Tensorflow2.0:实战LeNet-5识别MINIST数据集
LeNet-5模型
1990 年代提出的LeNet-5使卷积神经网络在当时成功商用,下图是 LeNet-5 的网络结构图,它接受32 × 32大小的数字、字符图片,这次将LeNet-5模型用来识别MINIST数据集中的数字,并在测试集中计算其识别准确率。
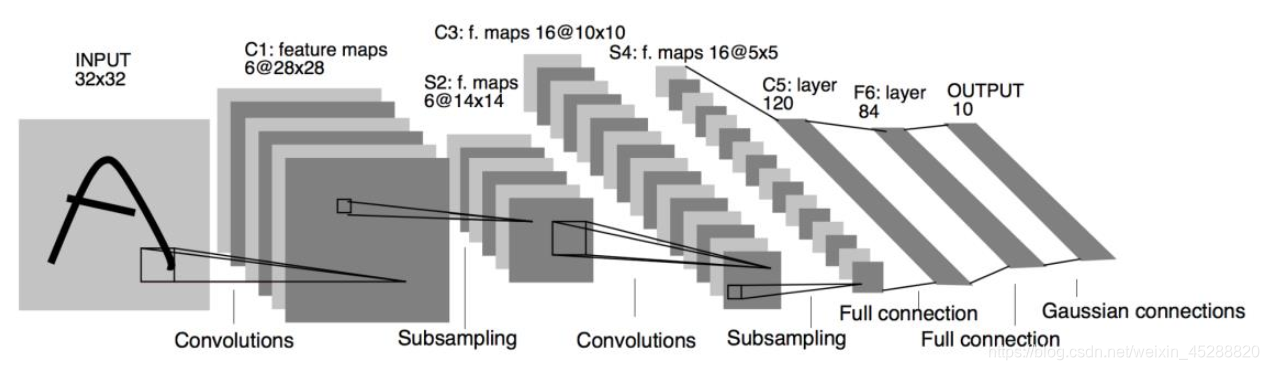
根据上图的网络结构,可以得出下图的模型结构图:
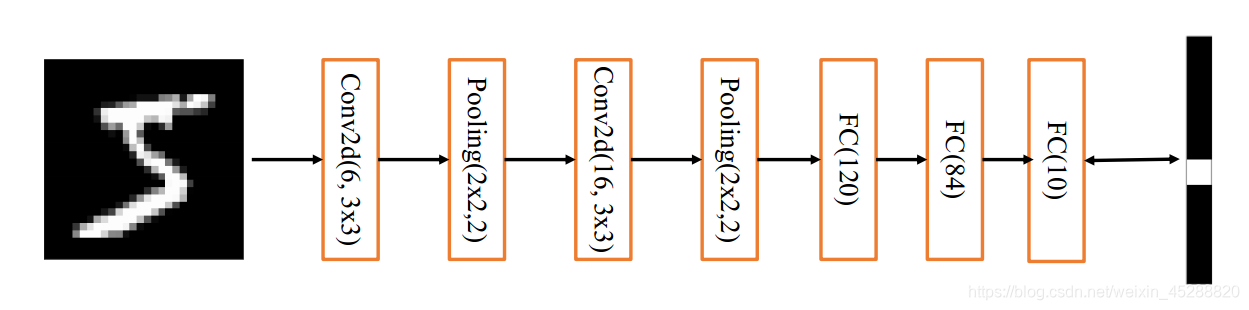
完整代码示例
第一部分:数据集的加载与预处理
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets # 导入经典数据集加载模块
# 加载 MNIST 数据集
(x, y), (x_test, y_test) = datasets.mnist.load_data() # 返回数组的形状
# 将数据集转换为DataSet对象,不然无法继续处理
train_db = tf.data.Dataset.from_tensor_slices((x, y))
# 将数据顺序打散
train_db = train_db.shuffle(10000) # 数字为缓冲池的大小
# 设置批训练
train_db = train_db.batch(512) # batch size 为 128
#预处理函数
def preprocess(x, y): # 输入x的shape 为[b, 32, 32], y为[b]# 将像素值标准化到 0~1区间x = tf.cast(x, dtype=tf.float32) / 255.# 将图片改为28*28大小的x = tf.reshape(x, [-1, 28 * 28])y = tf.cast(y, dtype=tf.int32) # 转成整型张量y = tf.one_hot(y, depth=10)return x, y
# 将数据集传入预处理函数,train_db支持map映射函数
train_db = train_db.map(preprocess)
# 训练20个epoch
train_db = train_db.repeat(20)
# 以同样的方式处理测试集
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_db = test_db.shuffle(1000).batch(512).map(preprocess)
第二部分:构建LeNet-5模型
from tensorflow.keras import Sequential
from tensorflow.keras import layers,losses, optimizers
def main():network = Sequential([layers.Conv2D(6, kernel_size=3, strides=1), # 第一个卷积层, 6 个 3x3 卷积核layers.MaxPooling2D(pool_size=2, strides=2), # 高宽各减半的池化层layers.ReLU(), # 激活函数layers.Conv2D(16, kernel_size=3, strides=1), # 第二个卷积层, 16 个 3x3 卷积核layers.MaxPooling2D(pool_size=2, strides=2), # 高宽各减半的池化层layers.ReLU(), # 激活函数layers.Flatten(), # 打平层,形成一维向量,方便全连接层处理layers.Dense(120, activation='relu'), # 