python findall函数_Ramp;Python Data Science系列:数据处理(11)Python正则表达式re模块(三)...

前言
使用正则表达式进行匹配,可以直接调用模块级函数,如match()、search()、findall()等,函数第一个参数是匹配的正则表达式,第二个参数则为要匹配的字符串。也可以使用re.compile()先将正则表达式编译成RegexObject对象,然后再调用RegexObject对象的方法,参数为要匹配的字符串。例如:
re.search(r'flash', 'Flash_WorkingNotes', re.I).group()
等价于
p = re.compile(r'flash', re.I)
p.search('Flash_WorkingNotes').group()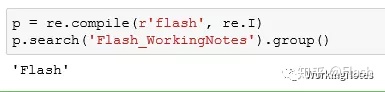
如果匹配的正则表达式只用一次,模块级函数使用起来很方便;若项目中包含多个正则表达式或者一个正则表达式被多次使用,编译成RegexObject对象更方便一些。以下内容,先编译成正则表达式对象,然后再调用这些对象的方法。
5.2.3 RegexObject的方法和MatchObject的方法
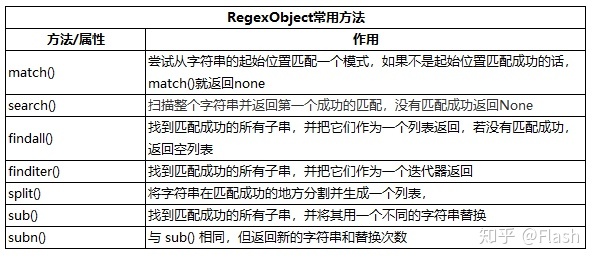
re模块提供了一个正则表达式引擎接口,可以将正则表达式编译成对象并用它们进行匹配。使用re.compile()将正则表达式编译成RegexObject对象,有对象就有方法可以调用,RegexObject对象常用方法有match()、search()、findall()、finditer()、split()、sub()以及subn()。
match()和search()匹配成功的话返回一个MatchObject实例,findall()、split()、sub()以及subn()返回一个列表,finditer()返回一个迭代器。
- match()函数
match()函数检查RE是否在字符串开始处匹配,match()函数只返回一次成功的匹配,从0开始,如果不是从0匹配成功,返回None。如果匹配成功,返回一个MatchObject 对象,可以通过group方法获取匹配成功的整个字符串。
1 匹配成功
p = re.compile('Flash', re.I)
p.match('flash workingnotes')
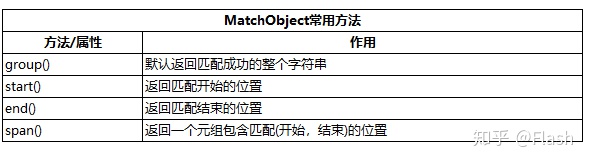
匹配成功的话,返回一个MatchObject对象,可以调用MatchObject的方法。
2 使用group()函数返回匹配成功的整个字符串
p = re.compile('Flash', re.I)
p.match('flash workingnotes').group()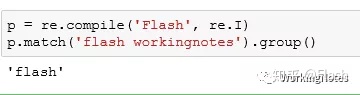
3 使用start()返回匹配开始的位置
p = re.compile('Flash', re.I)
p.match('flash workingnotes').start()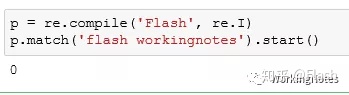
4 使用end()返回匹配结束的位置
p = re.compile('Flash', re.I)
p.match('flash workingnotes').end()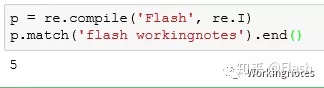
5 使用span()返回一个元组包含匹配(开始,结束)的位置
p = re.compile('Flash', re.I)
p.match('flash workingnotes').span()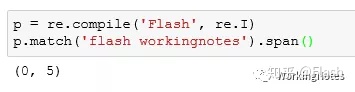
6 匹配失败
p = re.compile('Flash', re.I)
print(p.match('workingnotes flash'))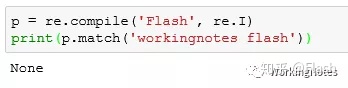
- search()函数
search()函数检查整个字符串,匹配成功,返回一个匹配对象MatchObject,没有匹配成功返回None
1 匹配成功
p = re.compile('Flash', re.I)
print(p.search('workingnotes flash'))
2 使用group()函数返回匹配成功的整个字符串
p = re.compile('Flash', re.I)
print(p.search('workingnotes flash').group())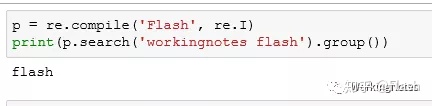
3 使用start()返回匹配开始的位置
p = re.compile('Flash', re.I)
print(p.search('workingnotes flash').start())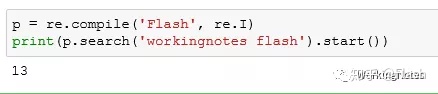
