hbase操作(shell 命令,如建表,清空表,增删改查)以及 hbase表存储结构和原理
两篇讲的不错文章
http://www.cnblogs.com/nexiyi/p/hbase_shell.html
http://blog.csdn.net/u010967382/article/details/37878701?utm_source=tuicool&utm_medium=referral
- hbase操做
-
- hbase web操作
- hbase shell 基本操作
- 1建表
- 具体命令
- 2建表后查看表describe
- 3清空表truncate lmj_test
- 4删除表
- 5修改表结构先disable后enable
- 6对表中记录的操作4种行操作
- 7表操作权限
- 8命名空间
- 1建表
-
- hbase原理及时间戳管理介绍
-
- hbase 表
-
hbase操做
hbase web操作
访问地址 http://hmaster:60010
hmaster的ip配置在$HBASE_HOME/conf/hbase-site.xml中
ip映射成主机名在env/hosts中配置在windows系统中的C:\Windows\System32\drivers\etc目录下的hosts文件中配置)
hbase shell 基本操作:
hbase shell 进入hbase console命令
whoami 查用户
help查看基本命令集合
help command 查看命令帮助
list看库中所有表
status 查看当前运行服务器状态
version 版本查询
exits '表名字' 判断表存在hbase shell中删除为 ctrl + backspace(单按删除键不好使)
1)建表
语法:create , {NAME => , VERSIONS => }
具体命令
hbase(main):004:0> exists 'test'hbase(main):005:0> create 'test','cf'hbase> create 't1', {NAME => 'f1', VERSIONS => 5}hbase> create 't1', {NAME => 'f1'}, {NAME => 'f2'}, {NAME => 'f3'}省略模式建立列族hbase> create 't1', 'f1', 'f2', 'f3'指定每个列族参数hbase> create 't1', {NAME => 'f1', VERSIONS => 1, TTL => 2592000, BLOCKCACHE => true}hbase> create 't1', 'f1', {SPLITS => ['10', '20', '30', '40']}hbase> create 't1', 'f1', {SPLITS_FILE => 'splits.txt'}hbase> # Optionally pre-split the table into NUMREGIONS, usinghbase> # SPLITALGO ("HexStringSplit", "UniformSplit" or classname)hbase> create 't1', 'f1', {NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}设置不同参数,提升表的读取性能。create 'lmj_test',{NAME => 'adn', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROWCOL', REPLICATION_SCOPE => '0', COMPRESSION => 'SNAPPY', VERSIONS => '1', TTL => '15768000', MIN_VERSIONS => '0', KEEP_DELETED_CELLS => 'false', BLOCKSIZE => '65536', ENCODE_ON_DISK => 'true', IN_MEMORY => 'false', BLOCKCACHE => 'false'}, {NAME => 'fixeddim', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROWCOL', REPLICATION_SCOPE => '0', COMPRESSION => 'SNAPPY', VERSIONS => '1', TTL => '15768000', MIN_VERSIONS => '0', KEEP_DELETED_CELLS => 'false', BLOCKSIZE => '65536', ENCODE_ON_DISK => 'true', IN_MEMORY => 'false', BLOCKCACHE => 'false'}, {NAME => 'social', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROWCOL', REPLICATION_SCOPE => '0', COMPRESSION => 'SNAPPY', VERSIONS => '1', TTL => '15768000', MIN_VERSIONS => '0', KEEP_DELETED_CELLS => 'false', BLOCKSIZE => '65536', ENCODE_ON_DISK => 'true', IN_MEMORY => 'false', BLOCKCACHE => 'false'}每个参数属性都有性能意义,通过合理化的设置可以提升表的性能create 'lmj_test',{NAME => 'adn', BLOOMFILTER => 'ROWCOL', VERSIONS => '1', TTL => '15768000', MIN_VERSIONS => '0', COMPRESSION => 'SNAPPY', BLOCKCACHE => 'false'},{NAME => 'fixeddim',BLOOMFILTER => 'ROWCOL', VERSIONS => '1', TTL => '15768000', MIN_VERSIONS => '0', COMPRESSION => 'SNAPPY', BLOCKCACHE => 'false'},{NAME => 'social',BLOOMFILTER => 'ROWCOL', VERSIONS => '1', TTL => '15768000', MIN_VERSIONS => '0',COMPRESSION => 'SNAPPY', BLOCKCACHE => 'false'}
