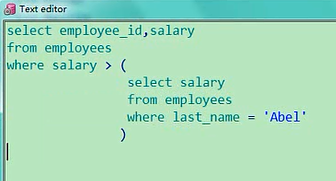
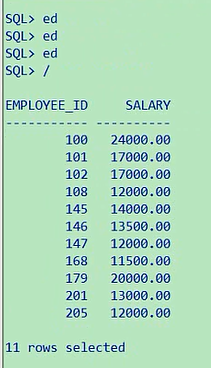
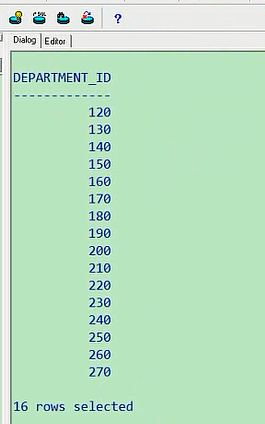
相关子查询是按照一行阶一行的子查询,主查询的每一行都执行一次子查询,这个呢叫相关子查询,好似对应的就应该叫不相关子查询,当然我们没有这个概念,不相关的,只是明确是相关的,外层子查询和内层子查询的关系比较密切,什么相关性,就是我们红色标注的,主查询每一行,都会执行一次子查询,怎么来理解这个事,我们来看一下,我们那会写过一个练习,就是他,就是这个练习,这个练习这个题目是这样要求的,按照department_name进行排序,我这儿使用了一个子查询,大家你看是不是这样,我外层当你每进行一次select的时候,从这个employees表当中,选一个id,选一个name,他相应的都会执行一遍这个子查询,子查询按照这样一个条件,返回一个department_name,那就意味着每一条数据,都有可能是返回不同的department_name,然后根据name的不同,进行一个order by,这就是我们说的相关子查询,内外相关度是比较高的,因为我使用了这样一个语句,因为明显你的这个d是内层的表,e1是外层的表,他两之间有相关性,这就叫相关子查询,对应的貌似叫非相关的,什么情况,就是我们之前写过的这个例子,比如说select employee_id,salary,from employees,where salary大于,我们写过这个例子,select salary,返回公司当中工资比Abel工资高的信息,我们是这样写的select employee_id,salary from employees where salary > (select salary from employees wherelast_name='Abel')当时我们是不是还说了,真正执行的时候是先执行内层查询,把内层查询的结果,返回给外层查询,你看这个题目当中,你外层不管是哪行数据进来,这个值都一样,没有内外层连接条件出现刚才那个情景,所以他呢就不能称之为相关子查询了,就是一个很一般的查询,因为你内层返回的结果跟外层的每一行都不一样,跟外层每一行都没有关系,返回的数据都是一样的,都是一个值
这里一共有11条,相比较于刚才相关的,大家理解一下,这里面我们有一个框,大家看一下,get这个环节,从主查询中获取候选列,然后execute执行,子查询使用主查询的数据,然后use,如果满足内查询的条件就返回该行,你看这个就和我们说的这个练习完全吻合,你外层找到一列的数据,这一列是谁啊,是department_id,然后这一列数据,然后这个数据在内层当中按照这个执行,执行的时候都会返回一个值,当然有的话就返回了,返回一个值,然后这个值被外层所使用,用它来进行排序,这就是一个相关子查询,就是因为有他select department_id, last_namefrom employees e1order by (select department_name from departments d where e1.department_id=d.department_id) asc
我们来看看这里面的题目,外层的表在内层中使用了,就是相关子查询
这个题目刚才我们都写了,查询员工工资大于平均工资的信息
这个题我们刚才是不是都已经做过了,我们解释一下,这不就是查询这三个信息,然后要求比本部门,外层的outer,在内层中使用,连接条件就是他们的department_id是一样,返回这个部门的平均工资,那意味着你外层每一条数据进去以后,都应该返回不同的avg,但是每次你外层数据进去的时候,都会再执行一遍再返回回来,这就叫相关子查询select last_name, salary, department_idfrom employees outerwhere salary > (select avg(salary) from employees where department_id=outer.department_id)
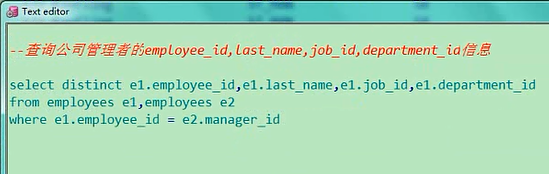
更我们刚才的查询结果是一样的,这是我们通过两个钟方式来给大家一个解答,这两个方式哪种都行,现在我们讲这个,又是另一种方式了,有点区别了,查询公司管理者的这四个信息,你看我们刚才写的这几个题,是不是他,这个,我说你这个题目当中,它是把内层的manager_id给返回回来了,其实我也不用返回什么select employee_id,last_name,job_id,department_idfrom employees e1where manager_id in (select manager_id from employees e2 where e1.employee_id=e2.manager_id)
