图片爬虫,手把手教你Python多线程下载获取图片
图片站lemanoosh数据为异步加载的形式,往下拉会展示更多数据,也就是下一页数据,通过谷歌浏览器可以很清晰的看到数据接口地址,以及数据展现形式,与其他网站返回json数据的不同之处是,该网站返回的是部分html源码数据,包含有需要获取的图片地址。
使用的第三方库:
import requests
from fake_useragent import UserAgent
import re
from multiprocessing.dummy import Pool as ThreadPool
import datetime
import time
其中使用 multiprocessing.dummy 执行多线程任务,使用线程池的方式来执行多线程任务。
扩展:
工作中有个常用的场景,比如现在需要下载10W张图片,我们不可能写个for循环一张一张的下载吧,又或者是我们做个简单的HTTP压力测试肯定是要使用多个,进程或者线程去做(每个请求handler,会有一个参数(所有的参数生成一个队列))然后把handler和队列map到Pool里面。肯定要用多线程或者是多进程,然后把这100W的队列丢给线程池或者进程池去处理在python中multiprocessing Pool进程池,以及multiprocessing.dummy非常好用,一般:
from multiprocessing import Pool as ProcessPool from multiprocessing.dummy import Pool as ThreadPool
前者是多个进程,后者使用的是线程,之所以dummy(中文意思“假的”) ————————————————
来源:本文为CSDN博主「FishBear_move_on」 原文链接:https://blog.csdn.net/haluoluo211/article/details/77636916
爬取思路
步骤一:获取列表页面内容并提取图片地址
接口地址:https://lemanoosh.com/app/themes/lemanoosh2017/resources/publications.php
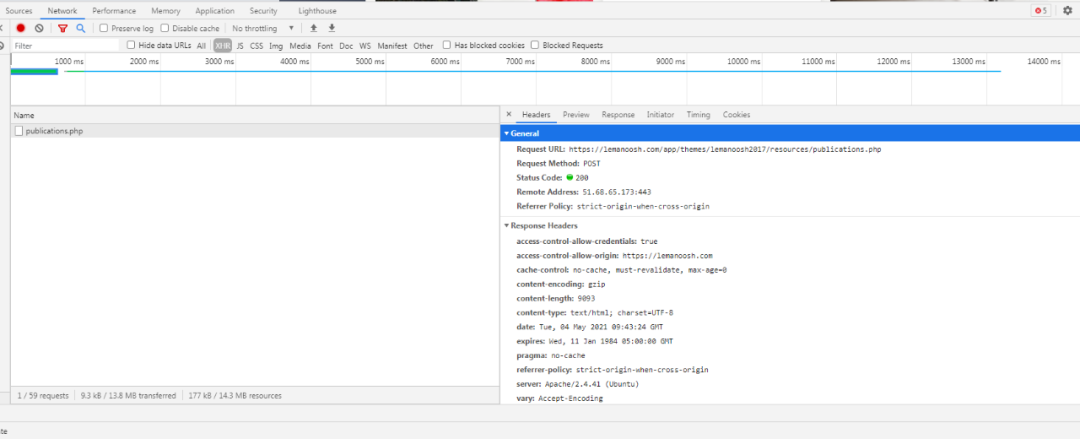
请求方式:POST
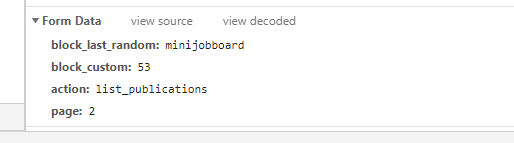
请求数据:
block_last_random: minijobboard
block_custom: 53
action: list_publications
page: 2
注意:page字段为页码数,更换页码数可相应获取数据内容。
参考源码:
#获取图片数据
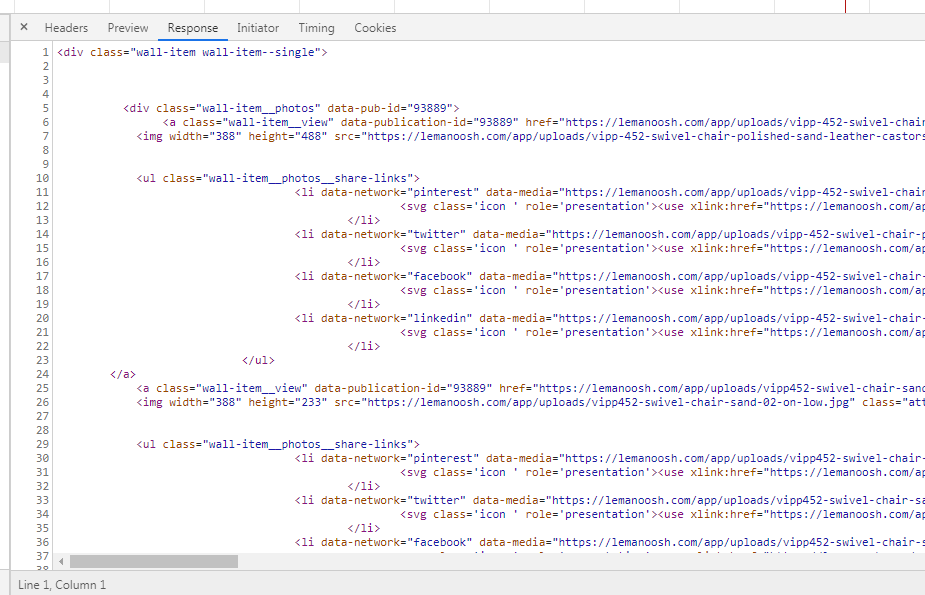
def get_pagelist(pagenum):url="https://lemanoosh.com/app/themes/lemanoosh2017/resources/publications.php"headers={'User-Agent':UserAgent().random}data={'block_last_random': 'custom','block_custom': '54','action': 'list_publications','page': pagenum,}response=requests.post(url=url,data=data,headers=headers,timeout=8)#print(response.status_code)if response.status_code == 200:html=response.content.decode('utf-8')datamedias=re.findall(r'data-media="(.+?)"',html,re.S)print(len(datamedias))print(datamedias)datamedias=set(datamedias)print(len(datamedias))return datamedias
图片数据,即图片地址使用了正则表达式获取,同时经过比对,发现源html数据内的图片地址存在重复,故进行了去重处理,采用的set函数!
