Datawhale 9月份学习笔记一之 图解Attention
Datawhale 学习笔记一之 图解Attention
学习路径:Attention–>Transformer–>BERT–>NLP
Attention 出现的原因:
基于循环神经网络(RNN)一类的seq2seq模型,在处理长文本时遇到了挑战,而对长文本中不同位置的信息进行attention有助于提升RNN的模型效果。
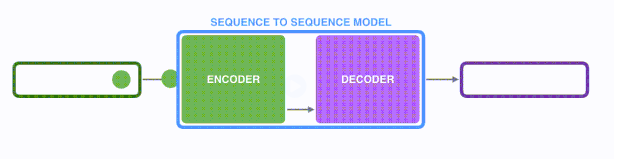
1. seq2seq框架
seq2seq模型由编码器(Encoder)和解码器(Decoder)组成。以基于RNN的seq2seq 模型,机器翻译任务为例。
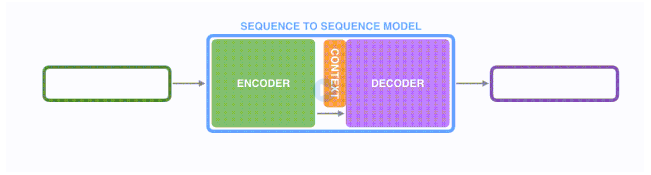
绿色的编码器会处理输入序列中的每个元素并获得输入信息,这些信息会被转换成为一个黄色的向量(称为context向量)。当我们处理完整个输入序列后,编码器把 context向量 发送给紫色的解码器,解码器通过context向量中的信息,逐个元素输出新的序列。(seq2seq模型是传递最后一个hidden state(隐藏层状态) 给解码器 )
第一步:
第二步:
第三步:
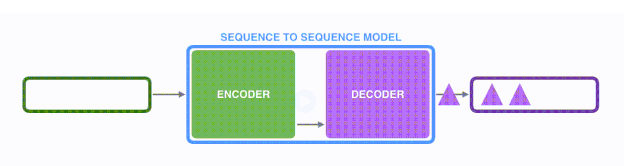 以上基于RNN的seq2seq模型编码器将所有信息都编码到了一个context向量中。
以上基于RNN的seq2seq模型编码器将所有信息都编码到了一个context向量中。
缺点:
1)单个向量很难包含所有文本序列的信息;
2)RNN递归地编码文本序列使得模型在处理长文本时面临非常大地挑战。
解决办法:
提出一种叫做注意力Attention的技术。通过attention技术,seq2seq模型极大地提高了机器翻译的质量。归其原因是:attention注意力机制,使得seq2seq模型可以有区分度、有重点地关注输入序列。
2. 注意力模型
不同于seq2seq模型,注意力模型:
1)编码器会把更多的数据传递给解码器。编码器把所有时间步的 hidden state(隐藏层状态)传递给解码器,而不是只传递最后一个 hidden state(隐藏层状态)
 2) 注意力模型的解码器在产生输出之前,做了一个额外的attention处理。具体为:
2) 注意力模型的解码器在产生输出之前,做了一个额外的attention处理。具体为:
- 由于编码器中每个 hidden state(隐藏层状态)都对应到输入句子中一个单词,那么解码器要查看所有接收到的编码器的 hidden
state(隐藏层状态)。 - 给每个 hidden state(隐藏层状态)计算出一个分数(我们先忽略这个分数的计算过程)。
- 所有hidden state(隐藏层状态)的分数经过softmax进行归一化。
- 将每个 hidden state(隐藏层状态)乘以所对应的分数,从而能够让高分对应的 hidden
state(隐藏层状态)会被放大,而低分对应的 hidden state(隐藏层状态)会被缩小。 - 将所有hidden state根据对应分数进行加权求和,得到对应时间步的context向量。
 attention可以简单理解为:一种有效的加权求和技术,其艺术在于如何获得权重。
attention可以简单理解为:一种有效的加权求和技术,其艺术在于如何获得权重。
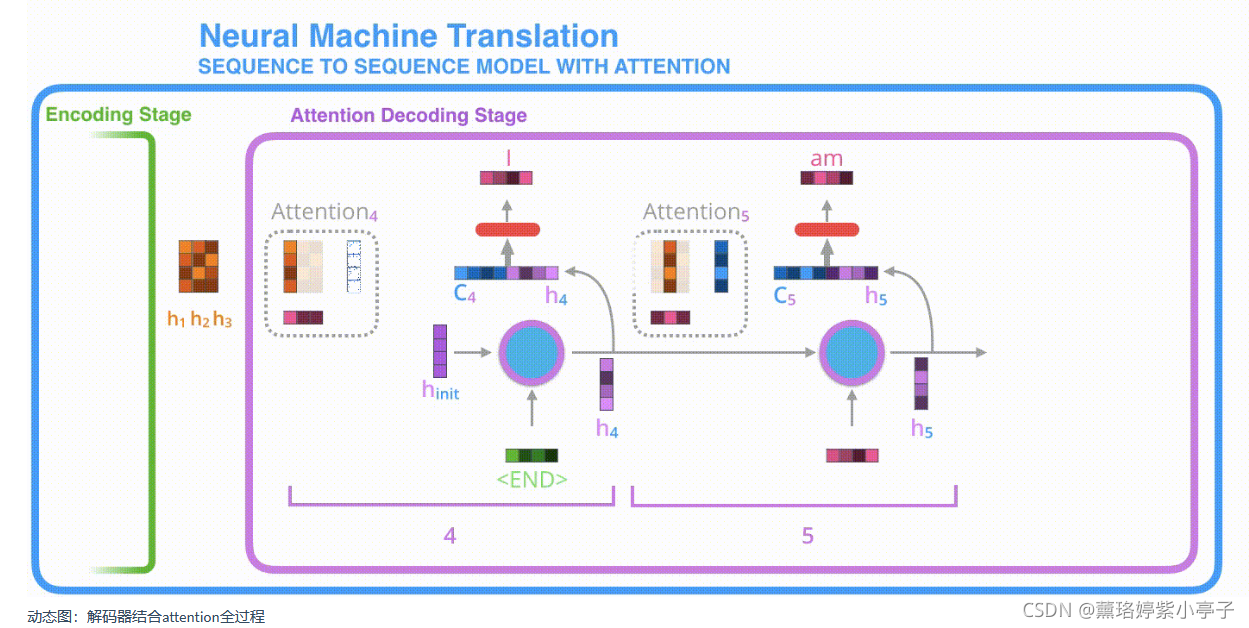
3.结合注意力的seq2seq模型解码器全流程
- 1 .注意力模型的解码器 RNN 的输入包括:一个word embedding 向量,和一个初始化好的解码器 hidden
state,图中是hinith_{init}hinit。 - 2 .RNN 处理上述的 2 个输入,产生一个输出和一个新的 hidden state,图中为h4。
- 3 . 注意力的步骤:我们使用编码器的所有 hidden state向量和 h4 向量来计算这个时间步的context向量(C4)。
- 4 .我们把 h4 和 C4 拼接起来,得到一个橙色向量。
- 5 .我们把这个橙色向量输入一个前馈神经网络(这个网络是和整个模型一起训练的)。
- 6 .根据前馈神经网络的输出向量得到输出单词:假设输出序列可能的单词有N个,那么这个前馈神经网络的输出向量通常是N维的,每个维度的下标对应一个输出单词,每个维度的数值对应的是该单词的输出概率。
- 7 .在下一个时间步重复1-6步骤。
具体地,动态图如下:
一、产生第一个单词的步骤:
 一、产生第二个单词的步骤:
一、产生第二个单词的步骤:
参考链接:十分感谢一群DataWhale小伙伴提供的资料~ 图解Attention
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!