【NLP】文本聚类和主题建模
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
文本聚类
数据
我们如何进行文本聚类?
1.嵌入文档
2. 降维
3. 集群嵌入
主题建模
Bertopic
代码概述
例子
(交互式)可视化
表示模型
KeyBERTInspired
词性
最大边际相关性
文本生成
Prompting
HuggingFace
OpenAI
Cohere
LangChain
主题建模变体
概括
尽管分类等监督技术在过去几年中在业界占据主导地位,但文本聚类等无监督技术的潜力也不容低估。
文本聚类旨在根据语义内容、含义和关系对相似文本进行分组,如图1 所示。就像我们在第 XXX 章的密集检索中使用文本嵌入之间的距离一样,聚类嵌入允许我们根据相似性对存档中的文档进行分组。
由此产生的语义相似文档集群不仅有助于对大量非结构化文本进行有效分类,而且还可以进行快速探索性数据分析。随着允许文本的上下文和语义表示的大型语言模型 (LLM) 的出现,文本聚类的功能在过去几年中显着增强。语言不是一袋单词,大型语言模型已被证明能够很好地捕捉这一概念。
文本聚类的一个被低估的方面是它在创造性解决方案和实施方面的潜力。在某种程度上,无监督意味着我们不受我们想要优化的特定任务或事物的限制。因此,文本聚类有很大的自由度,使我们能够避开常见的路径。虽然文本聚类自然会用于对文档进行分组和分类,但它可以用于通过算法和视觉方式查找不正确的标签、执行主题建模、加速标记以及许多更有趣的用例。
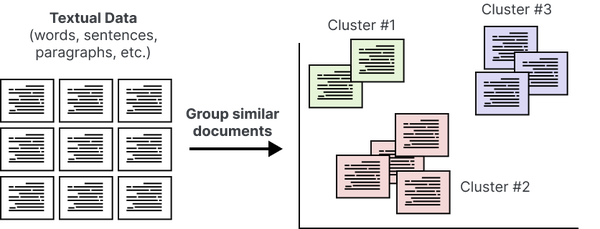
图 1 聚类非结构化文本数据。
这种自由也伴随着挑战。既然我们不受特定任务的指导,那么我们如何评估我们的无监督聚类输出呢?我们如何优化我们的算法?没有标签,我们优化算法的目的是什么?我们什么时候知道我们的算法是正确的?算法“正确”意味着什么?尽管这些挑战可能相当复杂,但它们并非无法克服,但通常需要一定的创造力和对用例的良好理解。
在文本聚类的自由度和它带来的挑战之间取得平衡可能相当困难。如果我们进入主题建模的世界,这一点就变得更加明显,主题建模已经开始采用“文本聚类”的思维方式。
通过主题建模,我们希望发现出现在大量文本数据中的抽象主题。我们可以用多种方式描述一个主题,但传统上是通过一组关键词或关键短语来描述的。关于自然语言处理(NLP)的主题可以用“深度学习”、“变压器”和“自注意力”等术语来描述。传统上,我们期望有关特定主题的文档包含比其他主题更频繁出现的术语。然而,这种期望忽略了文档可能包含的上下文信息。相反,我们可以利用大型语言模型和文本聚类来对上下文文本信息进行建模并提取语义信息主题。图 2 演示了通过文本表示来描述集群的想法。
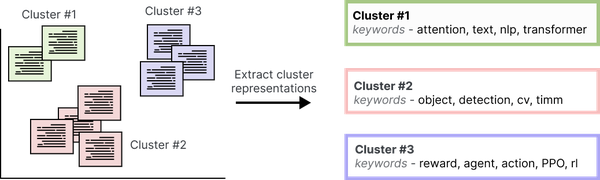
图 2 主题建模是一种赋予文本文档簇意义的方法。
在本文中,我们将提供有关如何使用大型语言模型完成文本聚类的指南。然后,我们将过渡到受文本聚类启发的主题建模方法,即 BERTopic。
文本聚类
NLP 探索性数据分析的主要组成部分之一是文本聚类。这种无监督技术旨在将相似的文本或文档分组在一起,以便轻松发现大量文本数据中的模式。在深入研究分类任务之前,文本聚类可以让您直观地了解任务及其复杂性。
从文本聚类中发现的模式可用于各种业务用例。从识别重复出现的支持问题和发现新内容来推动 SEO 实践,到检测社交媒体中的主题趋势和发现重复内容。可能性是多种多样的,通过这种技术,创造力成为关键组成部分。因此,文本聚类不仅仅是一种探索性数据分析的快速方法。
数据
在描述如何执行文本聚类之前,我们将首先介绍本章将要使用的数据。为了跟上本书的主题,我们将聚集机器学习和自然语言处理领域的各种 ArXiv 文章。该数据集大约包含XXX和XXX之间的XXX篇文章。
我们首先使用HuggingFace 的数据集包导入数据集,并提取稍后将使用的元数据,例如文章的摘要、年份和类别。
# 从huggingface加载数据
from datasets import load_dataset
dataset = load_dataset("maartengr/arxiv_nlp")# 提取特定元数据
abstracts = dataset["Abstracts"]
years = dataset["Years"]
categories = dataset["Categories"]
titles = dataset["Titles"]我们如何进行文本聚类?