2)建表后查看表:describe
得出{NAME => 'lmj_test', FAMILIES => [{NAME => 'adn', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROWCOL', REPLICATION_SCOPE => '0', COMPRESSION => 'SNAPPY', VERSIONS => '1', TTL => '15768000', MIN_VERSIONS => '0', KEEP_DELETED_CELLS => 'false', BLOCKSIZE => '65536', ENCODE_ON_DISK => 'true', IN_MEMORY => 'false', BLOCKCACHE => 'false'}, {NAME => 'fixeddim', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROWCOL', REPLICATION_SCOPE => '0', COMPRESSION => 'SNAPPY', VERSIONS => '1', TTL => '15768000', MIN_VERSIONS => '0', KEEP_DELETED_CELLS => 'false', BLOCKSIZE => '65536', ENCODE_ON_DISK => 'true', IN_MEMORY => 'false', BLOCKCACHE => 'false'}, {NAME => 'social', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROWCOL', REPLICATION_SCOPE => '0', COMPRESSION => 'SNAPPY', VERSIONS => '1', TTL => '15768000', MIN_VERSIONS => '0', KEEP_DELETED_CELLS => 'false', BLOCKSIZE => '65536', ENCODE_ON_DISK => 'true', IN_MEMORY => 'false', BLOCKCACHE => 'false'}]}
3)清空表:truncate ‘lmj_test’
4)删除表:
分两步,首先disable 'lmj_test',然后drop 'lmj_test'
5)修改表结构:先disable后enable
alter 't1', {NAME => 'f1'}, {NAME => 'f2', METHOD => 'delete'}例如:修改表test1的cf的TTL为180天hbase(main)> disable 'test1'hbase(main)> alter 'test1',{NAME=>'body',TTL=>'15552000'},{NAME=>'meta', TTL=>'15552000'}hbase(main)> enable 'test1'
6)对表中记录的操作(4种行操作)
put 增加一行语法:put ,,,,其中,timestamp可以系统默认,也可以自己设定,如put 't1', 'r1', 'c1', 'value', ts1put 'lmj_test','00001','adn:adn_3','aaa',1432483200000put 'lmj_test','00001','fixeddim:appcategory_1','1',1432483200000put 'lmj_test','00001','fixeddim:interest_15','100',1432483200000get查询对应数据(可以指定行、列族、列、版本)get 'lmj_test','000000104257464',{TIMESTAMP=>1432483200000}delete 删除数据删除指定行中指定列:delete , , , (必须指定列名,删除其所有版本数据)delete 'lmj_test','000000104257464','f1:col1'删除整行数据(可不指定列名):deleteall , , , deleteall 'lmj_test','000000104257464'scan 扫描全表,指定过滤条件,返回对应行scan 'lxw_hbase', {LIMIT => 1}其他条件继续添加在大括号中以上4个操作类是 org.apache.hadoop.hbase.client的子类,参考官网API查看详细信息count统计表中记录数count 'lxw_hbase', {INTERVAL => 100, CACHE => 500}#每100条显示一次,缓存区为500
7)表操作权限
给用户分配对每个表的操作权限,有RWXCA五种,对应READ, WRITE, EXEC, CREATE, ADMINgrant 'liu_mja','RW','lxw_hbase' #分配给用户liu_mja表lxw_hbase的读写权限还可以 查看权限user_permission 'lxw_hbase'收回权限revoke 'liu_mja','lxw_hbase'
8)命名空间
