从零开始行人重识别学习笔记
原文:从零开始行人重识别
(本文在原文的基础上增加了一些操作步骤截图、代码注释等等一些自己做的笔记补充,由于本人是新手,第一次接触reid和pytorch,有错误谢谢指出)
准备步骤:Anaconda、pytorch和torchvision安装
下载数据集和本次实践的代码:
Code: Practical-Baseline Data: Market-1501
目录
Part 1: 训练 ——将一批数据输入网络模型,得到模型最终的参数权重
Part 1.1: 准备数据集 (python prepare.py)
Part 1.2: Build Neural Network (model.py)
Part 1.3: 训练 (python train.py)
Part 2: 测试 ——将另一批数据输入训练好的网络模型,根据输出特征求距离对图片间的相似度排序,并求rank和mAP
Part 2.1: 特征提取 (python test.py)
Part 2.2: 评测(evaluate_gpu.py)
Part 3: 一个简单的可视化程序 (python demo.py)
Part 4: 轮到你了.
Part 1: 训练
Part 1.1: 准备数据集 (python prepare.py)
打开刚刚下载的代码prepare.py。 将第五行的地址改为你本地的地址。
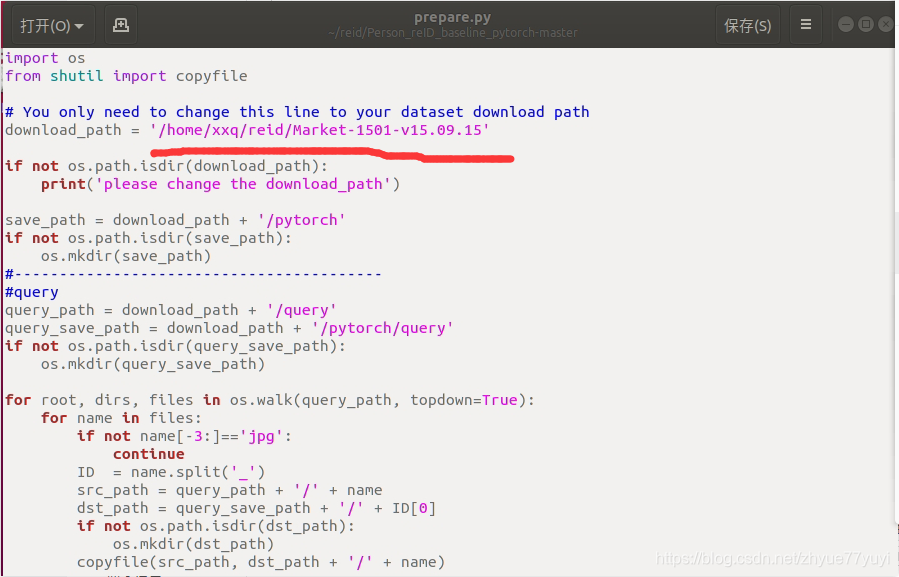
运行或者执行以下命令:
evaluate(qf,ql,qc,gf,gl,gc) # 函数功能就是上面做的按距离排序这件事函数传入的。
所以,qf来自于query_feature[i],query_feature来自于test.py中一批图片传入模型得到的特征数组query_feature.numpy()
同样,gf来自于gallery_feature,来自于test.py中一批图片传入模型得到的特征数组gallery_feature.numpy()注意到有两种图像我们不把他们考虑为正确匹配true-matches
- 一种是Junk_index1 错误检测的图像,主要是包含一些人的部件。
- 一种是Junk_index2 相同的人在同一摄像头下,按照reid的定义,我们不需要检索这一类图像。
query_index = np.argwhere(gl==ql) # 返回满足gl==ql的数组元组的索引,即query和gallery图像所属类别相同。camera_index = np.argwhere(gc==qc) # 所属摄像头相同# The images of the same identity in different cameras 只能匹配相同类别不同摄像头的图good_index = np.setdiff1d(query_index, camera_index, assume_unique=True) # 返回在query_index中但不在camera_index中的值# assume_unique为True,表示假定输入数组是唯一的,即不合并重复元素# Only part