现在我们有了数据,我们可以执行文本聚类。为了执行文本聚类,可以采用多种技术,从基于图的神经网络到基于质心的聚类技术。在本节中,我们将介绍一个众所周知的文本聚类流程,该流程由三个主要步骤组成:
-
嵌入文档
-
降低维度
-
簇嵌入
1.嵌入文档
聚类文本数据的第一步是将文本数据转换为文本嵌入。回想一下前面的章节,嵌入是捕获其含义的文本的数字表示。生成针对语义相似性任务优化的嵌入对于聚类尤其重要。通过将每个文档映射到数字表示,使得语义相似的文档接近,聚类将变得更加强大。可以在著名的句子转换器框架(reimers2019sentence)中找到一组针对此类任务优化的流行大型语言模型。图 3 显示了将文档转换为数字表示的第一步。
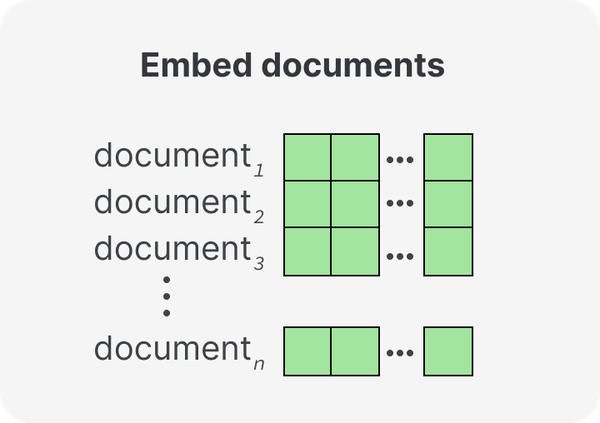
图 3 步骤 1:我们将文档转换为数字表示,即嵌入。
Sentence-transformers 具有清晰的 API,可以按如下方式使用从文本片段生成嵌入:
from sentence_transformers import SentenceTransformer# 我们加载我们的模型
embedding_model = SentenceTransformer('all-MiniLM-L6-v2')# 摘要被转换为向量表示
embeddings = model.encode(abstracts)这些嵌入的大小因模型而异,但通常每个句子或段落至少包含 384 个值。嵌入包含的值的数量称为嵌入的维数。
2. 降维
在对从 ArXiv 摘要生成的嵌入进行聚类之前,我们需要首先解决维数灾难。这种诅咒是在处理高维数据时出现的一种现象。随着维度数量的增加,每个维度内可能值的数量呈指数增长。查找每个维度内的所有子空间变得越来越复杂。此外,随着维数的增加,点之间距离的概念变得越来越不精确。
因此,高维数据对于许多聚类技术来说可能会很麻烦,因为识别有意义的聚类变得更加困难。簇更加分散且难以区分,因此很难准确识别和分离它们。
先前生成的嵌入维数很高,并且经常引发维数灾难。为了防止它们的维数成为问题,我们的聚类流程的第二步是降维,如图 4 所示。
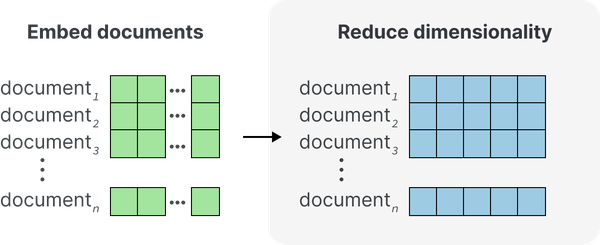
图 4 步骤 2:使用降维将嵌入减少到较低的维度空间。
降维技术旨在通过查找低维表示来保留高维数据的全局结构。众所周知的方法是主成分分析 (PCA) 和均匀流形逼近和投影 (UMAP; mcinnes2018umap)。对于这个管道,我们将使用 UMAP,因为它比 PCA 更能处理非线性关系和结构。
然而,降维技术并非完美无缺。它们无法完美地以低维表示形式捕获高维数据。此过程中信息将始终丢失。在降低维度和保留尽可能多的信息之间存在平衡。
为了执行降维,我们需要实例化 UMAP 类并将生成的嵌入传递给它:
from umap import UMAP# 我们实例化 UMAP 模型
umap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.0, metric='cosine')# 我们调整并改造我们的嵌入以减少它们
reduced_embeddings = umap_model.fit_transform(embeddings)我们可以使用` n_components`参数来决定低维空间的形状。在这里,我们使用“ n_components=5`”,因为我们希望保留尽可能多的信息,而又不会遇到维数灾难。没有一个值比另一个值做得更好,所以请随意尝试!
3. 集群嵌入
如图 5 所示,我们管道的最后一步是对之前减少的嵌入进行聚类。许多算法可以很好地处理聚类任务,从基于质心的方法(如 k-Means)到分层方法(如聚合聚类)。选择取决于用户,并且很大程度上受各自用例的影响。我们的数据可能包含一些噪音,因此检测异常值的聚类算法将是首选。如果我们的数据每天都会出现,我们可能需要寻找在线或增量方法,而不是在创建新集群时进行建模。
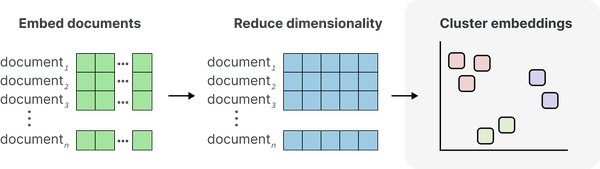
图 5 步骤 3:我们使用降维的嵌入对文档进行聚类。
一个很好的默认模型是带有噪声的基于分层密度的空间聚类应用程序(HDBSCAN;mcinnes2017hdbscan)。HDBSCAN 是一种称为 DBSCAN 的聚类算法的分层变体,它允许我们在无需显式指定聚类数量的情况下找到密集(微)聚类。作为一种基于密度的方法,它还可以检测数据中的异常值。不属于任何簇的数据点。这很重要,因为强制数据进入集群可能会产生嘈杂的聚合。
与之前的软件包一样,使用 HDBSCAN 非常简单。我们只需要实例化模型并将减少的嵌入传递给它:
from hdbscan import HDBSCAN# 我们实例化 HDBSCAN 模型
hdbscan_model = HDBSCAN(min_cluster_size=15, metric='euclidean', cluster_selection_method='eom')# 我们拟合我们的模型并提取聚类标签
hdbscan_model.fit(reduced_embeddings)
labels = hdbscan_model.labels_然后,使用之前生成的 2D 嵌入,我们可以可视化 HDBSCAN 如何对数据进行聚类:
import seaborn as sns# 将 384 维嵌入减少到 2 维,以便于可视化
reduced_embeddings = UMAP(n_neighbors=15, n_components=2,
min_dist=0.0, metric='cosine').fit_transform(embeddings)
df = pd.DataFrame(np.hstack([reduced_embeddings, clusters.reshape(-1, 1)]),columns=["x", "y", "cluster"]).sort_values("cluster")# 可视化集群
df.cluster = df.cluster.astype(int).astype(str)
sns.scatterplot(data=df, x='x', y='y', hue='cluster', linewidth=0, legend=False, s=3, alpha=0.3)正如我们在图 6 中看到的,它往往能够很好地捕获主要集群。请注意点簇如何以相同的颜色着色,表明 HDBSCAN 将它们放在一起。由于我们有大量的簇,绘图库会在簇之间循环颜色,因此不要认为所有蓝点都是一个簇。
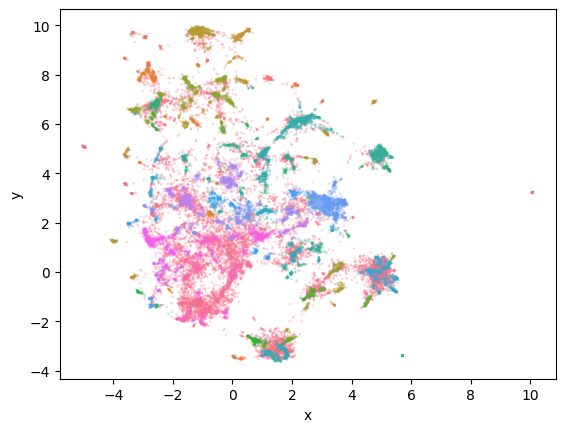
图 6 生成的聚类(彩色)和异常值(灰色)表示为 2D 可视化。
使用任何降维技术进行可视化都会造成信息丢失。它只是我们原始嵌入的近似值。尽管它提供了丰富的信息,但它可能会将集群推到一起,并使它们比实际情况更加疏远。因此,人工评估(我们自己检查聚类)是聚类分析的关键组成部分!
我们可以手动检查每个聚类,以查看哪些文档在语义上足够相似,可以聚类在一起。例如,让我们从集群XXX中随机抽取一些文档:
for index in np.where(labels==1)[0][:3]:print(abstracts[index])Sarcasm is considered one of the most difficult problem in sentiment analysis. In our ob-servation on Indonesian social media, for cer-tain topics, people tend to criticize something using sarcasm. Here, we proposed two additional features to detect sarcasm after a common sentiment analysis is con...Automatic sarcasm detection is the task of predicting sarcasm in text. This is a crucial step to sentiment analysis, considering prevalence and challenges of sarcasm in sentiment-bearing text. Beginning with an approach that used speech-based features, sarcasm detection has witnessed great interes...We introduce a deep neural network for automated sarcasm detection. Recent work has emphasized the need for models to capitalize on contextual features, beyond lexical and syntactic cues present in utterances. For example, different speakers will tend to employ sarcasm regarding different subjects...
