otto-group-product-classification-challenge 神经网络 分类训练
1.数据集: kaggle竞赛提供的一个商品分类数据集。
200,000 种产品,(样本数量)
93 个特征,(输入特征维数)
目标是建立一个能够区分要产品9种类别(输出维数)的预测模型。
数据集下载链接:
kagge 竞赛官网:(得注册登录,嫌麻烦的话可以直接去我的网盘,后面给出链接)
Otto Group Product Classification Challenge | Kaggle
其中,sampleSubmission.csv是提交格式,(不过deadline已经过了,现在可以拿来做分类练手,提交后可以看到自己的排名,大佬云集!)。

train.csv是训练集,除了特征以外,还有类别用于模型训练。

test.csv是测试集,只有特征,类别得我们拿训练好的模型做预测。
数据集网盘链接:
链接: https://pan.baidu.com/s/1MHh-RHTX38vqMrE83lAWZg?pwd=tw1q
提取码: tw1q
2.模型:
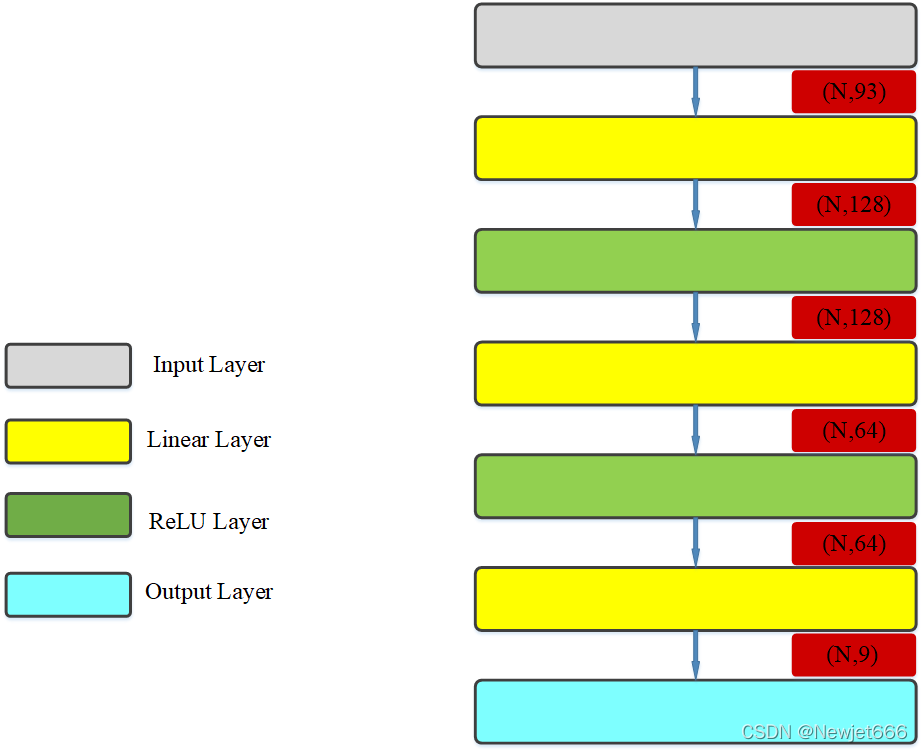
本文采用了如上图所示的全连接神经网络模型,其中,N指batch_size。
3.python 代码
import torch
import numpy as np
import pandas as pd
from tensorboardX import SummaryWriter
from torch import nn, optim
from torch.nn import Linear, ReLU, CrossEntropyLoss
from torch.nn.functional import softmax
from torch.utils.data import Dataset, DataLoader, SubsetRandomSampler# 使用gpu加速,没有显卡就用cpu
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 读取训练和测试数据集,数据类型为DataFrame
train_set = pd.read_csv("dataset/train.csv", index_col='id')
test_set = pd.read_csv("dataset/test.csv", index_col='id')# 确定分类,从训练集的分类中选中所有不重复分类labels
classes = train_set.iloc[:, -1].unique()# 建立分类号 和 products 的对应关系
idx_to_class = {i: x for i, x in enumerate(classes)}
class_to_idx = {x: i for i, x in idx_to_class.items()}# 数据集归一化
# 训练集
for col in train_set.columns[: -1]:mean = train_set[col].mean()std = train_set[col].std()train_set[col] = train_set[col].apply(lambda x: (x - mean) / std)# 测试集
for col in test_set.columns[:-1]:mean = train_set[col].mean()std = train_set[col].std()test_set[col] = test_set[col].apply(lambda x: (x - mean) / std)# 准备数据集,这里需要注意的是,训练集返回特征+类别号,测试集只返回特征
class data_set(Dataset):def __init__(self, df, train=True):self.df = dfself.train = trainif self.train:self.X = torch.from_numpy(np.array(self.df.iloc[:, :-1]))self.Y = [class_to_idx[x] for x in self.df.iloc[:, -1]]self.Y = torch.from_numpy(np.array(self.Y))else:self.X = torch.from_numpy(np.array(self.df))self.Y = torch.Tensor([])def __getitem__(self, item):if self.train:return self.X[item], self.Y[item]else:return self.X[item]def __len__(self):return len(self.df)# 数据集类实例化
train_data_set = data_set(train_set, train=True)
test_data_set = data_set(test_set, train=False)# 随机划分训练集和验证集0.8,0.2
num = len(train_data_set)
indices = list(range(num))
np.random.shuffle(indices)
split = int(np.floor(0.2 * num))
train_idx, valid_idx = indices[split:], indices[:split]# 随机采样器设置
train_sample = SubsetRandomSampler(train_idx)
valid_sample = SubsetRandomSampler(valid_idx)batch_size = 64# DataLoader生成Minibatch
train_loader = DataLoader(train_data_set, batch_size, sampler=train_sample)
