解读:【腾讯】基于兴趣点图谱的内容理解
重磅推荐专栏: 《Transformers自然语言处理系列教程》
手把手带你深入实践Transformers,轻松构建属于自己的NLP智能应用!
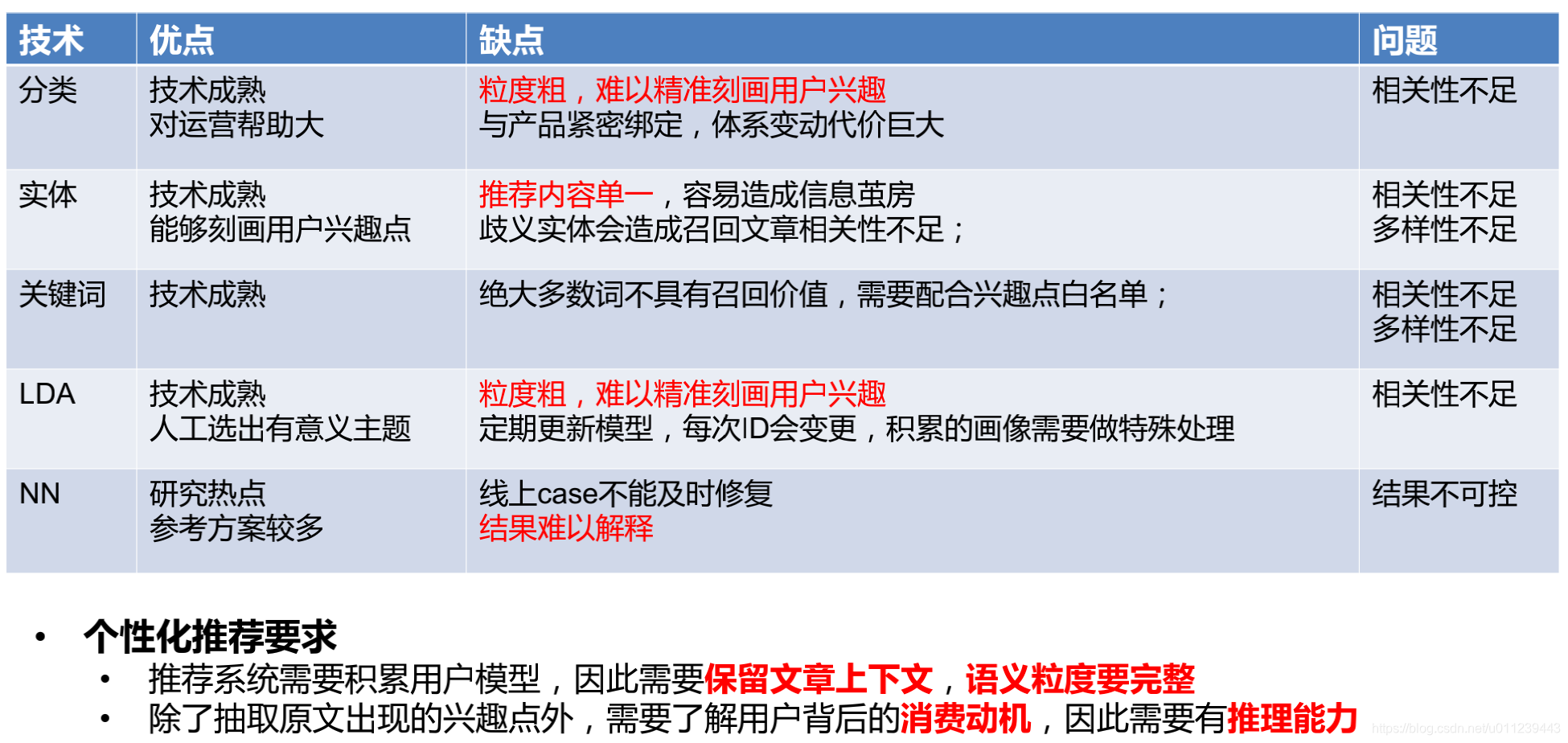
1. 项目背景
1.1 推荐不准

1.2 信息蚕房
单只用“分类、实体、关键词”进行召回,容易导致信息蚕房。如果我们能挖掘出“用户为什么会消费”的“兴趣点”,就能很好的缓解该问题。

1.3 内容理解相关研究
1.4兴趣图谱
这里作者将兴趣点分层了概念、话题和事件

2. 兴趣点图谱建设
