爬虫-豆瓣-2021.7.23-书籍排行榜前30页及每页读者和地址信息
1.环境
python3.7
pycharm2020.1
2.准备工作
2.1安装lxml
在cmd模式下,
pip install lxml在cmd模式下测试
python
import lxml如果没有报错,那么就证明库已经安装好了。
2.2安装BeautifulSoup
在cmd模式下
pip install beautifulsoup4在python编译器中测试
from bs4 import BeautifulSoup
soup = BeautifulSoup('Hello
', 'lxml')
print(soup.p.string)运行结果为:Hello
2.3安装requests
在cmd模式下
pip install requests在cmd模式下测试
python
import requests2.4 安装pyquery
在cmd模式下
pip install pyquery在cmd模式下测试
python
import pyquery3.爬虫代码
3.1 把内容写入文件代码
def write_to_file(content):with open('result5.txt', 'a', encoding='utf-8') as f:f.write(json.dumps(content, ensure_ascii=False))3.2 文件换行
def write_to_file_next():with open('result5.txt', 'a', encoding='utf-8') as f:f.write(json.dumps('', ensure_ascii=False) + '\n')3.3 获取网页页面信息
def get_one_page(url):time.sleep(1 + random.random() * 2)response = requests.get(url, headers=headers)if response.status_code == 200:return response.textreturn None其中time.sleep(1 + random.random() * 2),是为了反爬虫。必须要有,不然会封IP。
3.4 解析排行榜信息——正则表达式方式提取
正则表达式的方式比较麻烦,特别容易出错,不推荐使用
def get_book_all_infos(html):pattern = re.compile('.*?\s*(.*?)\s*''.*?.*?.*?''.*?(.*?)''.*?\s*(.*?)