python爬虫——Pyquery库
Pyquery库并非python标准库,所以需要下载:pip install pyquery
Pyquery是一个类似jquery(一个js库)的库,使用 lxml 进行快速 xml 和 html 操作。
利用它,我们可以直接解析 DOM 节点的结构,并通过 DOM 节点的一些属性快速进行内容提取。
1. 初始化Pyquery对象
初始化pyquery对象的方法有三种:文件名(filename)、网址(url)、字符串(text)
1.1 通过网址(url)初始化Pyquery对象
即,解析网址。在发起请求时注明编码集 如:encoding=“utf-8”
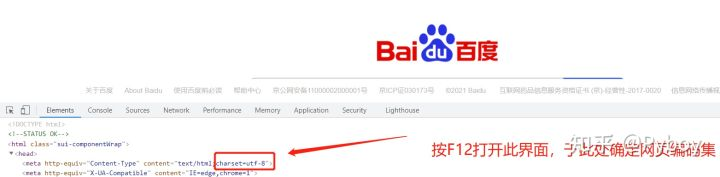
注意:一定要把协议补全了,这里的url就跟你在浏览器的网址栏里看到的一样。
from pyquery import PyQuery as pq
data = pq(url='https://www.baidu.com',encoding='utf-8')
print(data)#返回网页源代码
print(type(data))#1.2 通过字符串(text)初始化Pyquery对象
from pyquery import PyQuery as pq
text = '''
'''
data = pq(text)
print(data)#返回text的内容
print(data('span'))#数据分析
1.3 通过文件名(filename)初始化Pyquery对象
第一步,先创建一个html文件 : 练习.html
DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Titletitle>
head>
<body>
<div id="cont">
<ul class="slist">
<li class="item-0">web开发li>
<li class="item-1"><a href="link2.html">爬虫开发a>li>
<li class="item-0 active"><a href="link3.html"><span class="bold">数据分析span>a>li>
<li class="item-1 active"><a href="link4.html">深度学习a>li>
<li class="item-0"><a href="link5.html">机器学习a>li>
ul>
div>
body>
html>
第二步,解析
from pyquery import PyQuery as pqdata = pq(filename='练习.html',encoding='UTF-8')
print(data)#UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 175: illegal multibyte sequence
报错了不要急,原因是gbk解码错误。两种解决方式:
1)将html中的中文字符全部删除,再读取
DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Titletitle>
head>
<body>
<div id="cont">
<ul class="slist">
<li class="item-0">webli>
<li class="item-1"><a href="link2.html">a>li>
<li class="item-0 active"><a href="link3.html"><span class="bold">span>a>li>
<li class="item-1 active"><a href="link4.html">a>li>
<li class="item-0"><a href="link5.html">a>li>
ul>
div>
body>
html>
from pyquery import PyQuery as pqdata = pq(filename='练习.html',encoding='UTF-8')
print(data)#返回html文件内容
print(data('title'))#Title
2)先读取文件,并重新编码,再用字符串方式初始化
最终效果与1)是一样的。不过会占用内存,html文件太大时不太适合。
f
rom pyquery import PyQuery as pqwith open('练习.html','r+',encoding='utf-8') as f:text = f.read()
data = pq(text)
print(data)
print(data('title'))
2. 查找节点
补充资料:https://www.icode9.com/content-1-621561.html
2.1 标签选择器
语法:pyquery对象('标签名')
就是前面范例中的:
print(data('title'))#Title
如果要查某一个子标签,则:
语法:pyquery对象('标签a a的子标签b b的子标签c ...)