valid_loader = DataLoader(train_data_set, batch_size, sampler=valid_sample)
test_loader = DataLoader(test_data_set, batch_size)# 模型类
class model(nn.Module):def __init__(self):super(model, self).__init__()self.Linear1 = Linear(93, 128, bias=True)self.Linear2 = Linear(128, 64, bias=True)self.Linear3 = Linear(64, 9, bias=True)self.activate = ReLU()def forward(self, x):x = self.activate(self.Linear1(x))x = self.activate(self.Linear2(x))x = self.Linear3(x)return x# 类实例化
my_model = model()
my_model.to(device)# loss
criterion = CrossEntropyLoss(size_average=True)
criterion = criterion.to(device)# SGD
optimizer = optim.SGD(my_model.parameters(), lr=0.01, momentum=0.1)# 训练次数
epoch_num = 100
valid_loss_min = np.Inf# 可视化
writer = SummaryWriter("logs")for epoch in range(epoch_num):print("epoch:{}".format(epoch))# 模型训练my_model.train()train_loss = 0train_iter = 0for data in train_loader:train_iter += 1x, y = datax, y = x.to(device), y.to(device)y_pred = my_model(x.float())loss = criterion(y_pred, y)train_loss += loss.item()optimizer.zero_grad()loss.backward()optimizer.step()print("train_loss:{}".format(train_loss / train_iter))writer.add_scalar("train_loss", train_loss / train_iter, epoch)# 模型验证my_model.eval()valid_loss = 0valid_iter = 0for data in valid_loader:valid_iter += 1x, y = datax, y = x.to(device), y.to(device)y_pred = my_model(x.float())loss = criterion(y_pred, y)valid_loss += loss.item()if valid_loss < valid_loss_min:torch.save(model.state_dict(my_model), 'model.pt')valid_loss_min = valid_lossprint("model saved to path:model.pt")print("valid_loss:{}".format(valid_loss / valid_iter))writer.add_scalar("valid_loss", valid_loss / valid_iter, epoch)writer.close()# 加载训练好的模型和参数
my_model.load_state_dict(torch.load("model.pt", map_location=device))# 创建DataFrame准备写入结果数据
test_df = pd.DataFrame(0, index=np.arange(test_set.shape[0]), columns=np.concatenate([np.array(["id"]), classes]))
test_df['id'] = test_set.index# 开始测试
my_model.eval()
with torch.no_grad():counter = 0for data in test_loader:data = data.to(device)pred = my_model(data.float())# 注意这里的pred是线性层输出,要想输出概率,还得经过softmaxrow = softmax(pred).datafin_row = np.around(row.squeeze().to('cpu').numpy(), decimals=1)test_df.iloc[counter * batch_size:(counter + 1) * batch_size, 1:] = fin_row.copy()counter += 1# 写入数据到submission.csv
test_df.to_csv('submission.csv', index=False)
刚开始写,有很多不懂的地方,幸好kaggle大佬们写的代码开源,自己照着敲了一遍,收获巨大。
4.可视化结果:
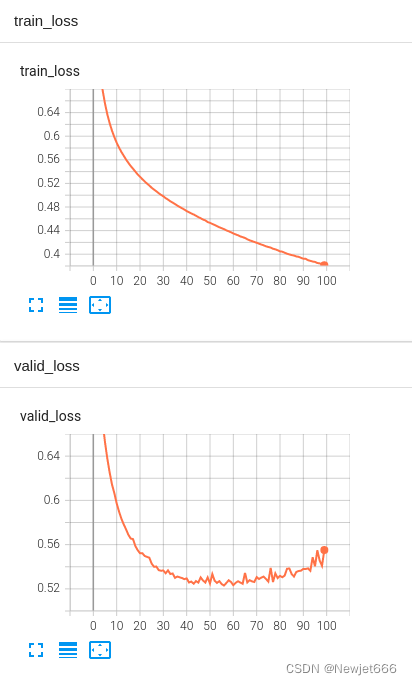
模型在训练集上逐步收敛,在验证集上loss先降低,又升高,原因是训练次数过多,导致过拟合,因此,在模型保存时,保存了泛化能力最好的模型参数,即在验证集上loss最小时的模型参数。
5.最后,一起进步!
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!