Datawhale 6月学习——图神经网络:超大图上的节点表征学习
前情回顾
- 图神经网络:图数据表示及应用
- 图神经网络:消息传递图神经网络
- 图神经网络:基于GNN的节点表征学习
- 图神经网络:基于GNN的节点预测任务及边预测任务
1 超大图上的节点表征学习
1.1 简述
在十分庞大(节点数极多)的图上,图神经网络训练所需要的计算资源相当多,会极大地消耗计算机内存及显卡显存,这对使用者的设备带来过大的要求。
图神经网络已经成功地应用于许多节点或边的预测任务,然而,在超大图上进行图神经网络的训练仍然具有挑战。普通的基于SGD的图神经网络的训练方法,要么面临着随着图神经网络层数增加,计算成本呈指数增长的问题,要么面临着保存整个图的信息和每一层每个节点的表征到内存(显存)而消耗巨大内存(显存)空间的问题。虽然已经有一些论文提出了无需保存整个图的信息和每一层每个节点的表征到GPU内存(显存)的方法,但这些方法可能会损失预测精度或者对提高内存的利用率并不明显。
因此,在进行超大图的节点表征学习时,需要考虑如何提高内存及显存的利用率。
一些针对这一问题的方法已被提出。
1.2 常见的方法
可以借助PyG官方文档来了解常见的应对超大图节点表征学习的方法。
一种主流的思路是将数据集进行划分,分批训练,再使用合适的方法耦合训练结果。
相关论文包括
- Inductive Representation Learning on Large Graphs, 这篇文章使用了大图中节点的低维嵌入方法,同时提出了GraphSAGE。
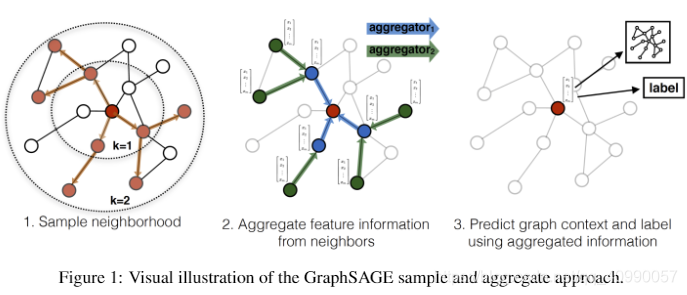
- Deep Graph Neural Networks with Shallow Subgraph Samplers,这篇文章使用浅子图采样器进行大图训练,主要针对深图神经网络的计算爆炸问题。
- Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Network,提出一种新的图神经网络的训练方法,它利用图聚类结构进行数据集采样。即本次学习的模型。
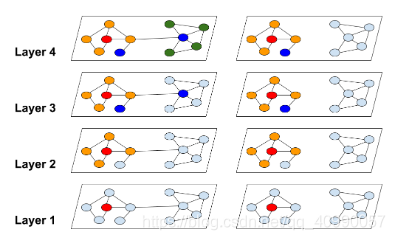
2 ClusterGCN
2.1 原理
ClusterGCN主要通过图节点聚类算法划分数据集,使用子图进行训练,然后再随机选择子图,构成batch减少划分数据集带来的信息丢失。
为了解决普通训练方法无法训练超大图的问题,Cluster-GCN论文提出:
- 利用图节点聚类算法将一个图的节点划分为 c c c个簇,每一次选择几个簇的节点和这些节点对应的边构成一个子图,然后对子图做训练。