of body is detected. junk_index1 = np.argwhere(gl==-1) # 类别为-1表示图片中无具体的人# The images of the same identity in same camerasjunk_index2 = np.intersect1d(query_index, camera_index) # 计算query_index和camera_index的公共元素 我们可以使用 compute_mAP 来计算最后的结果. 在这个函数中,我们忽略了junk_index带来的影响。
CMC_tmp = compute_mAP(index, good_index, junk_index)运行 python evaluate_gpu.py 指令,发现结果与上述 test结果相同。

!注释:pytorch view():
返回一个新张量,它的数据与 self 张量相同,但 shape 不同。
>>> x = torch.randn(4, 4)
>>> x.size()
torch.Size([4, 4]) # x 为4*4的张量
>>> y = x.view(16)
>>> y.size()
torch.Size([16]) # y为1*16的张量
>>> z = x.view(-1, 8) # -1的大小是从其他维度推断出来的
>>> z.size()
torch.Size([2, 8]) # z为2*8的张量"""
输出:
tensor([[-0.6413, 1.0150, 1.1099, 0.1736],[ 0.6944, 1.1347, 0.3699, -0.1459],[ 0.6396, 1.0228, -1.3372, -0.8312],[ 0.1817, 1.3849, 0.0417, -0.1628]]) torch.Size([4, 4])
tensor([-0.6413, 1.0150, 1.1099, 0.1736, 0.6944, 1.1347, 0.3699, -0.1459,0.6396, 1.0228, -1.3372, -0.8312, 0.1817, 1.3849, 0.0417, -0.1628]) torch.Size([16])
tensor([[-0.6413, 1.0150, 1.1099, 0.1736, 0.6944, 1.1347, 0.3699, -0.1459],[ 0.6396, 1.0228, -1.3372, -0.8312, 0.1817, 1.3849, 0.0417, -0.1628]]) torch.Size([2, 8])
"""
!注释:torch.squeeze()
函数功能:去除size为1的维度,包括行和列。当维度大于等于2时,squeeze()无作用。
其中squeeze(0)代表若第一维度值为1则去除第一维度,squeeze(1)代表若第二维度值为1则去除第二维度。
如果输入是形如(A×1×B×1×C×1×D)(A×1×B×1×C×1×D),那么输出形状就为: (A×B×C×D)
a = torch.Tensor(1,3)
