函数绘图语言解释器——编译原理课程实验报告
目录
一、实验目的
二、实验环境
三、实验内容
四、心得体会
一、实验目的
- 会用正规式和产生式设计简单语言的语法
- 会用递归下降子程序编写编译器或解释器
- 会撰写简单的技术文档
二、实验环境
Dev_c++ 5.1
三、实验内容
- 代码组织框架
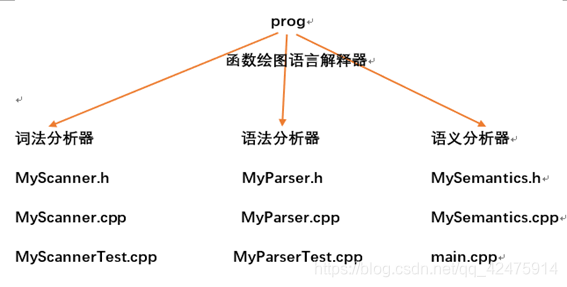
2.词法分析器
1.记号种类Token_Type:
ORIGIN,SCALE,ROT,IS,FOR,FROM,TO,STEP,DRAW, //关键字
T //参数
SEMICO,L_BRACKET,R_BRACKET,COMMA,//分隔符
PLUS,MINUS,MUL,DIV,POWER,//运算符
FUNC,//函数
CONST_ID,//常量
NONTOKEN,ERRTOKEN//空符号,出错符
2.记号类 Token
Token_Type type,//记号种类
char *lexeme,//记号原始串
double value,//常数的值
double (*func_ptr)(double)//函数指针
3.词法分析器类 Scanner
属性:
FILE * InFile; //输入文件流
unsigned int LineNo; //记号所在行号
char TokenStr[Token_Maxlen]; //记号缓冲区
方法:
MyScanner() { LineNo = 1; };
~MyScanner() {};
int InitScanner(const char *FileName); //获取文件输入流初始化InFile
void CloseScanner(); //关闭文件
unsigned int GetLineNo(); //获取当前记号所在行号
Token GetToken(); //获取记号
char GetChar(); //从文件输入流中读取一个字符并转为大写
void BackChar(char NextChar);//把字符回退到文件输入流中
void AddToTokenStr(char NextChar);//识别到的记号加入到记号缓冲中
Token InTokenTable(const char *c_str);//判断给定字符串是否在符号表中
void ClearTokenStr(); //清空记号缓冲区
4.对核心函数GetToken的设计思路
Token MyScanner::GetToken()
a.先过滤掉空白字符和换行,成功读入第一个字符并加入记号缓冲区;
b.如果第一个字符是字母,则可能是关键字,参数,PI,E,读入完成后,看该原始记号串是否在符号表中,存在返回该记号,不存在返回错误记号ErrToken;
c.如果第一个字符是数字,则只能是数(也包含小数),当读入到小数点时,可接着从缓冲区中读小数部分;
d.还可能读入的是运算符,这里读入-可能是减号或注释,/可能是除号或注释,*可能是乘号或幂运算,这些可通过多读一个字符得到唯一确定。其他则是出错记号ErrToken;
3.语法分析器
1.表达式的语法树节点类型
typedef struct TreeNodeStruct {
enum Token_Type OpCode; //接收记号的种类
union {struct { TreeNodeStruct *left, *right; } CaseOp; //二元运算节点struct { TreeNodeStruct *child; func_ptr mathfuncptr; } CaseFunc; //函数调用节点double CaseConst; //常数节点double *CasePara; //参数节点} content;
} *TreeNode;
2.构造语法树
TreeNode MakeTreeNode(enum Token_Type opcode, ...); //构造语法树
void PrintSyntaxTree(TreeNode root, int indent); //打印语法树3.递归子程序
//根据BNCF构造的非终结符递归子程序 //主要产生式的递归子程序,可明显分为两类//函数绘图语言的语句部分(for,origin,rot,scale语句等)仅进行语法分析,无需构造语法树,因此函数设计为void类型 void Program();void Statement();virtual void ForStatement();virtual void OriginStatement();virtual void RotStatement();virtual void ScaleStatement();//对表达式进行语法分析时还要为其构造语法树,因此函数返回值设计为指向语法树节点的指针。 TreeNode Expression();TreeNode Term();TreeNode Factor();TreeNode Component();TreeNode Atom();
4.这里核心是文法的推导和根据所得文法书写递归下降子程序
文法的一步一步优化
G1文法
Program-->ε| Program Statement SEMICO
Statement-->OriginStatement|ScaleStatement|RotStatement|ForStatement
OriginStatement-->ORIGIN IS L_BRACKET Expression COMMA Expression R_BRACKET