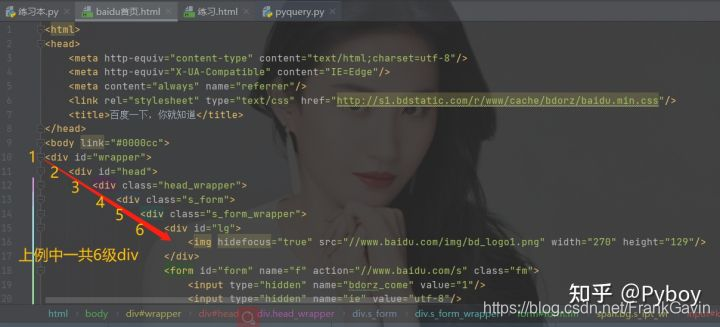
from pyquery import PyQuery as pqdata = pq(url='http://www.baidu.com',encoding='utf-8')#with open('baidu首页.html','w+',encoding='utf-8') as f:
# f.write(str(data))
print(data('div div div div div div'))
# 
2.2 CSS选择器
2.2.1 class选择器
语法:pyquery对象('.class属性值')
表示选择该pq对象中所有class='class属性值’的内容
语法:pyquery对象('标签1.class属性值')
表示选择 pq对象中class='class属性值’的标签1 内容
from pyquery import PyQuery as pq
with open('练习.html','r+',encoding='utf-8') as f:text = f.read()
data = pq(text)# 满足 class='item-0'的标签内容
print(data('.item-0'))
#web开发
#数据分析
#机器学习 # 同时满足 class='item-0'和class='active'的标签内容
print(data('.item-0.active'))
#数据分析 # class='item-1'的li标签
print(data('li.item-1'))
#爬虫开发
#深度学习
2.2.2 id选择器
语法:pyquery对象('#ID属性值')
表示选择该pq对象中所有id='ID属性值’的内容
语法:pyquery对象('标签1#ID属性值')
表示选择 pq对象中id='ID属性值’的标签1 内容。
这样写是可以,不过id不同于class,一个id对应一个css元素,一个css元素对应一个id,不存在id值相同的两个不同标签。所以没必要这样写
from pyquery import PyQuery as pqdata = pq(url='http://www.baidu.com',encoding='utf-8')print(data('#lg'))
# print(data('div#lg'))
#
2.2.4 其他
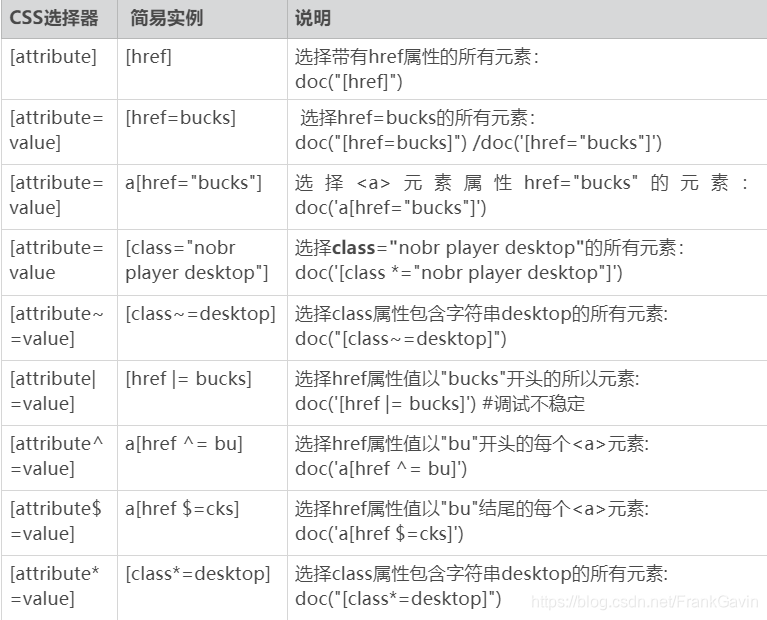
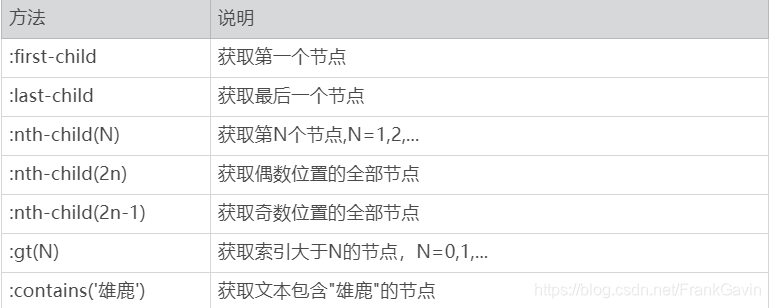
2.3 伪类选择器
html = '''
'''
from pyquery import PyQuery as pq
doc = pq(html)li = doc('li:first-child')# 选择第一个li节点
print(li)
#web开发 li1 = doc('li:last-child')# 选择最后一个li节点
print(li1)
#机器学习 li2 = doc('li:nth-child(2)')# 选择第二个li节点
print(li2)
#爬虫开发 li3 = doc('li:gt(2)')# 选择第3个li(不包括第三个)之后的li节点
print(li3)
#深度学习
#机器学习 li4 = doc('li:nth-child(2n)')# 选择偶数位置的li节点
print(li4)
#爬虫开发
#深度学习 li5 = doc('li:contains(深度)')# 选择包含'深度'文本的li节点
print(li5)
#深度学习
2.4 父级节点查找
语法:pyquery对象.parent()
直接父级节点查找
from pyquery import PyQuery as pq
doc = pq(html)#这是一个pyquery对象li = doc('li')#这也是一个pyquery对象
print(type(li))#输出结果:
<ul class="slist">
<li class="item-0">web开发</li>
<li class="item-1"><a href="link2.html">爬虫开发</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">数据分析</span></a></li>
<li class="item-1 active"><a href="link4.html">深度学习</a></li>
<li class="item-0"><a href="link5.html">机器学习</a></li>
</ul>
语法:pyquery对象.parents('条件1')
符合条件1的(父)祖级节点查找。如果不加条件限制,会返回所有的 父级 祖级。
from pyquery import PyQuery as pq
doc = pq(html)li = doc('li')
print(li.parents('div'))
输出:
<div id="cont">
<ul class="slist">
<li class="item-0">web开发</li>
<li class="item-1"><a href="link2.html">爬虫开发</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">数据分析</span></a></li>
<li class="item-1 active"><a href="link4.html">深度学习</a></li>
<li class="item-0"><a href="link5.html">机器学习</a></li>
</ul>
</div>
2.5 子级节点查找