- 由于是利用图节点聚类算法将节点划分为多个簇,所以簇内边的数量要比簇间边的数量多得多,所以可以提高表征利用率,并提高图神经网络的训练效率。
- 每一次随机选择多个簇来组成一个batch,这样不会丢失簇间的边,同时也不会有batch内类别分布偏差过大的问题。
- 基于小图进行训练,不会消耗很多内存空间,于是我们可以训练更深的神经网络,进而可以达到更高的精度。
该方法的提出大概依照了如下的逻辑:
- 提出使用图节点聚类算法将节点划分为多个簇。由于使用了子图进行训练,内存空间占用较全图训练更小,但仍然存在一些问题。
尽管简单Cluster-GCN方法可以做到较其他方法更低的计算和内存复杂度,但它仍存在两个潜在问题:
- 图被分割后,一些边(公式(4)中的 Δ \Delta Δ部分)被移除,性能可能因此会受到影响。
- 图聚类算法倾向于将相似的节点聚集在一起。因此,单个簇中节点的类别分布可能与原始数据集不同,导致对梯度的估计有偏差。
- 因此,提出了一种随机多簇方法
此方法的好处有,1)不会丢失簇间的边,2)不会有很大的batch内类别分布的偏差,3)以及不同的epoch使用的batch不同,这可以降低梯度估计的偏差。
博主不务正业的土豆的csdn文章对Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Network也对这篇文章进行了通俗易懂的讲解及相关知识的拓展,可以参考阅读。
2.2 代码实现
PyG库对基于图节点聚类的类簇划分进行了集成,可参见torch_geometric.data.ClusterData,以及torch_geometric.data.ClusterLoader。
此处使用Reddit数据集,是由来自Reddit论坛的帖子组成,如果两个帖子被同一人评论,那么在构图的时候,就认为这两个帖子是相关联的,标签是每个帖子对应的社区分类。
这是一个很大的数据集,拥有232965个节点及114615892条边,被分为41类。
from torch_geometric.datasets import Redditdataset = Reddit('../dataset/Reddit')
data = dataset[0]
代码的实现主要分为几步:
- 实例化数据集的划分(
cluster_data),随机聚合簇成为batch(train_loader),在后续代码中,划分后的数据集将作为全局变量使用
