2021-09-01 学习笔记:Python爬虫、数据可视化
2021-09-01 学习笔记:Python爬虫、数据可视化
结于2021-09-07;
内容来自 成都工业大学 数字媒体专业实训;
主要内容:
- PyCharm开发Python脚本的基础配置;
- Python爬虫基础:正则匹配(re)、网页获取(urllib)、网页解析(bs4/BeautifulSoup)
- 数据存储:数据库操作(sqlite3/pymysql)、简单excel编辑(xlwt);
- 数据可视化:Flask:Web框架、 Echarts、 WordCloud
内容很丰富,老师讲的很好;
笔记内容仅对个人知识进行补充,详细课程可以自行学习;
开发环境
Python无法进行代码加密;
Python安装及环境变量设置:
- 环境变量:Python目录 和 该目录下的Scripts工具目录;
PyCharm IDE;
- 这里使用anaconda提供的conda环境,管理Pyhton版本,没有单独安装和配置Pyhton,这里新初始化的环境是Python3.9;
- 初始化一个python工程项目;
- IDE右上角,或
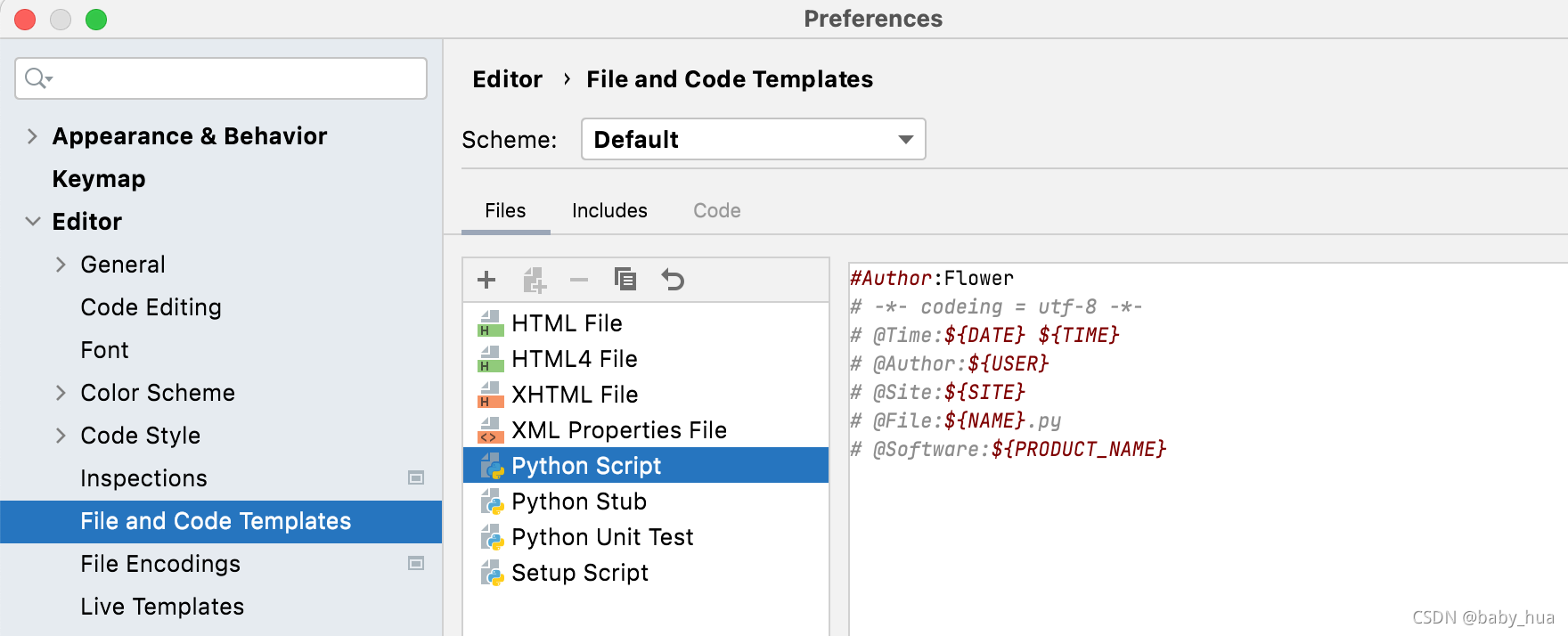
cmd+,打开设置,Editor->Font,可以设置字体; - Editor->File and Code Templates,可以设置模块通用的模板;
- 检查当前项目的Python解释器路径,如果与新建项目时不符,则需要进行解释器路径的配置;

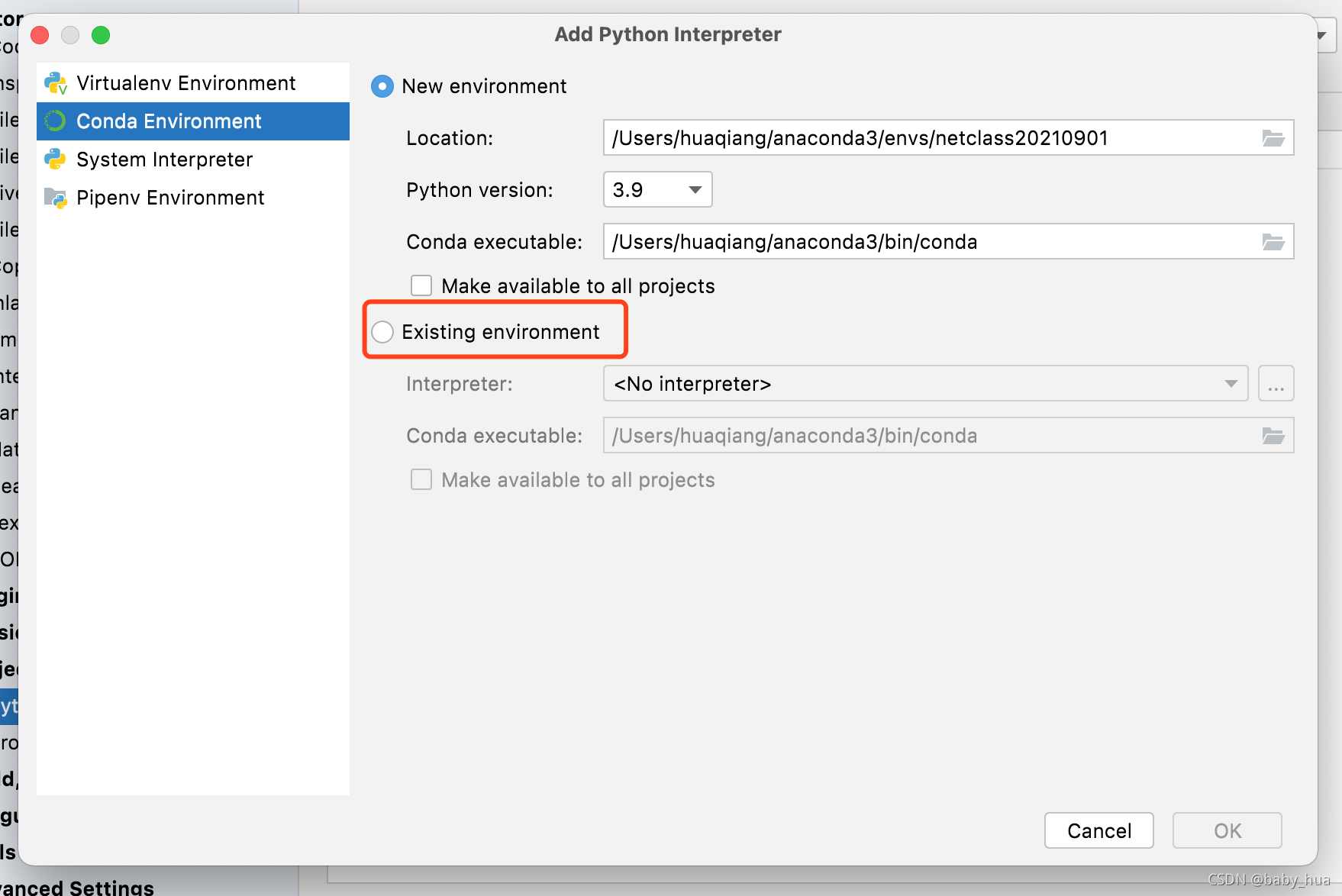
- 这里第一张图,也是当前环境安装Python扩展库的地方(还可以指定安装源),目前显示了已将安装的扩展库;
- 模块通用的模板示例如下:
#Author:Flower
# -*- coding = utf-8 -*-
# @Time:${DATE} ${TIME}
# @Author:${USER}
# @Site:${SITE}
# @File:${NAME}.py
# @Software:${PRODUCT_NAME}
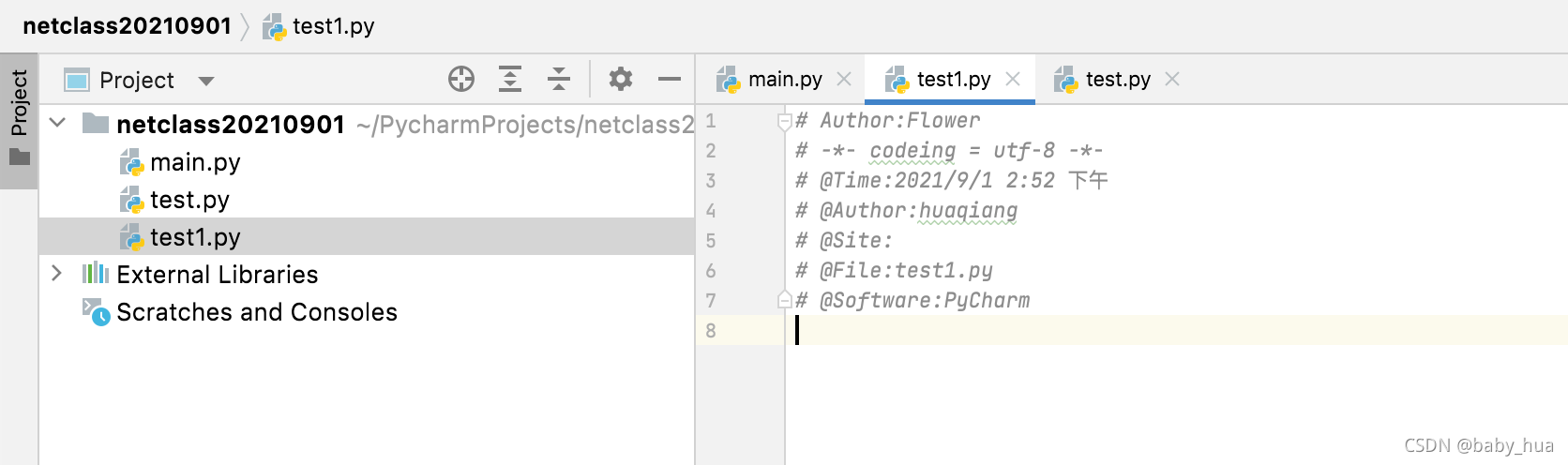
- 新建一个脚本,打印一条语句,右键选中脚本文件,选择Run即可运行程序;
- 双击文件名进行文件编辑
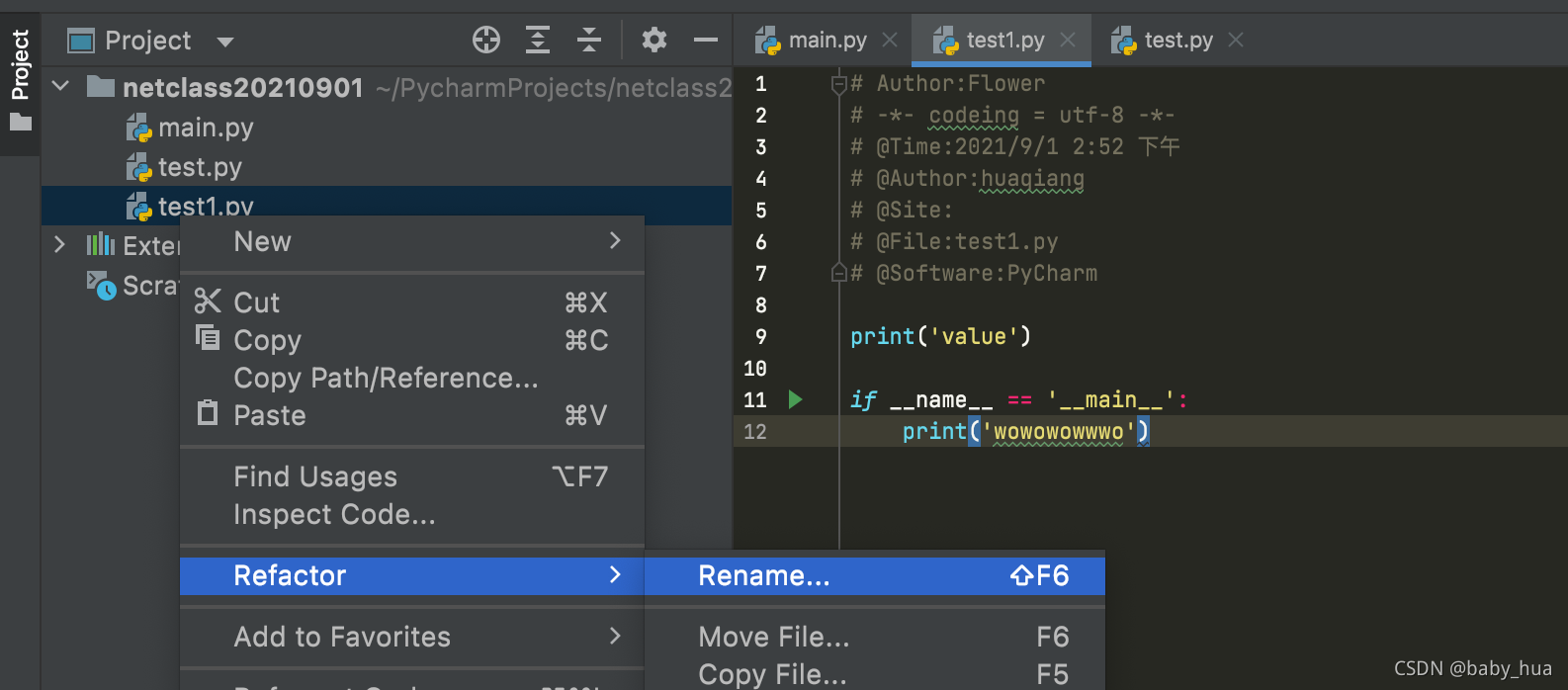
- 文件名修改方式如下:
Pyhton基础
- 查看关键字:
import keyword
keyword.kwlist
# ['False', 'None', 'True', '__peg_parser__', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']- 逻辑与或非:
and/or/not - 判断在不在序列:
in/not in - 判断是不是类实例:
is/is not
import random
random.randint(0, 2) # 0,1,2 随机一个- break continue pass
- Python3默认是UTF-8编码,所有字符串都是unicode字符串;
其他基础内容参考Learning Python的学习笔记,这里略过;
Python爬虫基础
需求:
- 爬取豆瓣电影Top250,信息;

爬虫基础知识:
- 根据用户需求定向,自动抓取互联网信息的脚本;
百度指数可以对比关键字的检索量,如
电影天堂,爱奇艺;电影天堂通过网络资源引流,广告变现;天眼查通过整合信息,卖会员变现;
请求网页:
- cookies:用户信息
- user-agent:浏览器信息
涉及到的库:
import sys
