Profit Maximization for Viral Marketing in Online Social Networks: Algorithms and Analysis
在线社交网络中病毒式营销的利润最大化:算法和分析
一、论文摘要及问题说明
1. 摘要
信息可以通过具有“口碑效应”的在线社交网络(OSNs)快速而广泛的传播。病毒式营销是一种典型的应用,其中OSNs中的某些种子用户以级联的方式将新产品或商业活动广告推销给其他用户。初始种子用户的选择在病毒式营销的费用和回报之间进行了权衡。
本文的主要工作:
- 定义了一个通用的利润指标,该指标自然地将影响力传播的好处与病毒营销中种子选择的成本结合在一起。
- 证明了利润度量与影响度量的显著不同之处在于它(利润)不再是单调的。该特征将利润最大化问题与传统的影响最大化问题区分开来。
- 开发了新的种子选择算法,以实现具有强大近似保证的利润最大化。
- 导出了几个利润最大化的上限,以对任何特定问题实例的算法实际性能进行基准测试。
- 使用实际OSNs数据集进行的实验评估证明了我们的算法和技术的有效性。
2. 说明
- 先前的研究大多都采用了固定的、预定的种子选择预算。本质上,种子选择的成本是为病毒式营销付出的代价(例如,为选择的用户提供免费样本或其他为促进营销而采取的激励措施)。另一方面,影响力传播是病毒式营销的回报,可以潜在地转化为产品采用量的增长。
- 利用病毒式营销的公司的目标是使回报的利润最大化,也就是回报减去投资最大。
- 将简单的爬山算法应用于利润最大化问题,在种子集的选择上不会有任何有力的理论保证。观察到用于利润最大化的种子选择是一个不受约束的次模最大化问题[注1],论文基于Buchbinder等人的双重贪婪算法的思想开发了新的种子选择算法。
二、问题公式化
1. 建模
- 将OSN建模为有向图G=(V,E),节点V代表用户,边E代表用户之间的联系。对于每个有向边
2. 符号及定义
- 关键的符号定义:
| 符号 | 描述 |
|---|---|
| G=(V,E) | 具有节点集V和边集E的社交图G |
| G=(V,E) | 具有节点集V和边集E的社交图G |
| Nu | u的邻居集合 |
| Vg(S) | 样本结果g中由S激活的节点 |
| S* | 最优种子集 |
| b(v) | 激活节点v产生的收益(benefit) |
| β(S) | 种子节点集S带来的整体收益 |
| c(S),c(v) | 选择种子集S和节点v花费的代价 |
| Ф(S) | 节点集S产生的利润:Ф(S)=β(S)-c(S) |
3. 利润最大化
1). 种子集S的影响散布以σ(S)表示,是影响传播的所有可能样本结果上激活的节点的预期数量,即σ(S)=Ε[| Vg(S) |]。
2). 利润最大化问题
- 利润度量标准:Ф(S)=β(S)-c(S) (定义可查看上面的表格)。
- β(S)=Ε[ ∑v∈Vg(S)b(v) ]是所有的节点被激活而带来的总收益。
- c(S)=∑v∈S c(V)是所有的种子节点被选择的总代价。
- 目标是找到Ф(S)最大时的一个种子节点集合。 β(v|S)为增加一个新的种子节点v∈V到种子集合S⊆V时所获得的边际收益(marginal benefit gain)。

