相应的日志信息。
3.7 编写python消费程序
初版代码如下:
import json
import requests
import time
import pymysqltaobao_url = "https://ip.taobao.com/outGetIpInfo?accessKey=alibaba-inc&ip="# 查询ip地址的信息(省份和运营商isp),通过taobao网的接口
def resolv_ip(ip):response = requests.get(taobao_url + ip)if response.status_code == 200:tmp_dict = json.loads(response.text)prov = tmp_dict["data"]["region"]isp = tmp_dict["data"]["isp"]return prov, ispreturn None, None# 将日志里读取的格式转换为我们指定的格式
def trans_time(dt):# 把字符串转成时间格式timeArray = time.strptime(dt, "%d/%b/%Y:%H:%M:%S")# timeStamp = int(time.mktime(timeArray))# 把时间格式转成字符串new_time = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)return new_time# 从kafka里获取数据,清洗为我们需要的ip,时间,带宽
from pykafka import KafkaClientclient = KafkaClient(hosts="192.178.263.150:9092,192.178.263.137:9092,192.178.263.134:9092")
topic = client.topics['nginxlog']
balanced_consumer = topic.get_balanced_consumer(consumer_group='testgroup',auto_commit_enable=True,zookeeper_connect='nginx-kafka01:2181,nginx-kafka02:2181,nginx-kafka03:2181'
)
# consumer = topic.get_simple_consumer()
for message in balanced_consumer:if message is not None:line = json.loads(message.value.decode("utf-8"))log = line["message"]tmp_lst = log.split()ip = tmp_lst[0]dt = tmp_lst[3].replace("[", "")bt = tmp_lst[9]dt = trans_time(dt)prov, isp = resolv_ip(ip)if prov and isp:print(prov, isp, dt,bt)db = pymysql.connect(host="192.178.263.134", user="sc", password="123456", port=3306, db="consumers", charset="utf8")cursor = db.cursor()try:cursor.execute('insert into nginxlog2(dt,prov,isp,bd) values("%s", "%s", "%s", "%s")' % (dt, prov, isp, bt))db.commit()print("保存成功")except Exception as err:print("修改失败", err)db.rollback()db.close()
四、项目详解
4.1 项目总流程
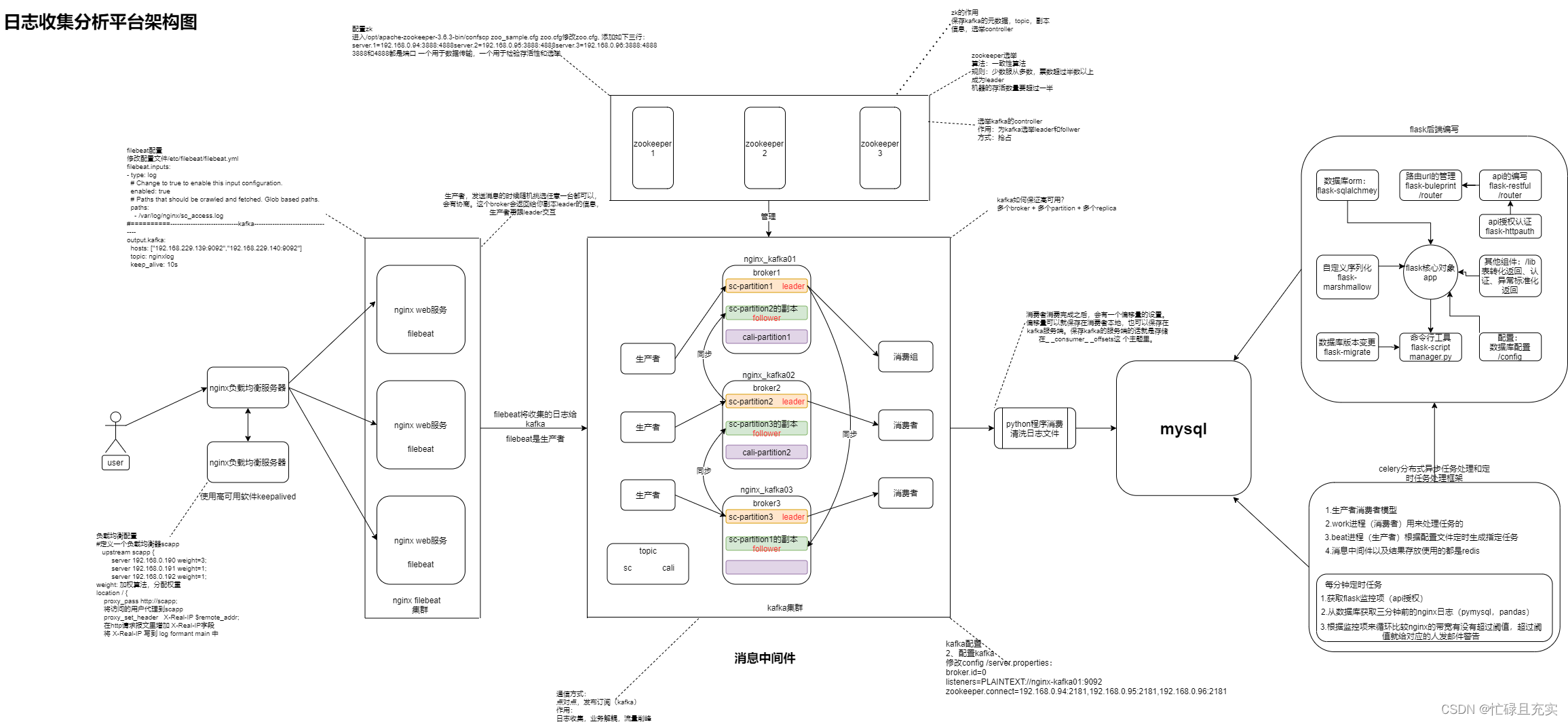
用户通过nginx负载均衡去访问nginx web集群,使用filebeat收集nginx web 集群上的日志,存入在kafka中,编写一个Python消费者程序,通过淘宝接口过滤出ip、省份、运营商、带宽,存入到数据库。
4.2 keepalived
4.2.1 keepalived的作用
Keepalived是Linux下一个轻量级别的高可用解决方案。Keepalived的作用是检测服务器的状态,如果有一台web服务器宕机,或工作出现故障,Keepalived将检测到,并将有故障的服务器从系统中剔除,同时使用其他服务器代替该服务器的工作,当服务器工作正常后Keepalived自动将服务器加入到服务器群中,这些工作全部自动完成,不需要人工干涉,需要人工做的只是修复故障的服务器。