from torch_geometric.data import ClusterData, ClusterLoader, NeighborSamplercluster_data = ClusterData(data, num_parts=1500, recursive=False, save_dir=dataset.processed_dir)
train_loader = ClusterLoader(cluster_data, batch_size=20, shuffle=True, num_workers=12)
subgraph_loader = NeighborSampler(data.edge_index, sizes=[-1], batch_size=1024, shuffle=False, num_workers=12)
- 图神经网络搭建
import torch
import torch.nn.functional as F
from torch.nn import ModuleList
from tqdm import tqdm
from torch_geometric.nn import SAGEConvclass Net(torch.nn.Module):def __init__(self, in_channels, out_channels):super(Net, self).__init__()self.convs = ModuleList([SAGEConv(in_channels, 128),SAGEConv(128, out_channels)])def forward(self, x, edge_index):for i, conv in enumerate(self.convs):x = conv(x, edge_index)if i != len(self.convs) - 1:x = F.relu(x)x = F.dropout(x, p=0.5, training=self.training)return F.log_softmax(x, dim=-1)def inference(self, x_all):pbar = tqdm(total=x_all.size(0) * len(self.convs))pbar.set_description('Evaluating')# Compute representations of nodes layer by layer, using *all*# available edges. This leads to faster computation in contrast to# immediately computing the final representations of each batch.for i, conv