论文阅读-基于EA的NAS
hello,这是鑫鑫鑫的论文分享站,今天分享的文章是Large-Scale Evolution of Image Classifiers,这是一篇将进化算法应用于NAS的论文,我们一起看看吧~
摘要
神经网络已被证明能有效地解决困难的问题,但设计它们的体系结构是很有挑战性的,即使仅仅对于图像分类问题也是如此。我们的目标是尽量减少人类的参与,所以我们采用进化算法来自动发现这样的网络。尽管有重要的计算要求,我们表明,现在有可能发展模型的精度在去年公布的范围内。具体来说,我们采用了前所未有的简单进化技术来发现CIFAR-10和CIFAR-100数据集的模型,从简单的初始条件开始,分别达到了94.6%(集成95.6%)和77.0%的精度。为了做到这一点,我们使用新颖直观的变异操作来导航大的搜索空间; 我们强调一旦进化开始,就不需要人类参与,并且输出是一个经过充分训练的模型。在这项工作中,我们特别强调结果的可重复性、结果的可变性和计算要求。
1. 介绍(简单介绍了一下,当前的进展)
在有大量训练数据的情况下,神经网络可以成功地执行困难的任务(He et al.,2015;Weyand et al.,2016;Silver et al.,2016;Wu et al.,2016)。然而,发现神经网络结构仍然是一项艰巨的任务。即使在图像分类的具体问题中,通过数百名研究人员多年的集中研究也达到了最新的水平(Krizhevsky et al.(2012);Simonyan&Zisserman(2014);Szegedy et al.(2015);He et al.(2016);Huang et al.(2016a)等)。
因此,近年来,自动发现这些架构的技术越来越流行也就不足为奇了(Bergstra&Bengio,2012;Snoek et al.,2012;Han et al.,2015;Baker et al.,2016;Zoph&Le,2016)。最早的此类“神经发现”方法之一是神经进化(Miller et al.,1989;Stanley&Miikkulainen,2002;Stanley,2007;Bayer et al.,2009;Stanley et al.,2009;Breuel&Shafait,2010;Pugh&Stanley,2013;Kim&Rigazio,2015;Zaremba,2015;Fernando et al.,2016;Morse&Stanley,2016)。尽管取得了令人鼓舞的结果,深度学习社区普遍认为进化算法无法匹配手工设计模型的精度(Verbancsics&Harguess,2013;Baker et al.,2016;Zoph&Le,2016)。在这篇文章中,我们证明了在今天,只要有足够的计算能力,发展这样的竞争模型是可能的。
据我们所知,我们使用了稍加修改的已知进化算法,并将计算规模扩大到前所未有的水平。 这一点,加上一组新颖直观的变异造作,使我们能够在CIFAR-10数据集上达到有竞争力的精确度。之所以选择这个数据集,是因为它需要大型网络才能达到高精度,因此带来了计算上的挑战。我们还在CIFAR-100数据集上向泛化和进化网络迈出了一小步。在从CIFAR-10到CIFAR-100的转换过程中,我们没有修改算法的任何方面或参数。我们在CIFAR-10上的典型神经进化结果的测试准确率为μ=94.1%,标准差σ=0.4% @9×1019次,我们的顶级模型(通过验证准确率)的测试准确率为94.6% @4×1020次。 在不增加训练成本的情况下,对每个群体的前2个模型进行验证,测试准确率达到95.6%。在CIFAR-100上,我们的单次实验得到了77.0% @2×1020次的测试精度。据我们所知,这些都是从琐碎的初始条件开始的自动发现方法在这些数据集上获得的最准确的结果。