import re # 正则匹配
import urllib.request, urllib.error # 获取网页
import sqlite3 # sqlite数据库操作
import bs4 # 解析网页
from bs4 import BeautifulSoup # 解析网页
import xlwt # excel操作Python3 的urllib 整合了urllib2的功能,现在只需要用urllib即可;
测试的网址:
httpbin.org这是github的一个测试网络请求和响应的网址;
urllib
import urllib.request
import urllib.parse
import urllib.errorclass HQUrlLibBlocking:def __init__(self):self.headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'}def getRequestParseHtmlFromUrlSimple(self, url):"""进行get请求,直接打开网页,获取网页信息"""try:response = urllib.request.urlopen(url, timeout=15)print(response.status)html_r = response.read().decode('utf-8')return html_rexcept urllib.error.URLError as e:print(e)def getRequestParseHtmlFromUrl(self, url):"""进行get请求,直接打开网页,获取网页信息"""try:request = urllib.request.Request(url, headers=self.headers, method='GET')response = urllib.request.urlopen(request, timeout=15)print(response.status)html_r = response.read().decode('utf-8')return html_rexcept urllib.error.URLError as e:print(e)def postRequestParseHtmlFromUrlSimple(self, url, params):"""进行post请求,未携带header浏览器信息,获取网页信息"""try:data = bytes(urllib.parse.urlencode(params), encoding='utf-8')response = urllib.request.urlopen(url, data=data, timeout=15)print(response.status)html_r = response.read().decode('utf-8')return html_rexcept urllib.error.URLError as e:print(e)def postRequestParseHtmlFromUrl(self, url, params):"""进行post请求,获取网页信息"""try:data = bytes(urllib.parse.urlencode(params), encoding='utf-8')request = urllib.request.Request(url, data=data, headers=self.headers, method='POST')response = urllib.request.urlopen(request, timeout=15)print(response.status)html_r = response.read().decode('utf-8')return html_rexcept urllib.error.URLError as e:print(e)if __name__ == '__main__':content_get = HQUrlLibBlocking().getRequestParseHtmlFromUrl('http://httpbin.org/get')print(content_get)postParams = {'hello':'world'}content_post = HQUrlLibBlocking().postRequestParseHtmlFromUrl('http://httpbin.org/post',postParams)print(content_post)print('over')
BeautifulSoup4
with open('./testBS4.html','rb') as file:html = file.read()# 将复杂的HTML文档转换成复杂的树形结构,每个节点都是Python对象bs = BeautifulSoup(html, 'html.parser')print(bs.title)print(bs.li)print(bs.title.string)print(bs.li.attrs)t_list = bs.find_all('li')print(t_list)- 将复杂的HTML文档转换成复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种;
- Tag:html文档标签对象,默认只拿到第一个;
- NavigableString:Tag包裹的内容
.string,Tag的属性.attrs; - BeautifulSoup:整个Document文档对象;
- Comment:注释,会不包含注释符号,只显示其中文字,是一种特殊的NavigableString;
bs.head.contentsbs.body.childrent_list = bs.find_all('li') # 字符串匹配
t_list = bs.find_all(re.compile('li')) # 字符串包含def class_is_exists(tag):return tag.has_attr('class')
t_list = bs.find_all(class_is_exists) # 符合条件 t_list = bs.find_all(id='head')
t_list = bs.find_all(class_=True)
t_list = bs.find_all('div', class_=True)
t_list = bs.find_all(text='hao123')
t_list = bs.find_all(text=['hao123','地图','贴吧'])t_list = bs.find_all('a', limit=2)# 选择器
t_list = bs.select('title') # 通过tag查找
t_list = bs.select('.class') # 通过class查找
t_list = bs.select('#id') # 通过id查找
t_list = bs.select("a[name='haha']") # 通过属性查找
t_list = bs.select('head > title') # 通过子标签查找
t_list = bs.select('.class1 ~ .class2') # 通过兄弟标签查找t_list[0].get_text()正则表达式
判断字符串是否符合一定的模式
re模块:
re.search():在一个字符串中搜索匹配正则的第一个位置,返回match对象re.match():从一个字符串的开始位置匹配正则,返回match对象re.findall():搜索字符串,以列表类型返回全部能匹配到的子串re.split():将一个字符串按照正则匹配结果进行分割,返回列表re.finditer():搜索字符串,返回一个匹配结果的迭代类型,迭代元素是match对象re.sub():在一个字符串中替换所有匹配正则的子串,返回替换后的字符串
re模式:
- 标志修饰符控制匹配模式;
- 多个表示按位
|来设置,如re.I | re.M; re.I:使匹配对大小写明暗re.L:做本地化识别(locale-aware)匹配re.M:多行匹配,影响^ $re.S:使.匹配包括换行在内的所有字符re.U:更具Unicode字符集解析字符,影响\w \W \b \Bre.X:该标志通过给予更灵活的格式,便于理解正则
import re# 使用模式对象
pattern_o = re.compile(r"AA") # r字符串中不会转义字符
match_o = pattern_o.search("ahwuefauwefhaw")# 不使用模式对象
match_o = re.search(r"AA", "ahwuefauwefhaw")# 字符替换
re.sub(r"a","A", ahwuefauwefhaw) # 匹配到a 用A替换正则表达式知识,可参考《正则校验-我需要的正则表达式知识》
示例程序
findLink = re.compile(r'')
findImgSrc = re.compile(r', re.S) # ?非贪婪
findTitle = re.compile(r'(.*)') # 贪婪
...bs = BeautifulSoup(html, "html.parser")
# 使用bs缩小范围到item
for item in bs.find_all('div', class_ = 'item'):item = str(item)# 在item的字符串中 通过正则进行匹配link = re.findall(findLink, item)[0]titles = re.findall(findTitle, item)# 其他判断 或字符串替换处理if len(titles) == 2:c_title = titles[0]o_title = titles[1] 数据保存
- excel操作
- 数据库操作
excel表保存
- 利用Python库
xlwt将数据写入excel表格;
import xlwtworkbook = xlwt.Workbook(encoding='utf-8') # 创建workbook
worksheet = workbook.add_sheet('sheet1') # 创建工作表
worksheet.write(0,1, 'hello') # 第0行 第1列 单元格写入 内容
worksheet.save('./test.xls') # 保存到excel这个和Pandas对excel的操作比,还是有点low;
sqlite数据库保存
- 数据类型(支持这五个数据类型相关的亲和类型):
- NULL
- INTEGER:带符号整数,根据值的大小存储在1 2 3 4 6 8字节中
- REAL:浮点数,存储为8字节浮点数字
- TEXT:文本字符串,使用数据库编码存储
- BLOB:blob数据,完全根据它的输入存储
import sqlite3# 打开或创建数据库
connect = sqlite3.connect('douban_top.db')
# 获取游标
cursor = connect.cursor()# 建表SQL
