使用Facebook的Pytorch的BigGraph从知识图谱中提取知识
机器学习使我们能够训练一个可以将数据转换为标签的模型,从而把相似的数据映射到相似或相同的标签。
例如,我们正在为电子邮件构建一个垃圾邮件过滤器。我们有很多电子邮件,其中一些标记为垃圾邮件,另一些标记为正常邮件(INBOX)。我们可以构建一个模型,该模型学习识别垃圾邮件。被标记为垃圾邮件的邮件在某种程度上类似于已经标记为垃圾邮件的邮件。
相似性的概念对于机器学习至关重要。在现实世界中,相似性的概念与某个主题相关,它取决于我们的知识。
另一方面,数学模型定义了相似性的概念。通常,我们将数据表示为多维向量,并测量向量之间的距离。
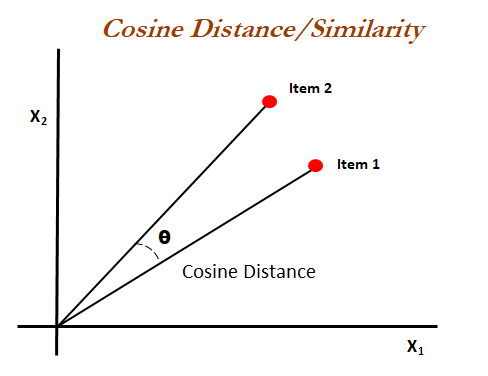
https://www.quora.com/Why-do-we-use-cosine-similarity-on-Word2Vec-instead-of-Euclidean-distance
特征工程是将我们对现实世界中的某个对象的知识转换为数字表示的过程。我们认为相似的对象转化为数字后的向量也会很靠近。
例如,我们正在估算房价。我们的经验告诉我们,房屋是由卧室的数量,浴室的数量,房龄,房屋面积,位置等来定义的。位于同一社区,具有相同大小和房龄的房屋的价格应该大致相同。我们将对房屋市场的了解转化为表征房屋的数字,并用它来估算房屋的价格。
不幸的
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!