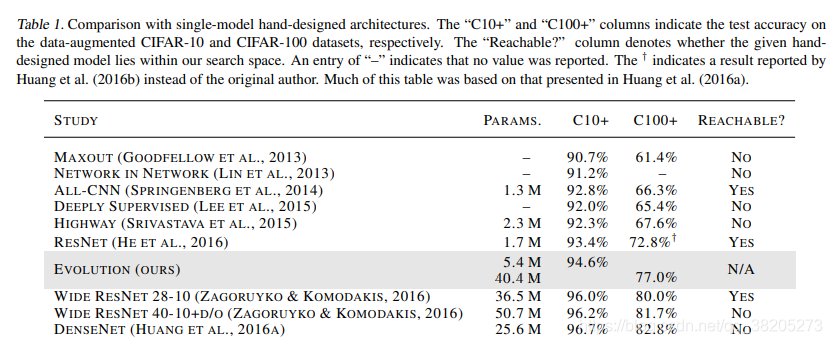
表1。与单一模型手工设计架构的比较。“C10+”和“C100+”列分别表示数据增强CIFAR-10和CIFAR-100数据集的测试精度。“可到达的”?“列表示给定的手工设计模型是否位于我们的搜索空间内。输入“–”表示未报告任何值。这表明(2016b)报告的结果,而不是原作者。这张表的大部分内容是基于Huang等人(2016a)提出的。
在整个研究过程中,我们特别强调了算法的简单性。特别是,
- 它是一种“one-shot”技术,产生一个完全训练的神经网络,不需要后处理。
- 它也有一些有效的元参数(即参数没有优化的算法)。从没有卷积的性能较差的模型开始,该算法必须进化出复杂的卷积神经网络,同时导航到一个相当不受限制的搜索空间:没有固定的深度、任意的跳转连接和对其值几乎没有限制的数值参数。
我们也密切关注结果报告。也就是说,
- 除了最高值之外,我们还展示了我们结果的可变性,我们考虑了研究人员的自由度(Simmons等人,2011),我们研究了对元参数的依赖性,
并披露了达到主要结果所需的计算量。我们希望我们对计算代价的明确讨论能够激发更多关于有效模型搜索和训练的研究。通过计算投资标准化模型性能的研究,可以考虑机会成本等经济概念。
2. 相关工作
神经进化可以追溯到许多年前(Miller等人,1989),最初只用于进化固定结构的重量。Stanley&Miikkulainen(2002)表明,使用整洁算法同时进化体系结构是有利的。NEAT有三种突变:(i)修改权重,(ii)在现有节点之间添加连接,或(iii)在拆分现有连接时插入节点。 它还有一种将两个模型重组为一个模型的机制和一种促进多样性的策略,称为适应度共享(Goldberg等人,1987)。进化算法使用一种编码方式来表示模型,这种编码方式与自然界的DNA相似,非常方便。NEAT使用直接编码:每个节点和每个连接都存储在DNA中。另一种范式,间接编码,已经成为许多神经进化研究的主题(Gruau,1993;Stanley et al.,2009;Pugh&Stanley,2013;Kim&Rigazio,2015;Fernando et al.,2016)。例如,CPPN(Stanley,2007;Stanley et al.,2009)允许在不同尺度上演化重复特征。此外,Kim和Rigazio(2015)在最初高度优化的固定架构中使用间接编码来改进卷积滤波器。
权重演化的研究仍在进行中(Morse&Stanley,2016),但更广泛的机器学习社区默认采用反向传播优化神经网络权重(Rumelhart等人,1988)。反向传播和进化可以结合在一起,如Stanley et al.(2009)中所述,其中仅进化结构。他们的算法遵循架构突变和权重反向传播的交替。类似地,Breuel&Shafait(2010)将这种方法用于超参数搜索。Fernando et al.(2016)也使用反向传播,允许通过结构修改继承训练的权重。
与用于图像分类的典型现代结构相比,上述研究创建的神经网络较小(He et al.,2016;Huang et al.,2016a)。他们关注的是进化过程的编码或效率,而不是规模。当涉及到图像时,一些神经进化结果达到了在MNIST数据集上成功所需的计算规模(LeCun et al.,1998)。然而,现代分类器通常在真实的图像上进行测试,例如CIFAR数据集中的图像(Krizhevsky&Hinton,2009),这更具挑战性。这些数据集需要大型模型来实现高精度。