print a
tensor([[-1.37,4.56,-3.57]])print a.squeeze(0)
tensor([-1.37,4.56,-3.57])!注释:对于两个特征,它们的余弦相似度就是两个特征在经过L2归一化之后的矩阵内积。
两个特征的余弦相似度计算出来的范围是**[-1,1]**
代码举例:
import torch
import torch.nn.functional as F
#假设feature1为N*C*W*H, feature2也为N*C*W*H(基本网络中的tensor都是这样)
feature1 = feature1.view(feature1.shape[0], -1)#将特征转换为N*(C*W*H),即两维
feature2 = feature2.view(feature2.shape[0], -1)
feature1 = F.normalize(feature1) #F.normalize只能处理两维的数据,L2归一化
feature2 = F.normalize(feature2)
distance = feature1.mm(feature2.t())#计算余弦相似度
!注释:np.argwhere()的用法
np.argwhere( a )
返回非0的数组元组的索引,其中a是要索引数组的条件。
举例:返回 Array a 中所有大于1的值的索引
>>> x = np.arange(6).reshape(2,3)
>>> x
array([[0, 1, 2],[3, 4, 5]])
>>> np.argwhere(x>1)
array([[0, 2],[1, 0],[1, 1],[1, 2]])
!注释:np.setdiff1d()的用法
setdiff1d(ar1, ar2, assume_unique=False)
返回值:在ar1中但不在ar2中的从小到大排序的唯一值。
1.assume_unique = False的情况:(从小到大排序,合并重复元素)
a = np.array([1,2,3,4])b = np.array([3,4,5,6])c = np.setdiff1d(a, b)print(c)#[1 2]
a = np.array([8,2,3,2,4,1])b = np.array([7,4,5,6,3])c = np.setdiff1d(a, b)print(c)#[1 2 8]2.assume_unique = True的情况:(按a中的顺序排序,并且不合并重复的元素)
a = np.array([8,2,3,4,2,4,1])b = np.array([7,9,5,6,3])c = np.setdiff1d(a, b,True)print(c)#[8 2 4 2 4 1]
Part 3: 一个简单的可视化程序 (python demo.py)
可视化结果,
python demo.py --query_index 777--query_index which query you want to test. You may select a number in the range of 0 ~ 3367.【因为原query文件夹里有3368张图片】
