机器学习-分类之决策树原理及实战
决策树
-
简介
- 决策树是一个非参数的监督学习方法,又称为判定树,是运用于分类的一种树结构,其中的每个内部节点代表对某一属性的一次测试,每条边代表一个测试结果,叶子节点代表某个类或者类的分布。
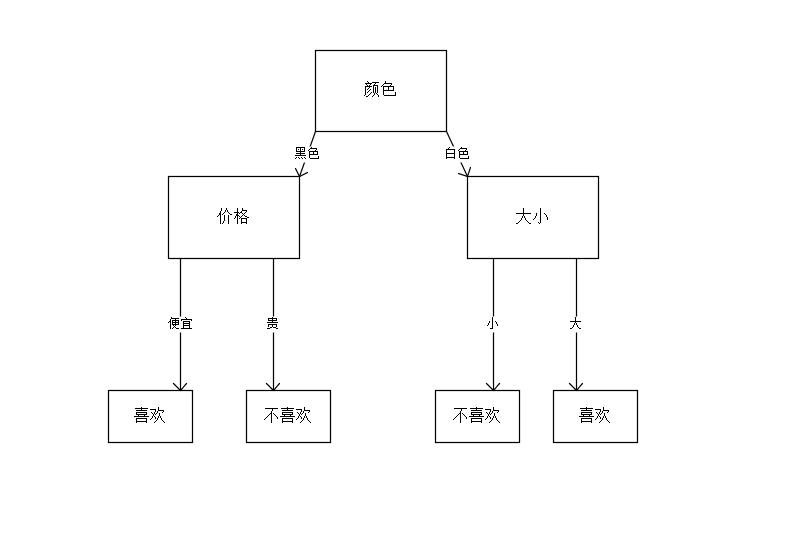
- 简单决策树
- 决策树的决策过程一般需要从决策树的根节点开始,将待测数据与决策树中的特征节点进行比较,并按照比较结果选择下一个比较分支,直到叶子节点作为最终的决策结果。决策树除了用于分类外,还可以用于回归和预测。分类树对离散变量做决策树,回归树对连续变量做决策树。
-
决策树学习
- 从数据产生决策树的机器学习技术称为决策树学习,通俗地说就是决策树。一个决策树一般包含以下3种类型的节点。
- 决策节点:是对几种可能方案的选择,即最后选择的最佳方案。如果决策属于多级决策,则决策树的中间可以有多个决策点,以决策树根部的决策点作为最终的决策方案。
- 状态节点:代表备选方案的经济效果(期望值),通过各状态节点的经济效果对比,按照一定的决策标准就可以选出最佳方案。由状态节点引出的分支称为概率枝,概率枝的数目表示可能出现的自然状态数目每个分支上要注明该状态出现的概率。
- 终节点:每个方案在各种自然状态下取得的最终结果,即树的叶子。
- 当然,作为机器学习的经典算法,决策树有其优缺点。
优点 缺点 简单易懂,原理清晰,可视化方便。 决策树有时候是不稳定的,因为数据微小的变动,可能生成完全不同的决策树。 决策树算法的时间复杂度(预测数据)是用于训练决策树的数据点的对数。 有些问题学习起来非常难,因为决策树很难表达,如异或问题、奇偶校验或多路复用器问题。 能够处理数值和分类数据。 如果有些因素占据支配地位,决策树是有偏差的。因此建议在拟合决策树之前先平衡数据的影响因子。 可以通过统计学检验验证模型。这使得模型的可靠性计算变得可能。 对连续性的字段比较难预测。 能够处理多路输出问题。 最优决策树的构建属于NP问题。 即使模型假设违反产生数据的真实模型,表现性能依旧很好。 - 决策树学习过程
- 决策树学习是数据挖掘中的一个经典方法,每个决策树都表现了一种树形结构,它由它的分支来对该类型的对象依靠属性进行分类。每个决策树可以依靠对源数据的分割进行数据测试。这个过程可以递归式地对树进行修剪。当不能再进行分割或者一个单独的类可以应用于某一分支时,递归过程就完成了。学习过程概括如下。
- 特征选择:从训练数据的特征中选择一个作为当前节点的分裂标准(特征选择的标准不同产生了不同的特征决策树算法,后面提到)。
- 决策树生成:根据所选特征评估标准,从上至下递归地生成子节点,直到数据集不可分时停止决策树生成。
- 剪枝:决策树容易过拟合,需要剪枝来缩小树的结构和规模。(包括预剪枝和后剪枝)
- 决策树学习是数据挖掘中的一个经典方法,每个决策树都表现了一种树形结构,它由它的分支来对该类型的对象依靠属性进行分类。每个决策树可以依靠对源数据的分割进行数据测试。这个过程可以递归式地对树进行修剪。当不能再进行分割或者一个单独的类可以应用于某一分支时,递归过程就完成了。学习过程概括如下。
- 从数据产生决策树的机器学习技术称为决策树学习,通俗地说就是决策树。一个决策树一般包含以下3种类型的节点。
-
决策树分类
- 流程
- 1.创建数据集。
- 2.计算数据集的信息熵。
- 3.遍历所有特征,选择信息熵最小的特征,即为最好的分类特征。
- 4.根据上一步得到的分类特征分隔数据集,并将该特征从列表中移除。
- 5.执行递归函数,返回步骤3,不断分隔数据集,直到分类结束。
- 6.使用决策树执行分类,返回分类结果。
- 不难发现,在构建决策树的过程中,要寻找划分数据集的最好特征。例如,一个数据集有10个特征,每次选取哪一个作为划分依据呢?这就必须采用量化的方法来进行判断,量化划分方法有很多,其中一项就是“信息论度量信息分类”,即使无序的数据变得有序。
- 基于信息论的决策树算法包括ID3、C4.5、CART等,这里不做具体介绍。其中涉及到了信息熵和信息增益的计算概念,可以查阅相关资料。
- 流程
-
Scikit-learn决策树算法类库