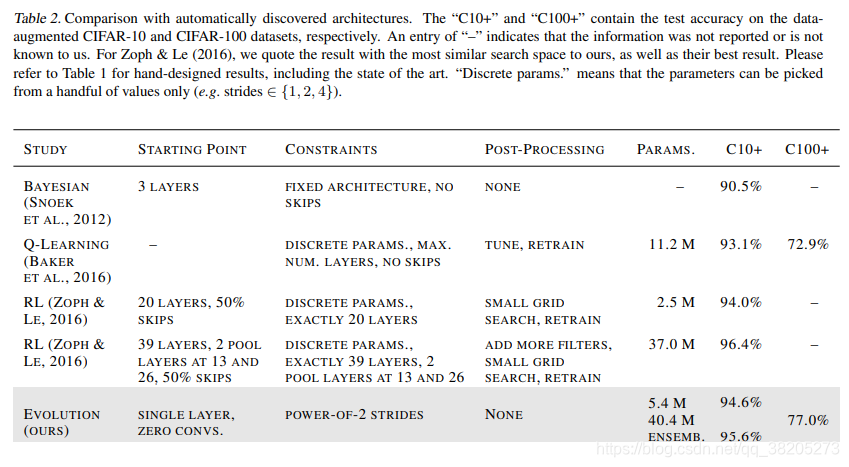
表2。与自动发现的体系结构进行比较。“C10+”和“C100+”分别包含dataaugmented CIFAR-10和CIFAR-100数据集的测试精度。输入“–”表示我们未报告或不知道该信息。对于Zoph&Le(2016),我们引用了与我们的搜索空间最相似的结果,以及他们的最佳结果。手工设计的结果,包括最新技术,请参考表1。“离散参数”意味着参数只能从少数值中选取(例如,步长∈{1,2,4})。
非进化神经发现方法在处理真实图像数据方面更为成功。Snoek等人(2012年)使用贝叶斯优化方法调整了固定深度架构的9个超参数,达到了当时的最新水平。Zoph&Le(2016)将强化学习用于更深层次的定长体系结构。在他们的方法中,神经网络“发现者”构造了一个卷积神经网络“发现者”,一次一层。除了调整图层参数外,还可以添加和删除跳过连接。这一点,再加上一些手动后处理,使它们非常接近(当前)最先进的水平。(此外,他们在序列到序列问题上超越了最新技术。)Baker等人(2016)使用Q-learning也可以一次发现一层网络,但在他们的方法中,层的数量由发现者决定。这是一个理想的特性,因为它允许系统构造浅层或深层的解决方案,这可能是手头数据集的要求。不同的数据集不需要特别调整算法。比较这些方法是困难的,因为他们探索非常不同的搜索空间和有非常不同的初始条件(表2)。
切向而言,LSTM结构也有神经进化研究(Bayer et al.,2009;Zaremba,2015),但这超出了本文的范围。与这项工作相关的还有Saxena和Verbeek(2016),他们将具有不同参数的卷积嵌入一类具有许多平行路径的“超级网络”。然后,他们的算法在超级网络中选择和集成路径。最后,超参数搜索的典型方法是网格搜索(例如,Zagoruyko和Komodakis(2016))和随机搜索,后者是两者中的佼佼者(Bergstra和Bengio,2012)。
我们的方法建立在以前的工作的基础上,有一些重要的区别。我们探索从基本初始条件开始的大型模型架构搜索空间,以避免用已知的好策略信息启动系统。我们的编码不同于上面提到的神经进化方法:我们使用一个简化的图形作为我们的DNA,它被转换成一个完整的神经网络图形用于训练和评估(第3节)。一些作用于这个DNA的突变让人联想到整洁。然而,一个突变可以代替单个节点插入整个层,即一次插入几十到几百个节点。我们还允许移除这些层,这样进化过程除了使体系结构复杂化之外,还可以简化体系结构。图层参数也是可变的,但我们没有规定一个小的可能值集可供选择,以允许更大的搜索空间。我们不使用健身分享。我们报告了使用重组的其他结果,但在大多数情况下,我们只使用突变。另一方面,我们使用反向传播来优化权重,这些权重可以通过突变遗传。再加上学习率突变,这就允许探索学习率时间表的空间,在进化过程结束时产生完全训练的模型(第3节)。表1和表2分别将我们的方法与手工设计的架构和其他神经发现技术进行了比较。
3. 算法
3.1. 进化算法
为了自动搜索高性能的神经网络结构,我们进化了一组模型。
进化算法思想:(锦标赛选择法)