这些打印的文档告诉我们,该簇可能包含谈论XXX 的文档。我们可以对每个创建的集群执行此操作,但这可能需要大量工作,特别是如果我们想试验我们的超参数。相反,我们希望创建一种方法来自动从这些集群中提取表示,而无需遍历所有文档。
这就是主题建模的用武之地。它允许我们对这些集群进行建模并赋予它们独特的含义。尽管有很多技术,但我们选择了一种基于这种聚类原理的方法,因为它具有显着的灵活性。
主题建模
传统上,主题建模是一种旨在在文本数据集合中查找潜在主题或主题的技术。对于每个主题,都会识别一组最能代表和捕捉主题含义的关键字或短语。该技术非常适合在大型语料库中查找共同主题,因为它为相似内容集赋予了意义。实践中主题建模的图示概述如图 7所示。
潜在狄利克雷分配(LDA;blei2003latent)是一种经典且流行的主题建模方法,它假设每个主题都由语料库词汇中单词的概率分布来表征。每个文档都被视为主题的混合体。例如,关于大型语言模型的文档可能很有可能包含“BERT”、“self-attention”和“transformers”等单词,而关于强化学习的文档可能很可能包含“PPO”等单词”、“奖励”、“rlhf”。
图 7 传统主题建模概述。
直到今天,该技术仍然是许多主题建模用例中的主要技术,并且凭借其强大的理论背景和实际应用,它不太可能很快消失。然而,随着大型语言模型看似呈指数级增长,我们开始想知道是否可以在主题建模领域利用这些大型语言模型。
已经有几种模型采用大语言模型进行主题建模,例如嵌入式主题模型和上下文主题模型。然而,随着自然语言处理的快速发展,这些模型很难跟上。
BERTopic 是解决此问题的一个方案,它是一种利用高度灵活的模块化架构的主题建模技术。通过这种模块化,许多新发布的模型可以集成到其架构中。随着大型语言建模领域的发展,BERTopic 也在不断发展。这允许以一些有趣且意想不到的方式将这些模型应用于主题建模。
Bertopic
Bertopic是一种主题建模技术,它假设语义相似文档的集群是生成和描述集群的强大方法。每个集群中的文档应该描述一个主要主题,并且它们组合起来可能代表一个主题。
正如我们在文本聚类中所看到的,聚类中的文档集合可能代表一个共同的主题,但该主题本身尚未描述。对于文本聚类,我们必须遍历聚类中的每个文档才能了解该聚类的含义。为了达到我们可以将集群称为主题的程度,我们需要一种以简洁且人类可读的方式描述该集群的方法。
尽管有很多方法可以做到这一点,但 BERTopic 中有一个技巧,可以让它快速描述集群,从而使其成为一个主题,同时生成高度模块化的管道。BERTopic 的底层算法大致包含两个主要步骤。
首先,正如我们在文本聚类示例中所做的那样,我们嵌入文档以创建数字表示,然后减少其维度,最后对减少的嵌入进行聚类。结果是语义相似的文档簇。
图 8 描述了与之前相同的步骤,即使用句子转换器来嵌入文档,使用 UMAP 进行降维,使用 HDBSCAN 进行聚类。
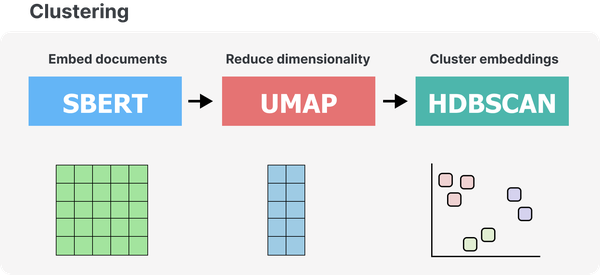
图 8 BERTopic 管道的第一部分是对文本数据进行聚类。
其次,我们为每个集群找到最匹配的关键字或短语。大多数情况下,我们会以聚类的质心为中心,找到最能代表它的单词、短语甚至句子。然而,这样做有一个缺点:我们必须持续跟踪我们的嵌入,如果我们要存储数百万个文档,那么存储和跟踪就会变得计算困难。相反,BERTopic 使用经典的词袋方法来表示集群。词袋正是顾名思义,对于每个文档,我们只需计算某个单词出现的频率并将其用作我们的文本表示。
然而,像“the”、“and”和“I”这样的词在大多数英语文本中出现得相当频繁,而且可能出现的次数过多。为了给这些词赋予适当的权重,BERTopic 使用了一种称为 c-TF-IDF 的技术,它代表基于类别的术语频率逆文档频率。c-TF-IDF 是经典 TF-IDF 过程的基于类的改编。c-TF-IDF 不考虑文档内单词的重要性,而是考虑文档簇之间单词的重要性。
要使用 c-TF-IDF,我们首先将集群中的每个文档连接起来以生成一个长文档。然后,我们提取 *c* 类中术语 *f_x* 的频率,其中 *c* 指的是我们之前创建的集群之一。现在我们只知道每个簇包含多少个单词以及包含哪些单词。
为了对这个计数进行加权,我们取一的对数加上每个簇 *A* 的平均单词数除以所有簇中术语 *x* 的频率。在对数中加一以保证正值,这也经常在 TF-IDF 中完成。
图 9 所示,c-TF-IDF计算允许我们为簇中的每个单词生成与该簇对应的权重。因此,我们为每个主题生成一个主题术语矩阵,描述它们包含的最重要的单词。它本质上是对每个主题的语料库词汇量的排名。
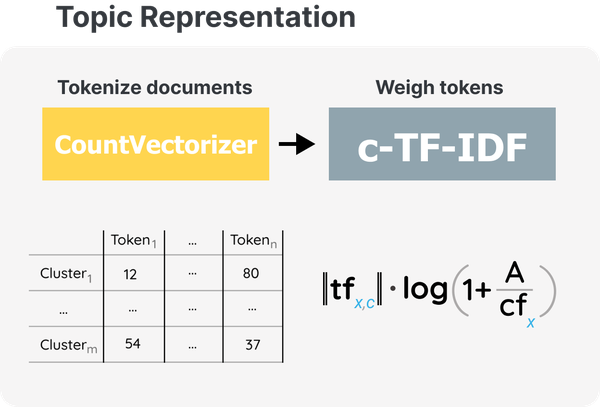
图 9 BERTopic 管道的第二部分是代表主题。计算类 *c* 中术语 *x* 的权重。
将这两个步骤放在一起,即聚类和表示主题,就形成了 BERTopic 的完整流程,如图 10 所示。通过这个管道,我们可以对语义相似的文档进行聚类,并从聚类中生成由多个关键字表示的主题。某个主题的关键词权重越高,该主题越具有代表性。

图 2-10 [bertopic_default.png] BERTopic 的完整流程大致包括两个步骤:聚类和主题表示。
有趣的是,c-TF-IDF 技巧不使用大型语言模型,因此没有考虑单词的上下文和语义性质。然而,与神经搜索一样,它提供了一个有效的起点,之后我们可以使用计算量更大的技术,例如类似 GPT 的模型。
该管道的一个主要优点是聚类和主题表示这两个步骤相对独立。当我们使用 c-TF-IDF 生成主题时,我们不使用聚类步骤中的模型,例如,不需要跟踪每个文档的嵌入。因此,这不仅在主题生成过程方面而且在整个管道方面都实现了显着的模块化。
通过集群,每个文档仅分配给一个集群或主题。在实践中,文档可能包含多个主题,并且将多主题文档分配给单个主题并不总是最准确的方法。我们稍后将讨论这个问题,因为 BERTopic 有几种处理此问题的方法,但重要的是要了解,BERTopic 的主题建模的核心是一项聚类任务。
BERTopic 管道的模块化性质可扩展到每个组件。尽管句子转换器被用作将文档转换为数字表示的默认嵌入模型,但没有什么可以阻止我们使用任何其他嵌入技术。这同样适用于降维、聚类和主题生成过程。无论用例是否需要 k-Means 而不是 HDBSCAN,以及 PCA 而不是 UMAP,一切皆有可能。
您可以将这种模块化视为使用乐高积木进行构建,管道的每个部分都可以完全替换为另一种类似的算法。这种“乐高积木”的思维方式如图 11所示。该图还显示了我们可以使用的附加算法乐高积木。尽管我们使用 c-TF-IDF 来创建初始主题表示,但我们可以通过许多有趣的方法使用 LLM 来微调这些表示。在下面的“表示模型”部分中,我们将详细介绍该算法乐高积木的工作原理。
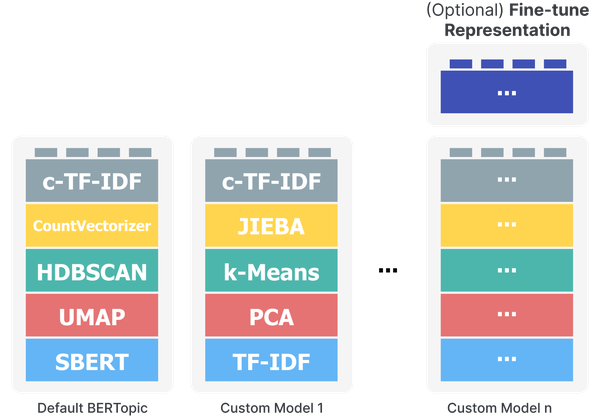
图 11 BERTopic 的模块化是一个关键组件,它允许您根据需要构建自己的主题模型。
代码概述
够了!这是实践的文章,所以终于到了一些实践编码的时候了。默认管道(如图 10所示)只需要几行代码:
from bertopic import BERTopic# 实例化我们的主题模型
topic_model = BERTopic()# 将我们的主题模型拟合到文档列表中
topic_model.fit(documents)然而,BERTopic 众所周知的模块化性以及我们迄今为止已经可视化的模块化性也可以通过编码示例来可视化。首先,让我们导入一些相关的包:
from umap import UMAP
from hdbscan import HDBSCAN
from sentence_transformers import SentenceTransformer
from sklearn.feature_extraction.text import CountVectorizerfrom bertopic import BERTopic
from bertopic.representation import KeyBERTInspired
from bertopic.vectorizers import ClassTfidfTransformer您可能已经注意到,大多数导入(例如 UMAP 和 HDBSCAN)都是默认 BERTopic 管道的一部分。接下来,让我们更明确地构建 BERTopic 的默认管道并执行每个单独的步骤:
