新的换脸模型FaceShifter论文解读

论文地址:https://arxiv.org/pdf/1912.13457.pdf
前言
本文介绍了一种pipline模型, 用以抽取多维度的图片特征信息, 并自适应的完成FaceSwap任务. 整体模型分类两个部分, 第一部分基于AAD(Adaptive Attentional Denormalization, 自适应的注意力非正规化层)构建, 用以生成高保真度的Face Swapping图片; 第二部分则是名为HEAR-Net(Heuristic Error Acknowledging Refinement Network, 启发式错误察觉网络), 其作用为采用一个非常有效的trick解决换脸过程中的面部遮挡问题. 模型的两个部分所解决的问题即构成了论文的卖点: 生成高保真度的, 并且可处理面部遮挡的换脸图片.
Face Swapping的研究脉络可大略的分为三部分, 首先是最早的replacement-based works, 简单的对像素进行一一替换, 这显然对图片的角度和人的姿势要求很高. 之后一些3D-based works使用3D模型来处理图片的姿势问题, 这些模型在推断人脸的纹理, 重建人物肖像的时候非常有效, 但在执行Face Swap时又几乎不会考虑图片之间的素材差距, 比如面部的遮挡, 周围的打光和图像风格等; 也有一些工作收集了大量数据用于监督方式的遮挡识别, 但是模型很容易识别不出它从未见过的遮挡类型. 最后就是近年来的进步, 使用GAN来提升图片质量, 著名的DeepFakes就是一个代表作, 但DeepFakes只能处理特定数据之间的脸部交换; 因此后续的不可知face swapping提出了, 比如RSGAN, IPGAN, FSGAN等. 作者提出, 这些形形色色的GAN都不能自适应的进行特征融合, 因此往往结果不如人意. 所以模型的卖点也就出来了, **首先它可以自适应的抽取多维度特征, 其次它可以考虑图片之间的风格差异如灯光, 表情, 脸型等.

模型介绍
本文提出的模型是一个两阶段pipline模型, 第一阶段称为Adaptive Embedding Intergration Network(AEI-Net), 模型如下所示:
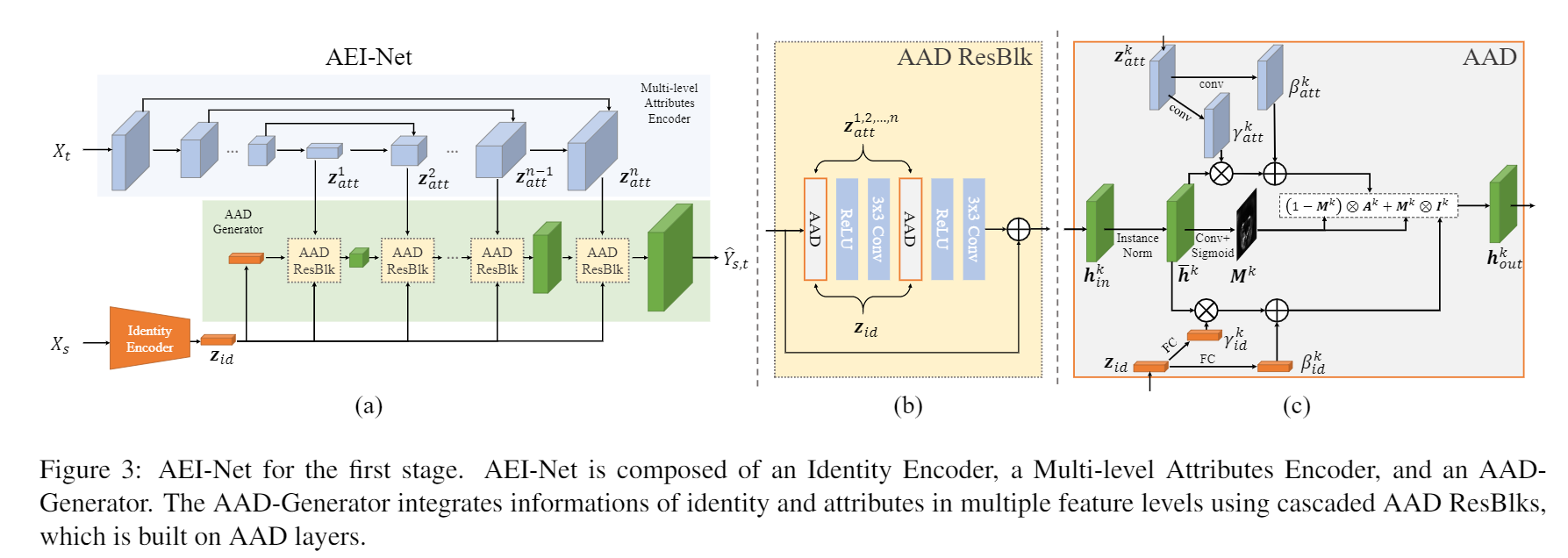
第一阶段:AEI-Net
不像那些只利用有限信息就完成换脸任务的框架,该框架中的第一部分设计了新型生成器网络AEI-Net 和新型的属性编码器——自适应注意力去正则化生成器 (AAD),从而自适应地整合了目标图像的所有属性以生成高保真的换脸图片。
图(a)为整个第一阶段架构。输入分别为source image 和target image。
AEI-Net主要包含三部分:身份编码器、多级属性编码器、自适应注意力去正则化生成器。