每个模型或个体都是经过训练的网络结构。 在一个单独的验证数据集上,模型的准确性是对个体质量或适合度的一种度量。 在每一个进化步骤中,一台计算机(即一个worker)从这个群体中随机选择两个人,比较他们的适应性。淘汰差的。选择其中最好的作为父代。然后,worker创建父代的一个副本,并通过应用一个突变来修改这个副本,(我们将此修改后的副本称为子副本),在worker创建子对象之后,它训练这个子对象,在验证集中对其进行评估,并将其放回总体中。然后子代激活,也就是说,可以自由地扮演父母的角色。因此,我们的方案使用随机个体的重复成对竞争,这使得它成为锦标赛选择的一个例子(Goldberg&Deb,1991)。使用两两比较而不是全人口操作,可以防止worker在提前完成任务时无所事事。
使用这种策略搜索复杂图像模型的大空间需要大量的计算。为了实现大规模,我们开发了一个大规模并行的无锁基础设施。许多workers在不同的计算机上异步操作。他们之间不直接交流。相反,他们使用一个共享的文件系统, 在那里存储种群。文件系统包含代表个体的目录。对这些个体的操作(例如杀死一个个体)在目录[1]上表示为原子重命名。有时,一个worker可以同时修改另一个worker正在操作的个体。在这种情况下,受影响的工人只是放弃并再次尝试 。 除非另有说明,种群规模为1000人。工人的数量总是与人口规模有关,为种群总数的1/4,为了在有限的空间内实现长时间的运行,经常对死亡个体的目录进行垃圾收集。
3.2. 编码和突变
个别结构被编码为一个图形,我们称之为DNA。
在该图中,顶点表示维张量或激活函数。作为卷积网络的标准,张量的两个维度表示图像的空间坐标,第三个维度表示多个通道。激活函数应用于顶点,可以是(i)使用修正线性单元(ReLUs)的批量归一化(Ioffe&Szegedy,2015)或(ii)普通线性单位。图的边表示单位连接或卷积,并包含定义卷积性质的可变数值参数。当多条边入射到一个顶点上时,它们的空间比例或通道数可能不一致。但是,顶点必须具有单个大小和通道数才能激活。输入不一致的问题必须解决。分辨率是通过选择一个传入边作为主边来完成的。我们选择这个主边作为不是跳过连接的边。来自非主边的激活在大小上通过zerothorder插值重塑,在通道数上通过截断/填充重塑,如He等人(2016)。除了图形,学习率值也存储在DNA中。
由于突变的作用,孩子与父母相似但不完全相同。在每一个复制事件中,工作者从一个预定的集合中随机挑选一个突变。可供选择的变异包括:(有的变异给出了范围)
- 改变学习率
- 恒等连接插入卷积层
- 删除卷积层
- 改变步长
- 改变卷积层的channel数
- 改变卷积层filter的大小(只能是奇数)
- 插入skip connection
- 删除skip connection
选择这些特定突变是因为它们与人类设计师在改进架构时可能采取的行动相似。这可能为未来的混合进化-手工设计方法扫清道路。突变的概率没有任何调整。
一个作用于数值参数的变异随机地在现有值周围选择新值。所有样本均来自均匀分布。例如,作用于具有10个输出通道的卷积的突变将导致具有5到20个输出通道(即,原始值的一半到两倍)的卷积。范围内的所有值都是可能的。因此,这些模型不受许多已知工作良好的过滤器的约束。所有其他参数也是如此,产生了一个“密集”的搜索空间。对于跨步,这适用于值的log-base-2,以允许激活形状更容易匹配[2]。原则上,任何参数都没有上限。例如,所有模型深度都是可以达到的。由于硬件的限制,搜索空间是无限的。参数的密集性和无界性导致了对一组真正大的可能架构的探索。
3.3. 初始条件
每个进化实验都是从一群简单的个体开始的,所有个体的学习率都是0.1。他们的表现都很差。每个初始个体构成一个没有卷积的单层模型。这种对糟糕初始条件的有意识的选择迫使进化本身做出发现。实验者的贡献主要是通过选择界定搜索空间的突变。总之,使用较差的初始条件和较大的搜索空间限制了实验者的影响。换句话说,它阻止了实验者“操纵”实验以获得成功。