ScaleStatement-->SCALE IS L_BRACKET Expression COMMA Expression R_BRACKET
RotStatement-->ROT IS Expression
ForStatement-->FOR T FROM expression TO Expression STEP ExpressionDRAW L_BRACKET Expression COMMA Expression R_BRACKET
Expression-->Expression PLUS Expression //a+b |Expression MINUS Expression //a-b |Expression MUL Expression //a*b |Expression DIV Expression //a/b |PLUS Expression //+b |MINUS Expression //-b |Expression POWER Expression //a**b |CONST_ID //常数|T|FUNC L_BRACKET Expression R_BRACKET //sin(t)|L_BRACKET Expression R_BRACKET //(a)
G2 (G1中Expression产生式是二义的,因为它没有区分运算的优先级和结合性,即所有的候选项均具有同等的指导分析的权利,从而造成有些分析步骤的不确定性)
改写文法,根据运算的优先级将Expression的所有候选项分组,具有相同优先级的候选项被分在同一个组里,并为每一个组引入一个非终结符
从上至下,结合性依次升高
| 表达式中的运算 | 结合性 | 非终结符 |
| (二元)PLUS,MINUS | 左结合 | Expression |
| MUL,DIV | 左结合 | Term |
| (一元) PLUS,MINUS | 右结合 | Factor |
| POWER | 右结合 | Component |
| (原子表达式)(常数,参数,函数,括号) | 无 | Atom |
Expression-->Expression PLUS Term |Expression MINUS Term |Term
Term-->Term MUL Factor|Term DIV Factor|Factor
Factor-->PLUS Factor|MINUS Factor|Component
Component-->Atom POWER Component|Atom
Atom-->CONST_ID|T|FUNC L_BRACKET Expression R_BRACKET|L_BRACKET Expression R_BRACKET
G3(G2中Program,Expression,Term含有左递归,G3是消除左递归和左因子的文法)
Program-->Statement SEMICO Program|ε
Expression-->Term Expression`
Expression`--> PLUS Term Expression`|MINUS Term Expression`|ε
Term-->Factor Term`
G4(编写适合递归下降子程序的文法) {},[],|,()
Program-->{Statement SEMICO} 重复0次或若干次
Statement-->OriginStatement|ScaleStatement|RotStatement|ForStatement
OriginStatement-->ORIGIN IS L_BRACKET Expression COMMA Expression R_BRACKET
ScaleStatement-->SCALE IS L_BRACKET Expression COMMA Expression R_BRACKET
RotStatement-->ROT IS Expression
ForStatement-->FOR T FROM expression TO Expression STEP ExpressionDRAW L_BRACKET Expression COMMA Expression R_BRACKET
Expression-->Term {(PLUS|MINUS) Term}
Term-->Factor {(MUL|DIV) Factor}
Factor-->PLUS Factor|MINUS Factor|Component
//保持产生式的右递归形式,在程序中通过递归调用实现右边的运算符的先计算
Component-->Atom POWER Component |Atom
Atom-->CONST_ID|T|FUNC L_BRACKET Expression R_BRACKET|L_BRACKET Expression R_BRACKET
根据EBNF所得的递归子程序(产生式左部分是函数名,后部分是函数体,根据上述文法中的产生式很容易写出递归程序,这里以两个为例,其他的同理可得)遇到终结符匹配,遇到非终结符递归下降到子程序