2.1 兴趣点挖掘
所谓的兴趣点,就是‘概念’、‘话题’、‘事件’的总称。作者在挖掘出兴趣点后,再基于句式规则、实体抽象等方法将兴趣点分类成‘概念’、‘话题’、‘事件’。下面我们主要介绍兴趣点是怎么挖掘的。
难点:
1)粒度难以合理成符合用户的兴趣
2)训练样本人工难以标注
方案:
1、使用UGC数据,即搜索数据,用户真实表达需求。
2、弱监督方法解决冷启动问题,一种方式是(Alignment Based)类似于计算最大公共子序列的方式得到兴趣点:

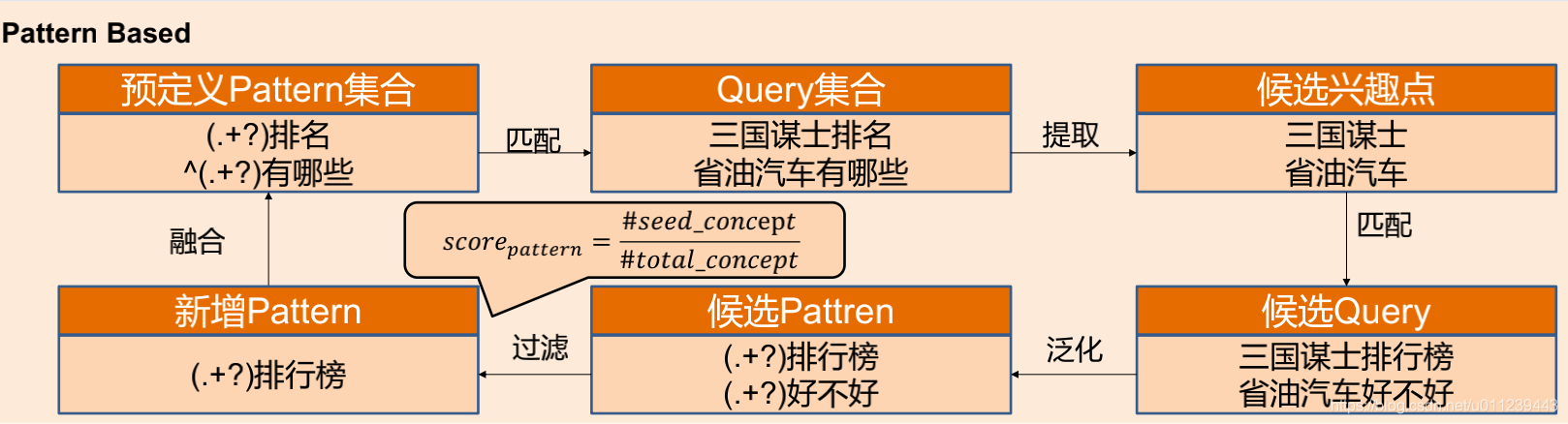
