【数据压缩-实验3】LZW编码
目录
LZW编码概述
LZW编解码原理
1.编码算法步骤
2.解码算法步骤
实验代码
1.数据结构分析
2.主要功能模块
3.主函数
实验结果
1.测试LZW编码算法,输出编码文件
2.对上述编码文件进行解码
3.测试10种不同格式的文件,分析压缩效率
-
LZW编码概述
LZW编码是围绕称为词典的转换表 来完成的, LZW 编码器通过管理这个词典完成输入与输出之间的转换。
LZW编码器的输 入是字符流,字符流可以是用 8 位 ASCII 字符组成的字符串,而输出是用 n 位 ( 例如 12 位 ) 表 示的码字流。
相比于Huffman编码:1)LZW编码只需要一遍扫描,具有自适应的特点;2)采用数字查找树/键树的算法,较为简单,便于快速实现
-
LZW编解码原理
1.编码算法步骤
步骤 1 :将词典初始化为包含所有可能的单字符,当前前缀 P 初始化为空。 步骤 2 :当前字符 C= 字符流中的下一个字符。 步骤 3 :判断 P + C 是否在词典中 (1 )如果 “ 是 ” ,则用 C 扩展 P ,即让 P=P + C ,返回到步骤 2 。 (2)如果 “ 否 ” ,则 输出与当前前缀P相对应的码字 W ; 将P+ C 添加到词典中; 令P=C,并返回到步骤 2 该算法首先初始化词典,然后顺序从待压缩文件中读入字符并按照上述步骤执行编码,最后将编得的码字流输出至文件中,可用以下流程图表示:
2.解码算法步骤
步骤 1 :在开始译码时词典包含所有可能的前缀根。 步骤 2 :令 CW : = 码字流中的第一个码字。 步骤 3 :输出当前缀 - 符串 string.CW 到码字流。 步骤 4 :先前码字 PW : = 当前码字 CW 。 步骤 5 :当前码字 CW : = 码字流的下一个码字。 步骤 6 :判断当前缀 - 符串 string.CW是否在词典中。(1)如果 ” 是 ” ,则把当前缀 - 符串 string.CW 输出到字符流。 当前前缀P = 先前缀 - 符串 string.PW 。 当前字符C = 当前前缀 - 符串 string.CW 的第一个字符。 把 缀-符串P+C 添加到词典。 (2)如果 ” 否 ” ,则当前前缀 P : = 先前缀 - 符串 string.PW 。 当前字符C:= 当前缀 - 符串 string.CW 的第一个字符。 输出缀-符串P+C 到字符流 , 然后把它添加到词典中。 步骤7:判断码字流中是否还有码字要译。 (1 )如果 ” 是 ” ,就返回步骤 4 。 (2)如果 ” 否 ”,结束 该算法首先初始化词典,然后顺序从压缩文件中读入码字并按照上述步骤执行解码,最后将解得的字符串输出至文件中,可用以下伪代码段表示:

-
实验代码
1.数据结构分析
利用数字查找树的思想建立该数据结构,词典里的每一个新词条都是由一个旧词条+一个新字符组成,且该树是动态建立的,树中每个节点可能存在多个子节点,故该数据结构中需要包含尾缀、母节点、第一个孩子节点和兄弟节点。可设计如下数据结构:
#define MAX_CODE 65535//词典中最多的词典数目
struct {int suffix;//尾缀字符int parent;//母节点int firstchild;//第一个孩子节点int nextsibling;//下一个兄弟节点
} dictionary[MAX_CODE+1];
int next_code;//用于记录下一个词条位置
int d_stack[MAX_CODE]; // stack for decoding a phrase2.主要功能模块
- 初始化词典
写入所有单个字符节点,构造“树”的第一层:
void InitDictionary( void){int i;for( i=0; i<256; i++){dictionary[i].suffix = i;dictionary[i].parent = -1;dictionary[i].firstchild = -1;dictionary[i].nextsibling = i+1;}dictionary[255].nextsibling = -1;next_code = 256;