in enumerate(self.convs):xs = []for batch_size, n_id, adj in subgraph_loader:edge_index, _, size = adj.to(device)x = x_all[n_id].to(device)x_target = x[:size[1]]x = conv((x, x_target), edge_index)if i != len(self.convs) - 1:x = F.relu(x)xs.append(x.cpu())pbar.update(batch_size)x_all = torch.cat(xs, dim=0)pbar.close()return x_all
这个网络由两个GraphSAGE卷积层构成。
- 构建训练函数及测试函数
def train():model.train()total_loss = total_nodes = 0for batch in train_loader:batch = batch.to(device)optimizer.zero_grad()out = model(batch.x, batch.edge_index)loss = F.nll_loss(out[batch.train_mask], batch.y[batch.train_mask])loss.backward()optimizer.step()nodes = batch.train_mask.sum().item()total_loss += loss.item() * nodestotal_nodes += nodesreturn total_loss / total_nodes@torch.no_grad()
def test(): # Inference should be performed on the full graph.model.eval()out = model.inference(data.x)y_pred = out.argmax(dim=-1)accs = []for mask in [data.train_mask, data.val_mask, data.test_mask]:correct = y_pred[mask].eq(data.y[mask]).sum().item()accs.append(correct / mask.sum().item())return accs
train函数对每一个随机聚合簇的batch进行训练。
- 实例化网络,指定优化器
