python实现美国国家气候数据中心NCDC预处理,按年重采样为年度数据,并保存为Excel格式
最近学习了处理气象数据NCDC 的过程,在这里记录并分享一下,由于刚开始学相关知识,文中有疏漏和不足,还请多见谅。
4.3更 摸了好久,决定还是更新一下,主要是稍微改了一点点代码,把其他列的数据也处理了,顺便添了一些站点信息,最后附上我处理好的数据。
目录
前言
一、处理步骤
1 获取待处理数据
(1)NCDC数据获取
(2)NCDC数据处理为xlsx格式
2 处理数据过程
二、完整代码
三、代码说明
1.处理CSV格式数据
2.添加经纬度等信息
前言
本文实现内容:对于格式转换后的NCDN数据(按年份保存的站点xlsx格数数据),将每年的站点数据按年重采样的各要素数据(气温、降水、气压等),并添加站点列,最按年后保存到一张Excel表中。
下面用图来表示
这里是待处理的数据,包含1990-2020共31个文件夹:
每个文件夹下有几百个当年站点数据的Excel表文件,以1990年的文件为例:
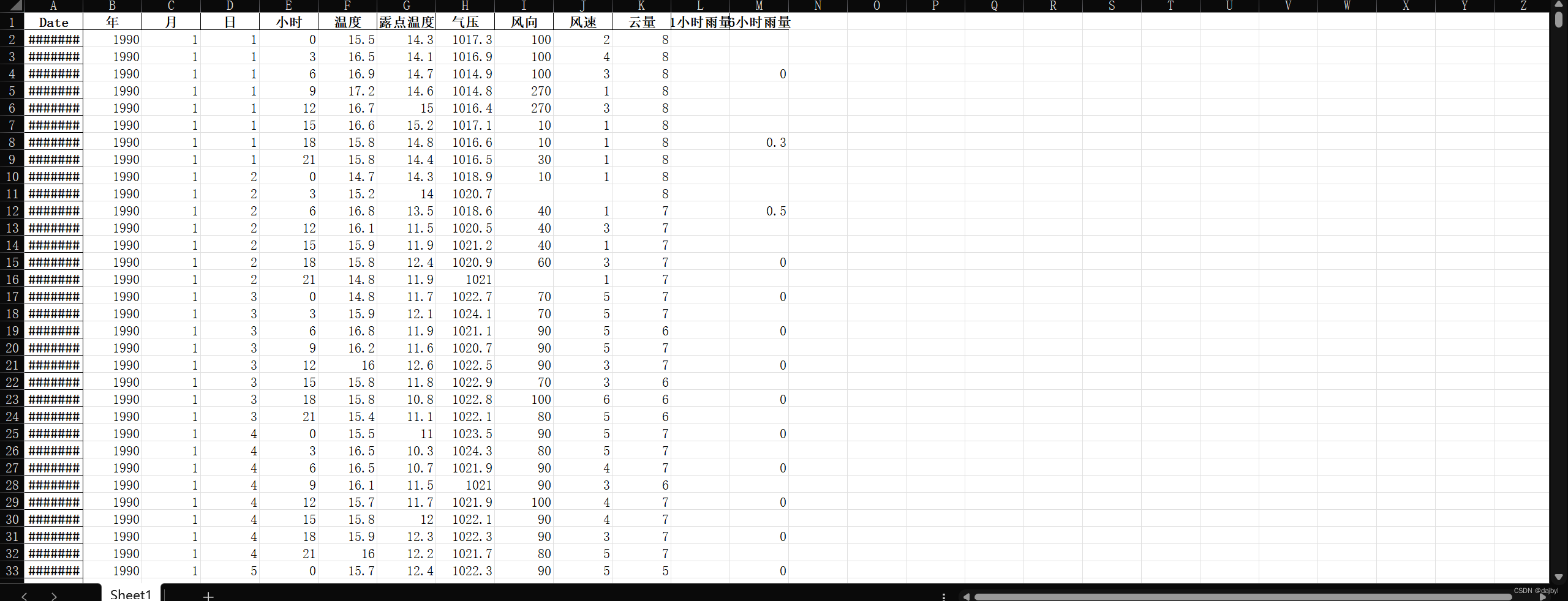
每个站点Excel表中又有几千行记录数据:
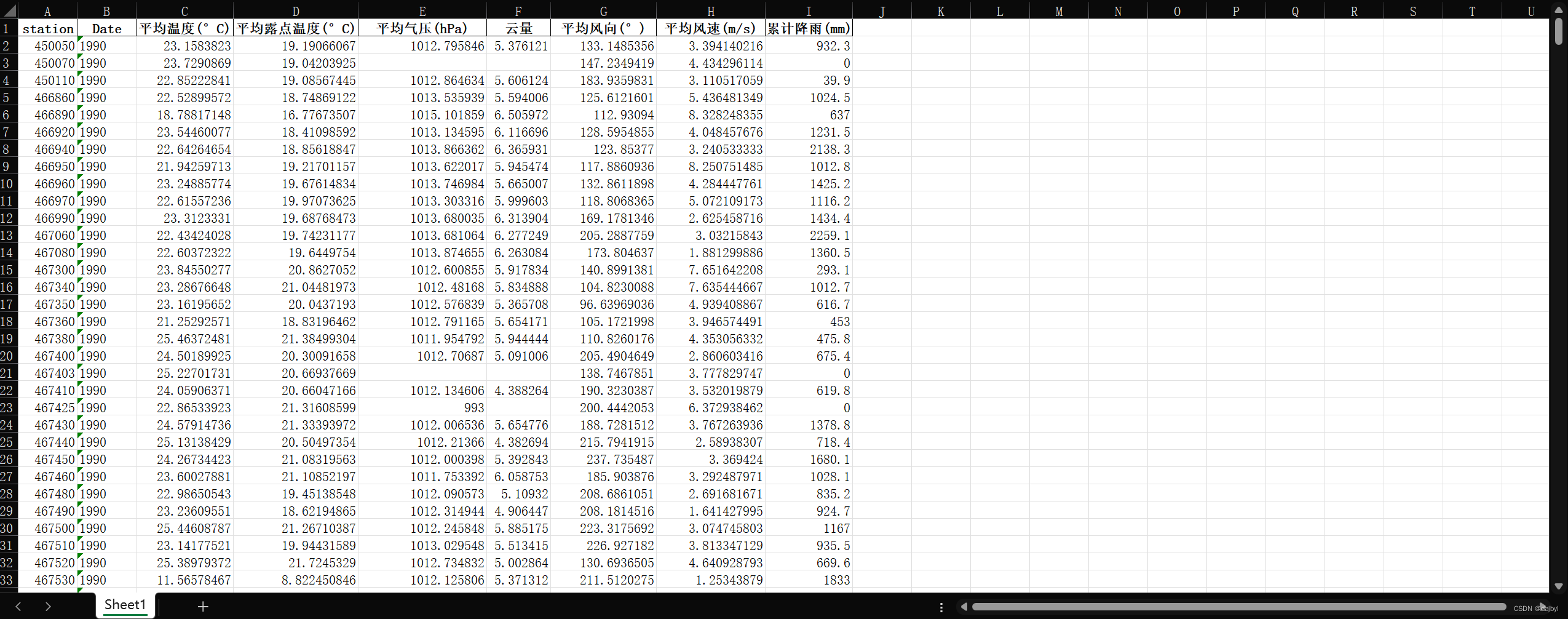
接下来是处理后的数据,这些站点数据的几千行记录数据被按年重采样到一行,然后再将每年的几百行站点数据保存到一张表中,最终保存为31个Excel表,以处理后的1990年的Excel表为例:
一、处理步骤
1 获取待处理数据
(1)NCDC数据获取
数据获取可参考:【数据分享】1942-2021全国400多个气象站气候数据 - 知乎
数据介绍可参考:ncdc气象数据格式介绍
(2)NCDC数据处理为xlsx格式
关于数据格式转化的代码,推荐参考文章:NCDC气象数据的提取与处理(二):python批量转换isd-lite数据为xlsx 写的非常详细,我也是参考这位大佬的文章注意:在进行处理前,请保证按照这篇文章将格式进行转换,得到待处理的Excel数据再进行下面的步骤
2 处理数据过程
(1)导入包
import os
import pandas as pd
import numpy as np
from tqdm import tqdm # 可视化进度,非必须
pandas、numpy、tqdm需要使用pip安装
(2)设置路径
folderPath = r"E:\b\exp\data\preData\NCDCxlsx"
outputPath = r"E:\b\exp\data\preData\TEST"
folerPath为待处理数据保存的路径,outputPath为最终保存处理好的路径
(3)遍历年份文件及里面的站点文件
nullStationDir = {} # 字典保存站点数据不足的站点文件
folders = os.listdir(folderPath) # 获取上级文件路径下的所有年份文件夹
# 以年为单位遍历
for folder in folders:fileList = [] # 当年所有站点文件的绝对路径列表nullStationList = [] # 当年数据不足的站点文件列表if os.path.splitext(folder)[-1] == "": # 通过后缀判断文件是否为文件夹# 获取年份文件夹下所有站点文件的绝对路径,并保存到列表fileList中for root, _, files in os.walk(f"{folderPath}\\{folder}"): for file in files:if os.path.splitext(file)[-1] == '.xlsx':fileList.append(os.path.join(root, file))
fileList保存当年文件夹下的所有站点数据的绝对路径
(4)设置处理后数据的列名