}- 查找词典中是否有当前读入字符
int InDictionary( int character, int string_code){int sibling;if( 0>string_code) return character;//如果是单个字符,直接返回当前字符sibling = dictionary[string_code].firstchild;//找第一个孩子节点while( -1- 新串加入词典
void AddToDictionary( int character, int string_code){int firstsibling, nextsibling;if( 0>string_code) return;dictionary[next_code].suffix = character;dictionary[next_code].parent = string_code;dictionary[next_code].nextsibling = -1;dictionary[next_code].firstchild = -1;firstsibling = dictionary[string_code].firstchild;if( -1- 编码
void LZWEncode( FILE *fp, BITFILE *bf){int character;int string_code;int index;unsigned long file_length;fseek( fp, 0, SEEK_END);file_length = ftell( fp);fseek( fp, 0, SEEK_SET);BitsOutput( bf, file_length, 4*8);InitDictionary();string_code = -1;while( EOF!=(character=fgetc( fp))){index = InDictionary( character, string_code);if( 0<=index){ // string+character in dictionarystring_code = index;}else{ // string+character not in dictionaryoutput( bf, string_code);if( MAX_CODE > next_code){ // free space in dictionary// add string+character to dictionaryAddToDictionary( character, string_code);}string_code = character;}}output( bf, string_code);
}- 解码
void LZWDecode( BITFILE *bf, FILE *fp){int character = 0;int new_code, last_code;int phrase_length;unsigned long file_length;file_length = BitsInput(bf, 4 * 8);if (-1 == file_length) file_length = 0;InitDictionary();last_code = -1;while (0 < file_length) {new_code = input(bf);if (new_code >= next_code) { // this is the case CSCSC( not in dict)d_stack[0] = character;phrase_length = DecodeString(1, last_code);}else {phrase_length = DecodeString(0, new_code);}character = d_stack[phrase_length - 1];while (0 < phrase_length) {phrase_length--;fputc(d_stack[phrase_length], fp);file_length--;}if (MAX_CODE > next_code) {// add the new phrase to dictionaryAddToDictionary(character, last_code);}last_code = new_code;}