\s*', re.S)# 得到排行榜中书籍的基本信息items = re.findall(pattern, html)# 根据基本信息(书籍的href)得到该书籍的所有读者信息get_one_book_readers(item[0])for item in items:print("写入了书籍基本信息href")write_to_file(item[0])print("写入了书籍基本信息title")write_to_file(item[1])print("写入了书籍基本信息pub")write_to_file(item[2])print("写入了书籍基本信息score")write_to_file(item[3])print("写入了书籍基本信息population")write_to_file(item[4])get_one_book_readers_info(item[0])write_to_file_next() 3.5 获取读者所有信息
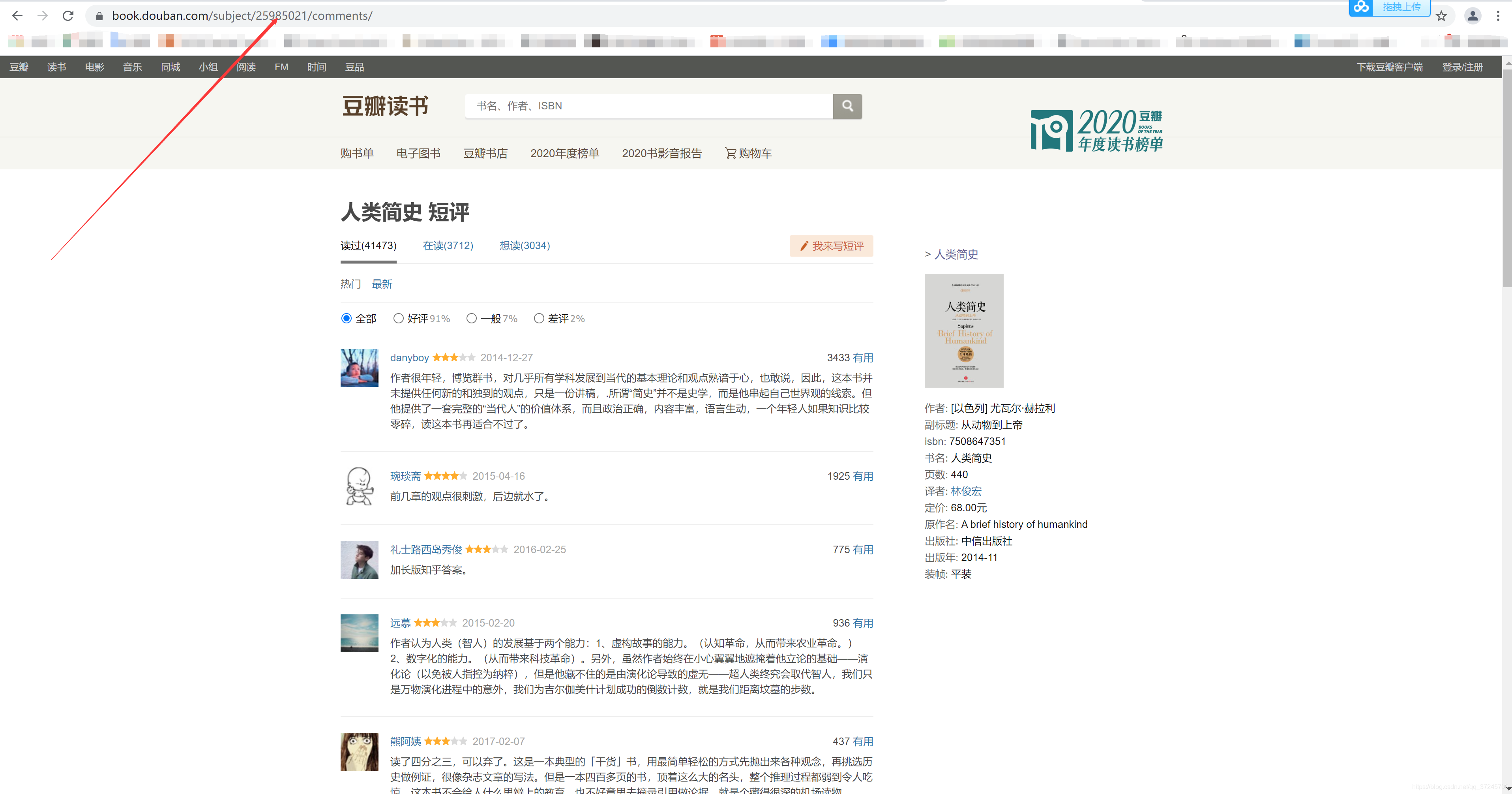
可以根据3.4 获取的书籍链接,找到该本书籍的评论列表链接。如,根据链接“https://book.douban.com/subject/25985021/”
可以点击评价人数,进入评价列表,如下图所示。
通常第一页看不出什么规律,需要跳转到第二页,就能看出网页地址的规律,这里就不放图了。
这里的规律是url + "comments/?start=" + str(offset * 20) + "&limit=20&status=P&sort=new_score"。offset在不断变化。
