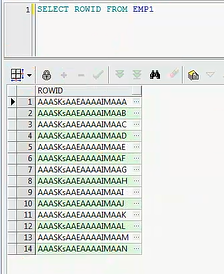
索引的说明,基本上就是说,我只是针对于ORACLE,索引是和表相关联的一个可选结构,也就是你可以建也可以不建,在逻辑上和物理上都有独立于表的数据,索引能优化查询,这个说的是毋庸置疑的,但不能优化DML操作,什么意思呢,就是这个东西就是两者之间永远是不可调和的事情,就好像你设计一张表,你建了一个索引,那么你去insert的时候,你除了把这条记录插入到表里以外,你还得把这条记录对应的索引给进行维护一下,这东西是永远都不可调和的,建两个索引你就得多维护一块,你建三个索引你就还得再多维护一块空间,那就是索引建多了,你进行写操作,那效率性能上,IO性能上就会降低,但是你的查询效率就会变快了,这是肯定的,你永远都没法去权衡,我们其实软件开发,大多数最多的情况下,其实都是两种方案取一个中间值,根据你自己的业务去做一个平衡,咱们软件在做设计的时候,用的最多的是用空间换时间,就是为了提高性能,牺牲一些空间,然后去换取时间,包括你做这个中间库,做这个缓存表,包括我们去做一个Lunece,Sorl,或者是ES,这些东西,大体上都是用空间换时间,很多设计其实都是从这个角度去考虑的,不同的维度怎么去做,后期再一点一点去讲吧,这个是ORACLE里面的一个概念了,如果SQL语句仅访问被索引的列,就是你访问的是索引的列比如ID就是索引,你只是查一下ID,那数据库仅从索引中读取数据,而不读取表,如果你只访问索引列之外,还访问列其他的数据,你要查一条记录的话,那他这个时候会根据rowid,来查找对应的行,ORACLE里面有rowid的概念,除了有rownum隐式的行号之外,还有rowid这个东西,这个东西其实很好找的,我还是拿emp1吧,SELECT ROWID FROM EMP1,其实咱们的ORACLE表里有这么一行,这一行就是ROWID,其实他就通过ROWID去检索哪个位置
ORACLE里面一般分7种索引:1. 正常我们一般使用唯一索引,你主键会unique index,create unique index emp_idx on emp1(empno)2. 一般索引,create index empno_idx on emp1(empno),这个语句就非常简单了,create index,给索引取个名,随便起个名字,但是一般要见名知意,你叫empno_idx一看我就知道是emp表中的empno的字段它是一个索引,on是这个索引建在哪个表上,建在emp1这个表上,然后建在emp1这个表哪一列上,就是这块有个大括号,建在empno这个列上,这个语句其实是你要记住的,3. 组合索引像其他的没有特殊需求,我一直用ORACLE这么多年,这些都没怎么用过,组合索引,也就是联合索引,这个有的时候还用一点,我一张表里两个字段, create index job_deptno_idx on emp1(job,deptno);做这个索引4. reverse反向索引5. 函数索引6. 压缩索引7. 升序降序索引,这个用的都很少
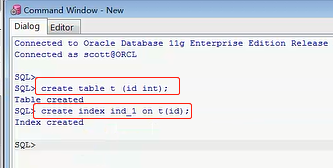
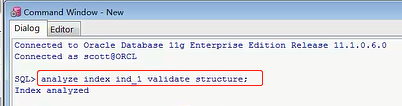
说明了索引碎片的问题了,咱们来看一下,这里是一个很简单的例子,creat table t(id int),这里只有一个字段id,等于int类型的,它是一个字段,然后我去把他建立一个索引,creat index ind_1 on t(id),就是把这个id当成一个索引,给他起个名字叫ind_1,就是建立一个索引名字,咱们来看一下,这个其实很简单
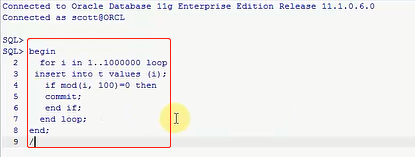
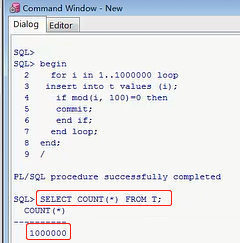