# 初始化一个空的数据框用于之后向里面添加站点数据,根据需要修改,输出Excel你所需的列名,名称可更改year = pd.DataFrame(columns=['station', 'Date', '平均温度(°C)', '平均露点温度(°C)', '平均气压(hPa)', '云量', '平均风向(°)', '平均风速(m/s)', '累计降雨(mm)'])
根据自己需要计算的数据设置列名,一般是只需平均温度和累计降雨,我这里每列都处理了,如果只需要平均温度和累计降水,则只需设为[‘station’, ‘Date’, ‘平均温度(°C)’, ‘累计降雨(mm)’],同时需要对(7)处理过程进行一定修改
(5)通过列表遍历读取站点数据
# 获得站点文件个数# total = len(fileList)# 通过站点文件的列表遍历年份文件夹下的所有站点文件# for idx, station in enumerate(fileList, 1):for stationPath in tqdm(fileList, desc=f"{folder}年站点"):stationCode = os.path.split(stationPath)[-1][0:6] # 站点文件绝对路径->站点文件名->站点号# print("*" * 10, stationCode, f'({idx}/{total})', "*" * 10)# 读取站点文件,根据需要选取列,这里的列名是输入的Excel里面列名,名称不可改data = pd.read_excel(stationPath, usecols=['Date', '温度', '1小时雨量', '6小时雨量', '露点温度', '气压', '风向', '风速', '云量']) data = data.set_index('Date') # 设置日期为索引便于重采样
这里usecols参数是待处理站点数据的列名,所以不能改,不过个数根据year设置的列来选取,比如year只需要平均温度和累计降水,则只需选取[‘Date’, ‘温度’, ‘1小时雨量’, ‘6小时雨量’]
另外这里注释掉的是不用tqdm包时手动打印处理进度
(6)检查站点记录数据缺失情况
# 按月检查站点文件test = data.resample('m').mean() # 这里以月重采样,如果需要更精细的,如站点每天都要求有数据,m改成dif test.shape[0] != 12:nullStationList.append(stationPath)continue
一些站点数据会有较多缺失,比如有的站点缺失几个月的记录
这里我是按月重采样,来检查是否每月都能保证有记录数据,处理的较粗糙,也可以选取其他重采样频率,但更精细的频率会过滤掉更多站点数据
这里数据不足的站点的绝对路径会被保存到列表中

(7)按年重采样处理
# 将数据按日期重采样到年尺度并计算年均值(温度、露点温度、气压、云量),同时删除不需要列,最后将日期转换为年格式meanData = data.resample('Y').mean()meanData.drop(columns=["1小时雨量", "6小时雨量", "风向", "风速"], axis=1, inplace=True)meanData.index = meanData.index.strftime("%Y")
将待处理数据的温度、露点温度、气压、云量按年取平均。注意这里云量应该不是取平均,因为原始NCDC数据云量的值是离散的代码表示(具体参考ncdc气象数据格式介绍),具体我也不清楚怎么处理。
