【每周代码】携程+12306爬虫项目实现
最近一直在做爬虫相关的工作
爬12306算是爬虫里的经典项目了(我觉得基本类似于深度学习里的手写字符串识别项目了hhhh)
和普通的爬虫项目不同,因为要用到实际的工作当中,所以整个流程进行了分布式处理:
大概思路如下:
- 得到车次的全量表,存入数据库(方便以后更新)
- 从数据库中得到车次,从携程上爬取对应车次的中间站信息网页
- 将原网址和对应转存网址的链接都统一存在redis里
- 将网址内容保存在ks3中
- 根据需求从redis里找到对应链接,从ks3中下载内容进行解析
这期间考虑了几个问题:
- 因为12306太容易崩了,所以为了爬虫的稳定性,除了总表是从12306里爬下来的以外,其他的部分都是从携程爬下来的。幸运的是携程没有反爬机制:)
- 分布式的好处在这里可能体现的不明显,对长期任务来说,一些比较难爬取的网页可以一次性存储到ks3中,根据需求多次解析。简单快捷。
- 依旧使用的是scrapy框架,所以代码部分没有体现redis存储和ks3存储(这一部分在自己搭建的架构的middlewares文件里修改)
老规矩,先把参考的微博列上:https://blog.csdn.net/u013243986/article/details/66972705
根据上面连接中的指南,可以得到这样的一个连接:
https://kyfw.12306.cn/otn/resources/js/query/train_list.js?scriptVersion=1.0
这个以js文件的形式加载到页面,包含了未来45天的车次数据,但是只有出发点和终点,没有中间站。
这里默认表里的数据算是火车车次的全量表(45天都没有发车记录的车。。也没有啥统计意义了)
下载的代码如下所示:
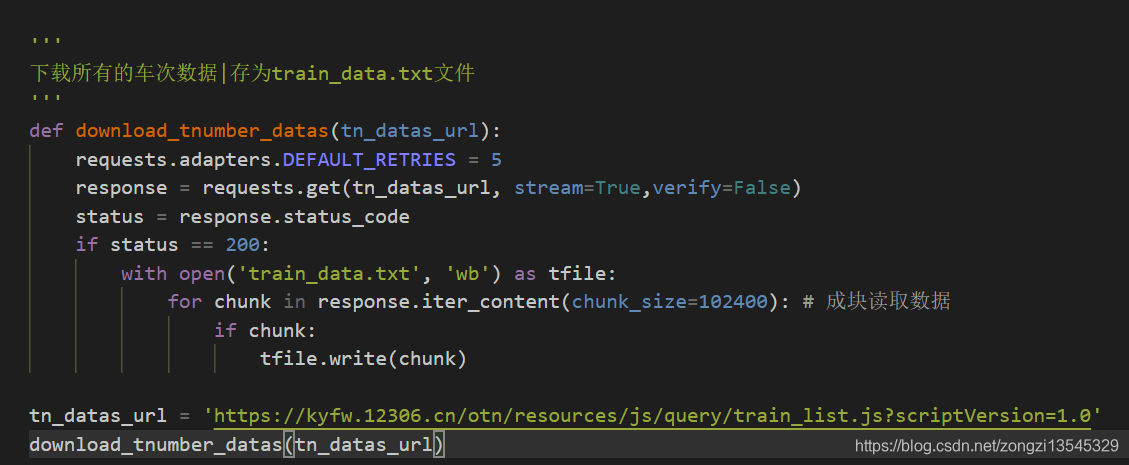
下载成功以后打开,还没有解析的json大概是酱紫的:

因为在这个爬虫项目中,日期的作用不大(只需要知道所有在运营的火车的车次号)
所以进行了解析,用正则表达式过滤了日期和车次后面对应的(出发-终点)的内容
代码如下所示:
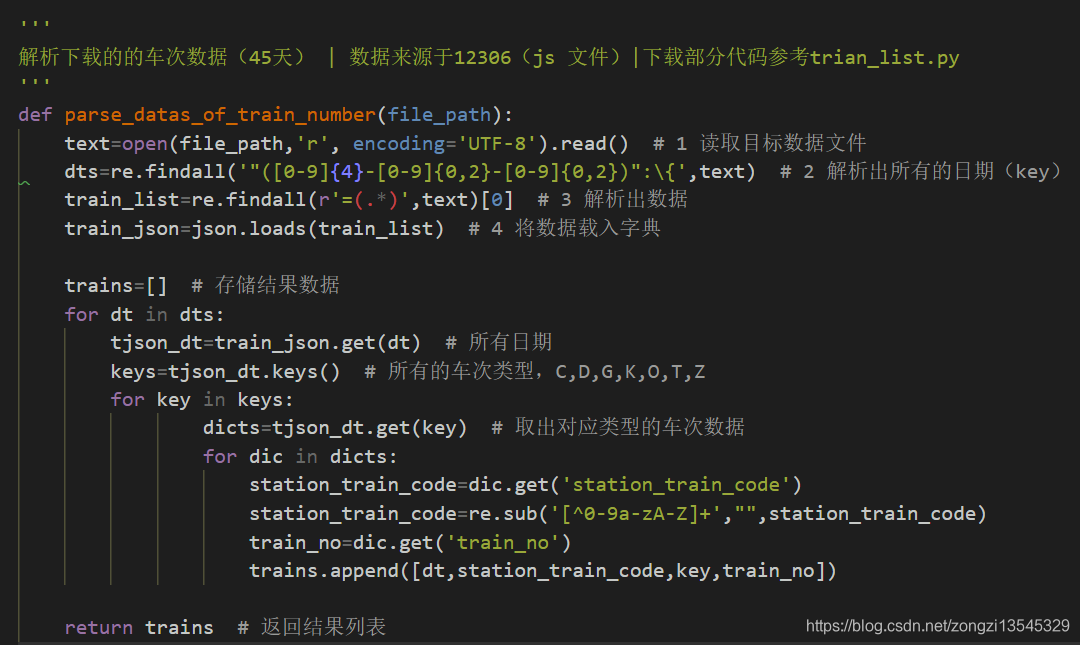