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Net(dataset.num_features, dataset.num_classes).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.005)
- 训练,测试
df = pd.DataFrame(columns = ["Loss"])
df.index.name = "Epoch"
df_test = pd.DataFrame(columns = ["Train","Val","test"])
df_test.index.name = "Epoch"for epoch in trange(1, 31):loss = train()df.loc[epoch] = lossif epoch % 5 == 0:train_acc, val_acc, test_acc = test()print(f'Epoch: {epoch:02d}, Loss: {loss:.4f}, Train: {train_acc:.4f}, 'f'Val: {val_acc:.4f}, test: {test_acc:.4f}')se = pd.Series([train_acc, val_acc, test_acc],index = ["Train","Val","test"])df_test.loc[epoch] = seelse:print(f'Epoch: {epoch:02d}, Loss: {loss:.4f}')
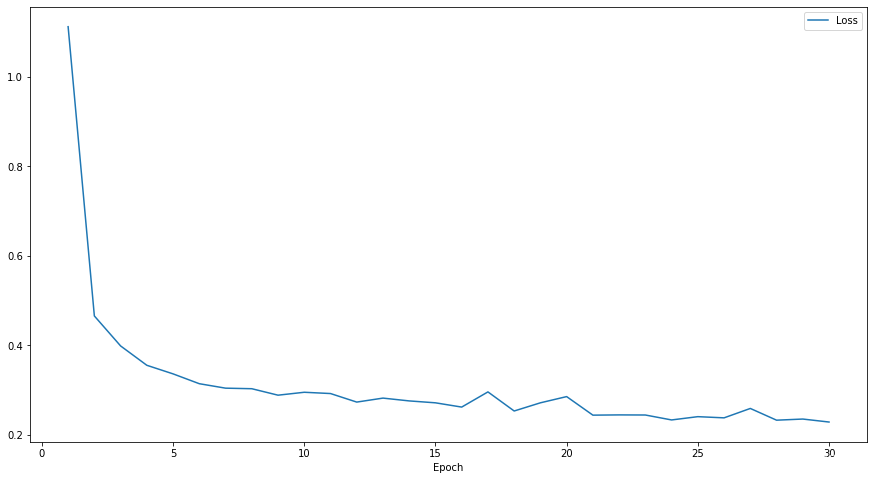
共进行了29个epoch的计算,计算结果如下
损失函数
在三个数据集上的准确率
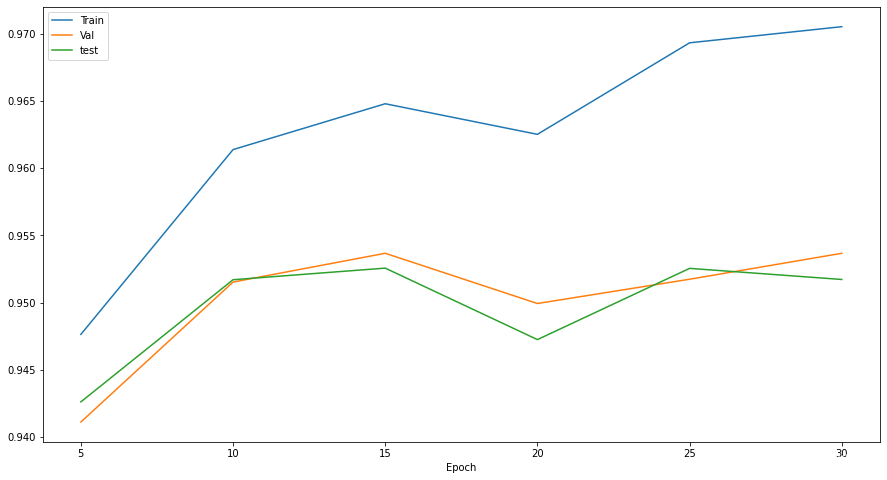
最终在训练集上的准确率为95.8%,验证集上的准确率为94.2%,测试集上的准确率为94.1%。
关于num_workers参数设定。
2.3 不同数量子数据集上的训练(作业)
2.3.1 数据集的随机划分
此处借助torch_geometric.data.RandomNodeSampler来实现一个数据集的随机划分,使用num_parts参数确定划分数量,划分后生成为类对象,可通过遍历该类对象获得划分好的data对象。
from torch_geometric.data import RandomNodeSampler
newdata_train = RandomNodeSampler(data, num_parts=3, shuffle=True)for each in newdata_train:each #这个对象为划分好的data对象