关系数据库系统中,命名空间namespace是表的逻辑分组,同一组中的表有类似的用途。以下引自:(http://blog.csdn.net/u010967382/article/details/37878701?utm_source=tuicool&utm_medium=referral)hbase的表也有命名空间的管理方式,命名空间的概念为即将到来的多租户特性打下基础:配额管理( Quota Management (HBASE-8410)):限制一个namespace可以使用的资源,资源包括region和table等; 命名空间安全管理( Namespace Security Administration (HBASE-9206)):提供了另一个层面的多租户安全管理; Region服务器组(Region server groups (HBASE-6721)):一个命名空间或一张表,可以被固定到一组 regionservers上,从而保证了数据隔离性。 命名空间可以被创建、移除、修改。建表时可以指定命名空间,格式如下::#Create a namespacecreate_namespace 'my_ns'#create my_table in my_ns namespacecreate 'my_ns:my_table', 'fam'#drop namespacedrop_namespace 'my_ns'#alter namespacealter_namespace 'my_ns', {METHOD => 'set', 'PROPERTY_NAME' => 'PROPERTY_VALUE'}预定义的命名空间:有两个系统内置的预定义命名空间hbase 系统命名空间,用于包含hbase的内部表 default 所有未指定命名空间的表都自动进入该命名空间使用默认的命名空间#namespace=default and table qualifier=barcreate 'bar', 'fam'指定命名空间#namespace=foo and table qualifier=barcreate 'foo:bar', 'fam'
hbase原理及时间戳管理介绍
分布式的、面向列的开源数据库
hdfs文件存储
MR处理数据
zookeeper做协同服务
hbase 表
数据以表存储表含行、列,列分为列簇(family)
如图,
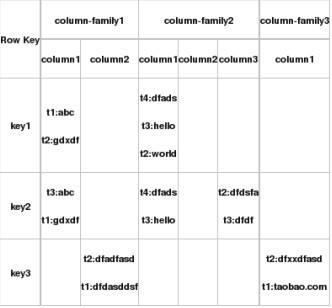
key1,key2,key3是三条记录的唯一row key值,
column-family1,column-family2,column-family3是三个列族
每个列族下包括几列,如列族 column-family1包括两列column1和column2
row这个维度用于region切分column则不用于分片,和row不同的是,一个row中多个columns的put或者delete操作是一个原子事务(同一个原子事务中不能同时put和 delete)Row key和column key(HBase中也称为qualifier)是bytes类型,而时间维度的key则是long integer类型,典型使用 java.util.Date.getTime()或者System.currentTimeMillis()来做为时间维度的key。唯一的确定一个cell数据:由row key1、column-family1、column1找到值集,值集按时间戳t排列,按有效期取得每个对应时间的值t1:abc,t2:gdxdf每个cell的值可能包含多个版本,以timestamp索引,倒序排列,默认为最近一个版本,时间戳最大(1) Row Key:nosql数据库中记录的主键,在 hbase内部保存为字节数组(字典序排列存储), 任意字符串(最大长度是 64KB)。读有位置相关性,经常一起读的行要放到一起存储。注意:int类型数据的字典序是1,10,100,118,11,12,128,15,16。恢复成int数值的自然序,在行键的左侧全部填充0(左填充0)。(2) 列族 column family:是schema的一部分(而列不是),必须在用表前先定义。列名以列族为前缀,create 'test','cf'put 'test','001','cf:c1','a1',1432483200000put 'test','002','cf:c2','a2'put 'test','001','cf2:c1','a1',1432483200000 报错ERROR: Unknown column family! Valid column names: cf:*(3) cell: 无类型,全部存储为字节码(4) 时间戳 timestamp管理(多版本数据有效期设置)每个cell的值可能包含多个版本,以timestamp索引,倒序排列(最近数据在最前面,默认取最近的数据)。时间戳的类型是 64 位整型。时间戳可以自动生成,也可以自己设定。避免数据版本冲突则时间戳必须具有唯一性。版本具有有效期,超过有效期则删除。有两种方式回收版本,称为 GC(垃圾收集)列值版本的保存数量限制,通过两种方式设置
1, version设置保留版本数。超过则删除最老的,创建Column Family时通过HColumnDescriptor.setMaxVersions(int versions)设置,这是Column Family级别,设置是即时生效,读取时读不了,但物理删除还是需要等到major compact操作中执行。设置为1只保留一个
2,TTL(Time To Live)设置保留时间。超过TTL则删除,默认是forever。
通过 HColumnDescriptor.setTimeToLive(int seconds)可以设置TTL。读操作如Get/Scan等是即时生效,但物理清除要等到major compact。一行row中所有cell的TTL都失效,则删除整行,HBase不显示建立或删除行,行中cell有值且有效,行就存在。
注意,version版本控制中,major compact不进行,则删除最近版本后,失效版本可以重新恢复为有效值
put的时间戳
默认使用的是currentTimeMillis。应用也可以使用自定义的值来做为每个列的 timestamp,只需要是一个long integer的值即可,不一定是时间
而get默认返回timestamp最大值的数据
delete的时间戳
1. 删除某个timestamp之前所有老版本
(指定timestamp比row中最新的版本大,则相当于删除整行,不是立即删除元数据,而是等到major compact时)
2. 删除某个timstamp点的版本
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!