# 将数据按日期重采样到年尺度并计算年累加值(1小时雨量、6小时雨量),同时删除不需要的温度,最后将日期转换为年格式sumData = data.resample('Y').sum()sumData.drop(columns=["温度", "露点温度", "气压", "风向", "风速", "云量",], axis=1, inplace=True)sumData.index = sumData.index.strftime("%Y")
同时累加1小时和6小时,一个站点只会有6小时或1小时中的一种记录方法,所以这里不会有影响
# 去除无风天后,将数据按日期重采样到年尺度并计算年均值(风向、风速),同时删除不需要列,最后将日期转换为年格式windData = data[~data["风向"].isin([np.nan,0])]windMeanData = windData.resample('Y').mean()windMeanData.drop(columns=["1小时雨量", "6小时雨量", "温度", "露点温度", "气压", "云量"], axis=1, inplace=True)windMeanData.index = windMeanData.index.strftime("%Y")
关于风速和风向是如何进行年重采样的,这方面我没找到相关计算资料,所以按照自己理解,去除无风天后再按年取平均来计算的
(8)处理后按列合并
# 将均值表和累加表横向关联,合并为新的表,并将1小时和6小时降雨量两列合并,同时添加新的站点列df = pd.merge(meanData.reset_index(), windMeanData.reset_index())df = pd.merge(df, sumData.reset_index())df['降雨'] = df['1小时雨量'] + df['6小时雨量']df.drop(columns=["1小时雨量", "6小时雨量"], axis=1, inplace=True)df.insert(0, 'station', int(stationCode)) # 新建一列用于存储站点信息,注意转换数据类型 str->int
(9)处理后按行合并
# 重命名数据框列名,要与year一致df = df.rename(columns={"温度": "平均温度(°C)", "露点温度": "平均露点温度(°C)", "气压": "平均气压(hPa)", "风向": "平均风向(°)", "风速": "平均风速(m/s)", "降雨": "累计降雨(mm)"})# 在每轮循环中将站点数据纵向关联合并到year数据框year = pd.concat([year, df])
这里重命名必须要与上面设置的year列名一致
(10)保存数据
# 将合并完的年数据重置索引,并将日期转换为整型df = df.reset_index(drop=True)df['Date'] = df['Date'].astype(int)# 保存当年不足数据nullStationDir[folder] = nullStationListsavePath = f'{outputPath}\\{folder}.xlsx' # 保存路径path可自定义更改with pd.ExcelWriter(savePath, mode='w') as writer:year.to_excel(writer, encoding='utf-8', index=False)
这里记录不足数据是通过字典保存的,keys为年份,values为对应年份数据不足站点的路径的列表
二、完整代码
给出数据处理部分的完整代码,注释比较详细,有问题和建议欢迎评论~
更新代码:
import os
import pandas as pd
import numpy as np
from tqdm import tqdmfolderPath = r"E:\b\exp\data\preData\NCDCxlsx"