- Ф(v|S)为增加v到种子节点集合S中所获得的边际收益。

4. 命题和结论
- 命题1:如果收益函数β(•)是次模的,那么利润函数Ф(•)也是次模的。
- 命题2:收益函数β(•)在独立级联模型下是次模的。
有以上命题可得,Ф(•)在独立级联模型下也是次模的。但是和σ(•)的分布不一样,它可能不再单调。Ф(v|S)=β(v|S)-c(v)可能是负值。故利润最大化比影响最大化的挑战更大。选择种子节点最大化利润是一个无约束次模最大化问题[注1]。
三、种子选择算法
1. 简单贪心启发式算法
1).简述
如果每个节点的效益相同,直觉的选择:针对每种可能的种子集大小运行一种影响最大化算法。但是当种子节点的选择成本不同时,这种方式将失效(大多数现有的影响最大化算法都无法通过种子选择中的成本来区分节点)。如果最有影响力的节点的成本很高(例如,受欢迎的用户可能需要更多激励措施才能成为“种子”),则所选种子集的总利润可能会很低,甚至是负数。
2). 算法1
种子集初始化为∅。在每次迭代中,如果通过从非种子节点V\S中选择新种子获得的最大边际利润增益Ф(v|S)为正,则贪婪启发式会将相应的节点添加到S。否则,这意味着无法通过添加任何新种子来进一步增加利润,因此该算法将停止并返回种子集S。(过程类似爬山算法)

3). 一个例子
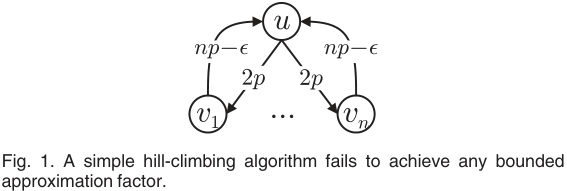
上图中有n+1个节点,2n条边。传播的概率被设定为pu,vi=2p并且pvi,u=np-ε,1≤i≤n,ε>0。
- 当节点u被选择为唯一的种子节点,每个节点被激活的概率是2p,所以收益Ф({u})=1+2np-1=2np。
- 当节点vi被选为唯一的种子节点,节点u被激活的概率是np-ε,u被激活后,剩下的节点vj被激活的概率是2p。因此收益Ф({u})=1+(np-ε)(1+2(n-1)p)-1=(np-ε)(1+2(n-1)p),p<1/2(n-1)。(即:收益=vi选择的代价+激活u的概率*(vj选择的代价+剩下的vj的个数*vj激活的概率))
- 一方面,当1+2(n-1)p<2,有Ф({vi})<Ф({u})。如果要应用简单的贪心算法,u是首先被选择的节点。对于任意的节点vi,Ф({u,vi})=2+2(n-1)p-2=2(n-1)p,意味着Ф(vi|{u})=2(n-1)p-2np=-2p<0。因此,贪心算法将在选择u后停止并返回S={u},其收益为Ф({u})=2np。
- 另一方面,当节点v1,v2,…,vn被选为种子,节点u被激活的概率是1-(1-np+ε)n(1-总的不被激活的概率)。Ф(V{u})=n+1-(1-np+ε)n-n=1-(1-np+ε)n。让p=1/n2并且ε=1/(4n2)。然后有Ф({u})=2/n和Ф(V{u})=1-(1-1/(2n))2n。当n→ ∞,有2/n→ 0和Ф(V{u}) → 1-1/e。因此,简单贪心算法的性能可能比最优解任意差,并且没有任何有界近似值。
2. 双重贪心算法(Double Greedy Algorithms)
1). 简述
Buchbinder等提出了双重贪婪算法来解决非约束次模函数具有强逼近保证的无约束子模最大化问题。确定性双重贪婪算法产生1/3近似,而随机性双重贪婪算法产生1/2近似。算法2以空集S和以社交网络的整个节点集初始化的集T开头。它们以任意顺序遍历网络中的所有节点,以确定是否将它们包括在S和T中。算法完成后,必须保持S=T,这就是选择的种子集。每个节点的决策基于将u添加到S的边际收益:Ф(S∪{u})-Ф(S)=Ф(u|S);从T中移除u的边际收益:Ф(T{u})-Ф(T)=-Ф(u|T\{u}))。在确定性方法中,如果每个节点u添加到S产生的边际利润收益高于从T移除的收益,则将u添加到S中,反之则将u从T中移除(第5-8行)。在随机化方法中,每个节点u被加入S的概率为Ф(u|S)/(Ф(u|S)-Ф(u|T\{u})),从T中移出的概率为:-Ф(u|T\{u})/(Ф(u|S)-Ф(u|T\{u}))。
2). 算法2
通常在双重贪婪算法中,初始化S、T为S0、T0,且∅∈S0∈T0∈V,并且检查 T0\S0 中的节点来决定是否将他们包含在集合S和T中。