代码类似 evaluate.py. 我们加入了可视化的部分。
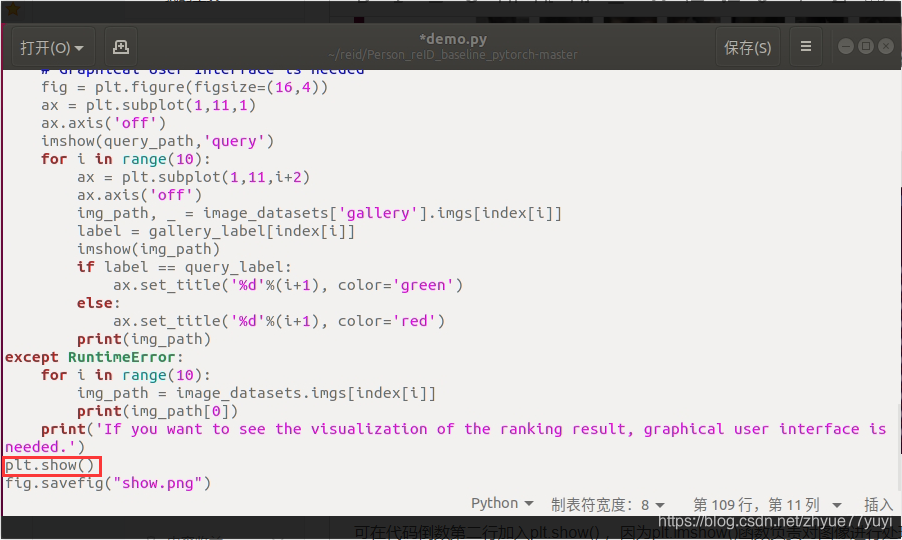
try: # Visualize Ranking Result 可视化结果排名# Graphical User Interface is needed 需要图形用户界面fig = plt.figure(figsize=(16,4)) # 显示的尺寸为16*4ax = plt.subplot(1,11,1) # 显示为1行,每行11个,表示这是第一张图ax.axis('off') # 不显示坐标轴imshow(query_path,'query') # 显示查询图片,总共显示11张图,查询图为第一张# 代码中有具体的imshow函数定义for i in range(10): #Show top-10 images i从0到9ax = plt.subplot(1,11,i+2) #循环画剩下的第2到第11张图ax.axis('off')img_path, _ = image_datasets['gallery'].imgs[index[i]] # index为已排好序的索引label = gallery_label[index[i]]imshow(img_path) if label == query_label: # 显示是查到的第几张图片,正确的是绿色,错误的是红色ax.set_title('%d'%(i+1), color='green') # true matchingelse:ax.set_title('%d'%(i+1), color='red') # false matchingprint(img_path) # 打印每一张图片的路径
except RuntimeError:for i in range(10):img_path = image_datasets.imgs[index[i]]print(img_path[0])print('If you want to see the visualization of the ranking result, graphical user interface is needed.') # 如果你想看到排名结果的可视化,图形用户界面是必要的运行 python demo.py --query_index 777 指令:
出现个小问题:
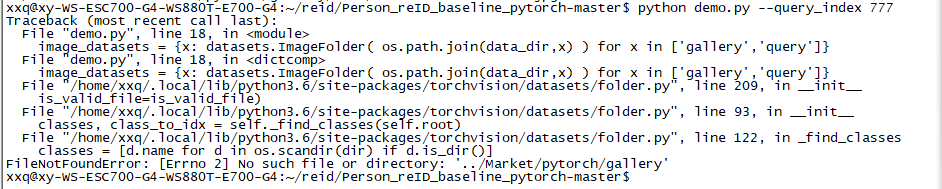
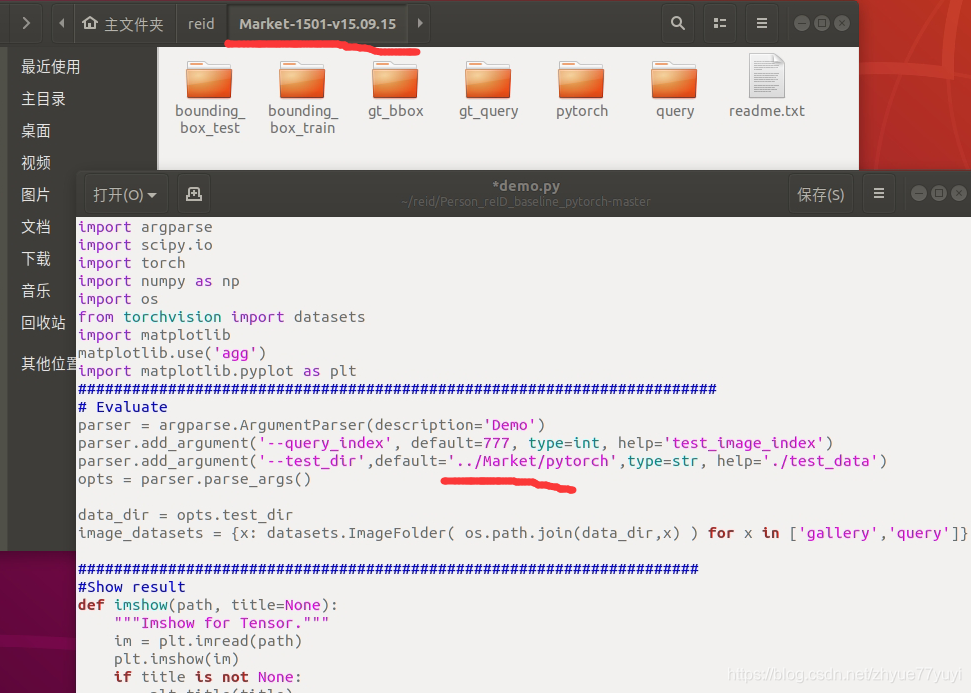
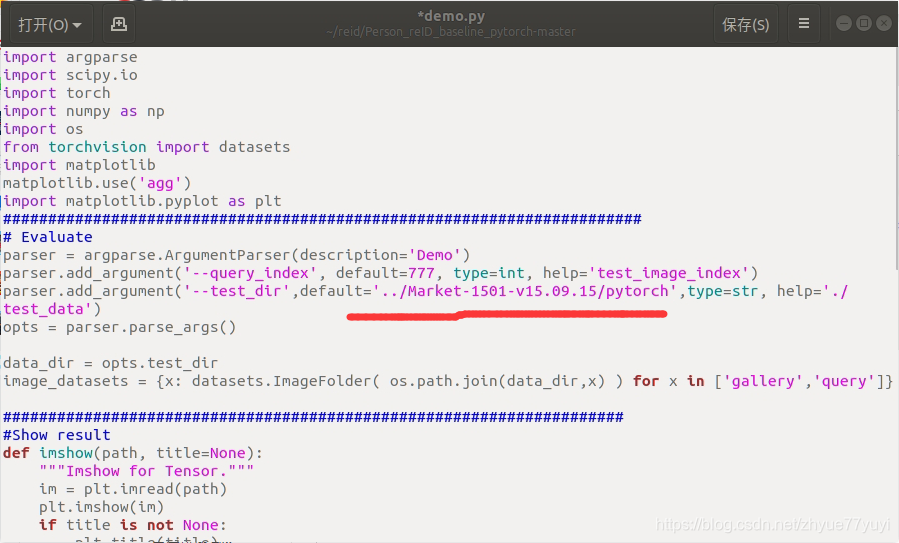
其实原因就是我的数据集文件夹名是Market-1501-v15.09.15而不是Market,在代码里修改数据集所在的目录就好。
继续执行指令,成功输出十一张图片的路径:
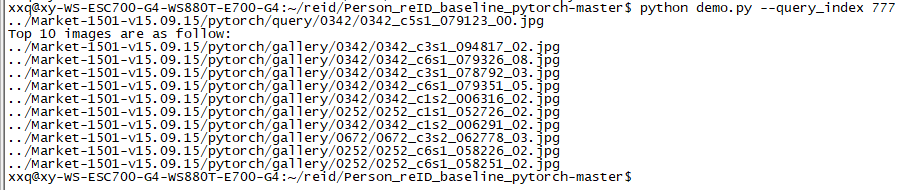