3.4. 训练和验证
训练和验证是在CIFAR-10数据集上完成的。
数据库:该数据集由50000个训练示例和10000个测试示例组成,所有这些示例都是32 x 32彩色图像,标记有10个公共对象类中的1个(Krizhevsky&Hinton,2009)。在一个验证集中提供了5000个培训示例。剩下的45000个例子构成了我们的实际训练集。如He等人(2016)所述,对培训集进行了扩充。CIFAR-100数据集的维数、颜色和示例数与CIFAR-10相同,但使用了100个类,这使得它更具挑战性。
训练:
使用TensorFlow(Abadi et al.,2016)进行训练,使用动量为0.9的SGD(Sutskever etal.,2013),批量大小为50,重量衰减为0.0001。每个训练运行25600步,选择的值足够简短,以便每个人可以在几秒钟到几个小时内进行训练,具体取决于模型大小。损失函数是交叉熵。一旦训练完成,验证集上的一个单独评估就可以提供准确度,作为个人的适应度。在测试评估过程中,采用多数投票的方式进行筛选。集合中使用的模型是通过验证精度来选择的。
3.5. 计算成本
为了估计计算成本,我们确定了模型训练和验证所使用的tensorflow(TF)运算,如卷积、一般矩阵乘法等。对于这些TF运算,我们估计了所需的浮点运算(FLOPs)的理论数量。这导致了从TF操作到FLOPs的映射,这对我们所有的实验都是有效的。
对于一个进化实验中的每个个体,我们计算在一批例子中,在训练(Ft FLOPs)和验证(Fv FLOPs)期间,TF操作在其体系结构中产生的总FLOPs。Nt,Nv分别为训练批次和验证批的数量,然后我们将成本FtNt+FvNv分配给个体,实验的成本是所有个体成本的总和。
我们打算我们的FLOPs测量只是一个粗略的估计。我们不考虑输入/输出、数据预处理、TF图构建或内存复制操作。其中一些未说明的操作在每个训练运行或每个步骤中发生一次,有些操作的组件在模型大小上是恒定的(例如磁盘访问延迟或输入数据裁剪)。因此,我们期望该估计对于大型体系结构(例如,具有许多卷积的体系结构)更有用。
3.6. 权重继承
我们需要在进化实验中训练完成的架构。如果这种情况没有发生,我们将被迫在最后重新训练最佳模型,可能不得不探索其超参数。这种额外的探索往往取决于被重新训练的模型的细节。另一方面,25600步还不足以充分训练每个人。训练一个大模型来完成这个过程对于进化来说是非常缓慢的。为了解决这个难题,我们允许子代尽可能地继承父母的体重。即,如果层具有匹配的形状,则保留权重。 因此,有些突变保留了所有的权值(如身份或学习率突变),有些突变不保留任何权值(重设权值突变),大多数突变保留了部分权值,但不是全部权值。后者的一个例子是滤波器大小变异:只有被变异的卷积滤波器才会被丢弃。
3.7. 报告方法
为了避免过度拟合,无论是进化算法还是神经网络训练都无法看到测试集。每次我们提到“最佳模型”时,我们都是指具有最高验证精度的模型。 然而,我们总是报告测试的准确性。这不仅适用于实验中最佳个体的选择,也适用于最佳实验的选择。此外,除非明确指出,我们只包括我们设法复制的实验。任何统计分析都是在看到报告的实验结果之前完全决定的,以避免根据我们的实验数据来调整我们的分析。
4. 实验和结果
我们想回答以下问题:
一个one-shot的训练过程是否能从一个很差的初始条件中通过演化得到一个和人工设计的网络性能相近的结构。
结果的可变性、并行性和方法的计算成本是什么?
