秀,Pandas 一行代码爬取半个月天气预报~
谈及Pandas的read.xxx系列的函数,大家的第一反应会想到比较常用的pd.read_csv()和pd.read_excel()
但是大多数人估计没用过pd.read_html()这个函数。虽然它低调,但功能非常强大,用于抓取Table表格型数据时,简直是个神器。
是的,这个神器可以用来爬虫!

定 义
pd.read_html()这个函数功能强大,无需掌握正则表达式或者xpath等工具,短短的几行代码就可以轻松实现抓取Table表格型网页数据。
原 理
一.Table表格型数据网页结构
为了了解Table网页结构,我们看个简单例子。
![]()

新浪天气预报
规律:以Table结构展示的表格数据,网页结构长这样:
... ... ... ... ...... ...
pandas请求表格数据原理

基本流程
其实,pd.read_html可以将网页上的表格数据都抓取下来,并以DataFrame的形式装在一个list中返回。
pd.read_html语法及参数
@deprecate_nonkeyword_arguments(version="2.0")
def read_html(io: FilePathOrBuffer,match: str | Pattern = ".+",flavor: str | None = None,header: int | Sequence[int] | None = None,index_col: int | Sequence[int] | None = None,skiprows: int | Sequence[int] | slice | None = None,attrs: dict[str, str] | None = None,parse_dates: bool = False,thousands: str | None = ",",encoding: str | None = None,decimal: str = ".",converters: dict | None = None,na_values=None,keep_default_na: bool = True,displayed_only: bool = True,
) -> list[DataFrame]:基本语法
io :接收网址、文件、字符串;
parse_dates:解析日期;
flavor:解析器;
header:标题行;
skiprows:跳过的行;
attrs:属性,比如 attrs = {'id': 'table'}参数详解
io :接收网址、文件、字符串;
parse_dates:解析日期;
flavor:解析器;
header:标题行;
skiprows:跳过的行;
attrs:属性,比如 attrs = {'id': 'table'}数据获取
今天我们要爬取的网站是新浪天气,这是一个含有table表格的网站,我们可以选择pa.read_html()直接进行数据爬取
数据获取结果展示如下:
# 导入所需的库
import pandas as pd
from icecream import ic# 目标网站
url = 'http://weather.sina.com.cn/china/beijingshi/'# 开始爬取网站
pd_data = pd.read_html(url)[1]# 结果展示
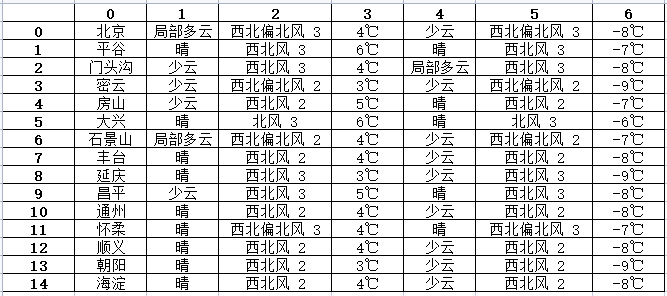
ic(pd_data)'''
ic| pd_data: 0 1 2 3 4 5 60 北京 局部多云 西北偏北风 3 4℃ 少云 西北偏北风 3 -8℃1 平谷 晴 西北风 3 6℃ 晴 西北风 3 -7℃2 门头沟 少云 西北风 3 4℃ 局部多云 西北风 3 -8℃3 密云 少云 西北偏北风 2 3℃ 少云 西北偏北风 2 -9℃4 房山 少云 西北风 2 5℃ 晴 西北风 2 -7℃5 大兴 晴 北风 3 6℃ 晴 北风 3 -6℃6 石景山 局部多云 西北偏北风 2 4℃ 少云 西北偏北风 2 -7℃7 丰台 晴 西北风 2 4℃ 少云 西北风 2 -8℃8 延庆 晴 西北风 3 3℃ 少云 西北风 3 -9℃9 昌平 少云 西北风 3 5℃ 晴 西北风 3 -8℃10 通州 晴 西北风 2 4℃ 少云 西北风 2 -8℃11 怀柔 晴 西北偏北风 3 4℃ 晴 西北偏北风 3 -7℃12 顺义 晴 西北风 2 4℃ 少云 西北风 2 -8℃13 朝阳 晴 西北风 2 3℃ 少云 西北风 2 -9℃14 海淀 晴 西北风 2 4℃ 少云 西北风 2 -8℃
'''注意,并不是所有表格都可以用pd.read_html爬取,有的网站表面上看起来是表格,但在网页源代码中不是table格式,而是list列表格式。
这种表格则不适用read_html爬取,得用其他的方法,比如selenium。
数据存储
pd_data.to_excel('天气预报.xlsx')最后我们使用pandas方法将数据保存在excel中,也是需要一行代码搞定的。方法如下:
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!