outputPath = r"E:\b\exp\data\preData\TEST"def Preprocess(folderPath, outputPath):nullStationDir = {} # 字典保存站点数据不足的站点文件folders = os.listdir(folderPath) # 获取上级文件路径下的所有年份文件夹# 以年为单位遍历for folder in folders:fileList = [] # 当年所有站点文件的绝对路径列表nullStationList = [] # 当年数据不足的站点文件列表if os.path.splitext(folder)[-1] == "": # 通过后缀判断文件是否为文件夹# 获取年份文件夹下所有站点文件的绝对路径,并保存到列表fileList中for root, _, files in os.walk(f"{folderPath}\\{folder}"): for file in files:if os.path.splitext(file)[-1] == '.xlsx':fileList.append(os.path.join(root, file)) # 初始化一个空的数据框用于之后向里面添加站点数据,根据需要修改,输出Excel你所需的列名,名称可更改year = pd.DataFrame(columns=['station', 'Date', '平均温度(°C)', '平均露点温度(°C)', '平均气压(hPa)', '云量', '平均风向(°)', '平均风速(m/s)', '累计降雨(mm)'])# 获得站点文件个数# total = len(fileList)# 通过站点文件的列表遍历年份文件夹下的所有站点文件# for idx, station in enumerate(fileList, 1):for stationPath in tqdm(fileList, desc=f"{folder}年站点"):stationCode = os.path.split(stationPath)[-1][0:6] # 站点文件绝对路径->站点文件名->站点号# print("*" * 10, stationCode, f'({idx}/{total})', "*" * 10)# 读取站点文件,根据需要选取列,这里的列名是输入的Excel里面列名,名称不可改data = pd.read_excel(stationPath, usecols=['Date', '温度', '1小时雨量', '6小时雨量', '露点温度', '气压', '风向', '风速', '云量']) data = data.set_index('Date') # 设置日期为索引便于重采样# 按月检查站点文件test = data.resample('m').mean() # 这里以月重采样,如果需要更精细的,如站点每天都要求有数据,m改成dif test.shape[0] != 12:nullStationList.append(stationPath)continue# 将数据按日期重采样到年尺度并计算年均值(温度、露点温度、气压、云量),同时删除不需要列,最后将日期转换为年格式meanData = data[~data["风向"].isin([np.nan,0])]meanData = data.resample('Y').mean()meanData.drop(columns=["1小时雨量", "6小时雨量", "风向", "风速"], axis=1, inplace=True)meanData.index = meanData.index.strftime("%Y")# 将数据按日期重采样到年尺度并计算年累加值(1小时雨量、6小时雨量),同时删除不需要的温度,最后将日期转换为年格式sumData = data.resample('Y').sum()sumData.drop(columns=["温度", "露点温度", "气压", "风向", "风速", "云量",], axis=1, inplace=True)sumData.index = sumData.index.strftime("%Y")# 去除无风天后,将数据按日期重采样到年尺度并计算年均值(风向、风速),同时删除不需要列,最后将日期转换为年格式windData = data[~data["风向"].isin([np.nan,0])]windMeanData = windData.resample('Y').mean()windMeanData.drop(columns=["1小时雨量", "6小时雨量", "温度", "露点温度", "气压", "云量"], axis=1, inplace=True)windMeanData.index = windMeanData.index.strftime("%Y")# 将均值表和累加表横向关联,合并为新的表,并将1小时和6小时降雨量两列合并,同时添加新的站点列df = pd.merge(meanData.reset_index(), windMeanData.reset_index())df = pd.merge(df, sumData.reset_index())df['降雨'] = df['1小时雨量'] + df['6小时雨量']df.drop(columns=["1小时雨量", "6小时雨量"], axis=1, inplace=True)df.insert(0, 'station', int(stationCode)) # 新建一列用于存储站点信息,注意转换数据类型 str->int# 重命名数据框列名,要与year一致df = df.rename(columns={"温度": "平均温度(°C)", "露点温度": "平均露点温度(°C)", "气压": "平均气压(hPa)", "风向": "平均风向(°)", "风速": "平均风速(m/s)", "降雨": "累计降雨(mm)"})# 在每轮循环中将站点数据纵向关联合并到year数据框year = pd.concat([year, df])# 将合并完的年数据重置索引,并将日期转换为整型df = df.reset_index(drop=True)df['Date'] = df['Date'].astype(int)# 保存当年不足数据nullStationDir[folder] = nullStationListsavePath = f'{outputPath}\\{folder}.xlsx' # 保存路径path可自定义更改with pd.ExcelWriter(savePath, mode='w') as writer:year.to_excel(writer, encoding='utf-8', index=False)return nullStationDirnullData = Preprocess(folderPath, outputPath)旧代码(不需要就不用点开了):
import os
import pandas as pd
import numpy as np
def Preprocess(path, save):"""TODO: 函数用于将处理好的NCDC数据文件(转换为Excel格式的NCDC数据)进行预处理。预处理包括:计算温度均值、累计降雨量和时间重采样。