python之简单爬虫(爬取豆瓣出版社)
环境准备:
1.python 3.0+
2.豆瓣出版社网址 https://read.douban.com/provider/all
ok,开始我们的实验
1.打开浏览器,输入网址,右击网页,查看网页源码,这里我用的是谷歌浏览器

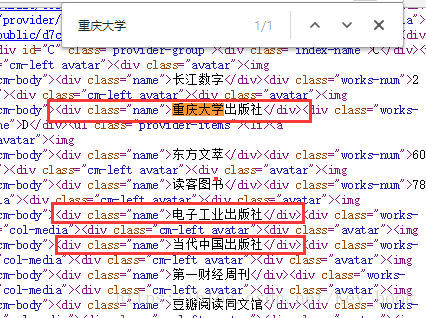
2.看上图我们发现许多出版社名称,接下来我们查找一个出版社名称,例如重庆大学
观察下图我们发现它们都在一个div标签内,且class=”name” ,所以,我们开始编写代码
3.代码
import urllib.request
import re
import os
url = "https://read.douban.com/provider/all" #获取url
pat = '(.*?)' #匹配规则
data = urllib.request.urlopen(url).read().decode("utf-8") #读取网页的内容并解码
relut = re.compile(pat).findall(data) #会返回一个列表
file = open(r"C:\Users\123\豆瓣出版社.txt", "w", encoding="utf-8") #这里我定义了一个自己的存储路径,大家可以根据自己的路径修改
for i in relut:file.write(i) #将出版社名称写入文件file.write("\n") #表示换行4.最后在你的存储目录下打开文件就可以查看内容了!

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!