在CIFAR-10上迭代设计的算法是否可以应用于CIFAR-100,而不做任何更改,并且仍然可以生成具有竞争力的模型?
我们使用第3节中的算法进行了几个实验。每个实验在几天内进化出一个群体,如图1所示。图中还包含了所发现的体系结构示例,这些示例非常简单。进化尝试跳过连接,但经常拒绝它们。
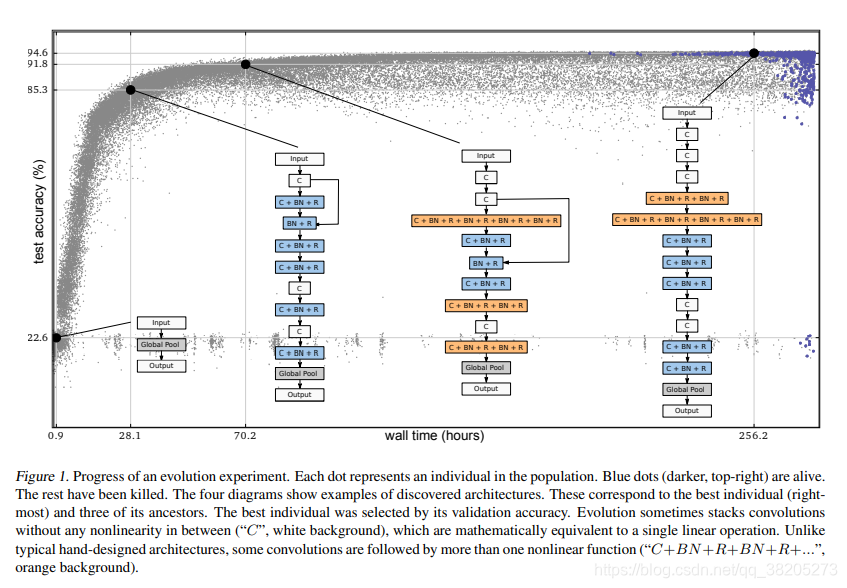
图1解释: 每个点代表人口中的一个个体。蓝点(较暗,右上角)是活的。其余的都被杀了。这四个图显示了发现的体系结构的示例。这些对应于最好的个体(最右边的)和它的三个祖先。通过验证准确度筛选出最佳个体。进化有时会叠加卷积,卷积之间没有任何非线性(“,白色背景),这在数学上相当于一个单一的线性运算。与典型的手工设计的结构不同,一些卷积后面有一个以上的非线性函数(“+BN+R+BN+R+…”,橙色背景)
为了了解结果的可变性,我们重复了5次实验。在所有5个实验运行中,验证的最佳模型的测试准确率为94.6%。并非所有的实验都达到相同的精度,但它们接近(μ=94.1%,标准差=0.4)。实验结果的细微差异可以通过验证准确度(相关系数=0.894)加以区分。所有5个实验的总计算量为4×1020次(或平均每个实验9×1019次)。每个实验分配给250名平行工作人员(第3.1节)。图2详细显示了实验的进展。
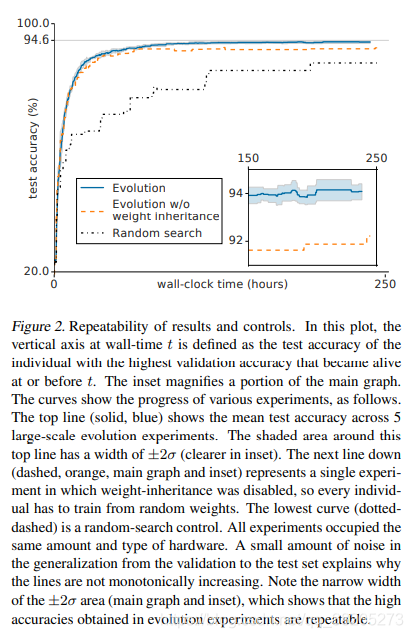
图2:结果和控制的可重复性。在该图中,壁时间的垂直轴被定义为具有最高验证准确度的个体的测试准确度,该个体在或之前变得活跃。插图放大了主图形的一部分。曲线显示了各种实验的进展,如下所示。顶行(实心,蓝色)显示了5个大规模进化实验的平均测试精度。该顶线周围的阴影区域宽度为±2σ(插图中更清晰)。下一行(虚线、橙色、主图和插图)表示一个禁用了权重继承的实验,因此每个个体都必须根据随机权重进行训练。最低曲线(dotteddashed)是一个随机搜索控件。所有的实验都使用相同数量和类型的硬件。从验证到测试集的泛化中的少量噪声解释了为什么线不是单调增加的。注意±2σ区域的窄宽度(主图和插图),这表明进化实验中获得的高精度是可重复的。
作为控制,我们禁用了选择机制,从而复制和杀死随机个体。这是与我们的基础设施最兼容的随机搜索形式。参数的概率分布隐含地由突变决定。在相同的硬件上,在相同的运行时间内,此控件仅达到87.3%的精度(图2)。计算总量为2×1017次。低触发器计数是随机搜索生成许多小的、不适当的模型的结果,这些模型训练很快,但消耗的设置时间大致恒定(不包括在触发器计数中)。我们试图通过避免不必要的磁盘访问操作来最小化此开销,但没有成功:在神经网络设置、数据扩充和训练步骤初始化的组合上仍然花费了太多开销。