3.5.1 获取用户评论信息——pyquery方式提取
“F12”查看网页信息。
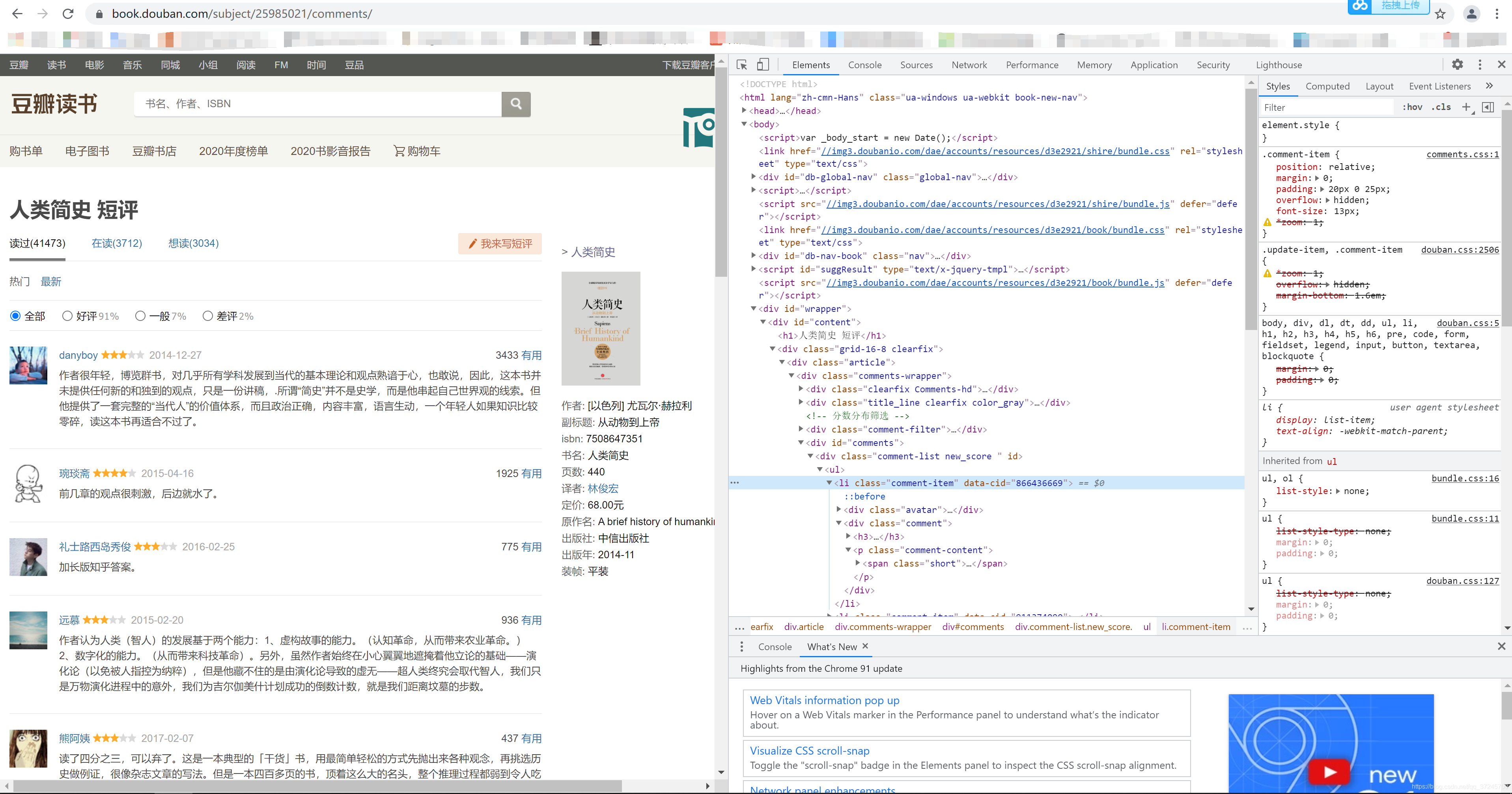
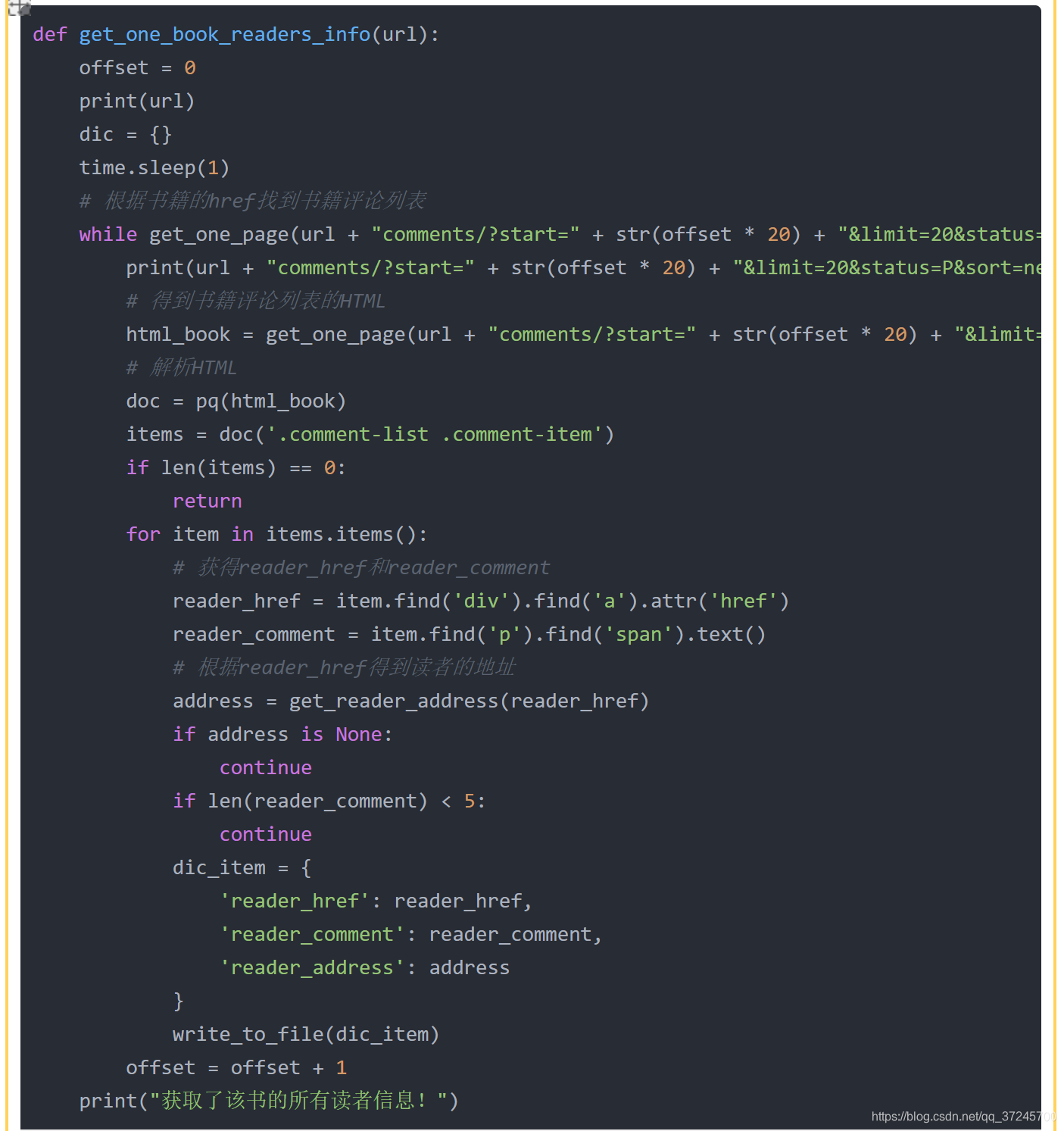
可以看到网页的每个评论都在节点“comment-item”中,因此用pyquery获取这些节点。
然后再一次遍历这些节点,获取节点中的各种信息。
3.5.2 获取用户地址信息——用BeautifulSoup提取信息
同上一样,查看网页信息,找到需要查找的节点的属性名或者节点名。然后定位到这个位置提取信息。
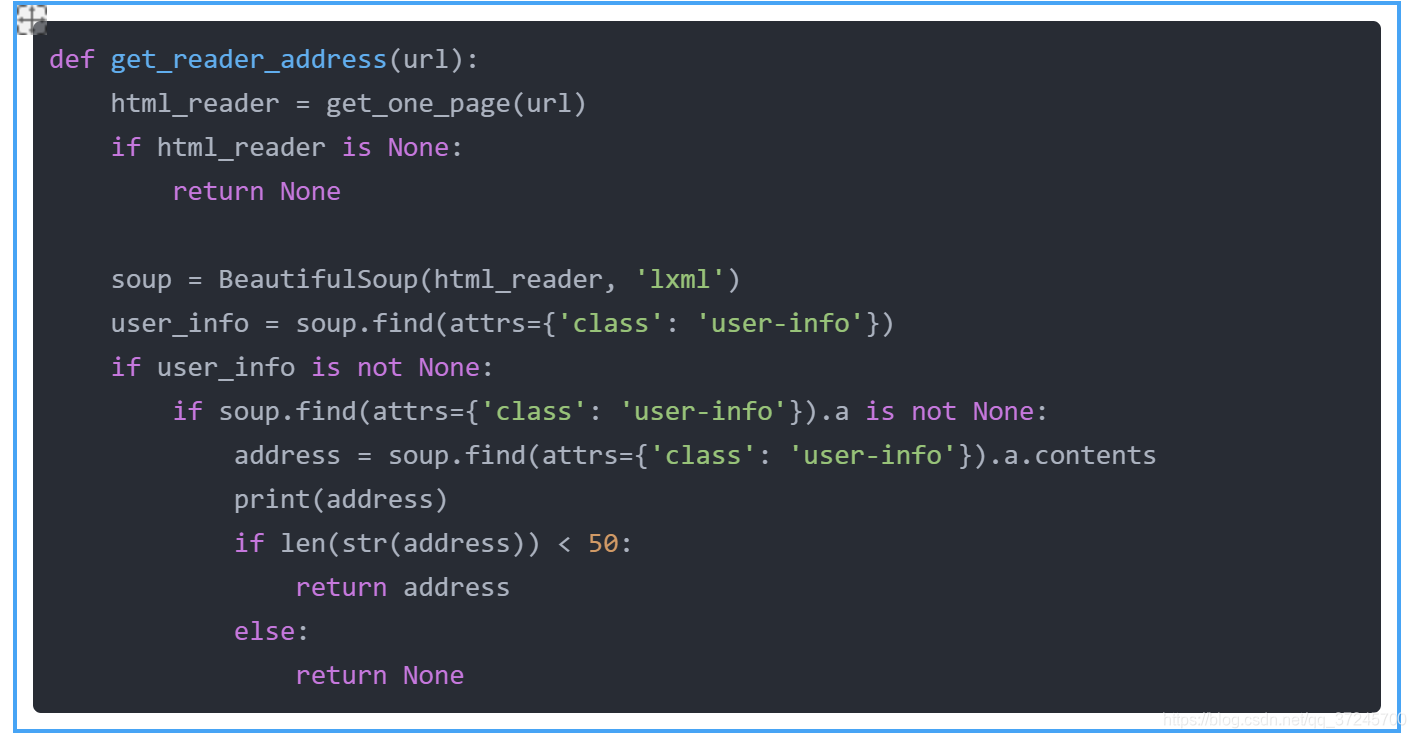
上面代码中的
if html_reader is None:return None是因为豆瓣在没有登录的情况下,只能访问前10页,后面的虽然能访问,但是没有信息,或者拒绝访问,所以这部分代码作为退出条件。
4 完整代码下载
https://download.csdn.net/download/qq_37245700/20430456?spm=1001.2014.3001.5501
导入相应包后可直接运行
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!