4.2.2 keepalived的工作原理
keepalived是以VRRP(Vritrual Router Redundancy Protocol,虚拟路由冗余协议)为实现基础的。
虚拟路由冗余协议,可以认为是实现路由器高可用的协议,即将N台提供相同功能的路由器组成一个路由器组,这个组里面有一个master 和多个 backup,master 上面有一个对外提供服务的 VIP(Virtual IP Address)(该路由器所在局域网内其他机器的默认路由为该 vip),master 会发组播,当 backup 收不到 vrrp 包时就认为 master 宕掉了,这时就需要根据 VRRP 的优先级来选举一个 backup 当 master。这样的话就可以保证路由器的高可用了。
keepalived 主要有三个模块,分别是core、check 和 vrrp。core 模块为keepalived的核心,负责主进程的启动、维护以及全局配置文件的加载和解析。check 负责健康检查,包括常见的各种检查方式。vrrp 模块是来实现 VRRP 协议的。
详细解释可以看:Keepalived 原理与实战 - 知乎 (zhihu.com)
4.3 kafak
4.3.1 什么是kafka
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
kafka是一个消息中间件,典型的生产者和消费者模型,一边生产一边消费。kafka经常用在日志收集内:
- 日志收集
- 业务解耦
- 流量削峰
可参考:Kafka学习之路 (一)Kafka的简介 - 扎心了,老铁 - 博客园 (cnblogs.com)
4.3.2 kafka的专业术语
1.Topic
topic主题,kafka的一个消息类别。用户只需要访问消息的topic,即可访问对应的信息类别。
2.Broker
kafka内的服务器节点,也可以叫做进程节点,broker存储topic的数据。
3.Partition
kakfa的分区,针对topic来说的,topic中的数据分割为一个或多个partition。partition的存储分为两部分,.index结尾的文件和 .log结尾的文件,成对存在.index存放的是索引,.log文件存放物理位置,每一个partition的数据都是由很多个segment存储,每一个segment由1个index和log文件组成。分成多个segment分段存储,便于清除,kafka可以按照两个维度清理数据,按时间,按大小。
每个partition都都会有leader partiton和follow partiton。其中leader partition是用来进行和producer进行写交互,follow从leader副本进行拉数据进行同步,从而保证数据的冗余,防止数据丢失的目的。
4.Replica
副本 就是完整备份的分区,kafka里的高可用,几份数据就是几份副本,Kafka的备份的单元是partition。
5.Leader
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
6.Follower
follower与leader相对应,Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。
7.ISR
in-sync-reolica 集合列表,需要同步的follower集合,如果leader挂了,就重新在follower内选一个作为leader,一般是列表的第一个。
比如说5个副本,1个leader, 4个follower,有一条消息来了,leader怎么知道要同步哪些副本呢?根据ISR来,如果一个follower挂了,那就从这个ISR列表里删除,如果一个follower卡住或者同步过慢它也会从ISR里删除。
8.Producer
生产者,生产者即数据的发布者,该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的segment文件中。生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition。
9.Consumer
消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
10.Offset