我们还运行了部分控件,其中禁用了权重继承机制。在相同的时间内(图2),使用9×1019次触发器,这种运行也会导致较低的精度(92.2%)。这说明权重继承在这个过程中很重要。
最后,我们将我们的神经进化算法应用于CIFAR-100,没有任何改变,并且具有相同的元参数。我们唯一的实验达到了77.0%的准确率,使用了2×1020次触发器。我们没有尝试其他数据集。表1显示,CIFAR-10和CIFAR-100的结果与现代手工设计的网络具有竞争力。
5. 分析
-
元参数。
我们观察到种群不断进化,直到稳定在某个局部最优值(图2)。此最佳值的适合度(即验证准确度)值在不同实验中有所不同(图2,插图)。由于并不是所有的实验都达到了可能的最高值,一些种群被“困住”在较低的局部最优解。这种捕获受两个重要的元参数(即算法未优化的参数)的影响。这些是人口规模和每个人的训练步骤数。下面我们讨论它们并考虑它们与局部最优解的关系。 -
人口规模的影响。
更大的群体更彻底地探索模型的空间,这有助于达到更好的优化(图3,左)。特别要注意的是,大小为2的群体可能会被困在非常低的适应值。关于这一点的一些直觉可以通过考虑一个超级适合个体的命运来获得,即一个个体,任何一个结构突变都会降低它的适合度(即使一系列的突变可能会改善它)。在人口规模为2的情况下,如果超级适合的个人赢了一次,它每次都会赢。在第一次获胜后,它将产生一个只有一个突变的孩子。因此,根据“超级适合”的定义,这个孩子是次等的[3]。因此,在下一轮的锦标赛选择,超级适合个人竞争对其子女,并再次获胜。这个循环永远重复,人口被困住了。即使一个由两个突变组成的序列允许从局部最优解“逃逸”,这样的序列也永远不会发生。这只是一个粗略的论据,启发性地提出为什么2号人口容易被困住。更一般而言,图3(左)从经验上证明了人口规模增加的好处。这种依赖性的理论分析相当复杂,并且假设种群动力学的非常具体的模型;通常较大的种群更善于处理局部最优解,至少超过一个大小阈值(Weinreich&Chao(2005)和参考文献) -
训练步数的影响。
另一个元参数是每个个体的训练步骤数。准确度随时间增加(图3,右)。更大意味着个体需要经历更少的身份突变才能达到给定的训练水平。T型T型T型 -
逃离局部最优解。、、数量的步骤,以防止被困人口形成,我们也可以释放一个已经被困的人口。例如,增加突变率或重置一个群体的所有权重(图4)效果很好,但成本相当高(更多细节见补充部分S3)。
-
重组