Args:path: 包含年份文件夹的上级文件夹路径save: 需要保存的文件夹路径Returns: 保存好的Excel文件"""folders = os.listdir(path) # 获取上级文件路径下的所有年份文件夹print(folders)for folder in folders: # 以年为单位进行遍历处理fileList = []if os.path.splitext(folder)[-1] == "": # 通过后缀判断文件是否为文件夹# 获取年份文件夹下所有站点文件的绝对路径,并保存到列表fileList中for root, dirs, files in os.walk(f"{path}\\{folder}"):for file in files:if os.path.splitext(file)[-1] == '.xlsx':fileList.append(os.path.join(root, file))# 初始化一个空的数据框用于之后向里面添加站点数据year = pd.DataFrame(columns=['station', 'Date', '温度', '降雨'])# 获得站点文件个数total = len(fileList)# 通过站点文件的列表遍历年份文件夹下的所有站点文件for idx, station in enumerate(fileList, 1):stationCode = os.path.split(station)[-1][0:6] # 获取站点编号,站点文件如:450010-99999-2000.xlsxprint("*" * 10, stationCode, f'({idx}/{total})', "*" * 10)data = pd.read_excel(station, usecols=['Date', '温度', "1小时雨量", "6小时雨量"]) # 筛选所需要的列,可自行修改data['Date'] = pd.to_datetime(data['Date'])data = data.set_index('Date') # 设置日期为索引便于重采样test = data.resample('m').mean()if test.shape[0] != 12:print(f'{folder}年{stationCode}站点数据不足!')continue# 将数据按日期重采样到年尺度并计算年均值,同时删除不需要的降雨列,最后将日期转换为年格式meanData = data.resample('Y').mean()meanData.drop(columns=["1小时雨量", "6小时雨量"], axis=1, inplace=True)meanData.index = meanData.index.strftime("%Y")# 将数据按日期重采样到年尺度并计算年累加值,同时删除不需要的温度,最后将日期转换为年格式sumData = data.resample('Y').sum()sumData.drop(columns='温度', axis=1, inplace=True)sumData.index = sumData.index.strftime("%Y")# 将均值表和累加表横向关联,合并为新的表,并将1小时和6小时降雨量两列合并,同时添加新的站点列df = pd.merge(meanData.reset_index(), sumData.reset_index())df['降雨'] = df['1小时雨量'] + df['6小时雨量']df.drop(columns=["1小时雨量", "6小时雨量"], axis=1, inplace=True)df.insert(0, 'station', int(stationCode)) # 新建一列用于存储站点信息,注意转换数据类型 str->int# 在每轮循环中将站点数据纵向关联合并到year数据框year = pd.concat([year, df])print(f'{folder}年{stationCode}站点数据添加成功!')