2.3.2 在不同划分结果上的训练
本次共进行了3、4、5、6共四种划分,划分的子数据集的节点数量如下:
| 划分 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|
| 节点数量 | 77696 | 57786 | 46793 | 39029 |
依然采用ClusterGCN进行训练,训练代码如下:
for each in newdata_train:cluster_data = ClusterData(each, num_parts=300, recursive=False)#, save_dir=dataset.processed_dir)train_loader = ClusterLoader(cluster_data, batch_size=20, shuffle=True, num_workers=12)subgraph_loader = NeighborSampler(each.edge_index, sizes=[-1], batch_size=320, shuffle=False, num_workers=12)model = Net(dataset.num_features, dataset.num_classes).to(device)optimizer = torch.optim.Adam(model.parameters(), lr=0.005)df = pd.DataFrame(columns = ["Loss"])df.index.name = "Epoch"df_test = pd.DataFrame(columns = ["Train","Val","test"])df_test.index.name = "Epoch"for epoch in trange(1, 31):loss = train()df.loc[epoch] = lossif epoch % 5 == 0:train_acc, val_acc, test_acc = test(each)print(f'Epoch: {epoch:02d}, Loss: {loss:.4f}, Train: {train_acc:.4f}, 'f'Val: {val_acc:.4f}, test: {test_acc:.4f}')se = pd.Series([train_acc, val_acc, test_acc],index = ["Train","Val","test"])df_test.loc[epoch] = seelse:print(f'Epoch: {epoch:02d}, Loss: {loss:.4f}')#result.append({"df":df,"df_test":df_test})break