我把这个改成exists,然后这里边怎么来修改,select我这里不需要你具体查什么,随便写一个东西就行,我们就写个A吧,select A from他,这个题目我们照常这样写的话,结果仍然是可以查询出来的,我们看一下select employee_id,last_name,job_id,department_idfrom employees e1where exists(select 'A' from employees e2 where e1.employee_id=e2.manager_id)
这就是我们说的exists,我只需要查询,这个employees表中的,管理者的信息,我只需要知道你是管理者,就可以了,具体说你是几号管理者,我在一输出就完了,我不用过多的关注,我再说一遍,我只需要知道,哪一个员工是管理者就完了,至于你说,是几号的,我不用过多关注,因为你内层查询的时候,我不再需要你给我返回出来,你是几号的,你看我们刚才的查询方式,实际上你是告诉我,你是几号的select employee_id,last_name,job_id,department_idfrom employees e1where e1.employee_id in (select manager_id from employees e2 where e1.employee_id = e2.manager_id)这个信息实际上我们不需要,我只需要知道你是管理者就完了,那我们就用到exists,内层里面当然还是一个相关子查询,所以他是相关子查询的一种应用,这个的employee_id,跟你内层的manager_id,每外层进去一个,就能够找到一个manager_id,如果有的话,返回就true,如果没有,就返回一个空,也就是所谓的false,一旦这里面找到一个就返回true,不继续再寻找了,那你找到的放进去的这条数据,对应的employee_id是谁,就将这条数据输出出来,不就是公司的管理者吗,你每次找一条数据往里面一放,一旦返回true就是管理者,一旦是false,就不是管理者,对于这个题目也可以这样来写,这就是这样的一个题目,然后我们看下一个题,叫not exists
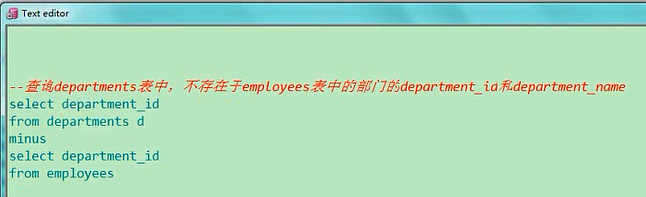
这个就和我们讲null一样,null是空,not null就是非空,not exists的意思,就是这个是true的,加上not就返回false,我们看看这个题目,查询departments表当中,不存在于employees表中的部门的,这两个信息,我们就把这个框写出来,select department_id,department_name,from departments,这毫无疑问了,关键是你where语句这,不在这个表中的信息,那就相当于你把这个表中的信息给他砍掉,实际上我们用旧的方式也能够实现,一会我们再说旧的方式,我们先用我们新的方式,新的方式的话,我只要你在或不在就行,我先把exist给他补上,然后呢你具体是谁,我不需要关注,你随便写一个select就行,比如'c',这都可以,from他不是说employees表吗,然后where,我们这个给外层这个表取一个别名,d,where内层这个表的department_id,等于外层这个表的department_id,你看我们这个查询是不是要求,这个外层这个表,id是在内层这个表里的,才返回一个true,现在要你返回不存在这里面的,那你前面加上一个not就行了,这个时候当你外层每一条数据进去的时候,一旦出现这个条件有数据的话,他就不让你输,因为他有not,如果没有,说明是查询到外层的数据不存在,存在于employees表中的select department_id,department_namefrom departments dwhere not exists (select 'c' from employees where department_id = d.department_id)
这是11条数据实际上是一样的,这是我们用不同的方式来实现的,当然你想在这里加上department_name的话,这个题目还不行了,这样有27个select department_id, department_namefrom departments dminusselect department_id, to_char(null) from employees
27个,这个也不一样了,你还是想让他带上department_name的话,就还是得用我们刚才这种方式select department_id,department_namefrom departments dwhere not exists (select 'c' from employees where department_id = d.department_id)如果只想看有哪些部门,你可以用我们上节讲的set运算符,这个是我们讲的exists和not exists的一个应用,下一个叫相关更新