代码通过 fig.savefig("show.png") 将这十一张图片保存在文件夹目录中:

ps:运行demo.py 时agg可能出现问题,将语句 atplotlib.use('agg') 删除就好。
删除后,运行demo.py会直接显示图片
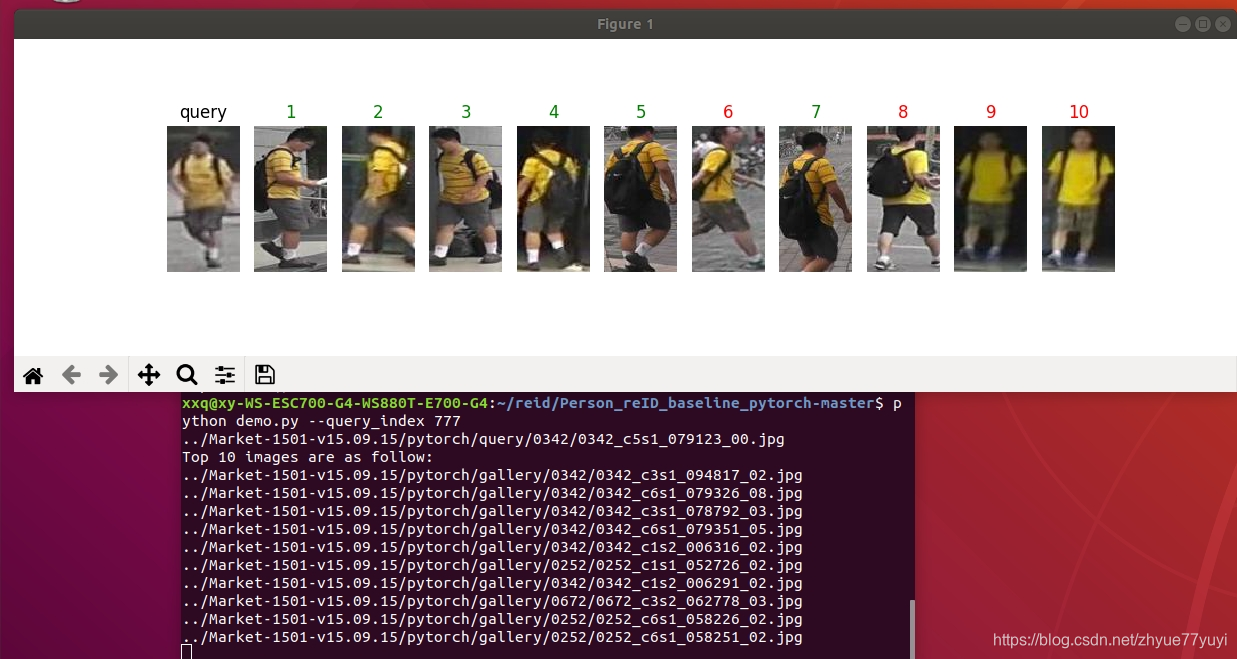
不过。画完之后图就马上消失了。
可在代码倒数第二行加入plt.show() ,因为plt.imshow()函数负责对图像进行处理,并显示其格式,但是不能显示。其后跟着plt.show()才能显示出来。
Part 4: 轮到你了.
- Market-1501 是一个在清华大学夏天收集的数据集.
让我们试试另一个数据集 DukeMTMC-reID, 是在Duke大学冬天采集的。
你可以在这里 Here 下到数据集. 试试去训练这个数据集
这个数据集和Market类似. 你可以 Here 看SOTA的结果
+ Quick Question. Could we directly apply the model trained on Market-1501 to DukeMTMC-reID? Why?- 快速问答。我们能直接用Market训好的模型放到DukeMTMC-reID上测试么? 为什么?
【解答】可以,但是结果还不够好。在许多文献中,不同的数据集通常会有区域间隙,这可能是由不同的因素造成的,如不同的光照和不同的遮挡。为了进一步的参考,您可以查看市场上在数据集Market-1501到DukeMTMC-reid迁移学习的排行榜。 (https://github.com/layumi/dukemtmc-reid_evaluation/tree/master/# transfer-learning)。
- 试试 Triplet Loss. Triplet loss是另一种广泛使用的目标函数. 你可以看看 https://github.com/layumi/Person-reID-triplet-loss. 我把代码风格和本实践保持了一致, 你可以看看我改了什么.
参考资料: Pytorch 03: nn.Module模块了解
PyTorch源码解读之torchvision.models
torch代码解析 为什么要使用optimizer.zero_grad()
PyTorch学习之路(level1)——训练一个图像分类模型
torch.norm()函数的用法
Pytorch——tensor.expand_as()函数示例
Python——div函数的使用及理解
pytorch view()
torch.squeeze()和unsqueeze()
关于.data和.cpu().data的各种操作
python数组冒号取值操作
浅述python中argsort()函数的用法
pytorch计算两个特征的余弦相似度
np.argwhere()的用法
python numpy中setdiff1d的用法
文中问题的答案:Answers to Quick Questions
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!