步骤二:下载获取图片数据 参考源码:
#下载图片数据
def dowm(imgurl):imgname=imgurl.split("/")[-1]imgname=f'{get_time_stamp13()}{imgname}'headers = {'User-Agent': UserAgent().random}r=requests.get(url=imgurl,headers=headers,timeout=8)with open(f'lemanoosh/{imgname}','wb') as f:f.write(r.content)print(f'{imgname} 图片下载成功了!')
使用线程池多线程获取图片数据参考源码:
#多线程下载图片数据
def thread_down(imgs):try:# 开4个 worker,没有参数时默认是 cpu 的核心数pool = ThreadPool()results = pool.map(dowm, imgs)pool.close()pool.join()print("采集所有图片完成!")except:print("Error: unable to start thread")
步骤三:循环获取下载图片 参考源码:
#主程序
def main():for i in range(1,2000):print(f'正在爬取采集第 {i} 页图片数据..')imgs=get_pagelist(i)thread_down(imgs)
附完整源码参考:
#20210429 获取图片数据
#微信:huguo00289
# -*- coding: utf-8 -*-
import requests
from fake_useragent import UserAgent
import re
from multiprocessing.dummy import Pool as ThreadPool
import datetime
import timedef get_float_time_stamp():datetime_now = datetime.datetime.now()return datetime_now.timestamp()def get_time_stamp16():# 生成16时间戳 eg:1540281250399895 -lndatetime_now = datetime.datetime.now()print(datetime_now)# 10位,时间点相当于从UNIX TIME的纪元时间开始的当年时间编号date_stamp = str(int(time.mktime(datetime_now.timetuple())))# 6位,微秒data_microsecond = str("%06d"%datetime_now.microsecond)date_stamp = date_stamp+data_microsecondreturn int(date_stamp)def get_time_stamp13():# 生成13时间戳 eg:1540281250399895datetime_now = datetime.datetime.now()# 10位,时间点相当于从UNIX TIME的纪元时间开始的当年时间编号date_stamp = str(int(time.mktime(datetime_now.timetuple())))# 3位,微秒data_microsecond = str("%06d"%datetime_now.microsecond)[0:3]date_stamp = date_stamp+data_microsecondreturn int(date_stamp)#获取图片数据
def get_pagelist(pagenum):url="https://lemanoosh.com/app/themes/lemanoosh2017/resources/publications.php"headers={'User-Agent':UserAgent().random}data={'block_last_random': 'custom','block_custom': '54','action': 'list_publications','page': pagenum,}response=requests.post(url=url,data=data,headers=headers,timeout=8)#print(response.status_code)if response.status_code == 200:html=response.content.decode('utf-8')datamedias=re.findall(r'data-media="(.+?)"',html,re.S)print(len(datamedias))print(datamedias)datamedias=set(datamedias)print(len(datamedias))return datamedias#下载图片数据
def dowm(imgurl):imgname=imgurl.split("/")[-1]imgname=f'{get_time_stamp13()}{imgname}'headers = {'User-Agent': UserAgent().random}r=requests.get(url=imgurl,headers=headers,timeout=8)with open(f'lemanoosh/{imgname}','wb') as f:f.write(r.content)print(f'{imgname} 图片下载成功了!')#多线程下载图片数据
def thread_down(imgs):try:# 开4个 worker,没有参数时默认是 cpu 的核心数pool = ThreadPool()results = pool.map(dowm, imgs)pool.close()pool.join()print("采集所有图片完成!")except:print("Error: unable to start thread")#主程序
def main():for i in range(1,2000):print(f'正在爬取采集第 {i} 页图片数据..')imgs=get_pagelist(i)thread_down(imgs)if __name__=='__main__':main()
以上内容仅供参考和学习,该网站适合新人练手,不妨参考学习,注意爬取频率!
·················END·················
你好,我是二大爷,
革命老区外出进城务工人员,
互联网非早期非专业站长,
喜好python,写作,阅读,英语
不入流程序,自媒体,seo . . .
公众号不挣钱,交个网友。
读者交流群已建立,找到我备注 “交流”,即可获得加入我们~
听说点 “在看” 的都变得更好看呐~
关注关注二大爷呗~给你分享python,写作,阅读的内容噢~
扫一扫下方二维码即可关注我噢~

关注我的都变秃了
说错了,都变强了!
不信你试试

扫码关注最新动态
公众号ID:eryeji
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!