另外一种方式是(pattern bootstrapping):
1、先预定义一些pattern集合
2、从Query集合中匹配Query
3、从匹配到的Query并提出候选兴趣点
4、用得到的候选兴趣点匹配出候选Query
5、基于候选Query泛化出候选Pattern
6、基于Pattern对应的兴趣点数量占比计算候选Pattern的得分,并过来分数低的Pattern,得到新增的Pattern
7.将新增的Pattern融合到pattern集合中,重复以上步骤
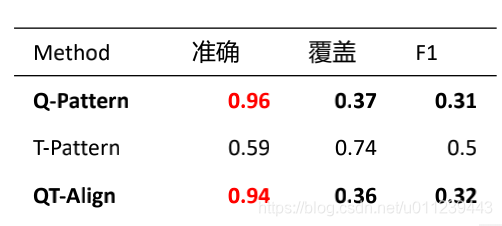
可以看到Q-Pattern和QT-Align准确率不错,但是覆盖率低却非常低。由此作者提出了改进的方案:
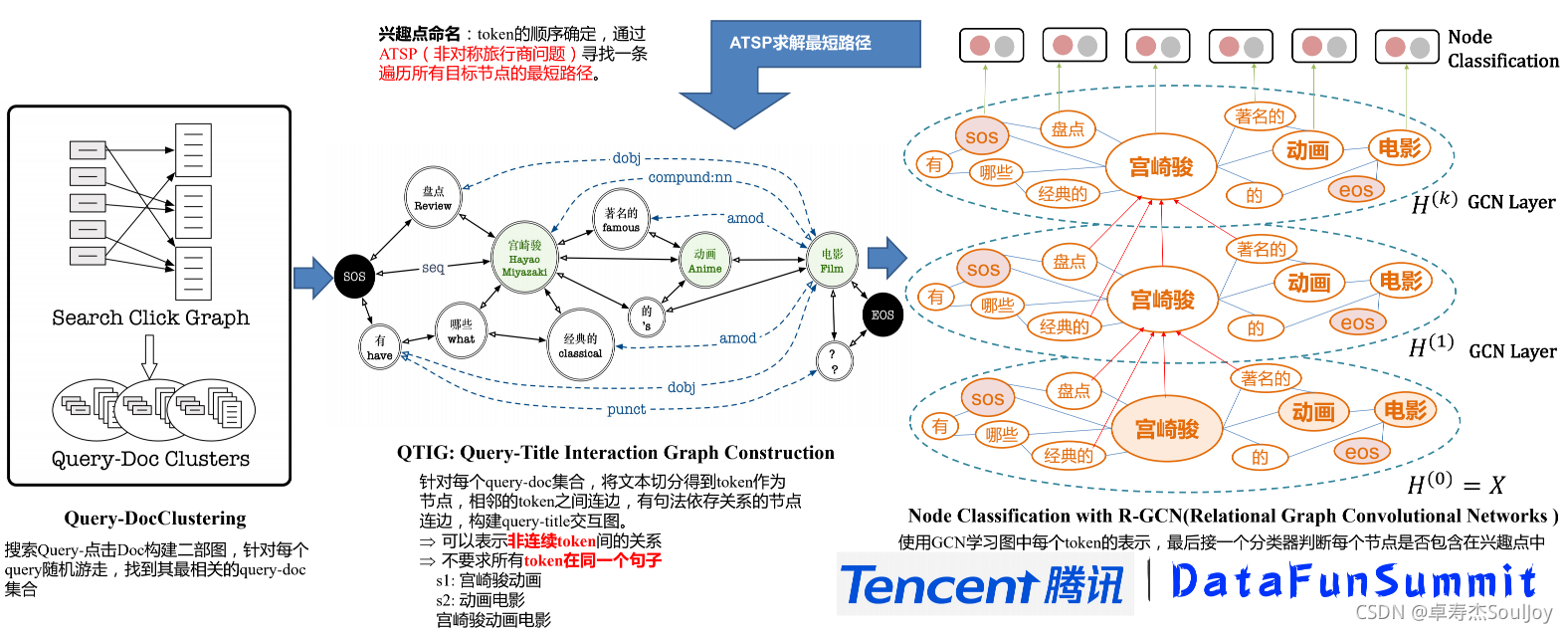
2.2 关系挖掘
2.2.1 上下位关系挖掘
2.2.1.1 分类-概念
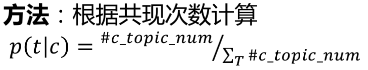
2.2.1.2 概念-实体

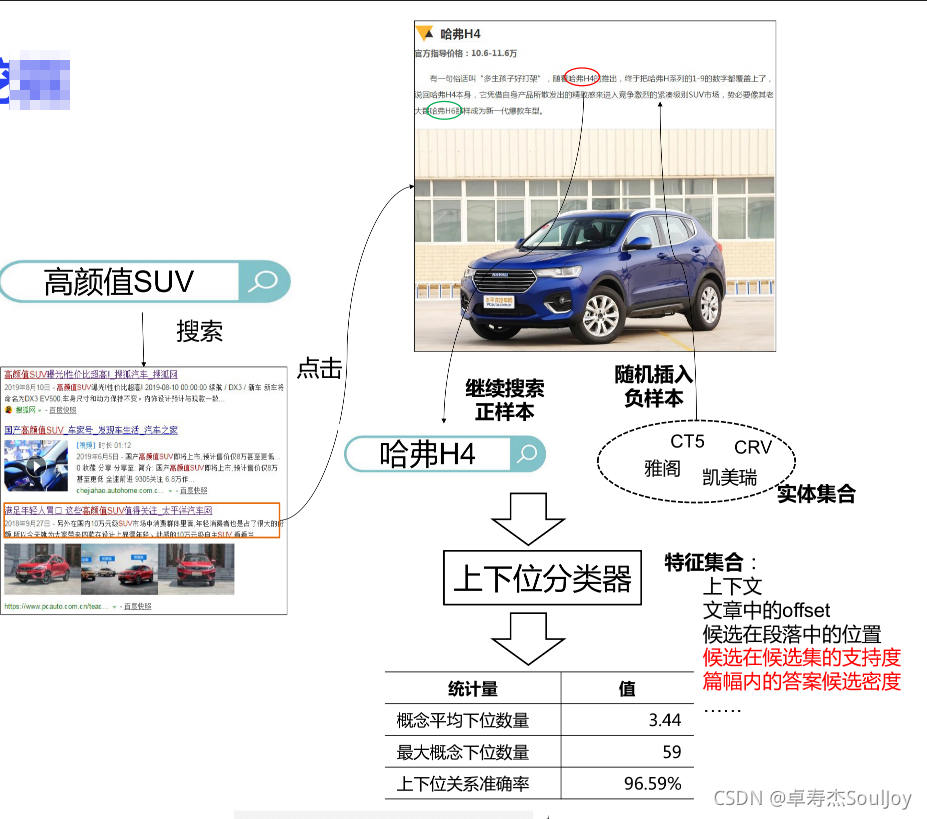
个人认为该方案正样本数据量可能比较少。文章中,实体文字可以加上超链接,这样就能很好的基于用户点击行为获得。而且,我感觉用户”继续搜索“为真正的正样本的正确率可能也不是很高。