sql = """create table company (id int primary key not null autoincrement,name text not null,age int not null,address char(50),salary real);"""
# 执行
cursor.execute(sql)
# 提交
connect.commit()# 查询SQL
sql_select = """select id,name,age,address,salary from company;
"""
cursor_res = cursor.execute(sql_select)
for row in cursor_res:print('id', row[0])print('name', row[1])print('age', row[2])print('address', row[3])print('salary', row[4])# 关闭
cursor.close()
cursor_res.close()
connect.close()其他数据库基本操作参考《SQL-深入浅出》
mysql数据库操作
from pymysql import *connect = connect(host='127.0.0.1', port=3306, user='usre',password='password',database='hq_test_local',charset='utf-8')cursor = connect.cursor()cursor.execute('SELECT * FROM %s'%(xm_provinces))
results = cursor.fetchall()# 其他操作基本一致# 这个函数用来判断表是否存在
def table_exists(self,table_name): sql = "show tables;"self.cur.execute(sql)tables = [self.cur.fetchall()]table_list = re.findall('(\'.*?\')',str(tables))table_list = [re.sub("'",'',each) for each in table_list]if table_name in table_list:return 1 #存在返回1else:return 0 #不存在返回0如果是使用Navicat Premium进行表结构创建,也可以查看具体表结构创建的SQL:
- 选中表,右键存储SQL文件,仅结构;
- 保存的sql文件中就有对应的创建表的SQL语句;
DROP TABLE IF EXISTS "user";
CREATE TABLE "user" ("id" integer PRIMARY KEY AUTOINCREMENT,"name" text(40,1),"age" integer(4)
);
数据可视化
- Flask:Web框架
- Echarts
- WordCloud
Flask
Flask:
- 是用Python基于Werkzeug工具箱编写的轻量级web开发框架,面向需求简单的小应用;
- Flask本身相当于一个内核,其他功能基本都需要第三方扩展,如可以用Flask-extension加入ORM、窗体验证工具、文件上传、身份验证等;
- Flask没有默认使用的数据库,可以使用MySQL,也可以使用NoSQL;
- WSGI 采用
Werkzeug(路由模块) - 模板引擎适应
Jinja2;
关于另一个fastAPI,也可以尝试使用;
快速网站框架:
- 所有Flask程序都必须创建一个程序实例;
- 客户端要获取资源时,一般会通过浏览器发起HTTP请求;
