Spark的简单安装和介绍( Spark端口为8081)
Spark简介(2022-06-14A)

Spark提供了一个分布式的、弹性的、数据集合(RDD)、我们在Scala当中学习的Seq、Set、Map集合的操作,可以直接应用在RDD(集合),进行Spark数据分析。

Spark集群构建:
Spark框架,没有太多的要求,只是一个计算框架。主从配置,比较方便
- N台机器构建都可以,并且可以很轻松配置出高可用集群。
安装配置(借助两台主机,完成一个Spark高可用的集群)
- 上传安装包、解压
tar -zxvf spark-3.1.2-bin-hadoop2.7.tgz -C /usr/hadoop/
2.配置文件
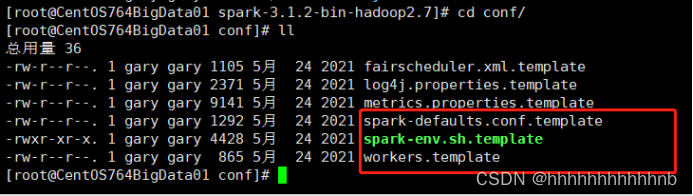
三个配置模板
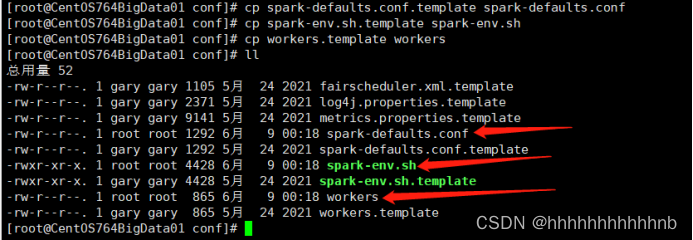
spark-defaults.conf
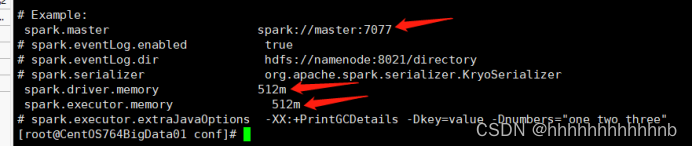
spark-env.sh

export HADOOP_CONF_DIR=/usr/hadoop/hadoop-2.10.1/etc/hadoop
export YARN_CONF_DIR=/usr/hadoop/hadoop-2.10.1/etc/hadoopexport SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=192.168.42.111:2181,192.168.42.112:2181,192.168.42.112:2181 -Dspark.deploy.zookeeper.dir=/usr/hadoop/spark-3.1.2-bin-hadoop2.7/zkData"Workers
将Local host修改为一下主机IP
192.168.42.111
192.168.42.112
192.168.42.113- 分发配置好的spark目录
scp -r spark-3.1.2-bin-hadoop2.7/ 192.168.42.112:/usr/hadoop/
启动测试
Spark依赖与zookeeper,先将Hadoop启动后
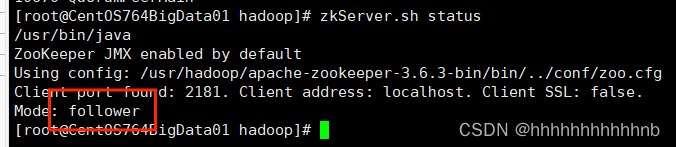
出现Mode类似即可
然后进入sbin目录启动Spark
./start-all.sh本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!