3. 通过迭代修剪进行热启动
1). 一个例子(双重贪心算法)
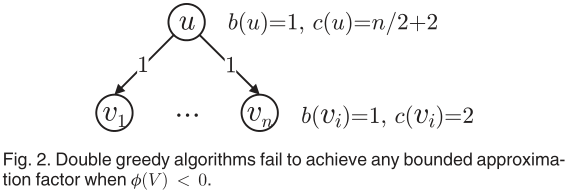
- 定理1提供了算法2的理论保证,但是Ф(V)≥0却是不切实际的,因为它意味着选择所有的节点作为种子节点都是有收益的,但是这在病毒式营销中是不现实的。
- 在图2中有n+1个节点(n>3),n条边。传播概率pu,vi =1,收益b(u)=1、b(vi)=1。种子选择的代价c(u)=n/2+2,并且对于vi来讲c(vi)=2。Ф(V)=(n+1)-(n/2+2+2n)=-(3n)/2-1<0。
- 假定算法2初始化S=∅并且T=V,并以u,v1,v2,…,vn的顺序遍历节点。在首次迭代中,我们有Ф(u|S)=Ф({u})=β({u})-c(u)=n+1-(n/2+2)=n/2-1。同时,-Ф(u|T\{u})=-(β(V)-β(V\{u})-c(u))=-((n+1)-n-(n/2+2))=n/2+1。因此,u从T退出以至于S=∅并且T=V\{u}。在第二次迭代中,Ф(v1|S)=β({v1})-β(∅)-c(c1)=1-2=-1,并且-Ф(v1|T\{v1})=-(β(V\{u})-β(V\{u,v1})-c(v1))=-(n-(n-1-2))=1。通过算法2,v1从T移出,相似的,vi也从T移出(r->r+)。因此,算法2最后返回S=∅,此时的Ф(S)=0。然而,我们已经知道Ф({u})=n/2-1>0.当n→∞时,有Ф({u})→∞。当Ф(V)<0时,确定性双贪婪算法的性能可能会比最优解任意差,并且没有任何有界近似值。
2). 改进
为解决上诉问题(会比最优解任意差),我们扩展了定理1的结果,以在弱得多的条件下维持相同的近似保证。我们首先提出一种减少搜索空间以最大化利润函数的方法。我们的策略是找到必须选择为种子的节点,并消除最优解中无法选择为种子的节点。给定收益函数Ф(•),我们定义两个节点集合A1={v:Ф(v|V\{v})>0}、B1={v:Ф(v|∅)≥0}。由于Ф(•)的次模性,A1⊆B1 空间Ω1=[A1,B1]包含所有的集合S,S满足A1⊆S⊆B1(从集合角度想象该空间)。
3). 算法3
使用迭代的策略减小空间Ω1=[A1,B1],由于A1中的节点必须包含在任何全局最大化的节点(any global maximizer:最优解中的节点)中,缩减B1为B2={v:Ф(v|A1)≥0}。相似地,由于V\B1的节点不能被包括在任何全局最大的节点中,我们可以扩展A1到A2={v:Ф(v|B1\{v})>0}。Ω2=[A2,B2]比Ω1更小。重复以上操作,直到A和B无法进一步变宽和变窄。

注解:
- 不受约束的次模最大化问题:典型的扩散模型下的影响函数是次模和单调。但是,本文中定义的利润函数是次模的,但不一定是单调的。
- 有关定理或者证明详情可见原文。
本文只是个人对论文的较为核心的算法做出的理解和记录,对后面部分的算法分析还未深入了解,故未做记录。如有理解不到位之处欢迎批评指正。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!