- Web服务器使用名为WEB服务器网关接口的WSGI(Web Server Gateway Interface)协议,把来自客户端的请求交给Flask程序实例;
- 一个HTTP请求,对应Server端一个处理逻辑;
- Flask使用Werkzeug来做路由分发(URL请求和视图函数之间的对应关系);根据每个URL请求,找打具体的视图函数;
- 在Flask程序中,路由一般是通过程序实例的装饰器实现;通过调用视图函数,获取到数据后,把数据传入HTML模板文件中,模板引擎负责渲染HTTP响应数据,然后右Flask返回响应数据给浏览器,最后浏览器显示;
Django是一个大而全的框架,更适合工程化开发;
Flask扩展包:
- Flask-SQLLalchemy 操作数据库
- Flask-migrate 管理迁移数据库
- Flask-Mail 邮件
- Flask-WTF 表单
- Flask-script 插入脚本
- Flask-Login 认证用户状态
- Flask-RESTful 开发REST API工具
- Flask-Bootstrap 集成前端框架
- Flask-Moment 本地化日期和时间
pip install flask
from flask import Flaskapp = Flask(__name__)# 装饰器的作用是将路由映射到视图函数index
@app.route('/')
def index():return 'Hello world!'if __name__ == "__main__":# 启动web服务器app.run()项目目录:
app.py # hello world
static # 网页静态资源
templates # html模板flask的 Debug Mode开启
修改代码后,刷新界面就可以看到相应的变化;
# 1.修改当前执行项目的configuration,开启Flask的debug模式# 2.代码设置
app.run(debug=True)
注:第一步如果创建的是Flak项目,才会有,如果是调用Flask库进行的调试,直接使用代码设置就可以了;
flask路由参数解析
# 字符串参数
@app.route("/user/" )
def welcome(name):return name# 数字参数: int float
@app.route("/user/" )
def welcome(id):return str(id)注:路由路径不可以重复;
html模板-Jinja2
pip install jinja2,安装Flask时应该已经带了;
from flask import Flask, render_templateapp = Flask(__name__)@app.route("/")
def welcome():return render_template('index.html')if __name__ == '__main__':app.run(debug=True)相应的
index.html是定义在templates目录下的html文件;
html的动态渲染
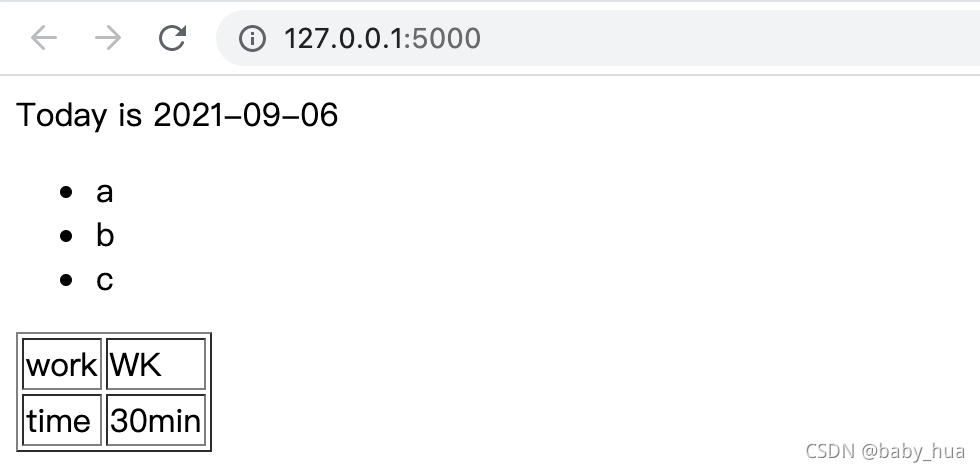
import datetime
from flask import Flask, render_templateapp = Flask(__name__)# 三种变量
@app.route("/")
def welcome():# 普通变量time = datetime.date.today()# 列表names = ['a', 'b', 'c']# 字典task = {"work":"WK", "time":"30min"}return render_template('index.html', var=time, list=names, task=task)if __name__ == '__main__':app.run(debug=True)<div>Today is {{ var }}div><ul>
