dqn在训练过程中loss越来越大_DQN算法实现注意事项及排错方法
在学习强化学习过程中,自己实现DQN算法时,遇到了比较多的问题,花了好几天的时间才得以解决。最后分析总结一下,避免再走弯路。
有可能开始实现出来的DQN算法,无论怎么训练总是看不错成果。需要注意的地方比较多,一步一步的来分析:
一、确定算法实现本身是否正确
算法学习的过程一般是:学习算法相关的资料,然后自己动手实现算法来进行训练。当训练总是失败时,就去网上找别人对这个算法的实现,然后对比自己的实现和别人实现的差异来纠错。
但这个时候比较容易遇到坑,因为别人的实现可能会有几个问题:
- 算法仅有一份代码实现,根本就不能复现效果和解决问题,有的甚至根本就无法运行。
- 很多算法的实现是那些正在学习算法的人写的(比如我这种),而不是对算法有很好的理解的人写的。也就是说,算法的实现完全就是错的。只是误打误撞,恰好训练时有点效果。
所以,就需要注意下面几个方面:
1、确定算法实现必须有哪些部分。
如果确定呢?比如看算法论文的原文,或者看大学的公开课等。
DQN算法的实现中应该包含目标网络(target network)和经验回放(Experience Replay)相关的代码。因为这是算法论文中有提到的。
Playing Atari with Deep Reinforcement Learningarxiv.org网络上有很多DQN算法的实现,但是有不少的实现是没有目标网络(target network)的,搜到这种文章还是直接跳过吧。
2、留意算法实现的细节
在DQN算法中,done参数是需要使用。网络上有不少DQN算法的实现是没有使用done参数进行训练的。

经过实际的对比测试发现,DQN算法中不使用done参数有时甚至将导致算法不能收敛。完整的代码和数据在这里。
3、区分算法本身和算法的变种
DQN算法有不少的变种,比如:Double-Q Learning,Dueling DQN等。如果你看的是权威算法的实现,可以肯定算法本身是不会错的。但是实现细节又和学习到的算法原理不同,那么有可能你看到的不是原始算法的实现,而是其变种。
二、了解不同环境对训练和算法收敛的影响
一般我们训练时使用的环境是gym,在测试DQN算法时,常用的环境有两个:
1、CartPole

立杆子游戏CartPole的特点是:如果算法模型越差,那么每一个游戏回合(episode)的时间就会越短,因为杆子倒下了游戏就马上结束了。