处理完以后的数据如图所示

总共大概9000+数据,可以认为是火车车次可运行的全量表。
因为12306的网站总是时不时崩溃,所以换了携程的网站来爬取数据
(虽然携程的数据也不是很完善,后面还登陆了其他网站进行了补充
还发现了很多冷门小知识hiahiahia)
登陆携程的页面,发现他的格式是这样子的:
http://trains.ctrip.com/TrainSchedule/ + 车次
在这个代码之前我还写过一个百度百科的爬虫,按照人名进行资料爬取,区别在于百度百科存在重名问题(比如张三可能有100个),所以需要对爬取的页面的“多义词”部分进行解析,把所有相同名字的全部爬取下来。
相比之下,携程的要简单很多,因为同一个车次,只会对应一个页面。
所以代码如下
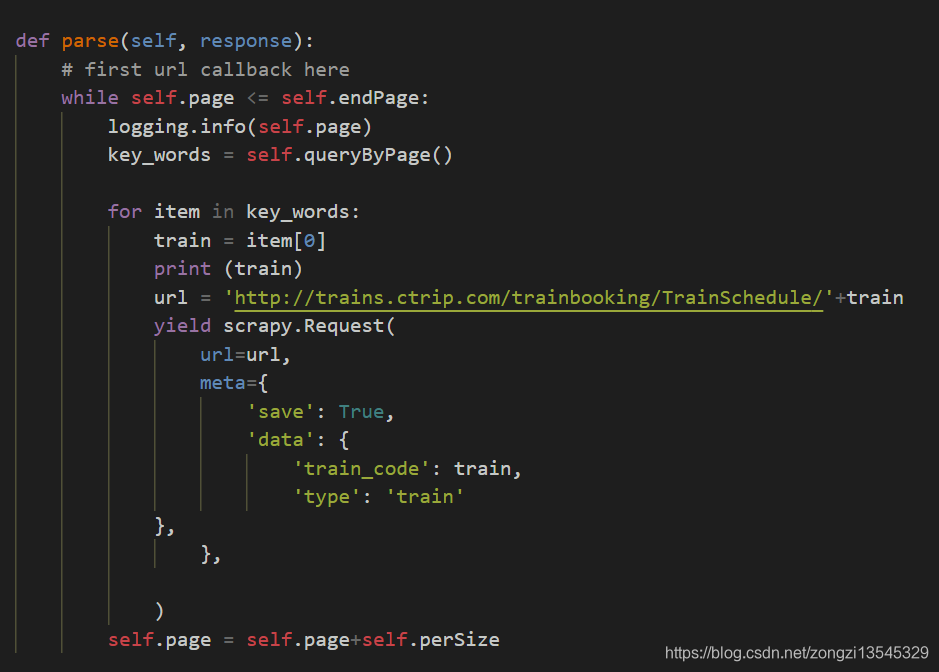
这里涉及到读取数据库的部分并没有截取
转存到redis的部分写在middleware里,并不影响正常用框架爬取
需要注意的是,携程网页的编码方式是“gbk”
如果用utf-8的话会报错
后面因为数据不是很全,又换了别的网页来爬取,整体代码结构差不多,这里就不赘言了。
技术层面来说,这并不是一个很难的操作,因为携程的网页上没有反爬机制,网页结构也比较简单(感觉携程的员工要来打我了
爬取流程比较顺畅
如果说意外收获的话,大概是发现了很多火车的冷知识?
比如P100,实际上车票是不会卖的,正常售票都统一按照Z100来售卖,这辆车是上海通往香港的,每日发车,但是隔日才会停香港,另一半时间在广东就停止了,所以火车系统内部为了区分,就把终点在香港的称作P100
hhhh通过小代码了解一些小知识,也是挺有意思的~
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!