{% for name in list %}<li>{{ name }}li>{% endfor %}ul>
<table border="1">
{% for key, value in task.items() %}<tr><td>{{key}}td><td>{{value}}td>tr>{% endfor %}table>
表单提交
from flask import Flask, render_template, request
app = Flask(__name__)# 表单提交页面
@app.route("/test/register")
def register():# templates目录的文件结构return render_template('test/register.html')# 表单提交请求,必须显式指定接收方式
@app.route("/test/regist", methods=['POST', 'GET'])
def regist():# 通过request获取请求信息request.method # 请求方式request.form # form表单字典# templates目录的文件结构return render_template('test/regist.html') # 提示:注册成功或失败if __name__ == '__main__':app.run(debug=True)
动态获取请求url根路径:
<form method="post" action="{{ url_for('test/regist') }}"><label>姓名:<input type="text" name="name">label><label>年龄:<input type="text" name="age">label><input type="submit" value="Submit">form>
网页模板
下载静态网页模板进行使用:
- 模板之家;
- BOOTSTAPMADE;
- colorlib;
步骤:
- index.html 放入 templates目录
- assets 文件夹 放入 static目录,便于CDN服务器分发;
- 在index.html中 修改引入assets资源的路径;
- 在index.html中的,保留并修改实际使用部分,其余部分删除即可;
其他:
列表展示
@app.route('/movie')
def movie():datalist = []con = sqlite3.connect("movie.db")cur = con.cursor()sql = "select * from movie250"data = cur.execute(sql)for item in data:datalist.append(item)cur.close()con.close()return render_template("movie.html", movies = datalist)
<table class="table table-striped"><tr><td>排名td><td>名称td>tr>{% for movie in movies %}<tr><td>{{movie[0]}}td><td><a href="{{movie[2]}}" target="_blank">{{movie[1]}}a>td>tr>{% endfor %}
table> 拓展:如何支持分页?