void MyParser::ForStatement() {//ForStatement ->FOR T FROM Expression TO Expression STEP //Expression DRAW (Expression,Expression)TreeNode StartPtr,EndPtr,StepPtr,XPtr,YPtr;StartPtr=EndPtr=StepPtr=XPtr=YPtr=NULL;//起点,终点,步长横,纵坐标表达式的语法树MatchToken(FOR, "FOR");MatchToken(T, "T");MatchToken(FROM, "FROM");StartPtr = Expression(); TreeTrace(StartPtr); Start=GetExprValue(StartPtr);MatchToken(TO, "TO");EndPtr = Expression(); TreeTrace(EndPtr);End=GetExprValue(EndPtr);MatchToken(STEP, "STEP");StepPtr = Expression(); TreeTrace(StepPtr);Step=GetExprValue(StepPtr);MatchToken(DRAW, "DRAW");MatchToken(L_BRACKET, "(");XPtr = Expression(); TreeTrace(XPtr);MatchToken(COMMA, ",");YPtr = Expression(); TreeTrace(YPtr);MatchToken(R_BRACKET, ")"); //DrawLoop(Start,End,Step,x_ptr,y_ptr);}//表达式的语法树的递归构造TreeNode MyParser::Expression() {//Expression → Term { ( PLUS | MINUS) Term } TreeNode left, right;Token_Type token_temp; //当前记号类型left = Term(); //左操作数的语法树while (token.type == PLUS || token.type == MINUS) //左结合{token_temp = token.type;MatchToken(token_temp); //第一类匹配right = Term(); //分析右操作数且得到其语法树left = MakeTreeNode(token_temp, left, right);// 构造运算的语法树,结果为左子树}return left;}
4.语义分析器
获取表达式(语法分析数的形式表示)的值
double GetExprValue(TreeNode root){if(root==NULL) return 0.0;switch(root->OpCode){ //二元运算符case PLUS:return GetExprValue(root->content.CaseOp.left)+GetExprValue(root->content.CaseOp.right);break; case MINUS:return GetExprValue(root->content.CaseOp.left)-GetExprValue(root->content.CaseOp.right);break;case MUL:return GetExprValue(root->content.CaseOp.left)*GetExprValue(root->content.CaseOp.right);break;case DIV:return GetExprValue(root->content.CaseOp.left)/GetExprValue(root->content.CaseOp.right);break;case POWER:return pow(GetExprValue(root->content.CaseOp.left),GetExprValue(root->content.CaseOp.right));break;case FUNC: //函数return(*root->content.CaseFunc.mathfuncptr)(GetExprValue(root->content.CaseFunc.child));break;case CONST_ID://常量return root->content.CaseConst;break;case T://参数return *(root->content.CasePara);break;default://默认返回0return 0.0; break;}
}
四、心得体会
- 上机遇到的问题?
①在编写函数绘图语言解释器的过程中,令我感觉到比较难攻克的点是递归下降子程序的编写,因为一开始对文法的推导就是错误的,当时错误的认为语句里出现的所有表达式都可以用expression来统一表示,后来才明白这个文法是二义文法,之后引入新的非终结符消除二义性,消除左递归后才得到真正的递归下降文法。
②当时在文法与程序如何对应上也是思索了一阵,还是之前学的基础知识有所遗忘,在经过了复习之后,其实非常简单,文法中产生式左部对应函数名,产生式右部对应函数体,具体递归下降的规则是:碰到终结符就匹配,碰到非终结符就递归下降到子程序,以此类推。
2. 优点和缺点?
优点:本实验采用面向对象语言c++编写,面向对象提出了类的概念,这使得我可以将词法,语法,语义分析制作成三个类,每个类有自己的属性和方法(方法实现一定的功能),这可以更好的让我明确词法,语法,语义这三个阶段分别要完成的工作以及他们之间如何传递数据,需要传递哪些数据等等。
不足:本实验不足之处在于界面UI比较简陋,在这方面有一定改进的空间。
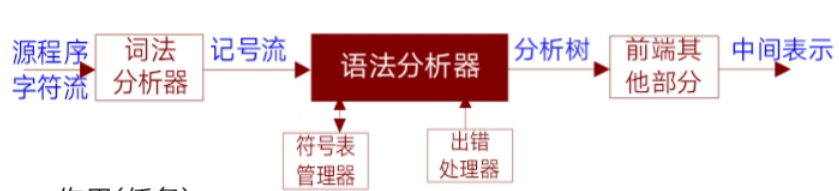
下面贴一张词法、语法分析器之间的关联关系:
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!