4 使用end()返回匹配结束的位置
p = re.compile('Flash', re.I)
print(p.search('workingnotes flash').end())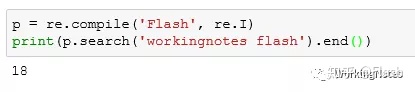
5 使用span()返回一个元组包含匹配(开始,结束)的位置
p = re.compile('Flash', re.I)
print(p.search('workingnotes flash').span())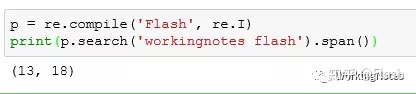
6 匹配失败
p = re.compile('Flash', re.I)
print(p.search('workingnotes fash'))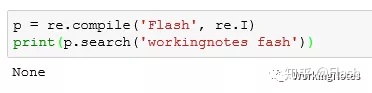
- findall()函数
findall()函数找到匹配成功的所有子串,并把它们作为一个列表返回,若没有匹配成功,返回空列表
1 匹配成功
p = re.compile('Flash', re.I)
print(p.findall('flash workingnotes Flash Workingnotes'))
编译正则表达式的时候,使用标志re.I,匹配时候不区分大小写,所以成功匹配flash和Flash。
2 匹配失败
p = re.compile('Flash', re.I)
print(p.findall('flah workingnotes Flah Workingnotes'))
- finditer()函数
finditer()函数找到匹配成功的所有子串,并把它们作为一个迭代器返回
p = re.compile('Flash', re.I)
print(p.finditer('flash workingnotes Flash Workingnotes'))
p = re.compile('Flash', re.I)
p1 = p.finditer('flash workingnotes Flash Workingnotes')
for match in p1:
print(match.group())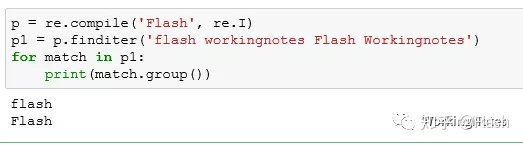
- split()函数
split()函数基于正则表达式的模式分隔字符串,通过参数max指定最大分割数。
如果找不到匹配的字符串的话,不进行分割。
1 使用非字母数字字符分割字符串
p = re.compile(r'W+')
p.split('Flash,Workingnotes.flash+Workings FlashWorkingnotes')
2 使用非字母数字字符分割字符串,限制最大分割次数为2
p = re.compile(r'W+')
p.split('Flash,Workingnotes.flash+Workings FlashWorkingnotes', 2)
3 匹配不到
p = re.compile(r'd')
p.split('Flash,Workingnotes.flash+Workings FlashWorkingnotes', 2)
- sub()函数和subn()函数
sub()函数和subn()函数用于搜索和替换,sub()函数找到匹配成功的所有子串,并将其用一个不同的字符串替换;subn()函数找到匹配成功的所有子串,并将其用一个不同的字符串替换,并且返回新的字符串和替换次数的元组。参数count可用于指定最大替换的次数。
1 使用gmy替换F(f)lash
p = re.compile(r'Flash', re.I)
p.sub('gmy', ('flash workingnotes Flash Workingnotes'))
2 使用gmy替换F(f)lash,替换次数为1次
p = re.compile(r'Flash', re.I)
p.sub('gmy', ('flash workingnotes Flash Workingnotes'), 1)
3 subn()函数与sub()函数一样,返回的是包含新字符串和替换执行次数的元组
p = re.compile(r'Flash', re.I)
p.subn('gmy', ('flash workingnotes Flash Workingnotes'))
p = re.compile(r'Flash', re.I)
p.subn('gmy', ('flash workingnotes Flash Workingnotes'),1)
6 总结
用了三部分介绍了Python之正则表达式re模块,这里只是抛砖引玉,选择性的介绍部分内容,没有介绍的可以参考https://docs.python.org/zh-cn/3/library/re.html。按照计划,后面进入到可视化内容的介绍。
关于作者:从事风控方面工作,数据科学爱好者,微信公众号WorkingNotes,欢迎交流。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!