}3.主函数
int main( int argc, char **argv){FILE *fp;BITFILE *bf;/*传参格式:argv[1]:D或E表示解码或编码argv[2]:输入文件的路径及名称argv[3]:输出文件的路径及名称*/if( 4>argc){fprintf( stdout, "usage: \n%s \n", argv[0]);fprintf( stdout, "\t: E or D reffers encode or decode\n");fprintf( stdout, "\t: input file name\n");fprintf( stdout, "\t: output file name\n");return -1;}if( 'E' == argv[1][0]){ // do encodingfp = fopen( argv[2], "rb");bf = OpenBitFileOutput( argv[3]);if( NULL!=fp && NULL!=bf){LZWEncode( fp, bf);fclose( fp);CloseBitFileOutput( bf);fprintf( stdout, "encoding done\n");}printf("Encode dictionary:\n");PrintDictionary();}else if( 'D' == argv[1][0]){ // do decodingbf = OpenBitFileInput( argv[2]);fp = fopen( argv[3], "wb");if( NULL!=fp && NULL!=bf){LZWDecode( bf, fp);fclose( fp);CloseBitFileInput( bf);fprintf( stdout, "decoding done\n");}printf("Decode dictionary:\n");PrintDictionary();}else{ // otherwisefprintf( stderr, "not supported operation\n");}return 0;
} -
实验结果
1.测试LZW编码算法,输出编码文件 
以上述文本文件作为输入,设置命令行参数如下: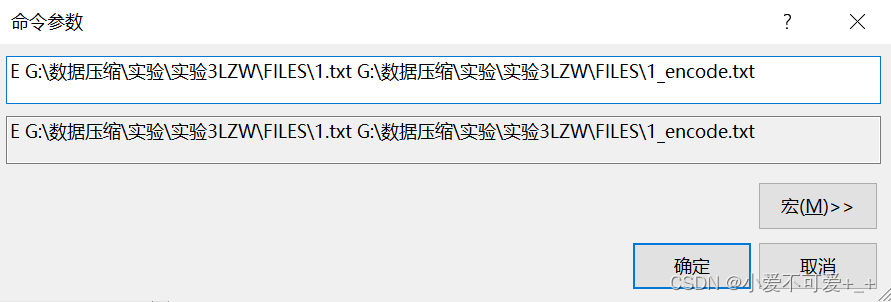
运行成功后打开编码后的文本文件: 
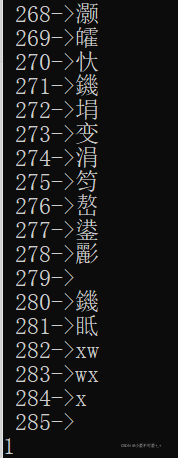
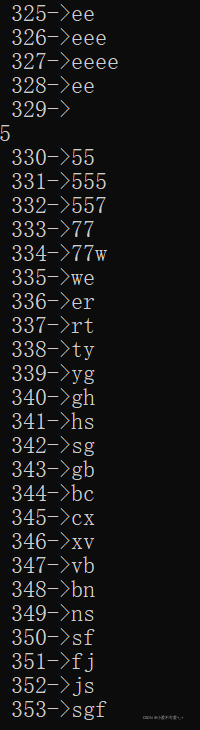
输出词典(一共353个词条):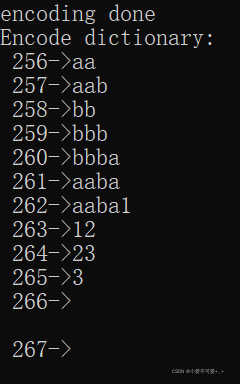


2.对上述编码文件进行解码
设置命令行参数如下:
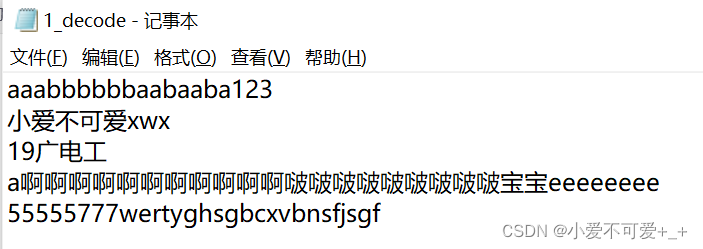
可以成功解码得到原文件且词典相同:
3.测试10种不同格式的文件,分析压缩效率
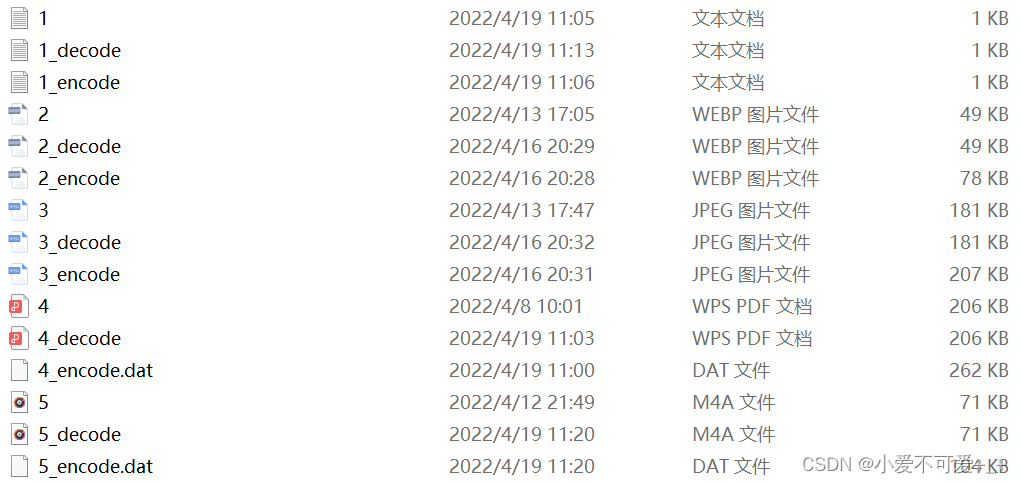
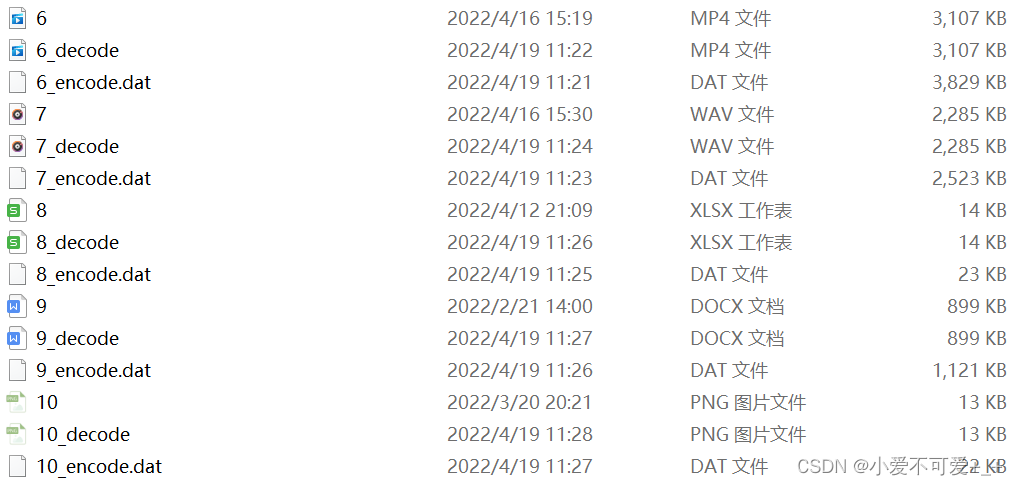
由以上数据观察到不同文件的压缩率差别非常的大,并且有很多文件在利用词典编码之后反而比原文件大了,这体现出了LZW编码的弊端,即当文件中重复字符较少时,需要构建的词典较大,反而会使压缩后的文件变大,从而达不到压缩的目的,故LZW编码要谨慎使用。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!