到目前为止,没有一个结果使用重组。然而,我们在额外的实验中探索了三种重组形式。继Tuson&Ross(1998)之后,我们也尝试进化突变概率分布。除此之外,我们还采用了一种重组策略,通过这种策略,孩子可以从一个父母那里继承结构,并从另一个父母那里继承突变概率。目标是让那些由于良好的突变选择而进展良好的个体能够迅速地将这些选择传播给其他人。在另一个实验中,我们尝试重新组合来自两个父母的训练权重,希望每个父母可能从训练数据中学习到不同的概念。在第三个实验中,我们重新组合了结构,这样孩子就可以将父母的结构并排融合,快速生成宽模型。虽然这些方法都没有改善我们的无重组结果,但进一步的研究似乎是有必要的。
6. 结论
在本文中,我们已经证明:
(i)神经进化能够为两个具有挑战性和流行的图像分类基准构建大型、精确的网络;
(ii)神经进化可以从琐碎的初始条件开始,同时搜索一个非常大的空间;
(iii)这个过程一旦开始,就不需要实验者的参与;
(iv)该过程产生完全训练的模型。完全训练模型需要体重遗传(第3.6节)。与强化学习不同的是,进化为权重遗传提供了一个自然的框架:可以构建突变来保证很大程度的相似性。
在原始模型和变异模型之间。进化也有较少的可调元参数,对结果的方差有相当可预测的影响,可以使其变小。
虽然我们没有专注于降低计算成本,但我们希望未来的算法和硬件改进将允许更经济的实现。在这种情况下,进化将成为一种吸引人的神经发现方法,其原因超出了本文的范围。例如,它“落地运行”,在实验一开始就改进任意初始模型。所使用的突变可以实现该领域的最新进展,并且无需重新开始实验即可引入。此外,重组可以合并不同个体的改良,即使它们来自其他群体。此外,还可以将神经进化与其他自动结构发现方法相结合。
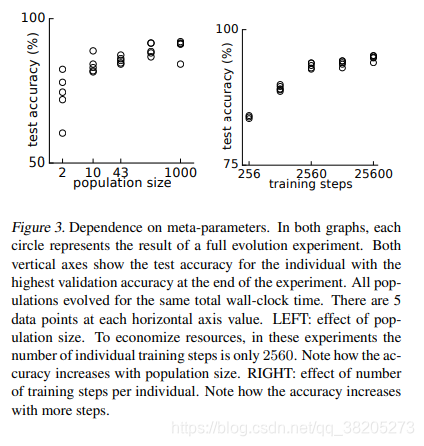
图3。对元参数的依赖。在这两张图中,每个圆都代表了一个完整的进化实验的结果。两个垂直轴都显示了实验结束时验证精度最高的个体的测试精度。所有的种群进化的总时间都是一样的。每个水平轴值有5个数据点。左:人口规模的影响。为了节省资源,在这些实验中,单个训练步骤的数目只有2560个。注意准确度是如何随着人口规模的增加而增加的。右:每个人的训练步数的影响。请注意,精度是如何随着步长的增加而提高的。
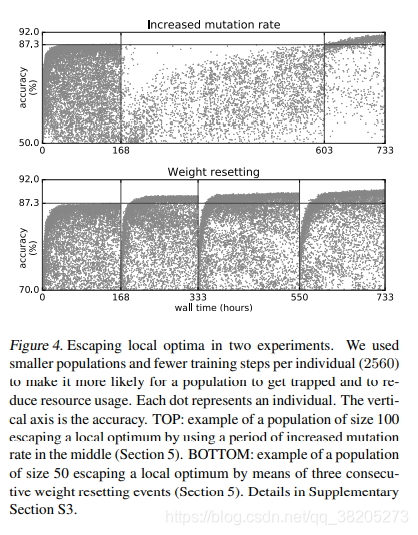
图4。在两个实验中逃离局部最优解。我们使用了更小的人口和更少的训练步骤(2560),使人口更容易陷入困境,并减少资源的使用。每个点代表一个人。垂直轴就是精度。上图:一个大小为100的群体通过在中间使用一个突变率增加的周期来逃脱局部最优值的例子(第5节)。底部:通过三个连续的权重重置事件(第5节),大小为50的群体逃脱局部最优的例子。详见补充章节S3。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!