2.3.3 在不同划分结果上的训练结果
-
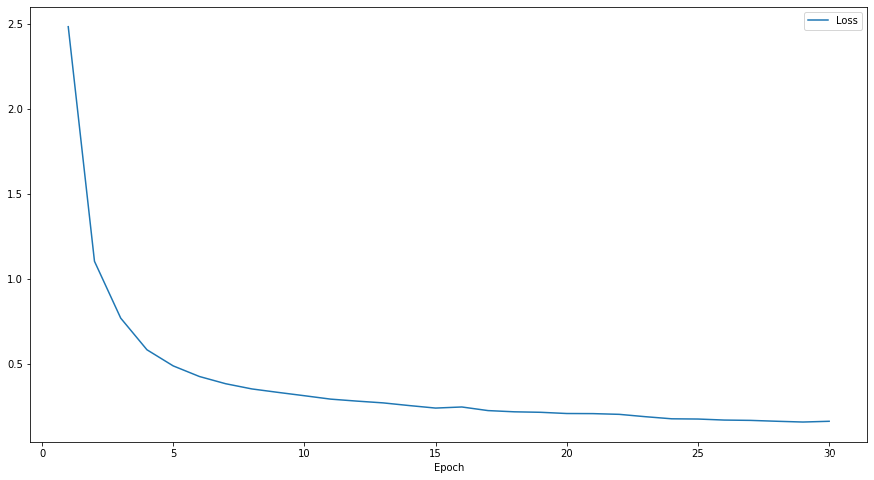
划分数为3
损失函数
在三个数据集上的准确率
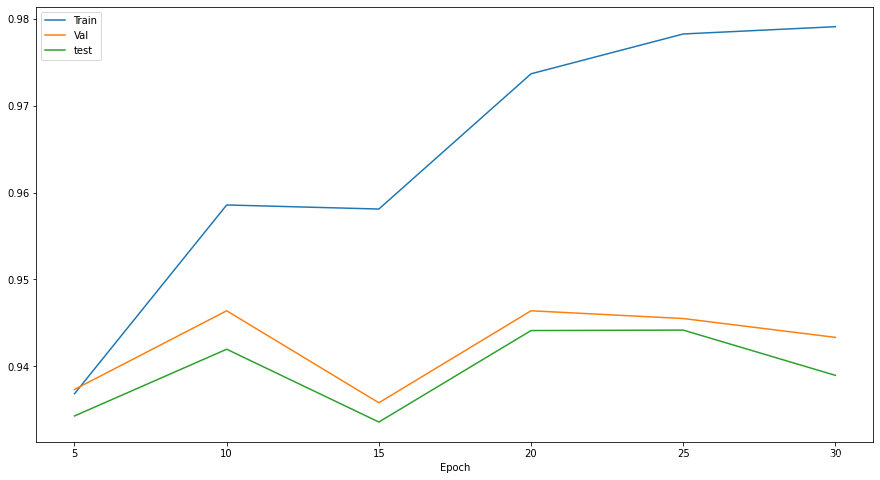
最终在训练集上的准确率为97.9%,验证集上的准确率为94.3%,测试集上的准确率为93.8%。 -
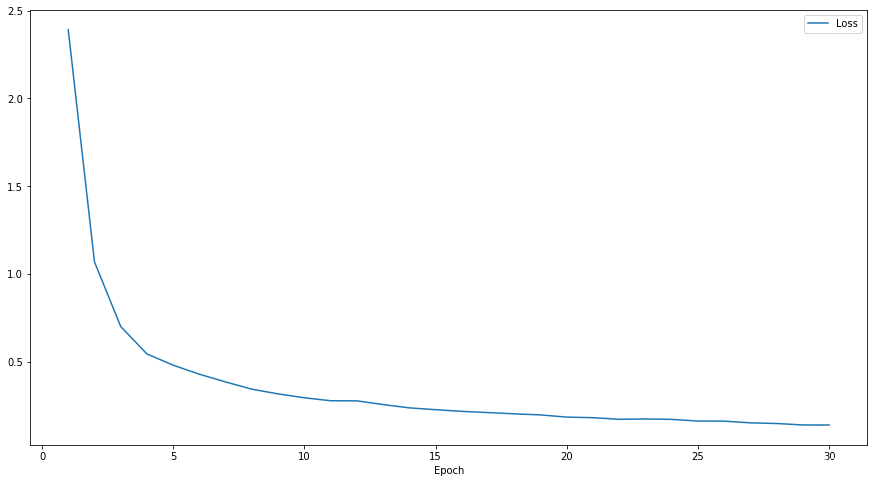
划分数为4
损失函数
在三个数据集上的准确率
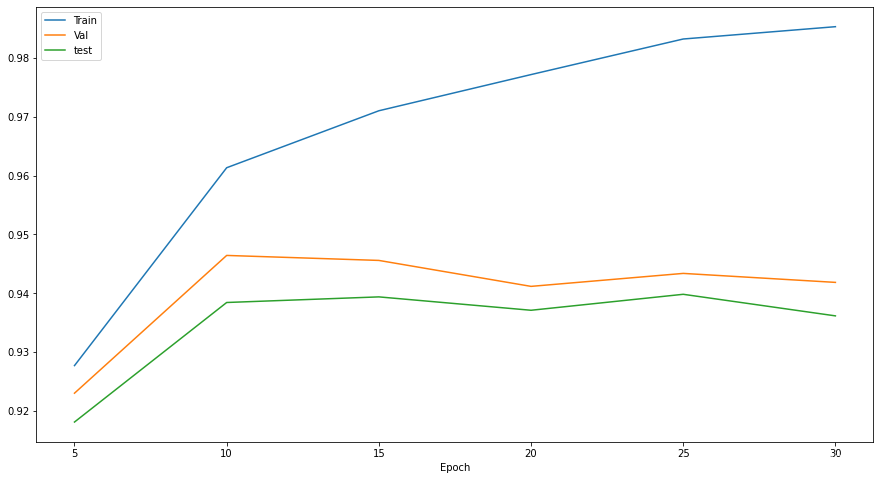
最终在训练集上的准确率为98.5%,验证集上的准确率为94.2%,测试集上的准确率为93.6%。 -
划分数为5
损失函数
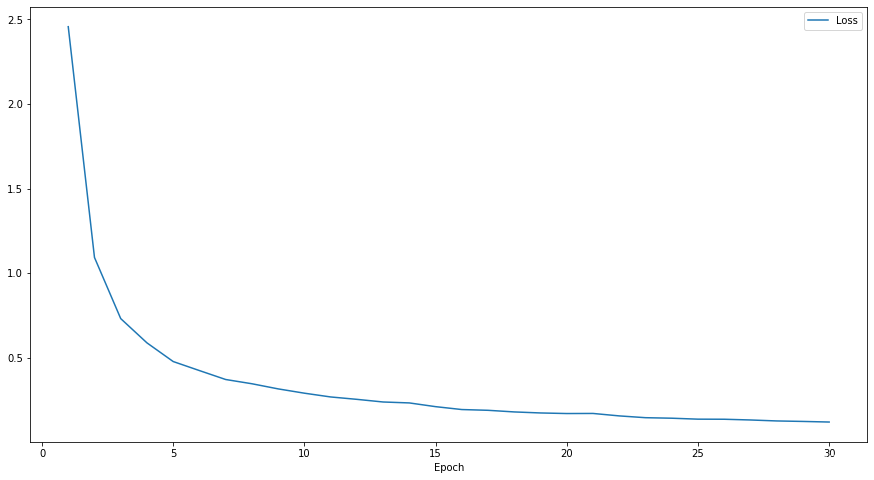
在三个数据集上的准确率
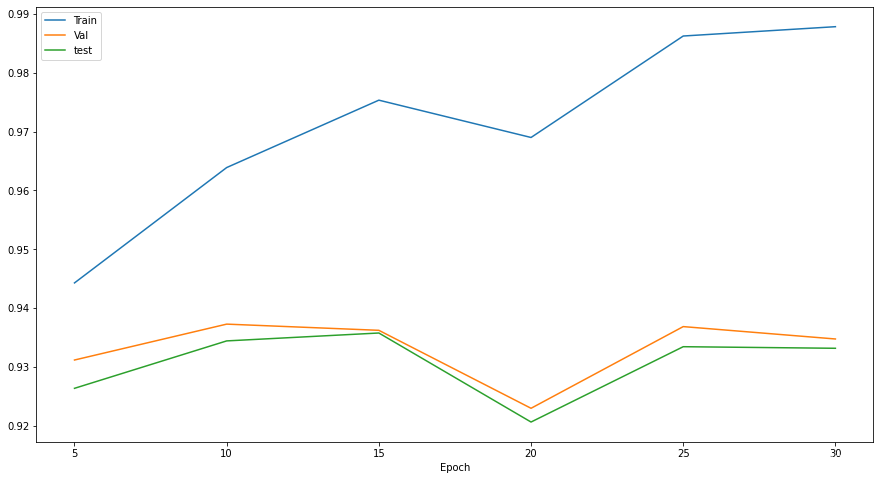
最终在训练集上的准确率为98.7%,验证集上的准确率为93.4%,测试集上的准确率为93.3%。 -
划分数为6
损失函数
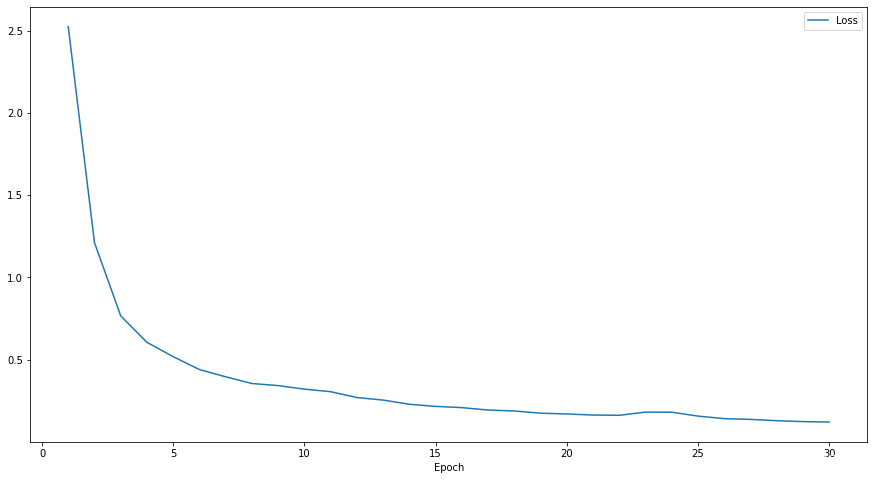
在三个数据集上的准确率
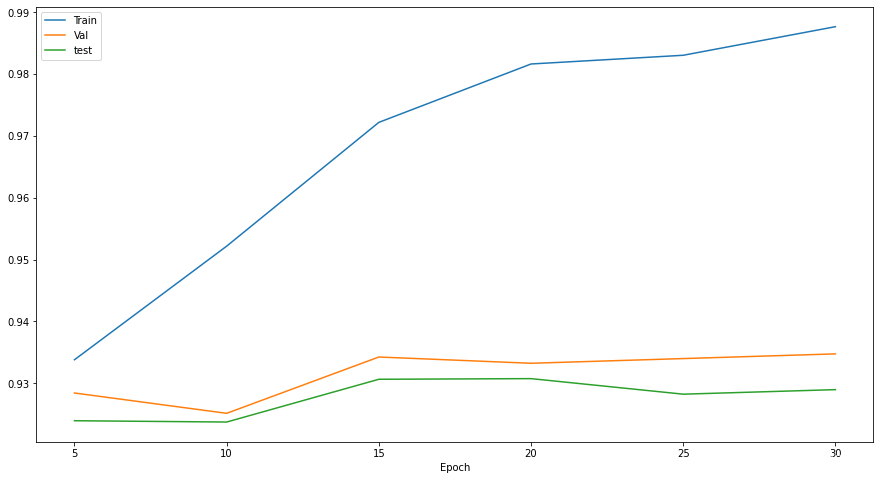
最终在训练集上的准确率为98.7%,验证集上的准确率为93.4%,测试集上的准确率为92.8%。
2.3.4 不同节点数量训练效果对比
小结上述结果如下表
| 节点数量 | 232965 | 77696 | 57786 | 46793 | 39029 |
|---|---|---|---|---|---|
| 训练集上准确率 | 95.8% | 97.9% | 98.5% | 98.7% | 98.7% |
| 验证集上准确率 | 94.2% | 94.3% | 94.2% | 93.4% | 93.4% |
| 测试集上准确率 | 94.1% | 93.8% | 93.6% | 93.3% | 92.8% |
可以看到,该网络随着数据集节点数的减少,虽然训练集上的准确性增加,但验证集及测试集的准确性均基本出现下降,出现了一定程度的过拟合。
参考阅读
- Datawhale组队学习
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!