语法1:pyquery对象.children('条件1')
符合条件1的直接子级节点查找,如果过不加条件限制,会返会所有直接子级。
from pyquery import PyQuery as pq
doc = pq(html)li = doc('li')
print(type(li))# 爬虫开发数据分析深度学习机器学习
语法2:pyquery对象('父节点 子节点')
注意:这个子节点并不需要是直接子关系,可以是孙子关系或者更下层的层级关系。
from pyquery import PyQuery as pq
doc = pq(html)li = doc('.item-0 span')
print(li)#数据分析
两个节点之间加空格,表示后者是前者的下级;
不加空格表示同时满足条件1和条件2(例如doc(’.item-1.active’)),不适用于标签选择器(因为不加.或者[]之类符号限制的话,系统会将两个相连的标签识别为一个标签名,会报错例如:divp)。
print(doc('.item-1.active'))
#深度学习
语法3:pyquery对象('标签1>标签2')
适用于标签选择器。查找标签1下的多有标签2。标签1和标签2必须成直接父子关系,否则查找不到。
from pyquery import PyQuery as pq
doc = pq(html)li = doc('ul>li')
print(li)
#web开发
#爬虫开发
#数据分析
#深度学习
#机器学习
2.6 同级(兄弟)节点查找
语法:pyquery对象.sibling('条件1')
查找符合条件1的兄弟节点。不加条件,则返回所有兄弟节点。
from pyquery import PyQuery as pq
doc = pq(html)
data = doc('li.active')
print(data)
#数据分析
#深度学习 print(data.siblings())
#爬虫开发
#web开发
#数据分析
#爬虫开发
#web开发
#深度学习
#机器学习
#机器学习 print(data.siblings('.item-1'))
#爬虫开发
#爬虫开发
#深度学习
2.7 同时查找多个节点
语法:pyquery对象('节点a,节点b')
from pyquery import PyQuery as pqdata = pq(url='http://www.baidu.com',encoding='utf-8')
for i in data('a,span').items():print(i)
输出结果:
<span class="bg s_ipt_wr"><input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off" autofocus=""/></span>
<span class="bg s_btn_wr"><input type="submit" id="su" value="百度一下" class="bg s_btn"/></span>
<a href="http://news.baidu.com" name="tj_trnews" class="mnav">新闻</a>
<a href="http://www.hao123.com" name="tj_trhao123" class="mnav">hao123</a>
<a href="http://map.baidu.com" name="tj_trmap" class="mnav">地图</a>
<a href="http://v.baidu.com" name="tj_trvideo" class="mnav">视频</a>
<a href="http://tieba.baidu.com" name="tj_trtieba" class="mnav">贴吧</a>
<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1" name="tj_login" class="lb">登录</a>
<a href="//www.baidu.com/more/" name="tj_briicon" class="bri" style="display: block;">更多产品</a>
<a href="http://home.baidu.com">关于百度</a>
<a href="http://ir.baidu.com">About Baidu</a>
<a href="http://www.baidu.com/duty/">使用百度前必读</a>
<a href="http://jianyi.baidu.com/" class="cp-feedback">意见反馈</a> 京ICP证030173号
3. 遍历pyquery对象
pyquery对象.items() 转换为生成器对象(迭代器的一种),再for循环遍历
from pyquery import PyQuery as pq
doc = pq(html)
data = doc('li').items()
print(type(data))
for i in data:print(i)
输出结果:
<class 'generator'>
<li class="item-0">web开发</li><li class="item-1"><a href="link2.html">爬虫开发</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">数据分析</span></a></li><li class="item-1 active"><a href="link4.html">深度学习</a></li><li class="item-0"><a href="link5.html">机器学习</a></li>