2、MountainCar
小车上山游戏MountainCar的特点是:如果算法模型越差,每一个游戏回合的时间就会越长,因为游戏结束的条件是要么小车上山,要么移动了200次。而开始训练算法时,小车是很难上山的,基本上都是移动次数超过限制游戏结束的。
当实现完算法需要验证算法的正确性时,结合上面两种环境的特点,推荐使用第一种环境来验证算法。原因如下:
第一种环境的特点是模型越差,游戏回合时间越短。当开始训练算法时,训练的速度就会比较快,如果算法正确收敛,那么会训练的越来越慢,比较好观察。
与之对比的是第二种环境,模型越差,游戏回合时间越长。训练开始时,因为每个回合的时间都比较长,在不借助其他工具的情况下,难以观察算法是否在收敛。所以就可能会出现算法本身是正确且收敛的,但是因为每回合时间太长,训练太耗时,所以短时间内看不出趋势就误认为算法是错误的。
三、善用tensorboardX来记录分析训练过程
训练过程中的数据对观察算法是否收敛和对比算法或超参数有很大的帮助。
1、观察算法是否收敛
最直观的,训练过程奖励(reward)的变化过程直接表明了算法是否收敛。
在此基础上,与环境相关的数据,比如游戏每回合的步数(step)也能反映算法是否收敛,CartPole环境每回合的步数应该慢慢增长,MountainCar环境每回合步数应该慢慢减少。
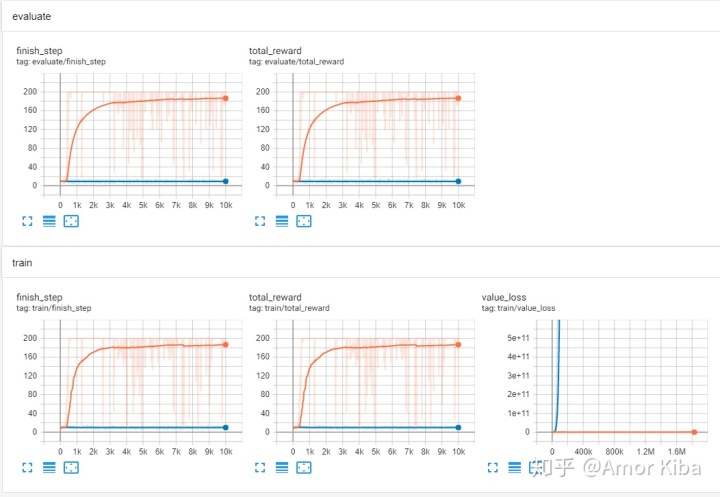
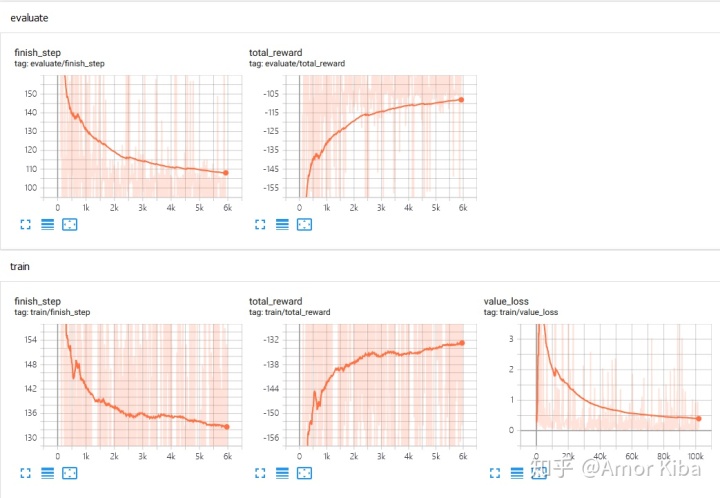
和算法相关数据,比如loss的值,在DQN算法中,loss的值应该慢慢减少,直到趋于平稳。
下图是DQN算法训练MountainCar-v0环境过程的tensorboardX截图,完整的代码和数据在这里。
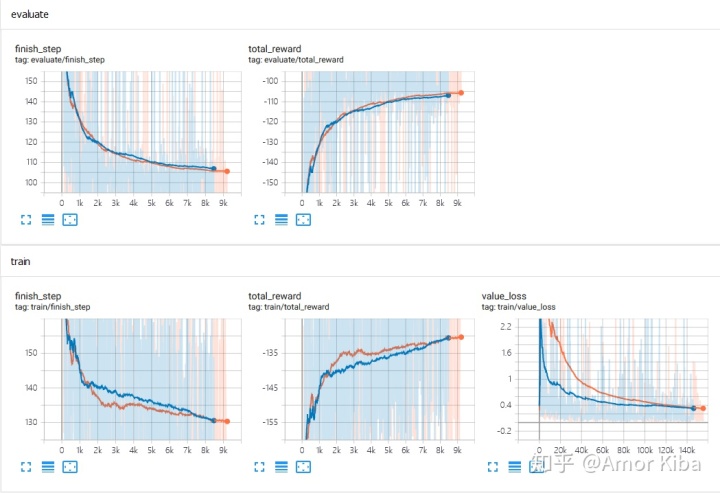
2、对比算法或超参数
可以对比不同算法或同个算法不同超参数值对算法的收敛,有助于直观的了解算法的性能和收敛的速度等。
下图是Deep Q-Learing(橙色线条)算法和Double-Q Learning(蓝色线条)训练MountainCar-v0环境过程的对比图,完整的代码和数据在这里。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!