(1)身份编码器:使用了一个预训练的人脸识别模型作为身份编码器,身份编码就是全连接层之前的最后一层特征向量。作者认为2D模型比3DMM效果要好,因为训练的2D人脸数据集更大;
(2)多级属性编码器:属性包括姿态、表情、光照和背景,需比身份更多的空间信息。使用多级特征图代替原先的单向量设计,利用类似U-Net结构编码器进行提取。训练采用自监督:要求生成的脸和target脸有一样的属性,不需要任何标签;
(3)自适应注意力去正则化生成器(AAD-Generator):嵌入身份和属性的特征来生成新的合成人脸。之前直接进行特征拼接,会导致模糊的融合结果。本文受到SPADE和AdaIN的启发,利用去正则(Denormalization)来实现多级特征级别的特征嵌入。AAD层的一项关键设计是自适应地调整身份嵌入和属性嵌入的有效区域,以便他们可以参与脸部不同部位的合成与同步。
输入的XsXs和XtXt分别是source和target的图片, source图片提供需要换的脸, target提供换脸后的图片背景. 具体处理过程中, XsXs由预训练好的工具Identity Encoder抽取人脸特征Zid(Xs)Zid(Xs). XtXt则由一个类似于U-Net的网络提取多属性信息, 比如人的pose, 表情和打光等. 与以前的工作将这些特征作为一个Vector不同, 本文将这些特征视为相对独立的特征集合, 并且使用不同的feature map表示。因此,
Zatt(Xt)={Z1att(Xt),Z2att(Xt),...,Znatt(Xt)}Zatt(Xt)={Zatt1(Xt),Zatt2(Xt),...,Zattn(Xt)}
Zatt(Xt)Zatt(Xt)代表特征合集, nn代表特征的种类. 本文没有规定究竟有多少特征需要学习, 而是将nn直接定为8, 并在实验中讨论了学习到的特征.
接着就是AAD层, AAD层接收的是上文提取的两个ZZ, AAD层共有多层, 其层数为n. 每层的输入为之前层的输出, 初始的ZidZid, 和ZkattZattk. 在每一个AAD中, 前一层的输出hkhk会分别和ZidZid, 和ZkattZattk一对一的整合, 也就是Ak=γkatt⨂hk+βkattAk=γattk⨂hk+βattk, 其中γ和βγ和β是通过FC或者Conv运算分别得到的参数. 为了体现自适应的整合不同的特征信息, 作者提出了一个MkMk, 是由hkhk经过sigmodsigmod和卷积之后获得的. 作者认为这个MkMk代表了不同脸部不同部位的重要程度, 比如眼睛, 嘴等等.
AAD网络经过多层的特征融合, 最终会生成一个Y^s,tY^s,t, 也就是换脸之后的图像. 该图像的示意如下图:

可以看出最后一列的Y^s,tY^s,t已经非常优秀了, 但我们可以发现相比于原图XtXt, 有一些头发和链子的遮挡被忽略了. 这也就是第二部分网络Hear-Net要解决的问题, 遮挡.
第二阶段:HEAR-Net
Hear-Net的结构并不复杂, 类似于U-net. 实际完成的任务是重新恢复一张图片.