偏移量,记录消费者每次消费的位置,便于消费者下次消费找到上次消费的位置,写入到本地的文件里面offset,消费一条写入一条。
消费者消费的时候,会记录自己的消费偏移量,要么自己保存offset再本地,要么提交在kafka的__consumer_offsets主题进行保存offset。
参考文章:Kafka学习之路 (一)Kafka的简介 - 扎心了,老铁 - 博客园 (cnblogs.com)
4.3.3 kafka里的数据可靠性和数据一致性问题
数据可靠性
Kafka 在 Producer 里面提供了消息确认机制,也就是说我们可以通过配置来决定有几个副本收到这条消息才算消息发送成功。
acsk=0,生产者不会等待任何来自服务器的响应,发完就发下一条。
acsk=1(默认值),只要集群的leader节点收到消息,生产者就会收到一个来自leader服务器的成功响应,只要集群的Leader节点收到消息,生产者就会收到一个来自服务器的成功响应如果消息无法到达Leader节点(例如Leader节点崩溃,新的Leader节点还没有被选举出来)生产者就会收到一个错误响应,为了避免数据丢失,生产者会重发消息。
acsk=-1,等待ISR列表中的每一个副本收到,生产者才会收到,效率最低但是最安全。
数据一致性
引入 High Water Mark 机制,木桶效应,最多只能消费ISR列表里偏移量最少的副本的消息数量。有一个机器当机了从ISR列表中被踢出,挂掉的那个partition再次恢复只有达到正在运行的partition的High Water Mark ,才会被重新加入ISR列表,如果有一个机器当机了,后续启动之后想要重新加入ISR,必须同步到High Water Mark(最高水位线,HW)值。
参考文章:kafka如何保证数据可靠性和数据一致性 - gaoyanliang - 博客园 (cnblogs.com)
4.3.4 kafka内leader的选举
顺延,在ISR列表内顺延下一个。
4.4 zookeeper
4.1.1 什么是zookeeper
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
ZooKeeper包含一个简单的原语集,提供Java和C的接口。
4.4.2 zookeeper内leader的选举
一致性算法,少数服从多数原则,票数过半的选为leader>=n//2+1,客户端连接任意一台zookeeper都可以操作,但是,数据新增修改等事物操作必须在leader上运行,客户端如果连接到follower上进事物操作,follower会返回给leader的ip,最终客户端还是会在leader上进心操作。
zookeeper集群必须是节点(机器)存活数过半,整个集群才能用,要不然数据容易混乱、脑裂,zookeeper集群的节点数一般都设置为奇数。
4.4.3 zookeeper在kafka内的作用
1、保存kafka的元数据、topic,副本信息。
2、选举kafaka的controller,zookeeper选出来的一台机器,通过抢占的方式进行选举controller的,先到先得。
controller的作用:选举出来的kafka的controller来管理kafka副本的leader和follower,同步,选举 。
参考文章:1.0 Zookeeper 教程 | 菜鸟教程 (runoob.com)
Zookeeper集群"脑裂"问题 - 运维总结 - 散尽浮华 - 博客园 (cnblogs.com)
4.5 filebeat
4.5.1 什么是filebeat
Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash进行索引。
Filebeat的工作方式如下:启动Filebeat时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。对于Filebeat所找到的每个日志,Filebeat都会启动收集器。每个收集器都读取单个日志以获取新内容,并将新日志数据发送到libbeat,libbeat将聚集事件,并将聚集的数据发送到为Filebeat配置的输出。
4.5.2.filebeat的构成
filebeat结构:由两个组件构成,分别是inputs(输入)和harvesters(收集器),这些组件一起工作来跟踪文件并将事件数据发送到您指定的输出,harvester负责读取单个文件的内容。
参考文章:一篇文章搞懂filebeat(ELK) - 一寸HUI - 博客园 (cnblogs.com)
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!