# 步骤 1 - 提取嵌入(蓝色块)
embedding_model = SentenceTransformer("all-MiniLM-L6-v2")# 步骤 2 - 降低维度(红色块)
umap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.0, metric='cosine')# 步骤 3 - 聚类减少嵌入(绿色块)
hdbscan_model = HDBSCAN(min_cluster_size=15, metric='euclidean', cluster_selection_method='eom', Prediction_data= True )# 第 4 步 - 对主题进行标记(黄色块)
vectorizer_model = CountVectorizer(stop_words="english")# 步骤 5 - 创建主题表示(灰色块)
ctfidf_model = ClassTfidfTransformer()# 步骤 6 - (可选)微调主题表示
# 一个 `bertopic.representation` 模型(紫色块)
representation_model = KeyBERTInspired()
# 组合步骤并构建我们自己的主题模型
topic_model = BERTopic(embedding_model=embedding_model, # 第 1 步 - 提取嵌入umap_model=umap_model, # 第 2 步 - 降低维度hdbscan_model=hdbscan_model, # 第 3 步 - 聚类简化嵌入vectorizer_model=vectorizer_model, # 第 4 步 - 对主题进行分词ctfidf_model=ctfidf_model, # 第 5 步 - 提取主题词representation_model=representation_model # 步骤6 - 微调主题
)这段代码允许我们明确地完成算法的所有步骤,并且本质上让我们可以根据需要构建主题模型。变量 中定义的结果主题模型现在代表 BERTopic 的基本管道,如图10 topic_model所示。
例子
我们将在整个用例中继续使用 ArXiv 文章的摘要。为了回顾一下我们对文本聚类所做的工作,我们首先使用 HuggingFace 的数据集包导入数据集,并提取稍后将使用的元数据,例如文章的摘要、年份和类别。
# Load data from huggingface
from datasets import load_dataset
dataset = load_dataset("maartengr/arxiv_nlp")# 提取特定的元数据
abstracts = dataset["Abstracts"]
years = dataset["Years"]
categories = dataset["Categories"]
titles = dataset["Titles"]使用 BERTopic 非常简单,只需三行即可使用:
# 只需三行代码即可训练我们的主题模型
from bertopic import BERTopic topic_model = BERTopic()
topic, probs = topic_model.fit_transform(abstracts)通过此管道,您将返回 3 个变量,即topic_model、topics和probs:
-
topic_model是我们之前刚刚训练过的模型,包含有关模型和我们创建的主题的信息。 -
topics是每个摘要的主题。 -
probs是主题属于某个摘要的概率。
在我们开始探索我们的主题模型之前,我们需要进行一项更改以使结果可重现。如前所述,BERTopic 的底层模型之一是 UMAP。该模型本质上是随机的,这意味着每次运行 BERTopic 时,我们都会得到不同的结果。我们可以通过将“random_state”传递给 UMAP 模型来防止这种情况。
from umap import UMAP
from bertopic import BERTopic# 使用自定义 UMAP 模型
umap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.0, metric='cosine', random_state=42)# Train our model
topic_model = BERTopic(umap_model=umap_model)
topics, probs = topic_model.fit_transform(abstracts)现在,让我们开始探索所创建的主题。该get_topic_info()方法对于快速描述我们发现的主题很有用:
topic_model.get_topic_info()Topic Count Name 0 -1 11648 -1_of_the_and_to 1 0 1554 0_question_answer_questions_qa 2 1 620 1_hate_offensive_toxic_detection 3 2 578 2_summarization_summaries_summary_abstractive 4 3 568 3_parsing_parser_dependency_amr ... ... ... ... 317 316 10 316_prf_search_conversational_spoke 318 317 10 317_crowdsourcing_workers_annotators_underline 319 318 10 318_curriculum_nmt_translation_dcl 320 319 10 319_botsim_menu_user_dialogue 321 320 10 320_color_colors_ib_naming
我们的模型生成了很多主题,XXX!每个主题都由多个关键字表示,这些关键字在“名称”列中用“_”连接起来。此名称列使我们能够快速了解主题的内容,因为它显示了最能代表该主题的四个关键字。
您可能还注意到第一个主题标记为 -1。该主题包含无法适合该主题并被视为异常值的所有文档。这是聚类算法 HDBSCAN 的结果,该算法不会强制对所有点进行聚类。要删除异常值,我们可以使用 k-Means 等非异常值算法,也可以使用 BERTopic 的
reduce_outliers()函数删除一些异常值并将其分配给主题。
例如,主题 2 包含关键字“summarization”、“summaries”、“summary”和“abstractive”。从这些关键词来看,该主题似乎是摘要任务。要获取每个主题的前 10 个关键字及其 c-TF-IDF 权重,我们可以使用 get_topic() 函数:
topic_model.get_topic(2)[('summarization', 0.029974019692323675),('summaries', 0.018938088406361412),('summary', 0.018019112468622436),('abstractive', 0.015758156442697138),('document', 0.011038627359130419),('extractive', 0.010607624721836042),('rouge', 0.00936377058925341),('factual', 0.005651676100789188),('sentences', 0.005262910357048789),('mds', 0.005050565343932314)]
这为我们提供了有关该主题的更多背景信息,并帮助我们理解该主题的内容。例如,看到“流氓”一词出现很有趣,因为这是评估摘要模型的常用指标。
我们可以使用该find_topics()功能根据搜索词搜索特定主题。我们来搜索一下主题建模的主题:
topic_model.find_topics("topic modeling")([17, 128, 116, 6, 235],[0.6753638370140129,0.40951682679389345,0.3985390076544335,0.37922002441932795,0.3769700288091359])