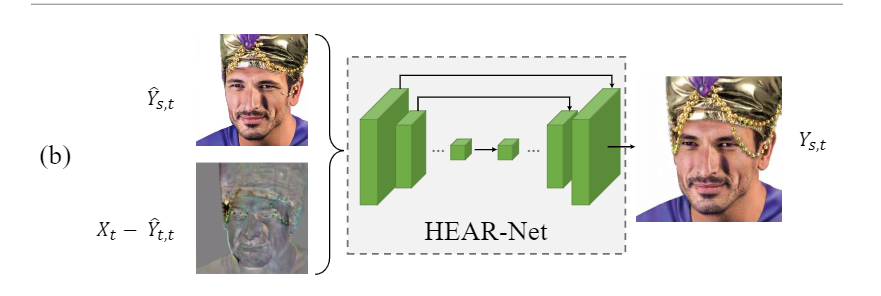
这来自作者的观察, 作者发现如果向他们训练好的AEI-net中输入XtXt, 所获得的结果和输入XsXs一样都会忽略一部分遮挡, 那么作者就可以通过对Y^t,tY^t,t和XtXt来简单的找到被忽略的遮挡信息. 使用类似U-net的结构, 可以更好的补充轮廓.
实验
(实验都懂肯定都挑自己最好的放在论文里
训练细节上, AEI-Net使用CelebA-HQ, FFHQ和VGGFace进行训练, HEAR-Net使用上述数据集前10%有遮挡的数据进行训练, 并随机采样了一批具有遮挡的数据.
测试则使用了FaceForensics++.
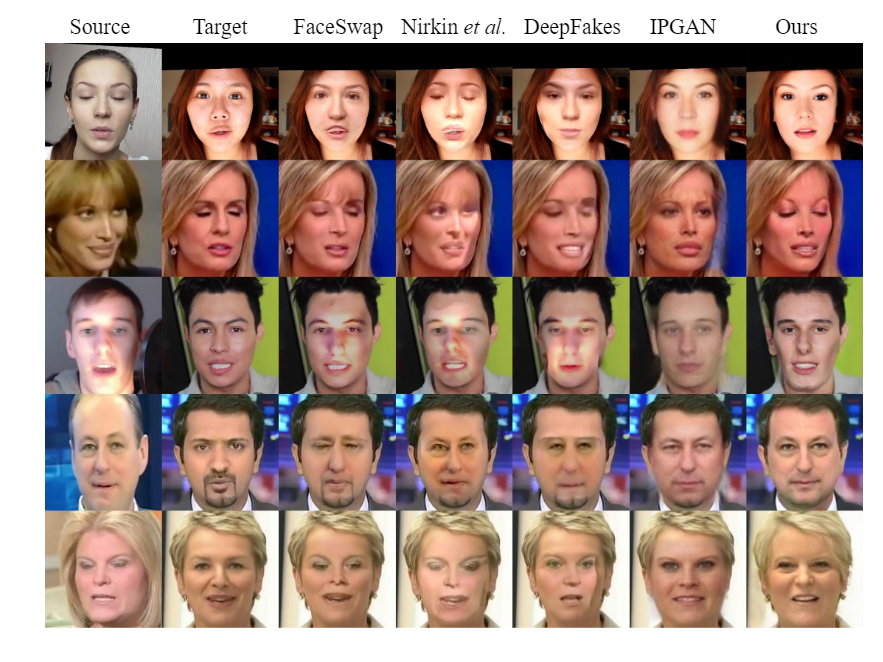
Quality test
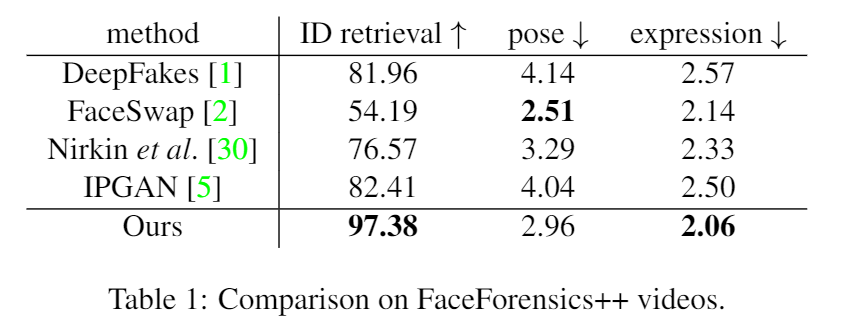
Quantity test
作者定义了三个基准值以评价模型的性能. ID-retrieval是用过人物识别工具在数据集中寻找和当前生成的照片最相似的一张, 然后判断它是否来自target视频中. pose和expression则计算了原图和生成图之间的L−2L−2距离
比较详细的解读:https://baijiahao.baidu.com/s?id=1664633435658216529&wfr=spider&for=pc
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!