CUDA---从入门到升华
最近在学习CUDA编程,将学习到的一些知识进行整合,方便自己翻阅学习。
典型的CUDA程序的执行流程
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用kernel在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存。
基础知识
- 符号声明
__global ____:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。
__device ____:在device上执行,单仅可以从device中调用,不可以和__global__同时用。
__host __:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device,此时函数会在device和host都编译。[1] - kernel、grid、block、thread以及数据类型
1、1-dim、2-dim、3-dim
dim3可以看成是包含三个无符号整数(x,y,z),缺省值初始化为1
dim3 grid_size(5,3);
dim3 block_size(98,5);
kernel_test<<grid_size,block_size>>(prams...);
2、kernel-grid-block-thread的组织结构
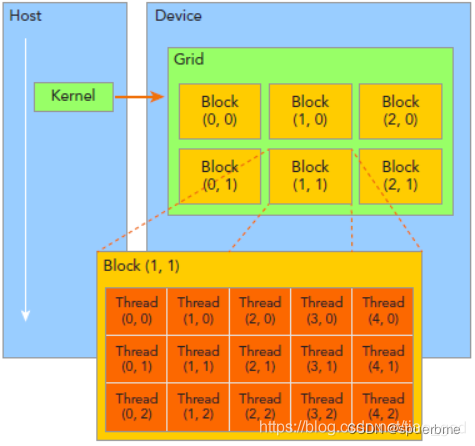
这里方便介绍我们用的都是二维的结构,
blockDim.x:Block的x方向的维度,这里是5,即每行5个线程。
blockDim.y:Block的y方向的维度,这里是3,即每列3个线程。
blockIdx.x:Block在x方向的位置,图中放大的Block是2,即为第2个。
blockIdx.y:Block在y向的位置,图中放大的Block是2,即为第2个。
注意blockIdx中的Idx是表示index的缩写,而不是表示x方向的ID
例:计算thread的索引
int index = blockIdx.x * blockDim.x + threadIdx.x;
求thread(1,1)的索引
A: index(1,1)=1*5+1;[2]
可以看出,block是行优先的。
-
host、device、数据空间申请、数据转移
-
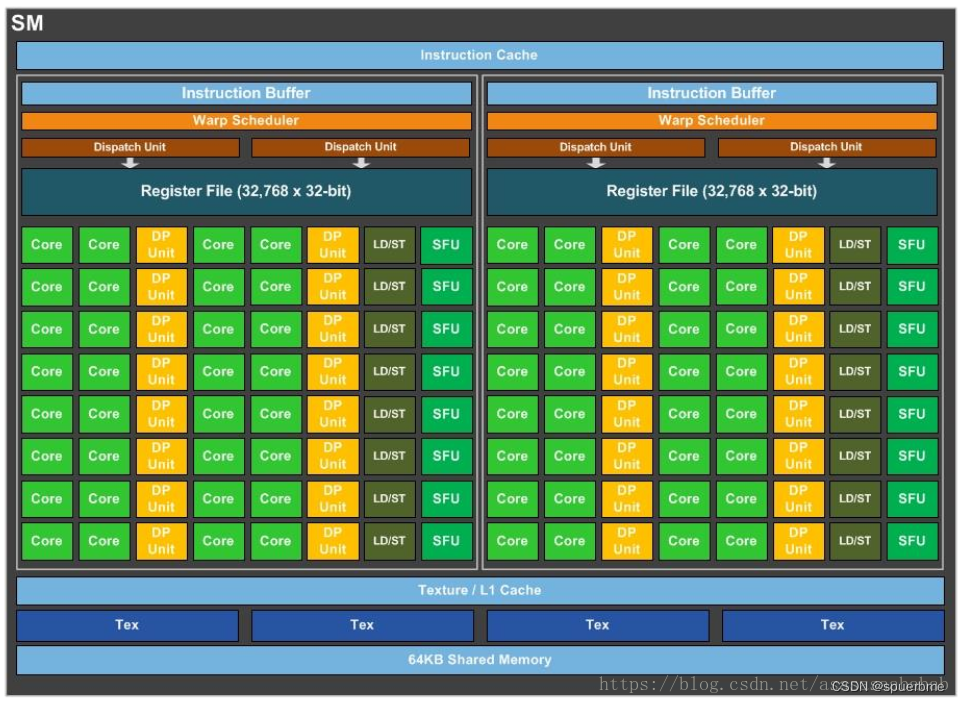
GPU、SM、SP、CUDA core、bank、wrap
1、
在GP100里,每一个SM有两个SM Processing Block(SMP),里边的绿色的就是CUDA Core,CUDA core也叫Streaming Processor(SP),这俩是一个意思。每一个SM有自己的指令缓存,L1缓存,共享内存。而每一个SMP有自己的Warp Scheduler、Register File等。要注意的是CUDA Core是Single Precision的,也就是计算float单精度的。双精度Double Precision是那个黄色的模块。所以一个SM里边由32个DP Unit,由64个CUDA Core,所以单精度双精度单元数量比是2:1。LD/ST 是load store unit,用来内存操作的。SFU是Special function unit,用来做cuda的intrinsic function的,类似于__cos()这种。[3]
GPU、SM、SP、CUDA core详解
2、共享内存被划分为大小相等的n个部分(每个部分称为一个bank),同一时刻的n个访存请求将分别通过这n个部分进行,从而使共享内存的带宽变为n倍。bank大小为32,即程序可同时读写32个不同bank的数据
3、warp是SM的基本执行单元。一个warp包含32个并行thread,这32个thread执行于SMIT模式。也就是说所有thread执行同一条指令,并且每个thread会使用各自的data执行该指令。 -
memories(全局内存、共享内存、纹理内存…)
cuda内存模型
1.上文中详细介绍了cuda的内存层次结构,这对未来程序优化是很有帮助的。
2.如果未来小伙伴们需要对程序进行加速,那就不得不提到共享内存。这里找到一篇文章详细介绍了共享内存加速的机制,以及当共享内存访问冲突时可采取的一些解决方法。
cuda共享内存概述
另:这位作者的举例生动有趣,人工智能、深度学习的朋友们都可以看看
应用场景
通过上述介绍,我们已经知道,CUDA适用于大型并行计算场景,可以用于图像计算、矩阵计算、深度学习、机器学习、算法优化等各种方面,更多功能还有待小伙伴们继续探索。
适用于CUDA的系统分析工具
NVIDIA Nsight Systems 入门及使用
除了上文提到的客户端使用方式,NVIDIA还提供了其命令行工具:nsys使用
这些工具为用户提供了查看CUDA核函数及其内存信息的功能,帮助用户对CUDA程序进行进一步优化。
1、尽可能地充分使用其带宽,避免核心闲置
2、尽可能减少malloc、devicetohost及hosttodevice所占时间比
通过以上两条优化建议,可以使得CUDA程序呈现出较好的加速比
规约算法
规约算法的七种优化方法详解
关于上述优化方法,建议先了解cuda程序的硬件,例如自己的显卡型号、一个block最多可以并行多少个线程等等。
编程实例
以一维block为例
#include 写在最后
如果想要进一步学习,以上这些知识是远远不够的。我们还需要大量的实践与磨炼,才能更上一层楼。最后,感谢文中所提到的博主创作的文章。
参考链接
[1]https://blog.csdn.net/xiaohu2022/article/details/79599947
[2]https://feimo.blog.csdn.net/article/details/107181883
[3]https://blog.csdn.net/asasasaababab/article/details/80447254
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!