Echarts
图表展示
- 在assets/js目录下,导入echarts.min.js,也可以通过npm来安装;
- 编写图表展示的html页面,并引入js,
;
详细示例和教程参考官网 文档-配置项 即可;
图表代码可以copy,也可以download完整的图表html;
@app.route('/score')
def score():score = []num = []con = sqlite3.connect("movie.db")cur = con.cursor()sql = "select score, count(score) from movie250 group by score"data = cur.execute(sql)for item in data:score.append(item[0])num.append(item[1])cur.close()con.close()return render_template("scrore.html", score = score, num = num)
xAxisdata: {{score|tojson}}
seriexdata: {{num}}
这里如果 score 是一个字符串数组,为避免从数据库读出的字符串包含特殊字符,可以使用
tojson进行转换;
WordCloud应用
词云:
- 词频高的展示文字大一些;
- 文档中提供了许多示例,可以参考;
- 如果要支持中文,需要安装
pip install jieba进行中文分词;
这是文档中的一个常见示例的实现代码:
import osfrom os import path
from wordcloud import WordCloud# get data directory (using getcwd() is needed to support running example in generated IPython notebook)
d = path.dirname(__file__) if "__file__" in locals() else os.getcwd()# Read the whole text.
text = open(path.join(d, 'constitution.txt')).read()# Generate a word cloud image
wordcloud = WordCloud().generate(text)# Display the generated image:
# the matplotlib way:
import matplotlib.pyplot as plt
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")# lower max_font_size
wordcloud = WordCloud(max_font_size=40).generate(text)
plt.figure()
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()# The pil way (if you don't have matplotlib)
# image = wordcloud.to_image()
# image.show()
我们的网站嵌入词云:
# pip install jieba
import jieba # 分词
# pip install matplotlib
from matplotlib import pyplot as plt # 绘图 保存
# pip install wordcloud
from wordcloud import WordCloud # 词云from PIL import Image # 图片处理的库
import numpy as np # 矩阵运算
import sqlite3 # 数据库# 获取文本数据
con = sqlite3.connect('movie.db')
cur = con.cursor()
sql = 'select instruction from movie250'
data = cur.execute(sql)
text = ''
for item in data:text = text + item[0]
cur.close()
con.close()
# 分词处理
cut = jieba.cut(text)
cut_str = ' '.join(cut)# 遮罩生成词云
img = Image.open(r"./一张白底的形状图.png")
img_array = np.array(img)wc = WordCloud(background_color='white',mask=img_array,font_path="msyh.ttc"
)
wc.generate_from_text(cut_str)# 绘制图片
fig = plt.figure(1)
plt.imshow(wc)
plt.axis('off') # 不显示坐标轴
# plt.show()
plt.save('./static/assets/img/wordcloud.png', dpi=500)
Wordcloud安装不成功的处理:
- 从非官网Python扩展包下载wordcloud模块的whl文件,名如
wordcloud-1.6.0-cp37m-win32.whl,注意这里cp后边是python版本;- 使用命令
pip install wordcloud-1.6.0-cp37m-win32.whl进行安装;- 另外,如果用的是conda的环境,注意记得切换;
WordCloud 配置
WordCloud:
font_pathstring 字体路径widthint 输出画布宽,默认400像素heightint 输出画布高,默认200prefer_horizontalfloat 默认0.9 词语水平方向排版的概率,相当于垂直方向排版概率0.1masknd-array 默认None 绘制词云使用的二维遮罩,全白的部分不会被绘制;scalefloat 默认1 表示画布缩放的比例min_font_sizeint 默认4 显示上最小的字体大小max_font_sizefont_stepint 默认1 字体步长,大于1时,运算会快些,但误差也大;max_wordsnumber 默认200, 要显示词的最大个数stopwordsset of strings 空时使用内置默认的集合,用于设置需要屏蔽的词;background_color生成图片的背景颜色mode默认RGB;可以设置为RGBA,若此时background_color非空,则背景透明relative_scalingfloat 默认0.5 表示词频与字体大小的关联性color_func生成新颜色的函数,为空时,使用默认的方法;regexp正则表达式,用于分割输入的文本collocationsbool 默认True,表示是否包括两个词的搭配colormap默认viridis,给每个单词随机分配颜色,若指定color_func,这被忽略;fit_words(frequencies)根据词频生成词云generate(text)根据文本生成词云generate_from_frequencies(frequencies)根据词频生成词云generate_from_text(text)根据文本生成词云to_array()转化为 numpy arrayto_file(filename)输出到文件
Over!
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!