结果显示主题 17 与我们的搜索词具有相对较高的相似度 (0.675)。如果我们再检查这个主题,我们可以发现它确实是一个关于主题建模的主题:
topic_model.get_topic(17)[('topic', 0.0503756681079549),('topics', 0.02834246786579726),('lda', 0.015441277604137684),('latent', 0.011458141214781893),('documents', 0.01013764950401255),('document', 0.009854201885298964),('dirichlet', 0.009521114618288628),('modeling', 0.008775384549157435),('allocation', 0.0077508974418589605),('clustering', 0.005909325849593925)]
虽然我们知道他的主题是关于主题建模的,但让我们看看 BERTopic 摘要是否也分配给这个主题:
topics[titles.index('BERTopic: Neural topic modeling with a class-based TF-IDF procedure')]17
这是!看来该主题不仅涉及基于 LDA 的方法,还涉及基于集群的技术,例如 BERTopic。
最后,我们之前提到,许多主题建模技术假设单个文档甚至一个句子中可以有多个主题。尽管 BERTopic 利用聚类(假设对每个数据点进行单一分配),但它可以近似主题分布。
我们可以使用这种技术来查看 BERTopic 论文中第一句话的主题分布:
index = titles.index('BERTopic: Neural topic modeling with a class-based TF-IDF procedure')# 计算 token 级别的主题分布
topic_distr, topic_token_distr = topic_model.approximate_distribution(abstracts[index][:90], calculate_tokens=True)
df = topic_model.visualize_approximate_distribution(abstracts[index][:90], topic_token_distr[0])
df
图 12 BERTopic 中提供了多种可视化选项。
输出如图 12 所示,表明该文档在一定程度上包含多个主题。这项任务甚至是在代币级别上完成的!
(交互式)可视化
手动浏览XXX主题可能是一项艰巨的任务。相反,一些有用的可视化功能使我们能够对生成的主题有一个广泛的概述。其中许多是通过使用 Plotly 可视化框架进行交互的。
图 13 显示了 BERTopic 中所有可能的可视化选项,从 2D 文档表示和主题条形图到主题层次结构和相似性。尽管我们没有浏览所有可视化,但有一些值得研究。
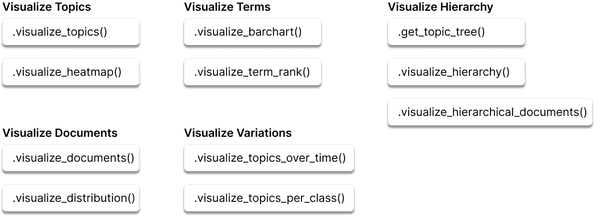
图 13 BERTopic 中提供了多种可视化选项。
首先,我们可以使用 UMAP 来减少每个主题的 c-TF-IDF 表示,从而创建主题的 2D 表示。
topic_model.visualize_topics()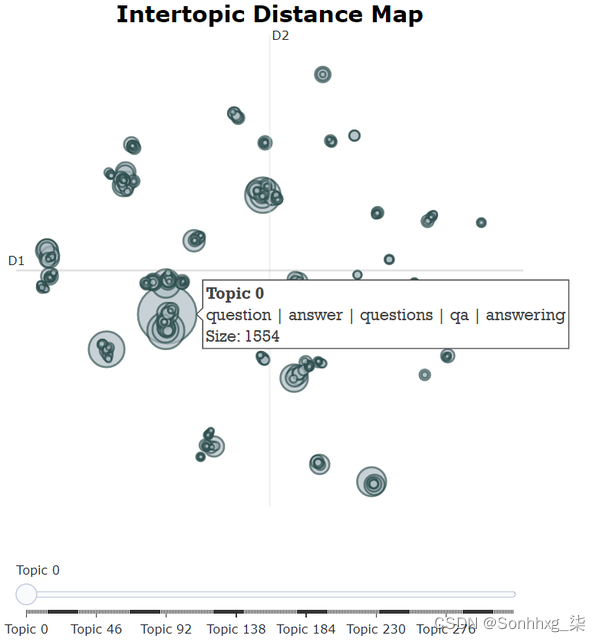
图 14 二维空间中表示的主题间距离图。
如图 14 所示,这会生成一个交互式可视化,当将鼠标悬停在圆圈上时,我们可以看到主题、其关键字及其大小。一个主题的圈子越大,它包含的文档就越多。通过与此可视化的交互,我们可以快速查看相似主题的组。
我们可以使用该visualize_documents()函数将这种分析提升到一个新的水平,即在文档级别分析主题。
# 可视化选定的主题和文档
topic_model.visualize_documents(titles, topic=[0, 1, 2, 3, 4, 6, 7, 10, 12, 13, 16, 33, 40, 45, 46, 65])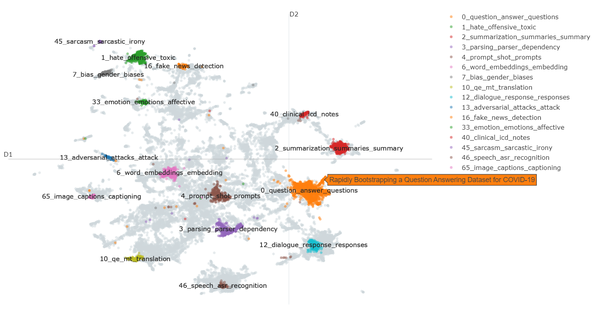
图 15 摘要及其主题以 2D 可视化形式表示。
图 15 演示了 BERTopic 如何在 2D 空间中可视化文档。
我们只可视化了选定的主题,因为显示所有 300 个主题会导致可视化相当混乱。此外,我们传递的不是“摘要”,而是“标题”,因为当我们将鼠标悬停在文档上时,我们只想查看每篇论文的标题,而不是整个摘要。
最后,我们可以使用 Visualize_barchart() 创建所选主题中关键字的条形图:
topic_model.visualize_barchart(topics=list(range(50, 58, 1)))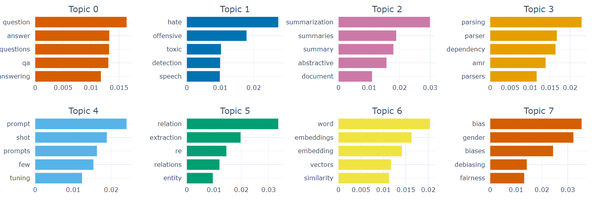
图 16 前 8 个主题的前 5 个关键词。
图 16 中的条形图很好地表明了哪些关键字对于特定主题最重要。以主题2为例——似乎“总结”这个词最能代表该主题,而其他词的重要性也非常相似。
表示模型
通过 BERTopic 采用的神经搜索风格模块化,它可以利用许多不同类型的大型语言模型,同时最大限度地减少计算。这允许使用多种主题微调方法,从词性到文本生成方法,例如 ChatGPT。图 17 展示了我们可以利用各种 LLM 来微调主题表示。

图 17 应用 c-TF-IDF 加权后,可以使用各种表示模型对主题进行微调。其中许多是大型语言模型。
使用 c-TF-IDF 生成的主题可以作为与其主题相关的单词的良好第一排名。在本节中,这些单词的初始排名可以被视为主题的候选关键词,因为我们可能会根据任何表示模型更改它们的排名。我们将介绍几种可在 BERTopic 中使用的表示模型,从大型语言建模的角度来看,这些模型也很有趣。
在开始之前,我们首先需要做两件事。首先,我们将保存原始主题表示,以便更容易比较有和没有表示模型:
# 保存原始表示
from copy import deepcopy
original_topics = deepcopy(topic_model.topic_representations_)其次,让我们创建一个简短的包装器,我们可以使用它来快速可视化主题词的差异,以比较有表示模型和没有表示模型的情况:
def topic_differences(model, original_topics, max_length=75, nr_topics=10):""" 对于前 10 个主题,显示两个模型之间主题表示的差异 """for topic in range(nr_topics):# 提取前 5 个单词每个模型每个主题og_words = " | ".join(list(zip(*original_topics[topic]))[0][:5])new_words = " | ".join(list(zip(*model.get_topic(topic)))[0][:5])# Print a 'before' and 'after'whitespaces = " " * (max_length - len(og_words))print(f"Topic: {topic} {og_words}{whitespaces}--> {new_words}")KeyBERTInspired
c-TF-IDF 生成的主题不考虑主题中单词的语义性质,这可能最终会创建带有停用词的主题。我们可以使用模块bertopic.representation _model.KeyBERTInspired ()根据主题关键字与主题的语义相似度来微调主题关键字。
正如您可能已经猜到的那样,KeyBERTInspired 是一种受关键字提取包 KeyBERT ( GitHub - MaartenGr/KeyBERT: Minimal keyword extraction with BERT ) 启发的方法。在最基本的形式中,KeyBERT 使用余弦相似度将文档中单词的嵌入与文档嵌入进行比较,以查看哪些单词与文档最相关。这些最相似的词被视为关键词。