全连接层, 120 个节点layers.Dense(84, activation='relu'), # 全连接层, 84 节点layers.Dense(10) # 全连接层, 10 个节点])# 构建网络模型,给输入X的形状,其中4为随意的BatchSizenetwork.build(input_shape=(4, 28, 28, 1))# 统计网络信息# print(network.summary())optimizer = optimizers.Adam(lr=1e-4)loss_all = []# 创建损失函数的类,在实际计算时直接调用类实例即可criteon = losses.CategoricalCrossentropy(from_logits=True)for step, (x, y) in enumerate(train_db):# 将输入张量x的shape[512.784]变成[x = tf.reshape(x, (-1, 28, 28))with tf.GradientTape() as tape:# 插入通道维度,=>[b,28,28,1]x = tf.expand_dims(x, axis=3)# 前向计算,获得10类别的预测分布,[b, 784] => [b, 10]out = network(x)# 将真实标签转化为one-hot编码,[b] => [b, 10]# 计算交叉熵损失函数,标量loss = criteon(y, out)# 自动计算梯度,关键看如何表示待优化变量grads = tape.gradient(loss, network.trainable_variables)# 自动更新参数optimizer.apply_gradients(zip(grads, network.trainable_variables))# step为80次时,记录并输出损失函数结果if step % 100 == 0:print(step, 'loss:', float(loss))loss_all.append(float(loss))# step为80次时,用测试集验证模型if step % 100 == 0:total, total_correct = 0., 0correct, total = 0, 0for x, y in test_db: # 遍历所有训练集样本# 插入通道维度,=>[b,28,28,1]x = tf.reshape(x, (-1, 28, 28))x = tf.expand_dims(x, axis=3)# 前向计算,获得10类别的预测分布,[b, 784] => [b, 10]out = network(x)# 真实的流程时先经过softmax,再argmax# 但是由于softmax不改变元素的大小相对关系,故省去pred = tf.argmax(out, axis=-1)y = tf.cast(y, tf.int64)y = tf.argmax(y, axis=-1)# 统计预测正确数量correct += float(tf.reduce_sum(tf.cast(tf.equal(pred, y), tf.float32)))# 统计预测样本总数total += x.shape[0]# 计算准确率print('test acc:', correct / total)第三部分 测试结果
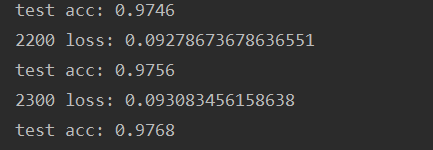
经过2300step迭代训练后,识别数字的准确率达到了97.68%
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!