- sklearn实现了优化过的CART树算法,既可以分类也可以回归,对应的是DecisionTreeClassifier和DecisionTreeRegressor。参数类似,含义却完全不同。常用的方法为fit()和predict(),前者表示训练,后者表示预测。
-
决策树可视化
- 方法一
- graphviz安装即配置环境变量
- 方法二
- 使用pip安装pydotplus
- 方法一
-
实战
- 使用决策树对身高体重数据进行分类
- 说明
- 数据集给出特征为身高和体重,分类结果为胖瘦。
- 程序包含可视化代码。
- 代码实现
-
# -*-coding:utf-8 -*-import numpy as npimport scipy as spfrom sklearn import treefrom sklearn.metrics import precision_recall_curvefrom sklearn.metrics import classification_reportfrom sklearn.model_selection import train_test_splitdef getData():'''获取数据集:return:'''data = []labels = []with open("data/1.txt") as ifile:for line in ifile:tokens = line.strip().split(' ')data.append([float(tk) for tk in tokens[:-1]])labels.append(tokens[-1])x = np.array(data)labels = np.array(labels)y = np.zeros(labels.shape)y[labels == 'fat'] = 1return x, yif __name__ == '__main__':x, y = getData()x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)# 使用信息熵作为划分标准,对决策树进行训练clf = tree.DecisionTreeClassifier(criterion='entropy')print(clf)clf.fit(x_train, y_train)with open("tree.dot", 'w') as f:f = tree.export_graphviz(clf, out_file=f)# 系数反映每个特征的影响力。越大表示该特征在分类中起到的作用越大 '''print('两个特征所占的权重是:', clf.feature_importances_)# 测试结果显示answer = clf.predict(x_test)print('测试数据是:', x_test)print('测试数据使用模型预测对应的类是:', answer)print('测试数据对应的类是:', y_test)print(np.mean(answer == y_test))# 准确率与召回率'''precision, recall, thresholds = precision_recall_curve(y_train, clf.predict(x_train))answer = clf.predict_proba(x)[:, 1]print(classification_report(y, answer, target_names=['thin', 'fat']))# 落地模型import pydotplusdot_data = tree.export_graphviz(clf, out_file=None)graph = pydotplus.graph_from_dot_data(dot_data)graph.write_pdf("tree.pdf")
-
-
补充说明
- 考书《Python3数据分析与机器学习实战》
- 具体数据集和代码可以查看我的GitHub,欢迎star或者fork
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!