在 BERTopic 中,我们希望使用类似的东西,但在主题级别而不是文档级别。如图 18 所示,KeyBERTInspired使用c-TF-IDF为每个主题创建一组代表性文档,方法是随机采样每个主题500个文档,计算它们的c-TF-IDF值,并找到最具代表性的文档。这些文档被嵌入并平均以用作更新的主题嵌入。然后,计算候选关键词与更新后的主题嵌入之间的相似度,以对候选关键词重新排名。
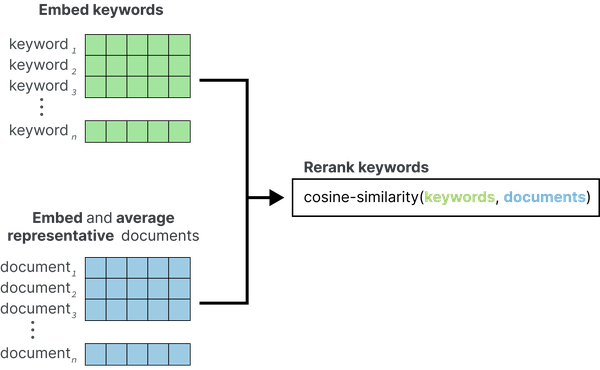
图 18 KeyBERTInspired 表示模型的流程
# KeyBERTInspired
from bertopic.representation import KeyBERTInspired
representation_model = KeyBERTInspired()# 更新我们的主题表示
new_topic_model.update_topics(abstracts, representation_model=representation_model)# 显示主题差异
topic_differences(topic_model, new_topic_model)Topic: 0 question | qa | questions | answer | answering --> questionanswering | answering | questionanswer | attention | retrieval
Topic: 1 hate | offensive | speech | detection | toxic --> hateful | hate | cyberbullying | speech | twitter
Topic: 2 summarization | summaries | summary | abstractive | extractive --> summarizers | summarizer | summarization | summarisation | summaries
Topic: 3 parsing | parser | dependency | amr | parsers --> parsers | parsing | treebanks | parser | treebank
Topic: 4 word | embeddings | embedding | similarity | vectors --> word2vec | embeddings | embedding | similarity | semantic
Topic: 5 gender | bias | biases | debiasing | fairness --> bias | biases | genders | gender | gendered
Topic: 6 relation | extraction | re | relations | entity --> relations | relation | entities | entity | relational
Topic: 7 prompt | fewshot | prompts | incontext | tuning --> prompttuning | prompts | prompt | prompting | promptbased
Topic: 8 aspect | sentiment | absa | aspectbased | opinion --> sentiment | aspect | aspects | aspectlevel | sentiments
Topic: 9 explanations | explanation | rationales | rationale | interpretability --> explanations | explainers | explainability | explaining | attention
更新后的模型显示,与原始模型相比,主题更容易阅读。它还显示了使用基于嵌入的技术的缺点。原始模型中的单词,例如“amr”和“qa”是完全合理的单词
词性
c-TF-IDF 对其认为重要的单词类型不做任何区分。无论是名词、动词、形容词,甚至是介词,它们最终都可以成为重要的关键词。当我们想要拥有易于理解且易于解释的标签时,我们可能需要仅由名词等描述的主题。
这就是著名的 SpaCy 包的用武之地。工业级 NLP 框架,附带各种管道、模型和部署选项。更具体地说,我们可以使用 SpaCy 加载一个能够检测词性的英语模型,无论单词是名词、动词还是其他东西。
如图 19 所示,我们可以使用 SpaCy 来确保只有名词才会出现在我们的主题表示中。与大多数表示模型一样,这是非常高效的,因为名词仅是从数据的一小部分但具有代表性的子集中提取的。

图 19 PartOfSpeech 表示模型的流程
# 词性标记
from bertopic.representation import PartOfSpeechrepresentation_model
= PartOfSpeech("en_core_web_sm") # 在默认管道之上使用 BERTopic 中的表示模型
topic_model.update_topics(abstracts,representation_model=representation_model) # 显示主题差异
topic_differences(topic_model, original_topics)Topic: 0 question | qa | questions | answer | answering --> question | questions | answer | answering | answers
Topic: 1 hate | offensive | speech | detection | toxic --> hate | offensive | speech | detection | toxic
Topic: 2 summarization | summaries | summary | abstractive | extractive --> summarization | summaries | summary | abstractive | extractive
Topic: 3 parsing | parser | dependency | amr | parsers --> parsing | parser | dependency | parsers | treebank
Topic: 4 word | embeddings | embedding | similarity | vectors --> word | embeddings | similarity | vectors | words
Topic: 5 gender | bias | biases | debiasing | fairness --> gender | bias | biases | debiasing | fairness
Topic: 6 relation | extraction | re | relations | entity --> relation | extraction | relations | entity | distant
Topic: 7 prompt | fewshot | prompts | incontext | tuning --> prompt | prompts | tuning | prompting | tasks
Topic: 8 aspect | sentiment | absa | aspectbased | opinion --> aspect | sentiment | opinion | aspects | polarity
Topic: 9 explanations | explanation | rationales | rationale | interpretability --> explanations | explanation | rationales | rationale | interpretability
最大边际相关性