4. 获取信息
4.1 获取属性值——attr()
语法1:pyquery对象.attr('属性名')
attr()只传递一个参数:属性名,表示查找属性值;
如果传递第二个参数,则表示修改属性值。
修改时,若第一个参数,这个属性不存在,则创建。
语法2:pyquery对象.attr.属性名
from pyquery import PyQuery as pq
doc = pq(html)
print(doc.attr('id'))#cont
print(doc.attr.id)#cont
doc.attr('name', 'alink')
print(doc.attr('name'))#alink
attr方法是在pyquery对象的第一个标签里查找属性,如果没找到就返回None。
print(doc.attr('href'))#None
print(doc.attr.href)#None
所以我们需要先把一个pyquery对象用items()方法转换成一个迭代器对象,再迭代这个迭代器对象,再使用attr()方法取找每一个标签里的属性。
from pyquery import PyQuery as pq
doc = pq(html)
data = doc('li').items()
for i in data:print(i)print(i.attr('class'))
输出结果:
<li class="item-0">web开发</li>item-0
<li class="item-1"><a href="link2.html">爬虫开发</a></li>item-1
<li class="item-0 active"><a href="link3.html"><span class="bold">数据分析</span></a></li>item-0 active
<li class="item-1 active"><a href="link4.html">深度学习</a></li>item-1 active
<li class="item-0"><a href="link5.html">机器学习</a></li>item-0
4.2 获取文本——text()
from pyquery import PyQuery as pq
doc = pq(html)
data = doc('span')
print(data)#数据分析
print(data.text())#数据分析
text()中也可以传递参数,表示修改文本。
data.text('金融分析')
print(data.text())#金融分析
4.3 获取节点内部的HTML文本——html()
获取或设置子节点的html表示,不传参表示查询,传参表示修改。
from pyquery import PyQuery as pq
doc = pq(html)
data = doc('li').items()
for d in data:print(d.html())d.html('修改文档')print(d.html())
运行结果:
web开发
<span>修改文档</span>
<a href="link2.html">爬虫开发</a>
<span>修改文档</span>
<a href="link3.html"><span class="bold">数据分析</span></a>
<span>修改文档</span>
<a href="link4.html">深度学习</a>
<span>修改文档</span>
<a href="link5.html">机器学习</a>
<span>修改文档</span>
5. 节点操作
为了提取方便,我们可以修改我们已经获取的html的节点,如在指定位置添加class,移除不需要的某个(些)节点等
5.1 移除指定节点——remove()
先查找到要移除的结点,然后.remove()即可
from pyquery import PyQuery as pq
doc = pq(html)
data = doc('li')
data.remove()
print(doc)
运行结果:
<div id="cont">
<ul class="slist"></ul>
</div>
5.2 移除class属性——removeClass()
removeClass('要移除的属性值')
from pyquery import PyQuery as pq
doc = pq(html)
data = doc('li.active')
data.remove_class('item-0')
print(data)
运行结果:
<li class="active"><a href="link3.html"><span class="bold">数据分析</span></a></li>
<li class="item-1 active"><a href="link4.html">深度学习</a></li>
5.3 增加class属性——addClass()
addClass('要增加的属性值')
from pyquery import PyQuery as pq
doc = pq(html)
data = doc('li.item-0.active')
data.add_class('春天来了')#中文会自动Unicode编码
print(data)
#数据分析
6. 注意事项
pyquery库直接请求url的话,没有办法设置请求头和请求方式,也不能上传数据。
所以只能用来爬取一些简单的网址。
不过用来做数据解析和提取时挺好用的,一般也确实是这样用的。
获取网页的工作用别的库,如requests库来完成。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!