Python词频统计——《红楼梦》人物出场次数统计
代码实现
import jieba as j
names = ['贾母', '贾珍', '贾蓉', '贾赦', '贾政', '袭人', '王熙凤', '紫鹃', '翠缕', '香菱','豆官', '薛蝌', '薛蟠', '贾宝玉', '林黛玉', '平儿', '薛宝钗', '晴雯', '甄费', '林之孝']
txt = open('红楼梦.txt', 'r', encoding='utf-8').read()
words = j.lcut(txt)
counts = {}
for word in words:if len(word) == 1:continueelif word in ["老太太", "老祖宗", "史太君", "贾母"]:word = "贾母"elif word in ["贾珍", '珍哥儿', '大哥哥']:word = "贾珍"elif word in ["老爷", '贾政']:word = "贾政"elif word in ["宝二爷", '宝玉', '贾宝玉']:word = "贾宝玉"elif word in ["王熙凤", "熙凤", "凤辣子", "贾琏"]:word = "王熙凤"elif word in ['紫鹃', '鹦哥']:word = '紫鹃'elif word in ['翠缕', '缕儿']:word = '翠缕'elif word in ['香菱', '甄英莲']:word = '香菱'elif word in ['豆官', '豆童']:word = '豆官'elif word in ["林黛玉", "潇湘妃子", "林丫头", "林妹妹", "黛玉"]:word = "林黛玉"elif word in ["薛宝钗", "宝姑娘", "宝丫头", "蘅芜君", "宝姐姐", '宝钗']:word = "薛宝钗"elif word in ["甄费", '甄士隐']:word = "甄费"if word in names:counts[word] = counts.get(word, 0) + 1items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
for i in range(len(items)):word, count = items[i]print('{0:<3}{1:>5}'.format(word, count))
运行结果
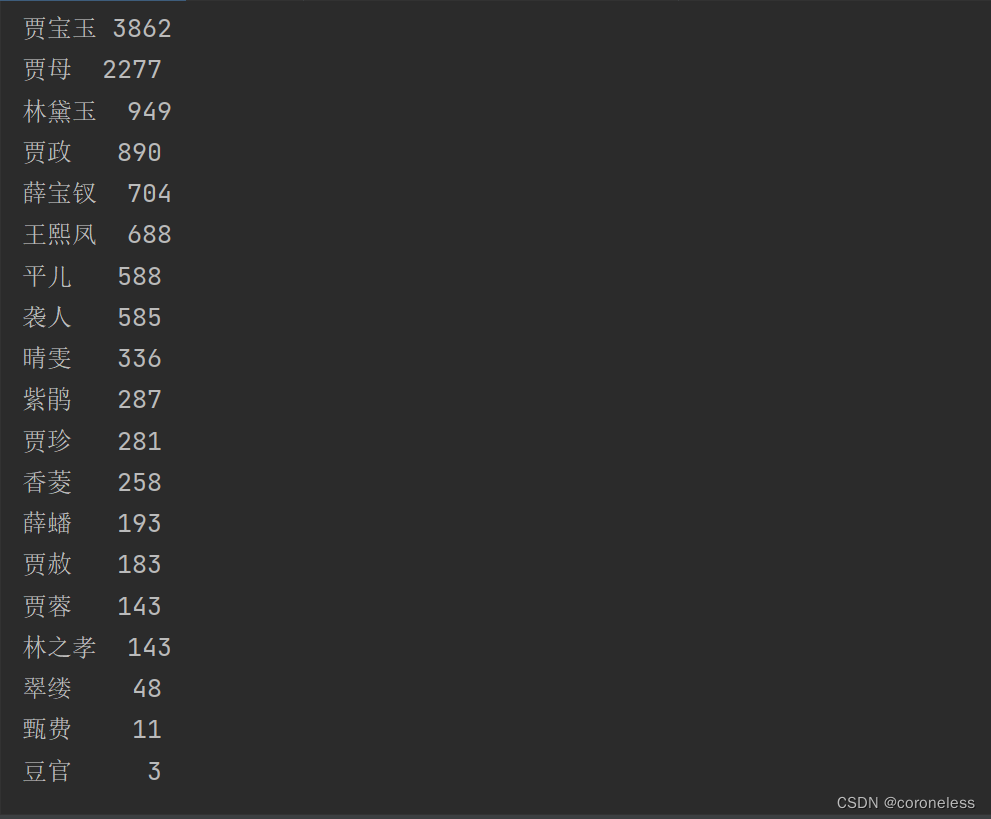
以下进行代码的逐行拆解。
代码讲解
首先,导入库。
import jieba as j之后,建立一个保存主要人物名称的列表names,主要人物可自行百度。
names = ['贾母', '贾珍', '贾蓉', '贾赦', '贾政', '袭人', '王熙凤', '紫鹃', '翠缕', '香菱','豆官', '薛蝌', '薛蟠', '贾宝玉', '林黛玉', '平儿', '薛宝钗', '晴雯', '甄费', '林之孝']然后,打开红楼梦txt文档,用lcut()进行分词,将分词结果保存在变量words中。
txt = open('红楼梦.txt', 'r', encoding='utf-8').read()
words = j.lcut(txt)设置字典counts用以保存人物出场的次数。
counts = {}对变量words进行for循环,设置word长度为1时不计数。
for word in words:if len(word) == 1:continue设置多分支条件,目的是将一个人物的不同称谓或别号所出现的次数归为这个人物的出场次数,如
“老太太”、“老祖宗”、“史太君”等这些称谓其实都是在指贾母,我们需要将这些词替换为“贾母”便于词频统计。
至于为什么替换为“贾母”而不是其他的称谓,是因为要与上面的names列表相对应。
人物的其它称谓或别号可自行百度。
elif word in ["老太太", "老祖宗", "史太君", "贾母"]:word = "贾母"elif word in ["贾珍", '珍哥儿', '大哥哥']:word = "贾珍"elif word in ["老爷", '贾政']:word = "贾政"elif word in ["宝二爷", '宝玉', '贾宝玉']:word = "贾宝玉"elif word in ["王熙凤", "熙凤", "凤辣子", "贾琏"]:word = "王熙凤"elif word in ['紫鹃', '鹦哥']:word = '紫鹃'elif word in ['翠缕', '缕儿']:word = '翠缕'elif word in ['香菱', '甄英莲']:word = '香菱'elif word in ['豆官', '豆童']:word = '豆官'elif word in ["林黛玉", "潇湘妃子", "林丫头", "林妹妹", "黛玉"]:word = "林黛玉"elif word in ["薛宝钗", "宝姑娘", "宝丫头", "蘅芜君", "宝姐姐", '宝钗']:word = "薛宝钗"elif word in ["甄费", '甄士隐']:word = "甄费"进行人物的词频统计,这里只会统计保存在names列表里的人物名称的出场次数,可以自行添加需要统计出场次数的人物名称。
counts[word]设置了字典的键,如果word在names人物名称列表中,则其在counts字典中的值加1。
if word in names:counts[word] = counts.get(word, 0) + 1将字典counts的键值对转化成列表并保存在变量items当中。
items = list(counts.items())
通过print(items)语句,可以发现items变成了一个二维数据,下图为输出结果截图。

然后我们进行出场次数的排序,reverse=True指定降序排序。
items.sort(key=lambda x: x[1], reverse=True)最后for循环,对人物出场次数进行格式化输出。
for i in range(len(items)):word, count = items[i]print('{0:<3}{1:>5}'.format(word, count))
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!