2.2.1.3 事件-话题

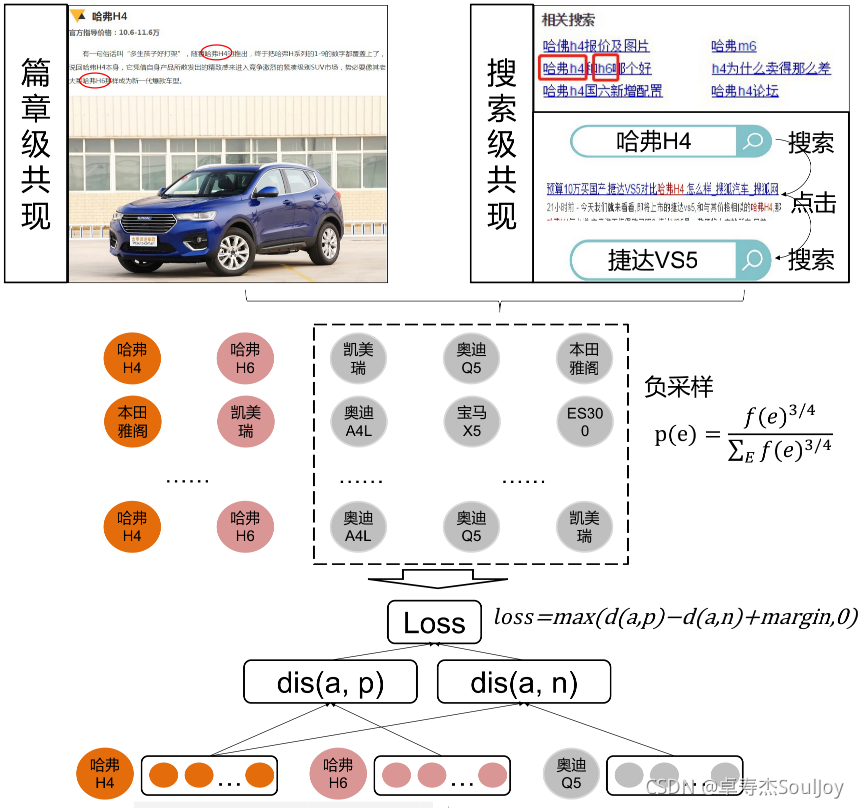
2.2.2 关联关系挖掘

3. 兴趣点图谱应用
3.1 内容理解
简单来说就是把文章打上概念、事件、话题。
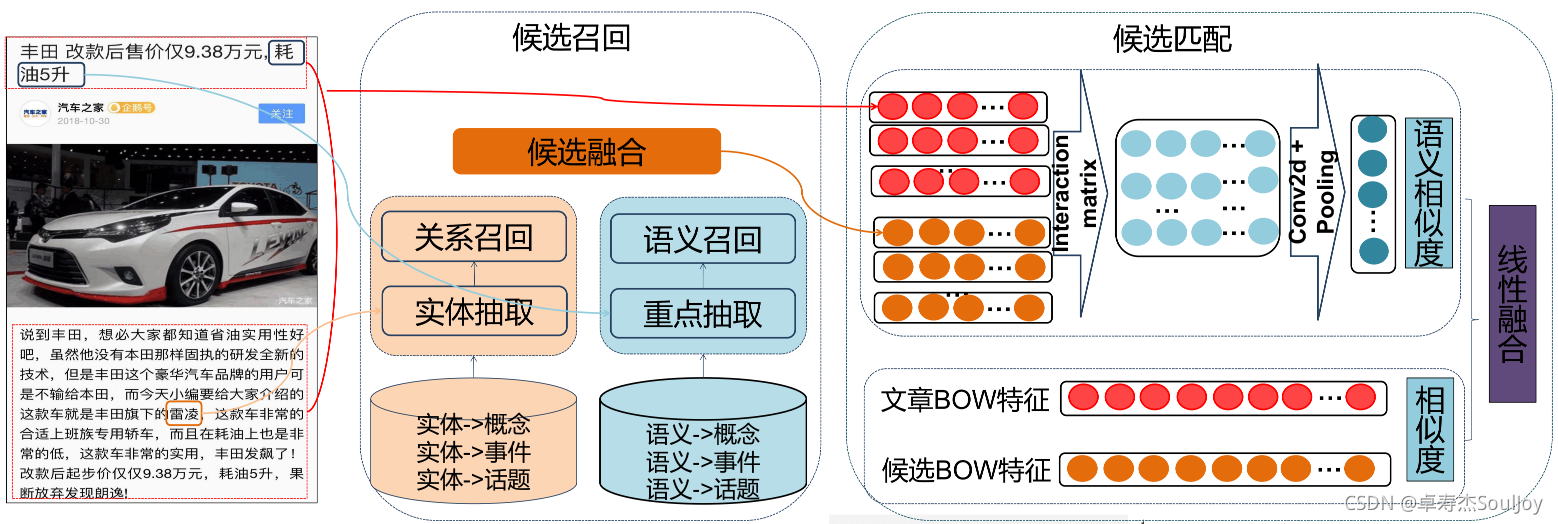
3.1.1 召回

”词语级显示语义召回“的结果还会经过相似度计算过滤一波,以减少候选集:

3.1.2 匹配
由于是离线计算,所以语义匹配使用了MatchPyramid 交叉匹配的架构,还是加上了BOW相似度,最后两者线性融合:
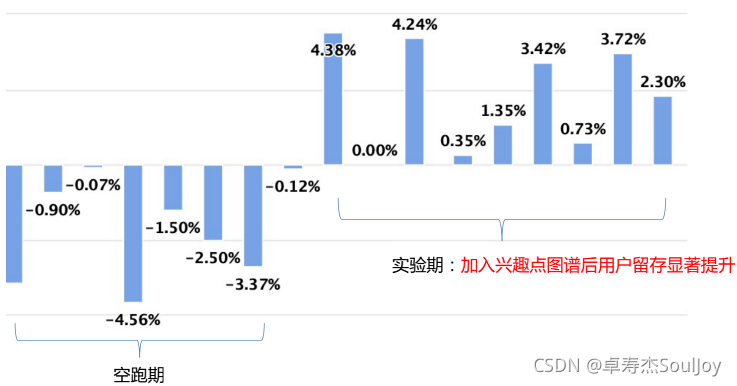
3.2 效果
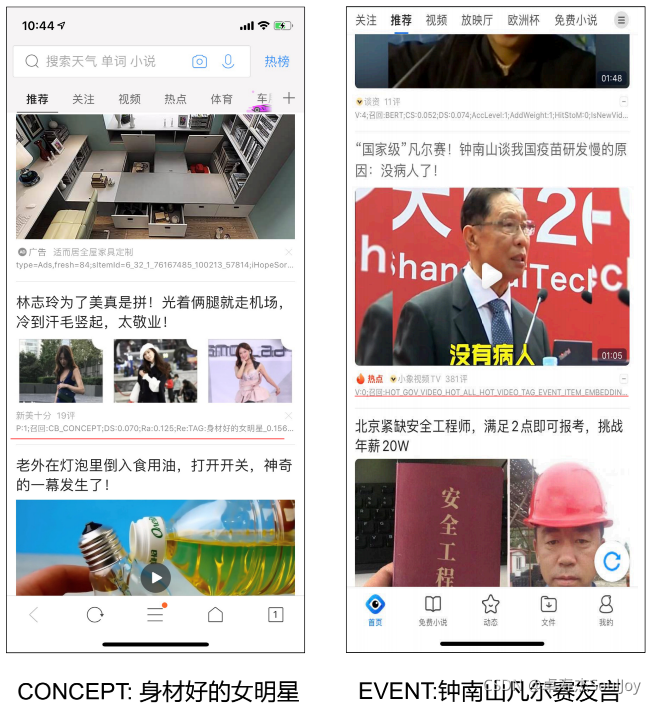
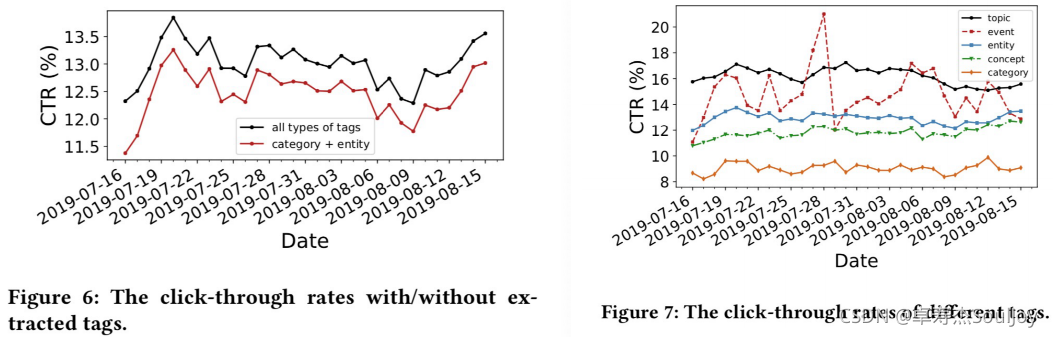
Figure 7 可以看出,基于兴趣点中‘话题’、‘事件’召回的点击率效果比较好,但是基于‘概念’召回的点击率效果会比实体都差。这是由于“概念”本质上是对实体进行了抽象,所以更具多样性,但准确性会降低。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!