# 将合并完的年数据重置索引,并将日期转换为整型year = year.reset_index(drop=True)year['Date'] = year['Date'].astype(int)'''数据框格式如下:--------------------------------------------station Date 温度 降雨0 450070 2000 24.029553 790.61 450110 2000 22.805576 0.02 466860 2000 22.452576 598.3.. ... ... ... ...409 599850 2000 27.177576 1552.1410 599950 2000 27.919750 2180.2411 599970 2000 27.797267 1021.8--------------------------------------------温度:℃ 降雨:mm'''# 保存数据savePath = rf'{save}\\{folder}.xlsx' # 保存路径path可自定义更改with pd.ExcelWriter(savePath, mode='w') as writer:year.to_excel(writer, encoding='utf-8', index=False)print(f"保存{folder}年数据成功")# 执行数据处理函数
Preprocess(r'E:\b\exp\data\preData\NCDCxlsx', r'E:\b\exp\data\preData\preNCDC')三、代码说明
1.处理CSV格式数据
如果处理csv数据可尝试以下修改:
①要处理的是csv数据,修改25行和37行代码,将后缀判断改为".csv",读取方式改为"read_csv"
# if os.path.splitext(file)[-1] == '.xlsx':
if os.path.splitext(file)[-1] == '.csv':# data = pd.read_excel(station, usecols=['Date', '温度', "1小时雨量", "6小时雨量"])
data = pd.read_csv(station, usecols=['Date', '温度', "1小时雨量", "6小时雨量"])但是要注意内容、格式、命名等应该与之前excel一样,内容参考NCDC,列名如下:
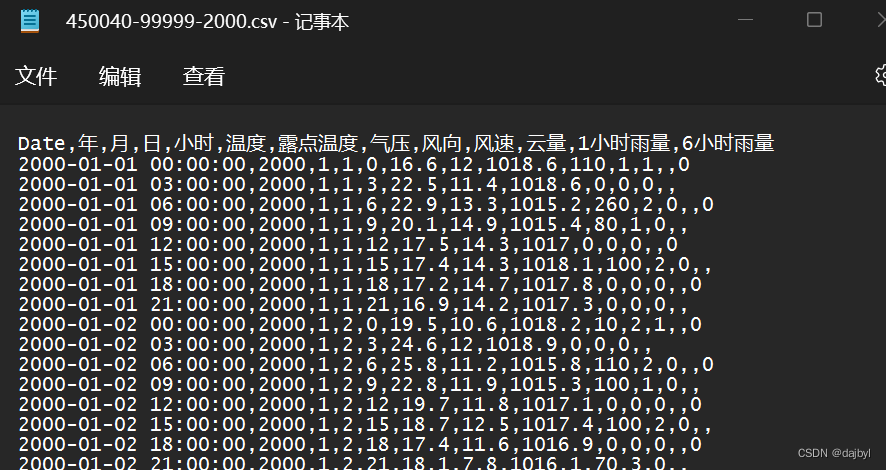
如果只是列名不同,也是再37行修改为对应列名就行。如果内容不一样,代码就无法使用了,中间部分都需要修改,不过处理思路比较简单(数据读取为DataFrame格式进行处理,数据必须有日期列以用于时间重采样,再将DataFrame转为需要的格式)。
②处理后保存为csv
如果保存格式需要csv,对84-86行修改如下,这里我自己试的时候用"utf-8"编码会出现乱码。
# with pd.ExcelWriter(savePath, mode='w') as writer:
# year.to_excel(writer, encoding='utf-8', index=False)
# print(f"保存{folder}年数据成功")year.to_csv(savePath, encoding='utf_8_sig', index=False)
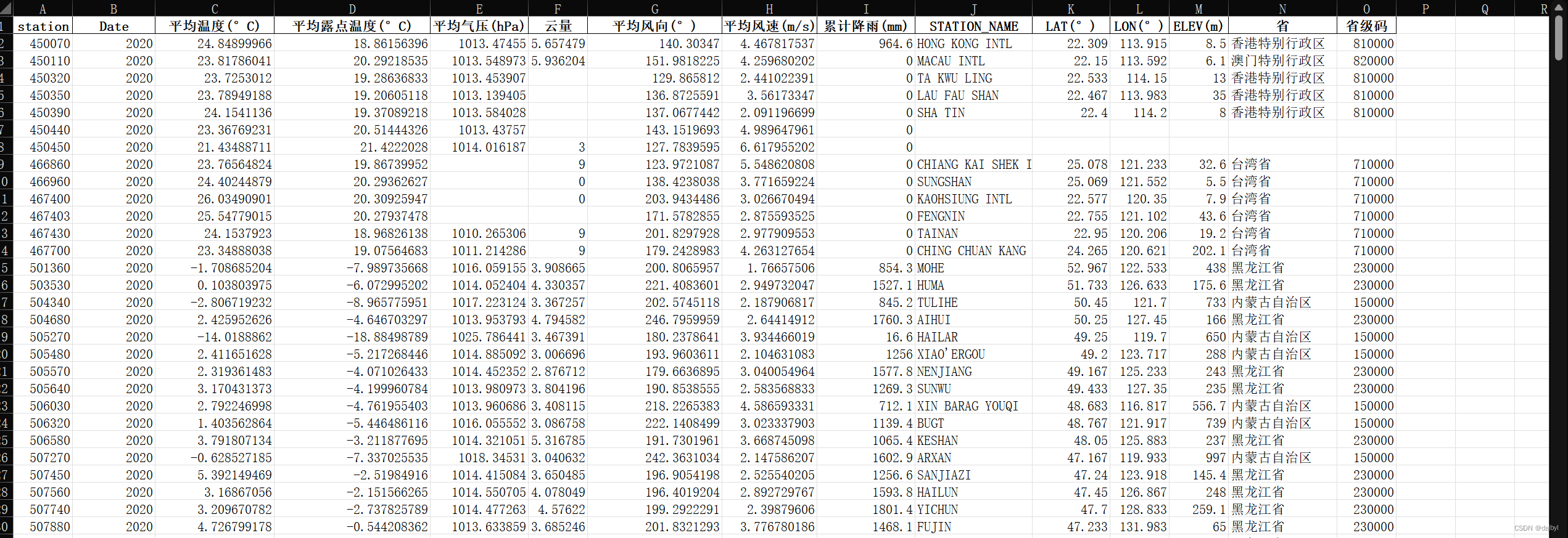
print(f"保存{folder}年数据成功")2.添加经纬度等信息
在重采样处理后的基础上加上关于站点的信息,主要添加了经纬度、高程、省份及省份码,有部分站点(大概20个左右)在岛屿上不好获得省份,下面是大致效果:
最后分享下我处理的1990-2020年的数据
注意:仅供参考,不保证准确性,且未经过数据清洗
链接:https://pan.baidu.com/s/1xN5UcA7EcsQoMaJ4zt6-lg?pwd=mfu5
提取码:mfu5
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!