使用 c-TF-IDF,结果关键字中可能存在大量冗余,因为它不认为“car”和“cars”等词本质上是同一件事。换句话说,我们希望最终的主题具有足够的多样性,并且尽可能少地重复。
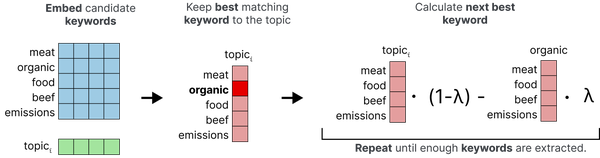
图 20 最大边际相关性表示模型的过程。结果关键词的多样性由 lambda (λ) 表示。
我们可以使用一种称为最大边际相关性(MMR)的算法来使我们的主题表示多样化。该算法从与主题最匹配的关键字开始,然后迭代计算下一个最佳关键字,同时考虑一定程度的多样性。换句话说,它需要多个候选主题关键词,例如30个,并尝试挑选最能代表该主题但又彼此不同的前10个关键词。
# 最大边际相关性
from bertopic.representation import MaximalMarginalRelevance
representation_model = MaximalMarginalRelevance(diversity=0.5)# 在默认管道之上使用 BERTopic 中的表示模型
topic_model.update_topics(abstracts, representation_model=representation_model)# 显示主题差异
topic_differences(topic_model, original_topics)Topic: 0 question | qa | questions | answer | answering --> qa | questions | answering | comprehension | retrieval
Topic: 1 hate | offensive | speech | detection | toxic --> speech | abusive | toxicity | platforms | hatefu我
Topic: 2 summarization | summaries | summary | abstractive | extractive --> summarization | extractive | multidocument | documents | evaluation
Topic: 3 parsing | parser | dependency | amr | parsers --> amr | parsers | treebank | syntactic | constituent
Topic: 4 word | embeddings | embedding | similarity | vectors --> embeddings | similarity | vector | word2vec | glove
Topic: 5 gender | bias | biases | debiasing | fairness --> gender | bias | fairness | stereotypes | embeddings
Topic: 6 relation | extraction | re | relations | entity --> extraction | relations | entity | documentlevel | docre
Topic: 7 prompt | fewshot | prompts | incontext | tuning --> prompts | zeroshot | plms | metalearning | label
Topic: 8 aspect | sentiment | absa | aspectbased | opinion --> sentiment | absa | aspects | extraction | polarities
Topic: 9 explanations | explanation | rationales | rationale | interpretability --> explanations | interpretability | saliency | faithfulness | methods
由此产生的主题更加多样化!主题XXX,原本使用了大量“概括”一词,主题中只包含“概括”一词。此外,现在删除了重复项,例如“嵌入”和“嵌入”。
文本生成
文本生成模型在 2023 年显示出了巨大的潜力。它们在广泛的任务中表现良好,并允许在提示方面发挥广泛的创造力。它们的能力不容低估,坦率地说,不在 BERTopic 中使用它们将是一种浪费。
如图 21 所示,我们可以通过专注于在主题级别而不是文档级别生成输出来在 BERTopic 中有效地使用它们。这可以将API调用的数量从数百万(例如,数百万个摘要)减少到几百(例如,数百个主题)。这不仅显着加快了主题标签的生成速度,而且在使用外部 API(例如 Cohere 或 OpenAI)时也不需要大量积分。

图 21 使用文本生成LLM和提示工程,根据与每个主题相关的关键字和文档为主题创建标签。
Prompting
如图 21所示,文本生成的一个主要组成部分是提示。在 BERTopic 中,这同样重要,因为我们希望为模型提供足够的信息,以便它可以决定主题的内容。BERTopic 中的提示通常如下所示:
prompt = """
I have a topic that contains the following documents: \n[DOCUMENTS]
The topic is described by the following keywords: [KEYWORDS]Based on the above information, give a short label of the topic.
"""该提示由三个部分组成。首先,它提到了最能描述该主题的一些文档。这些文档是通过计算它们的 c-TF-IDF 表示并将它们与主题 c-TF-IDF 表示进行比较来选择的。然后使用“ [DOCUMENTS] ”标签提取并引用前 4 个最相似的文档。
I have a topic that contains the following documents: \n[DOCUMENTS]其次,构成主题的关键字也会传递到提示并使用“ [KEYWORDS] ”标签进行引用。这些关键字也可以使用 KeyBERTInspired、PartOfSpeech 或任何表示模型进行优化。
The topic is described by the following keywords: [KEYWORDS]第三,我们对大语言模型进行了具体说明。这与之前的步骤一样重要,因为这将决定模型如何生成标签。
Based on the above information, give a short label of the topic.对于主题 XXX,提示将呈现如下:
"""
I have a topic that contains the following documents:
- Our videos are also made possible by your support on patreon.co.
- If you want to help us make more videos, you can do so on patreon.com or get one of our posters from our shop.
- If you want to help us make more videos, you can do so there.
- And if you want to support us in our endeavor to survive in the world of online video, and make more videos, you can do so on patreon.com.The topic is described by the following keywords: videos video you our support want this us channel patreon make on we if facebook to patreoncom can for and more watch Based on the above information, give a short label of the topic.