你看到我当前有一个索引了,然后它是存在一个T表的,它是在T表的ID这一列上的,T表就一个字段ID,当然T表是没有任何数据的,刚把索引建完,表和索引都建完,然后呢这个时候,咱们要做的另外一件事情,就做插入,就做插入一堆数据,这堆语句是做什么事情的,一般来讲你建表的时候,要求建表的时候,直接把应该有的索引都建上,这个性能是比较高的,你不能等表已经插入100条数据的时候,然后再建索引,那就不太好了,性能就比较低了,你设计一张数据库表的时候,一定要想好了,这个业务哪个字段会反复的查询,直接把索引建好,你最好是这么去做,这是多少次啊,这是一个简单的块,for in 100万条数据,然后往里去insert,就是往t表里添加100万条数据,然后去取模,取模做什么事啊,if mod(i,100)取模就是i这个值取100,等于0的话,那我就commit提交了,end if,就是往里插数据,如果那什么的时候,去模等于0的时候,去做这个事,咱们看一下,用Command Window,我就执行一下这个,我就回车
这个过程可能很慢,你看一下这个语句,他就是insert into 这么多条数据,就往这张表里插数据,只要你这个取模的时候,取100等于0的时候,就commit,提交,然后其他情况就不提交,就跳着来的,咱们的数据可能是1,3,6,...,就少了很多,就咱们不按照顺序去走,稍等一下,他这个过程可能比较长,100万条数据吗,我这么做的目的其实就是让他产生这个索引碎片的问题,一会我们查一下这个表,这个数据一定是很多的,然后这样,它是做这个事情,分析ind_1,然后这个节奏,就是去分析一下,现在肯定是属于一个正常的,这个表里的数据都是非常正确的
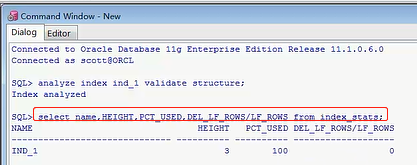
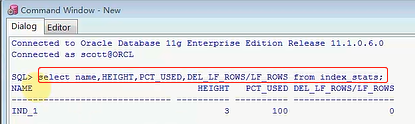
我分析完索引以后,我开始得去分析一下,不进行分析的话,就是index_stat这张表,如果你不进行分析这里面是没数据的,只有你分析了以后,才会有数据,刚才我应该不分析,先查一下这个表,这个表里面肯定是没数据的,但是刚才我执行完分析以后,他就相当于把数据插入到index_stats表里了,我们要取的值不就是这几个值吗,高度,一个PCT_USED,还有一个就是LF_ROWS的取值,select name,HEIGHT,PCT_USED,DEL_LF_ROWS/LF_ROWS from index_stats
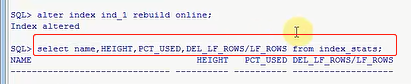
咱们这个情况是属于最正常的情况,这个高度是正常的,咱们看看这个条件,这个条件如果是大于等于4,或者小于50%,或者是大于0.2的时候,无论哪个指标成立满足了,就是你张表的索引是有问题,你应该进行索引碎片的整理,就这三个阀值,那我现在是什么情况啊,我现在这个HEIGHT高度是几,我这个高度是3,属于一个理想的状态,PCT_USED是100%,百分之百就是相当于使用率很高,因为我基本上没有做其他的操作,你只有小于50%了,你这个使用率小于50%了,你得碎片整理,如果你大于50%,甚至60%,70%,100%,非常完美的情况下,你都不用做,这个查询速率是很高的,或者是这个值大于0.2,我这个值是多少啊,我这个值是0,那肯定是小于0.2的,目前来讲,刚才我做了这个操作,我查的时候肯定是走索引的,他这个性能一定是最佳的,肯定是跟咱们的索引是没关系的,但是接下来我要做的事是破坏他,我怎么破坏呢,我这样,我去批量的DELETE,delete t where rownum < 700000,这是多少,rownum只要小于70万的,我一下子删除了70%的数据,一共100万条,我删除了70%的数据,你说他肯定会对这个索引的碎片,造成很大的影响,咱们来做一下这个事情吧,那这个删除操作稍微等一下,就是已经删除69万9999条数据