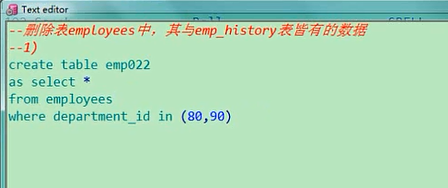
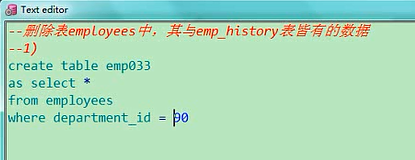
删除表employees中,其与这个表皆有的数据,把这个表和这个表共有的数据删除,是这个意思,是吧,删除的话我们得先有一个准备的工作,我先造两个表,create table emp,emp022,as select *,from employees,where department_id in (80,90),80号,90号部门的数据,赋给他create table emp022asselect * from employeeswhere department_id in(80,90)
然后我再造一个033,把90号的数据都给他create table emp033asselect * from employeeswhere department_id = 90
然后我们看一下select * from emp022;
这是37条数据select * from emp033;
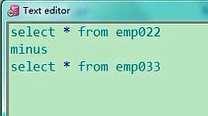
这是3条数据,上面这个表当中大家注意到,它是有3条数据是90号部门的,剩下的34条数据是80号部门的,现在我想把这个表的数据和这个表的数据一样的3条数据给干掉,就只要80号部门的,那这个怎么去写啊,我现在是想进行删除操作,而不是仅仅一个查询,如果仅仅是一个查询的话,那是不是和我们上节讲的一样的,我们上节讲的叫set运算符,是不是这样写,如果我仅仅是需要查询的话,select * from emp022,然后minus,select * from emp033,就是把022当中把033中一样的给减去就行,一共34个select * from emp022minusselect * from emp033
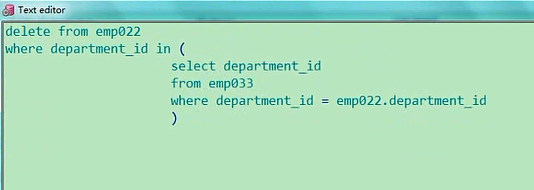
这仅仅是一个查询,你要改的话,delete from emp022,然后where,department_id等于某一个,select department_id from emp033,where,department_id等于外层的emp022的department_id,他两的部门id都一样,如果有一样的话,把一样的这个值给赋过来,返回多个值,indelete from emp022where department_id in (select department_id from emp033 where department_id = emp022.department_id)
就是这样的,各个总工资找到了,然后再往后看,然后说呢,公司中各部门的平均总工资,平均总工资,我刚才算出来的是各部门的总工资,然后下一步需要做的就是,你把这些值都加起来,然后除以11,除以11得到一个平均的总工资,这11个部门,就是相当于要依托于我现在算的这个值,然后再求出一个平均总工资,再比较谁比他大,要么你就用子查询,有多层嵌套,非常的呕心,我们现在就是一个现成的,那现成的这个东西,我想后面用一用他,那我们就要用到with语句,怎么整啊,with dept,sum_sal,as,怎么来实现的,这就是我们现在得到的这个值,然后为了方便,我在sum这里再取上一个别名,sum_sal,现在这个结构就放到这里了,这是一个结构with dept_sum_sal as (select department_name,sum(salary) sum_sal from departments d, employees ewhere d.department_id = e.department_id group by department_name),中间用逗号隔开,让你查询这个东西,with这个怎么写,平均的avg,dept_avgsql,as,在这写吧,怎么写,select,你现在需要查询的是公司的各个部门加起来的,平均的总工资,那相当于把这个值,再求一个和,各个部门的总工资,把他们加起来,sum(sum_sal),这个求一个和,from这个表,这个表你把它给算出来,这儿你再取一个别名也行,sum_sal1,我这个叫1,这个是公司整个的总和,现在要的是平均,你再给他除以一个count(*),这样写吧,from他,这个值是公司的平均总工资,这个提供完以后,这两个结构放在这,写上select,查询这些部门信息,就是相当于从这个表中去查,select * from这个表,where这个怎么写,这个表他有一个他,就是你各个部门的总工资大于公司的平均总工资,select这个值,from这个表with dept_avgsal as(select sum(sum_sal1)/count(*) avg_sum_sal2 from dept_sumsal),select * from dept_sumsalwhere sum_sal1 > (select avg_sum_sal2 from dept_avgsal)