"""HuggingFace
幸运的是,与大多数大型语言模型一样,我们可以通过 HuggingFace 的 Modelhub ( https://huggingface.co/models )使用大量开源模型。
Flan-T5 生成模型系列是最著名的开源大型语言模型之一,它针对文本生成进行了优化。这些模型的有趣之处在于它们是使用一种称为指令调整的方法进行训练的。通过对许多作为指令的任务进行微调 T5 模型,该模型学会遵循特定的指令和任务。
BERTopic 允许使用这样的模型来生成主题标签。我们创建一个提示,并要求它根据每个主题的关键字创建主题,并标有“[KEYWORDS]”标签。
from transformers import pipeline
from bertopic.representation import TextGeneration# 使用 Flan-T5 生成 Text2Text
generator = pipeline('text2text-generation', model='google/flan-t5-xl')
representation_model = TextGeneration(generator)# 使用表示模型在默认管道顶部的 BERTopic
topic_model.update_topics(abstracts, representation_model=representation_model)# 显示主题差异
topic_differences(topic_model, original_topics)Topic: 0 speech | asr | recognition | acoustic | endtoend --> audio grammatical recognition
Topic: 1 clinical | medical | biomedical | notes | health --> ehr
Topic: 2 summarization | summaries | summary | abstractive | extractive --> mds
Topic: 3 parsing | parser | dependency | amr | parsers --> parser
Topic: 4 hate | offensive | speech | detection | toxic --> Twitter
Topic: 5 word | embeddings | embedding | vectors | similarity --> word2vec
Topic: 6 gender | bias | biases | debiasing | fairness --> gender bias
Topic: 7 ner | named | entity | recognition | nested --> ner
Topic: 8 prompt | fewshot | prompts | incontext | tuning --> gpt3
Topic: 9 relation | extraction | re | relations | distant --> docre
创建了一些有趣的主题标签,但我们也可以看到该模型无论如何都不完美。
OpenAI
当我们谈论生成式人工智能时,我们不能忘记 ChatGPT 及其令人难以置信的性能。虽然不是开源的,但它创造了一个有趣的模型,在短短几个月内改变了人工智能领域。我们可以从 OpenAI 的集合中选择任何文本生成模型以在 BERTopic 中使用。
由于该模型是在 RLHF 上进行训练并针对聊天目的进行了优化,因此该模型的提示效果非常令人满意。
from bertopic.representation import OpenAI# OpenAI Representation Model
prompt = """
I have a topic that contains the following documents: \n[DOCUMENTS]
The topic is described by the following keywords: [KEYWORDS]Based on the information above, extract a short topic label in the following format:
topic:
"""
representation_model = OpenAI(model="gpt-3.5-turbo", delay_in_seconds=10, chat=True)# 在 BERTopic 之上使用表示模型默认管道
topic_model.update_topics(abstracts, representation_model=representation_model)# 显示主题差异
topic_differences(topic_model, original_topics) Topic: 0 speech | asr | recognition | acoustic | endtoend --> audio grammatical recognition
Topic: 1 clinical | medical | biomedical | notes | health --> ehr
Topic: 2 summarization | summaries | summary | abstractive | extractive --> mds
Topic: 3 parsing | parser | dependency | amr | parsers --> parser
Topic: 4 hate | offensive | speech | detection | toxic --> Twitter
Topic: 5 word | embeddings | embedding | vectors | similarity --> word2vec
Topic: 6 gender | bias | biases | debiasing | fairness --> gender bias
Topic: 7 ner | named | entity | recognition | nested --> ner
Topic: 8 prompt | fewshot | prompts | incontext | tuning --> gpt3
Topic: 9 relation | extraction | re | relations | distant --> docre
由于我们希望 ChatGPT 以特定格式返回主题,即“主题:<主题标签>”,因此当我们创建自定义提示时,指示模型以这种格式返回主题非常重要。请注意,我们还添加了“delay_in_seconds”参数,以便在您有免费帐户的情况下在 API 调用之间创建恒定的延迟。
Cohere
与 OpenAI 一样,我们可以在 BERTopic 管道之上使用 Cohere 的 API,通过生成文本模型进一步微调主题表示。确保获取 API 密钥,然后您就可以开始生成主题表示。
import cohere
from bertopic.representation import Cohere# Cohere Representation Model
co = cohere.Client(my_api_key)
representation_model = Cohere(co)# 在默认管道之上使用 BERTopic 中的表示模型
topic_model.update_topics(abstracts, representation_model=representation_model)# 显示主题差异
topic_differences(topic_model, original_topics)Topic: 0 speech | asr | recognition | acoustic | endtoend --> audio grammatical recognition
Topic: 1 clinical | medical | biomedical | notes | health --> ehr
Topic: 2 summarization | summaries | summary | abstractive | extractive --> mds
Topic: 3 parsing | parser | dependency | amr | parsers --> parser
Topic: 4 hate | offensive | speech | detection | toxic --> Twitter
Topic: 5 word | embeddings | embedding | vectors | similarity --> word2vec
Topic: 6 gender | bias | biases | debiasing | fairness --> gender bias
Topic: 7 ner | named | entity | recognition | nested --> ner
Topic: 8 prompt | fewshot | prompts | incontext | tuning --> gpt3
Topic: 9 relation | extraction | re | relations | distant --> docre
LangChain
为了进一步发展大型语言模型,我们可以利用 LangChain 框架。它允许用附加信息来补充任何先前的文本生成方法,甚至链接在一起。最值得注意的是,LangChain 将语言模型与其他数据源连接起来,使它们能够与环境交互。
例如,我们可以使用它通过 OpenAI 构建矢量数据库,并在该数据库之上应用 ChatGPT。由于我们希望最大限度地减少 LangChain 所需的信息量,因此将最具代表性的文档传递到包中。然后,我们可以使用LangChain支持的任何语言模型来提取主题。下面的示例演示了 OpenAI 与 LangChain 的结合使用。
from langchain.llms import OpenAI
from langchain.chains.question_answering import load_qa_chain
from bertopic.representation import LangChain# Langchain representation model
chain = load_qa_chain(OpenAI(temperature=0, openai_api_key=MY_API_KEY), chain_type="stuff")
representation_model = LangChain(chain)# 在默认管道之上使用 BERTopic 中的表示模型
topic_model.update_topics(abstracts, representation_model=representation_model)# 显示主题差异
topic_differences(topic_model, original_topics)Topic: 0 speech | asr | recognition | acoustic | endtoend --> audio grammatical recognition
Topic: 1 clinical | medical | biomedical | notes | health --> ehr
Topic: 2 summarization | summaries | summary | abstractive | extractive --> mds
Topic: 3 parsing | parser | dependency | amr | parsers --> parser
Topic: 4 hate | offensive | speech | detection | toxic --> Twitter
Topic: 5 word | embeddings | embedding | vectors | similarity --> word2vec
Topic: 6 gender | bias | biases | debiasing | fairness --> gender bias
Topic: 7 ner | named | entity | recognition | nested --> ner
Topic: 8 prompt | fewshot | prompts | incontext | tuning --> gpt3
Topic: 9 relation | extraction | re | relations | distant --> docre
主题建模变体
主题建模的领域相当广泛,范围从许多不同的应用到同一模型的变体。这也适用于 BERTopic,因为它针对不同目的实现了各种变体,例如动态、(半)监督、在线、分层和引导主题建模。图22 -X 显示了许多主题建模变体以及如何在 BERTopic 中实现它们。
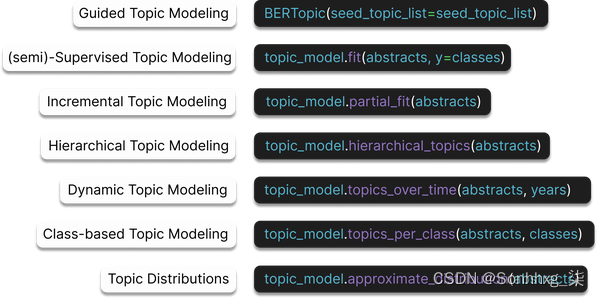
图 22 BERTopic 中的 -X 主题建模变体
概括
在本文中,我们讨论了一种基于集群的主题建模方法,BERTopic。通过利用模块化结构,我们使用各种大型语言模型来创建文档表示并微调主题表示。我们提取了 ArXiv 摘要中的主题,并了解如何使用 BERTopic 的模块化结构来开发不同类型的主题表示。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!